[Paper Review] Mildly Conservative Q-learning for Offline Reinforcement Learning
Paper Review
Mildly Conservative Q-learning for Offline Reinforcement Learning
Introduction
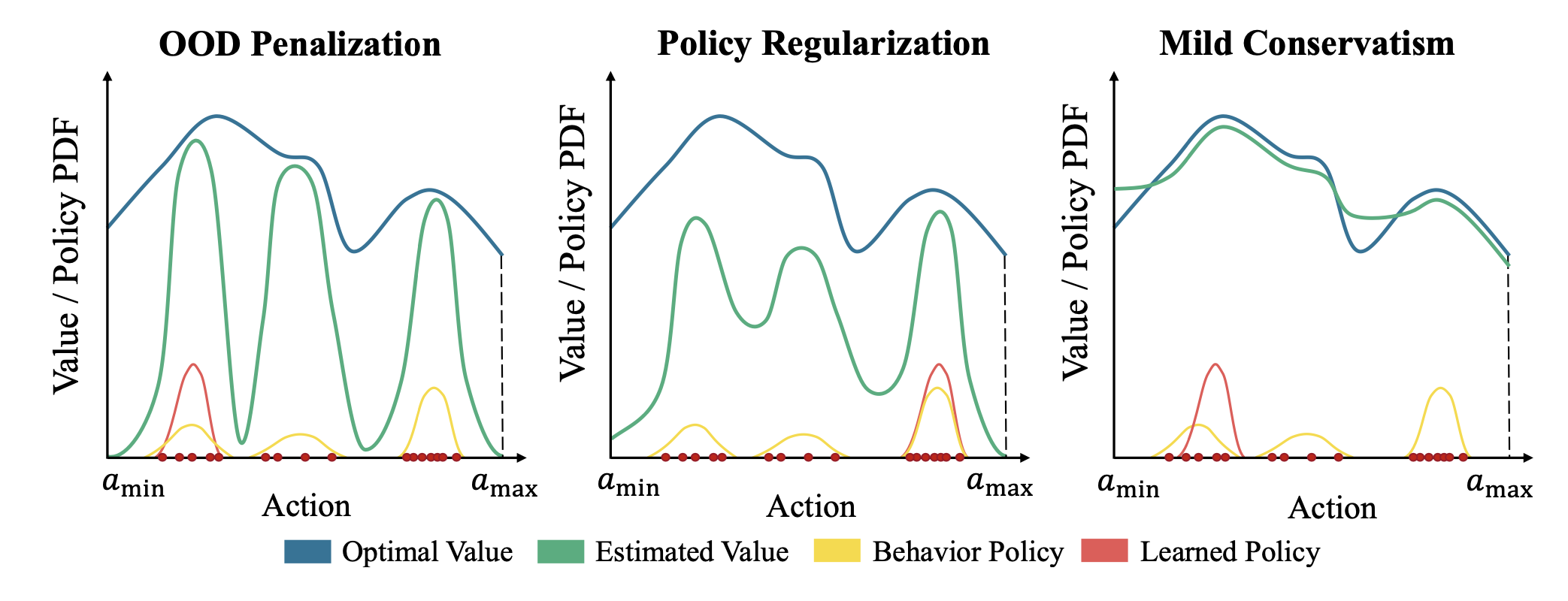
이 논문은 앞서 다루었던 CQL (conservative Q-learning) 방법과 같이 OOD actions 에 대해 learned value function 이나 Learned Q function 의 over-optimistic Q-value 를 penalize 하는 방식이 종종 불필요한 pessimism 을 불러온다고 언급한다. 그렇기에 network 가 관련 value function 에 대해 지나치게 underestimate 하지 않고 suboptimal trajectories 에 “stitch” 함으로써 좋은 가능한 trajectory 를 갖도록 하는 방법을 제안한다.
Preliminaries
앞선 CQL 논문과 notation 이 대부분 비슷하다. Learned policy pi(.|s) 의 target 이 되는 값을 계산하는 Bellman backup 은 아래와 같은 방식으로 계산된다. Q function 이 주어지면 T^pi 라는 operator 로 target Q value 가 계산된다.
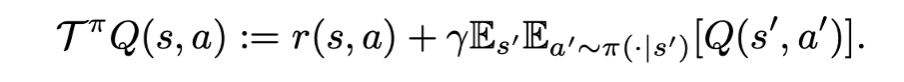
optimal policy 의 Q function 은 아래와 같은 Bellman optimal operator 관계를 만족한다. (given s’ 일 때, A action space 로부터 maximum Q value 를 갖는 a’ 선택.)
