[Paper Review] Multiple Instance Learning for Heterogeneous Images: Training a CNN for Histopathology
Paper Review

Multiple Instance Learning for Heterogeneous Images: Training a CNN for Histopathology
같은 저자가 동일 년도에 썼던 논문이다. Couture2018b는 Couture2018a와 마찬가지로 tile selection과 tile aggregation과 관련된 내용을 담고 있다.
발표 후 추가 사항 정리
- 전체 파이프라인과 라벨에 관한 내용
- patient-level label을 각 TMA spot에도 동일하게 적용한다.
- TMA spot은 보통 지름이 2500~3500 px 크기이고, random crop은 실험 조건에 따라 227 x 227부터 3500 x 2500 px까지 다양하게 잘렸다.
- 이 잘린 crop image가 FCN을 거쳐 d x d x C의 형태로 output이 나오게 되고, 이 때 d x d grid에서 한 칸이 227 x 227 px의 single instance가 되는 것이다. 즉 random crop이 어떻게 되었는지에 따라서 d값이 달라지는 것이다. 또한 하나의 instance는 C dimension을 가지게 된다.
- 이후 single instance 들은 foreground mask를 거쳐서 없어질 instance들은 없어지고, aggregation 된다.
- aggregation 될 때 하나의 동그란 image에 대해서만 이루어지는 것이 아니라, 1713명의 patient에 5970 images가 있다고 했으니, rough하게 3-4개의 image에서 몇 백개 또는 몇 천개의 instance들씩 뽑은 걸로 bag label을 추정하게 되는 것이다.
Introduction
위 논문은 Couture2018a에 소개되었던 quantile function(QF)을 사용한 tile aggregation을 Multi-Istance(MI) learning의 pooling layer로 포함시켜 end-to-end 모델을 설계하였다.
1) pooling with the quantile function and learning how much heterogeneity is expected for each class
2) an augmentation technique for training MI methods with a CNN
Main Contribution
a) More general MI aggregation method
b) MI augmentation technique for training MI method
c) Exploration of single instance and MI learning on continuous spectrum
d) Large data set, classifying breast cancer TMAs
e) Method for visualizing each instance, interpretability
Method
Multiple Instance Learning with a CNN
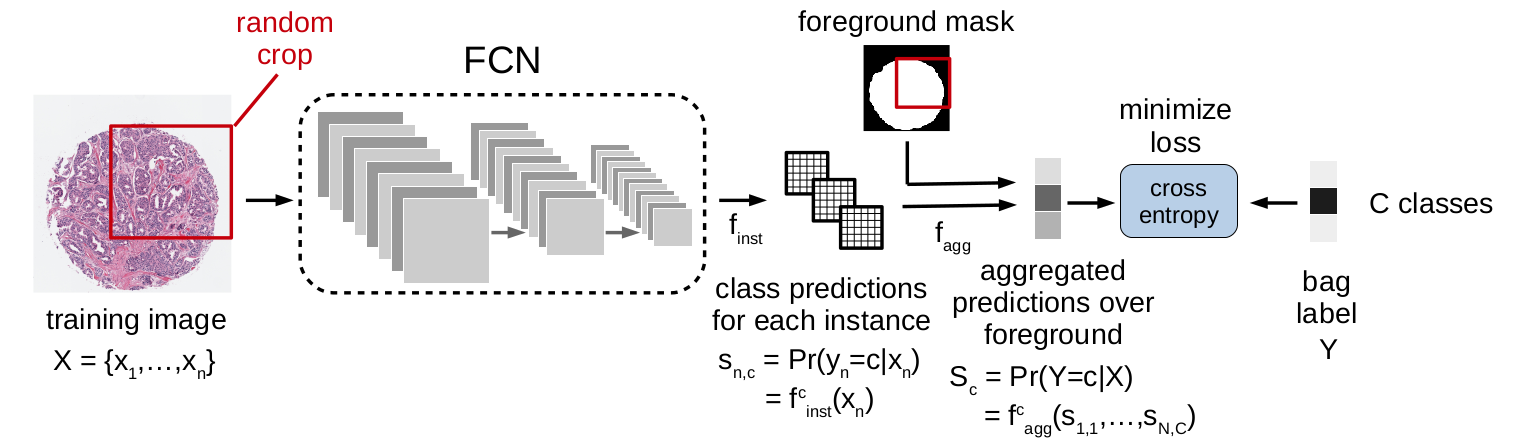
두 가지 중요한 function이 등장한다. function_inst는 fully convolutional network (FCN) 형태의 개별 instance classifier로써 각 class에 속할 probability를 계산한다. 뒤이은 function_agg는 global MI layer로써 계산된 instance probabilities를 bag probability로 aggregate 한다. (Q=15)
FCN은 받은 이미지를 마지막 layer의 softmax를 통해 w x w x 3의 input image를 d x d x C 로 계산해준다. 이 때 single instance는 d x d grid 상의 하나의 점으로써 정의된다. MI aggregation은 계산된 probabilities와 함께 foreground mask를 받아 foreground instances에 대해서만 계산한다.
Multiple Instance Aggregation

