[Paper Review] Recurrence resonance - noise-enhanced dynamics in recurrent neural networks
Paper Review
Recurrence resonance - noise-enhanced dynamics in recurrent neural networks
This paper introduces Recurrence Resonance (RR), where adding optimal white noise enhances the mutual information () between consecutive states, reflecting improved internal information flow. Using Symmetric Boltzmann Machines (SBMs) with varied weight matrices (random, Autapses-only, Hopfield, NRooks), the study shows that RR occurs in systems with multiple pre-existing attractors (fixed points, n-cycles) when trapped in one without noise. Optimal noise r_opt enables exploration of these attractors, increasing entropy () and , while excessive noise disrupts predictability, reducing .
What does it mean that adding noise
it means adding random signals (white noise, drawn from ) to each neuron in the recurrent neural network (RNN). Specifically:
- Noise is introduced via in the input equation , where controls its strength too explore how noise affects the network’s dynamics and information processing. While noise is typically seen as disruptive, the paper shows it can enhance information flow under specific conditions, a phenomenon (RR)
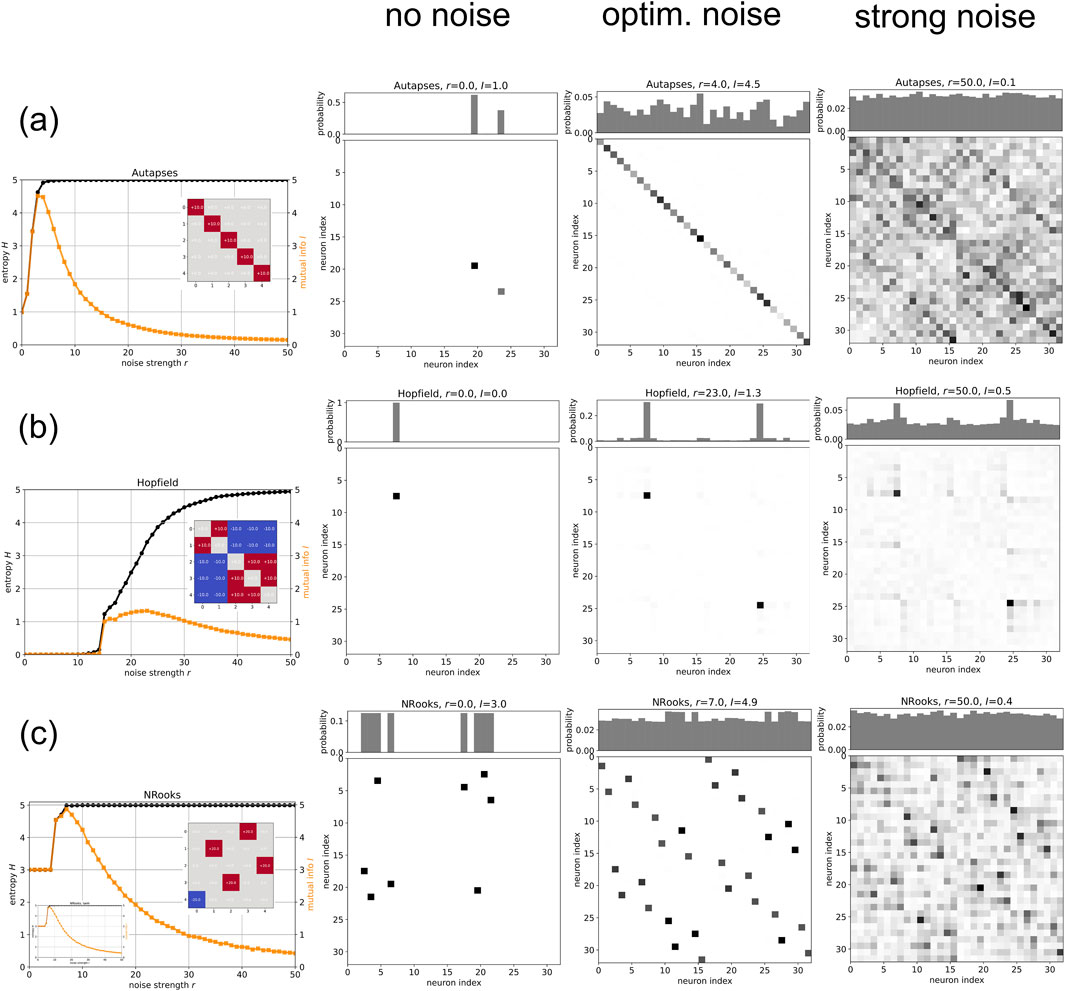
- Continuous noise was applied in most experiments, with strength varied to observe changes in entropy , mutual information , and divergence (Figures 1, 2).