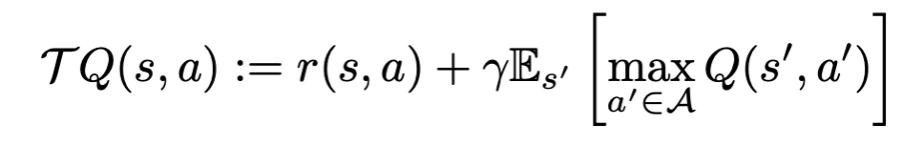
behavior policy, learned (parameterized) policy 의 notation 에 차이가 생기는데, 실제 given offline data를 만드는데 사용한 policy 는 mu(.|s) 라고 표현하고, learned policy 를 pi(.|s) 라고 표현한다. 이 때 Bellman backup 에 사용되는 action 은 learned policy a’~pi(.|s) 로부터 샘플되고 이 mu 는 pi 와 distribution shift 가 잠재하기 때문에 mu 의 support 의 바깥에 위치할 수도 있는 것이다. (OOD action). 이전과 달리 OOD action 과 “in” action 을 구분짓고 OOD action 에게 pseudo target value 를 할당하는 방식을 제안한다.
Mildly Conservative Q-learning
먼저 MCB operator 를 정의하고 practical version of MCB operator 에 대해 설명한 뒤 SAC 와 함께 mu 를 modeling 하는 모델이 추가된 전체 algorithm 을 소개한다.
Mildly Conservative Bellman (MCB) operator
독특하게도 given state 에 대해 learned (parameterized) policy 로부터 sample 된 action 이 given policy mu 의 support region 에 있는지 (if mu(action | state) > 0) 에 따라 target value 가 다르게 계산되어 할당된다.

흥미롭게도, (4) 의 else 단락에서, 실제로 learned policy 에 의해 sample 된 action은 a 임에도 불구하고, 실제 target Q value 는 다시 mu 의 support region 의 action a’ 중에서 Q value 가 최대가 되는 a’ 로부터 구한 Q value 에 delta 를 뺀 값을 할당하고 있다. 즉, given state 에 대해 learned policy 로부터 OOD action 이 sample 이 되어도, 이 action 을 Q function model 에 넣어서 Q value 를 구하는 것이 아니라, state 로부터 mu support region 에 해당하는 즉 OOD action 이 아닌 action 들을 Q function model 에 넣어보고 그 중 최대값을 구해서, delta 를 뺀 값을 target 으로 삼는 것이다. delta > 0 을 빼주는 것은 OOD action 에 대한 target value 에, in action 에 대한 optimal target value 보다는 작은 값을 넣어서, 다시 executing policy 과정에서 OOD action 이 덜 선택되게끔 하기 위함이라 설명하고 있다.
Practical MCB Operator
behavior policy 에 기반해서 action 이 OOD action 인지, in action 인지 판단하기 때문에 behavior policy 를 아는 것이 중요하다. 이 때, behavior policy 로부터 generate 된 offline dataset 은 가지고 있지만 존재하지만 종종 그 기저의 true behavior policy mu 는 알지 못한다. 그렇기 때문에 이 static dataset 으로부터 supervised learning 으로 empirical behavior policy mu_hat 을 fitting 하는 방식을 사용한다. (VAE)
또한 실질적으로 continuous setting 에서는 give state 에 대한 모든 action 에 대한 Q function 을 계산할 수 없기 때문에, 아래 OOD action 에서의 target Q value 를 계산하는 것은 intractable 하다.
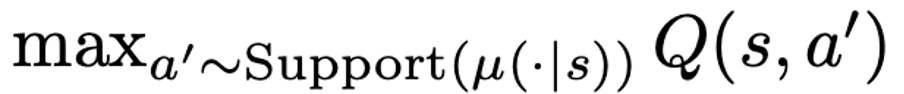
그렇기 때문에 기존 T1 operator 에 변화를 줘서, OOD action 의 pseudo target Q value 를 할당할 때, give state 로부터 가능한 모든 action 에 대해 Q value 를 계산해 그 중 maximum 을 선택하는 방식이 아니라, N개의 action 을 empirical behavior policy mu 로부터 sample 해서 그 중 max 값의 Q value 를 pseudo target Q value 로 사용한다.
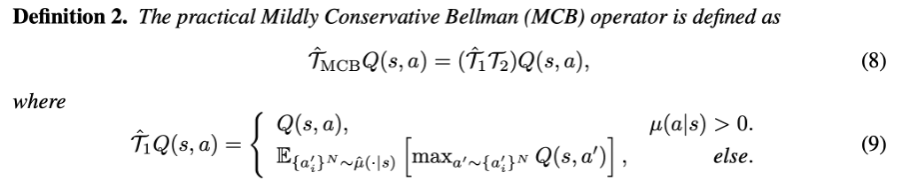
이 때 delta 가 subtraction 되는 부분이 빠졌는데, 이는 N 개를 sample 하기에 일반적으로 아래 조건을 만족하기 때문이라 설명하고 있다.