Mean pooling을 사용하면 많은 정보가 손실된다. 대신 quantile function은 instance들의 distribution을 통해 boundary point를 표상함으로써 better discretization을 제공한다.
Training with Multiple Instance Augmentation
이 논문에서는 random cropping을 통한 image augmentation으로 training sample을 추가로 만들어주었다. 구체적으로 set of instances를 선택할 때 이미지를 randomly crop 하였고, 각 crop은 foreground mask에서의 최소 75%를 포함하도록 설계되었다. 이 방식을 사용해도 개별 instance의 크기는 변하지 않고 input image size의 제한도 사라지게 된다. 논문에서는 다음 문장을 강조하였다.
As the MI aggregation layer is invariant to input size, the entire image and all its instances are always used at test time.
Experiments
DATA set
1713 patients, typically four cores, with a total of 5970 cores. Each core is selected from the H&E-stained WSI by a pathologist.
Implementation Details
utilized the pre-trained CNN AlexNet, fine-tun with MI architecture. Cross entropy loss is adjusted to ignore patients missing label for a particular tasks.
MI Augmentation and the Importance of MI learning
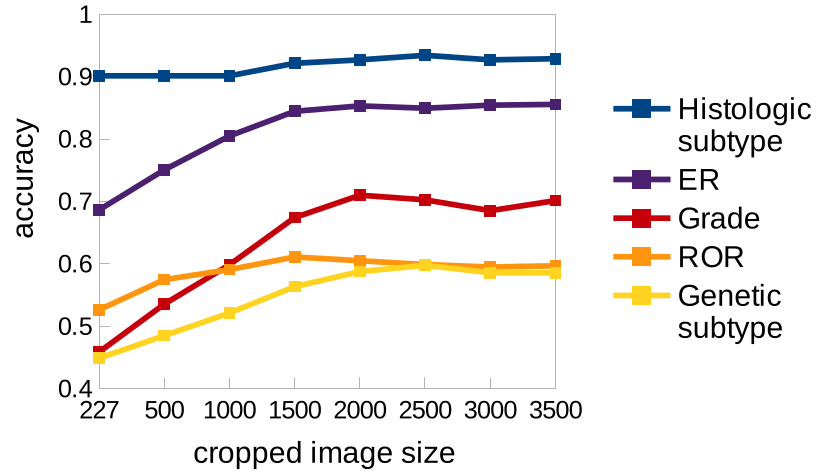
가로축은 cropped image size로, 최소 size인 227 x 227은 오직 하나의 instance로만 구성되어 있다. Training 과정에 더 큰 size가 사용될수록 정확도가 큰 폭으로 증가했다. (Although it should not be surprising ~, the magnitude of improvement is very significant.)
특히 ER status(보라색)에서 accuracy가 68.6% to 85.6%로 증가했는데, 이는 MI learning과 effect of heterogeneity의 importance를 예증(demonstrate)한다.
MI aggregation
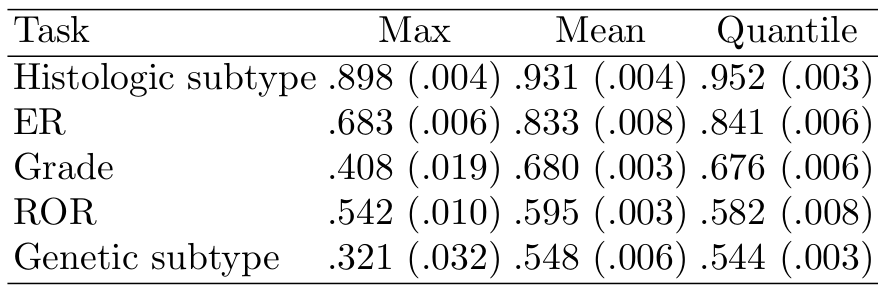
Crop size를 고정하고 pooling 방식을 바꾸어 training한 결과이다. QF pooling을 사용했을 때 성능은 mean pooling과 비슷하거나 outperform 했다. 저자는 이런 성능의 향상을 "predicting the bag class from a more complete view, thereby capturing heterogeneity" 라고 설명했다.
Heterogeneity & Continuous spectrum


각 instance의 class prediction 값을 통해 구한 each region's contribution to the classification 결과를 visualization 하였다. 또한 test set에서 proportion of instances predicted to belong to each class를 구하였다. 이 부분의 해석은 not discrete, but continuous라 쓰여있다. 정확한 함의는 이해하지 못하였다..
Conclusion
- tile selection: pathologist select the cores
- tile aggregation: quantile function을 pooling layer에 접목시켜 foreground mask와 함께 각 instance probabilities를 aggregate하여 bag probability를 계산하는 end-to-end 모델을 제안함.
이 논문 역시 분류가 tile selection, tile aggregation이었지만 핵심 내용은 후자였다. 다른 tile selection 방식들은 어떻게 이루어지는지 간단하게라도 조사해 봐야겠다는 생각이 들었다. 자세한 설명 덕분에 Couture2018a에서 읽다 제대로 모르고 넘어갔던 quantile function 부분을 더 명확히 이해할 수 있었다.
마지막 heterogeneity 파트의 continuous spectrum이 가지는 의의 및 결과 해석 부분은 여전히 잘 모르겠다.
궁금했던 점
- 포스팅엔 쓰지 않았지만 마지막 discussion 부분에 with a small number of labeled samples, our model was successful in fine-tuning the AlexNet CNN라 하였다. 아직 sample 수가 많고 적음에 대한 .. intuition이 부족한 것 같다. 저자의 말을 어느정도까지 믿어야 할지도 잘 모르겠다. (성능이 좋았다, 정확도가 높았다, 샘플 수가 적었다 등의 정성적인 description)
- 언급했던 heterogeneity와 continuous spectrum 관련된 부분이 구체적으로 무슨 의미를 가지고 왜 저자는 나름 강조했는지를 잘 모르겠다.