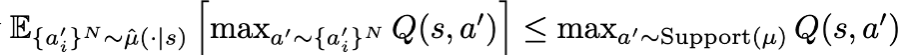
Algorithm
behavior policy mu 는 앞에서 언급했던 것처럼 그 기저의 prior information 을 얻을 수 없는 경우가 대부분이다. 그렇기 때문에 empirical 하게 behavior policy mu_hat 을 supervised learning 으로 학습하는 네트워크를 추가한다.
Modeling the behavior with the CVAE
저자는 conditional variational autoencoder (CVAE) 를 통해 behavior policy mu 를 모델링했다. fixed logged dataset 이 존재할 때, 이 모델의 목적은 conditioned on states 이 given 일 때 action 을 reconstruction 하는 것이다.

기본적인 CVAE 방식과 비슷하게 encoder, decoder 구조로 되어있고, MSE loss 와 prior identity matrix 와의 KL divergence 를 regularization loss 로 활용하고 있다.
Loss functions
필자는 보통 알고리즘을 읽기 전에 코드를 먼저 읽는다. 코드와 코어 알고리즘을 보면서 굉장히 달랐고 이해가 안갔던 방식이 있었는데 그 부분에 대해 여기서 설명하고 있다.
실질적으로 이 논문의 초반에서 state 한 것은 “먼저 state 이 주어졌을 때 learned policy 로부터 action 을 sample 하고, 이것이 mu 에 대해 in action 이면 standard Bellman backup 을 진행하고, mu 에 대해 OOD action 이면 pseudo target Q value 를 할당하는 방식을 진행한다” 이다. 하지만 코드를 보면, given state 를 얻고 학습된 VAE 로부터 “in action” 만을 decode 한다.
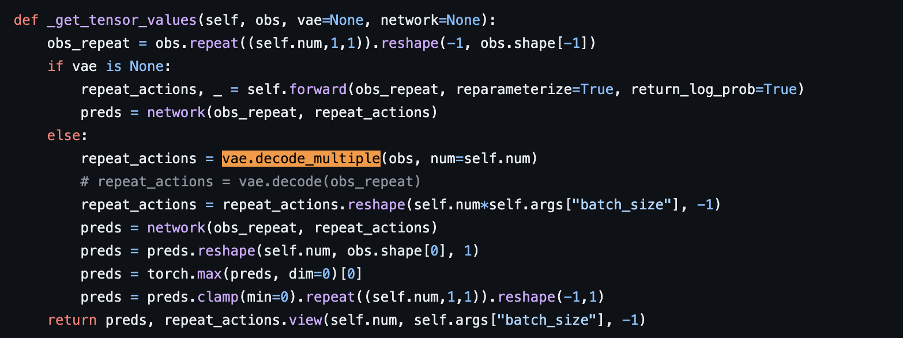
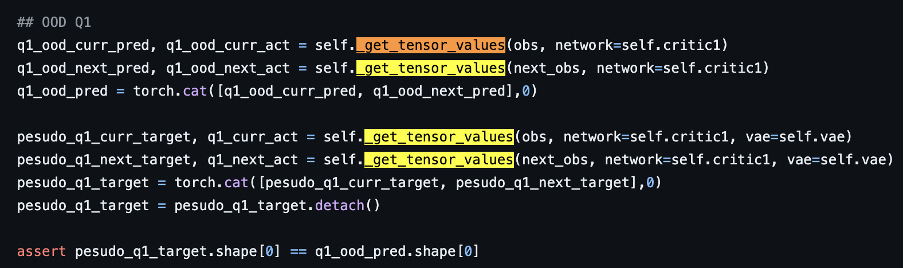
https://github.com/dmksjfl/MCQ/blob/master/offlinerl/algo/modelfree/MCQ.py
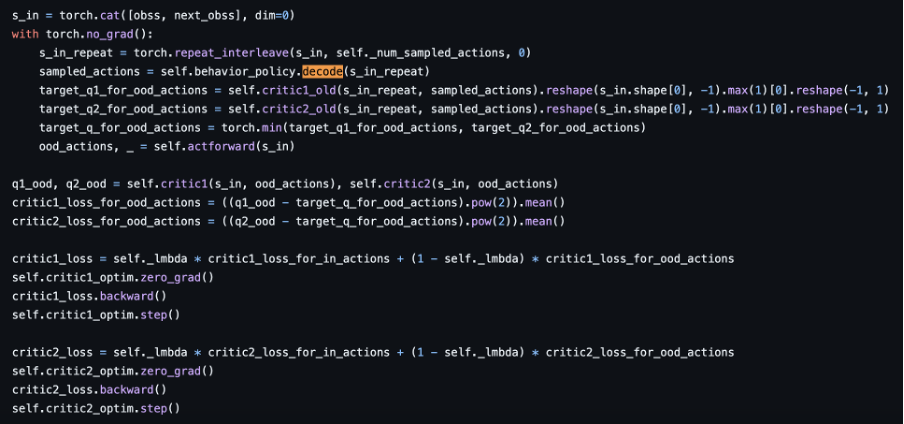
https://github.com/yihaosun1124/OfflineRL-Kit/blob/main/offlinerlkit/policy/model_free/mcq.py
이 논문에서는 sample 한 action 이 mu 에 대해 in-distribution action 인지 out-of-distribution action 인지 판단하는 것이 true behavior policy 가 알려져 있지 않은 상황에서 판단하기 difficult 하며, empirical behavior policy mu_hat 으로부터 판단하는 것도 정확하지 않아 problematic 하다고 언급한다.

그렇기에 의도적으로 OOD action 을 learned policy 로부터 처음부터 sample 하고 (한다고 치고) 실제로는 이에 대해 mu 를 modeling 하는 VAE 로부터 decode 한 in-distribution actions 의 max Q value 를 pseudo target Q value 로 할당하여 loss term 을 구성한다. 즉 위에서 언급한 “먼저 state 이 주어졌을 때 learned policy 로부터 action 을 sample 하고” mu 에 의해 in-distribution 인지 out-of-distribution 인지 판단하는 과정 자체가 생략되어 있는 것이다.
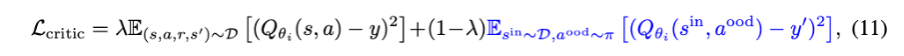
그리하여 위처럼 식이 구성되게 된다.
Results
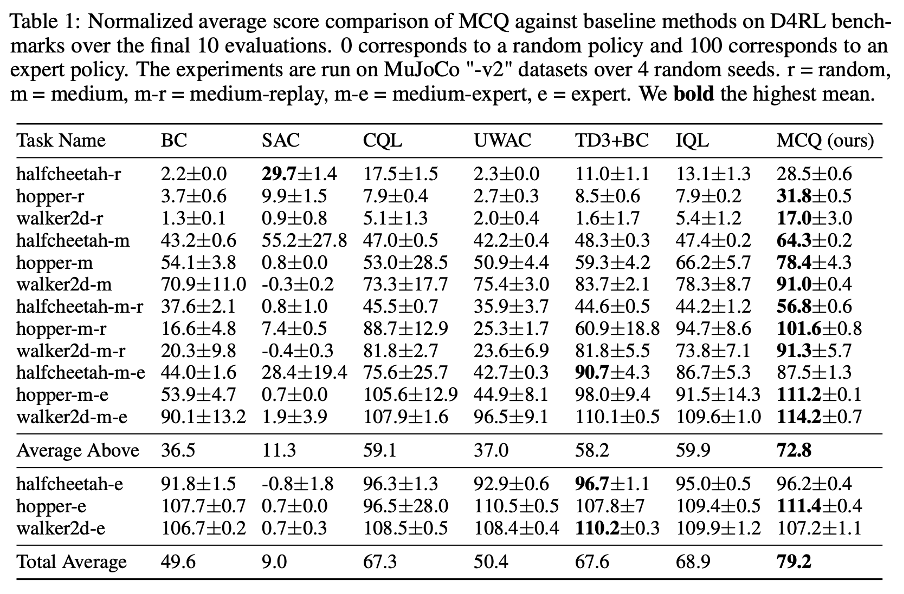
성능 기록표를 살펴보면, Mujoco dataset 에 대해, CQL 및 IQL 보다 전반적으로 더 좋은 성능을 기록하고 있다.
Discussion (limitation and future work)
저자가 언급하고 있는 limitation 과 future work 는 한가지였다.
- weighting coefficient lambda 를 task 마다 tuning 해야함. empirically 0.7~1 사이의 수가 괜찮았으나, automatic tuning of lambda 가 앞으로 해결해야 할 과제임.
또한 lambda 뿐만 아니라 다른 hyperparameter 의 tuning 도 영향을 미칠 것으로 생각된다. 예를 들면 VAE 의 모델 capacity 라거나 pseudo target, 즉 max Q value 을 계산할 때 sampling (decoding) 하는 action 의 개수 등 또한 task 마다 성능을 좌지우지 할 것으로 생각된다. 특히 VAE 를 학습하여 사용할 경우 여전히 out-of-dataset action 을 생성할 수 있고 이것이 extrapolation error 를 야기할 수 있기 때문에 task 마다 점검이 필요하다. 마지막으로 상대적으로 complex task 에 대해서는 test 가 이루어지지 않았다는 점도 한계점 및 향후 작업으로 생각될 수 있다.