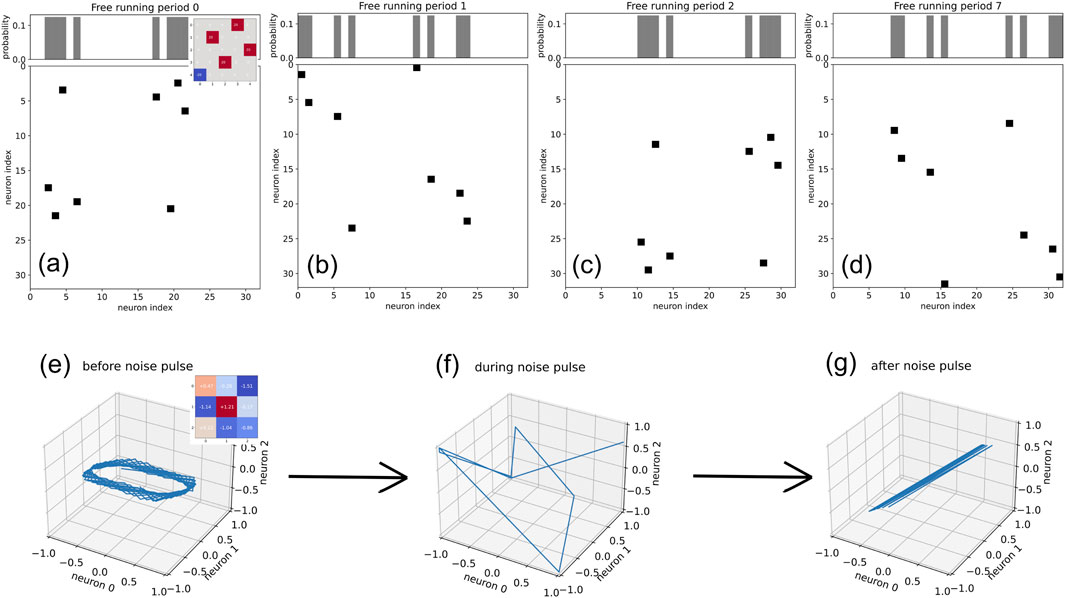
- Short noise pulses were also tested to switch attractors
Noise enables the exploration of already-existing multiple attractors
- Multiple attractors (e.g., fixed points, n-cycles) are predefined by the weight matrix and the network’s dynamics before noise is added (Section 3.1). Noise doesn’t create new attractors but allows the system to transition between them (Section 4).
- Without noise (), the system is trapped in one attractor; with optimal noise (), it visits more pre-existing attractors. Excessive noise () randomizes transitions without forming new attractors
method to confirm that the system visits multiple attractors
They confirmed it using joint probability distributions and information-theoretic measures:
- Joint Probability : Calculated from state time series over steps, visualized as matrices (Figures 1D-F, 2 columns 2-4).
- r = 0: Few states visited (trapped in one attractor).
- r = r_opt: More states visited, clustered around attractors.
- r = 50: Nearly all states visited randomly.
- Information Measures:
- Entropy : Measures state diversity (Equation 4).
- Mutual Information : Measures predictability between states, peaking at r_opt
- Divergence : Indicates randomness.
- State Transition Graphs: Showed preferred paths forming attractors as increases
- Specific Tests: Confirmed in Autapses-only (32 fixed points), Hopfield (2 fixed points), and NRooks (4 8-cycles) via patterns
What kind of prior learning process allowed multiple attractors to already exist?
No explicit learning process was used; multiple attractors exist due to the weight matrix and inherent dynamics, not training.
- Mechanism:
- is predefined (randomly or structurally), and the RNN’s feedback loops naturally form attractors like fixed points or cycles (Section 1, 2.1).
- Example: Large creates stable attractors; small leads to randomness (Section 3.1.1).
- No Training: Unlike supervised learning, attractors emerge from the system’s autonomous dynamics (e.g., NRooks’ permutation-like ensures cycles, Section 3.2.3).
- Exception: Hopfield’s was designed to store two patterns, implying a minimal "learning" setup, but this was pre-set, not trained in the study (Section 3.2.2).
- Conclusion: Attractors are a mathematical consequence of and dynamics, assumed to exist for studying noise effects (Section 4).
Weight matrix design (Random, Autapses-only, Hopfield, NRooks)
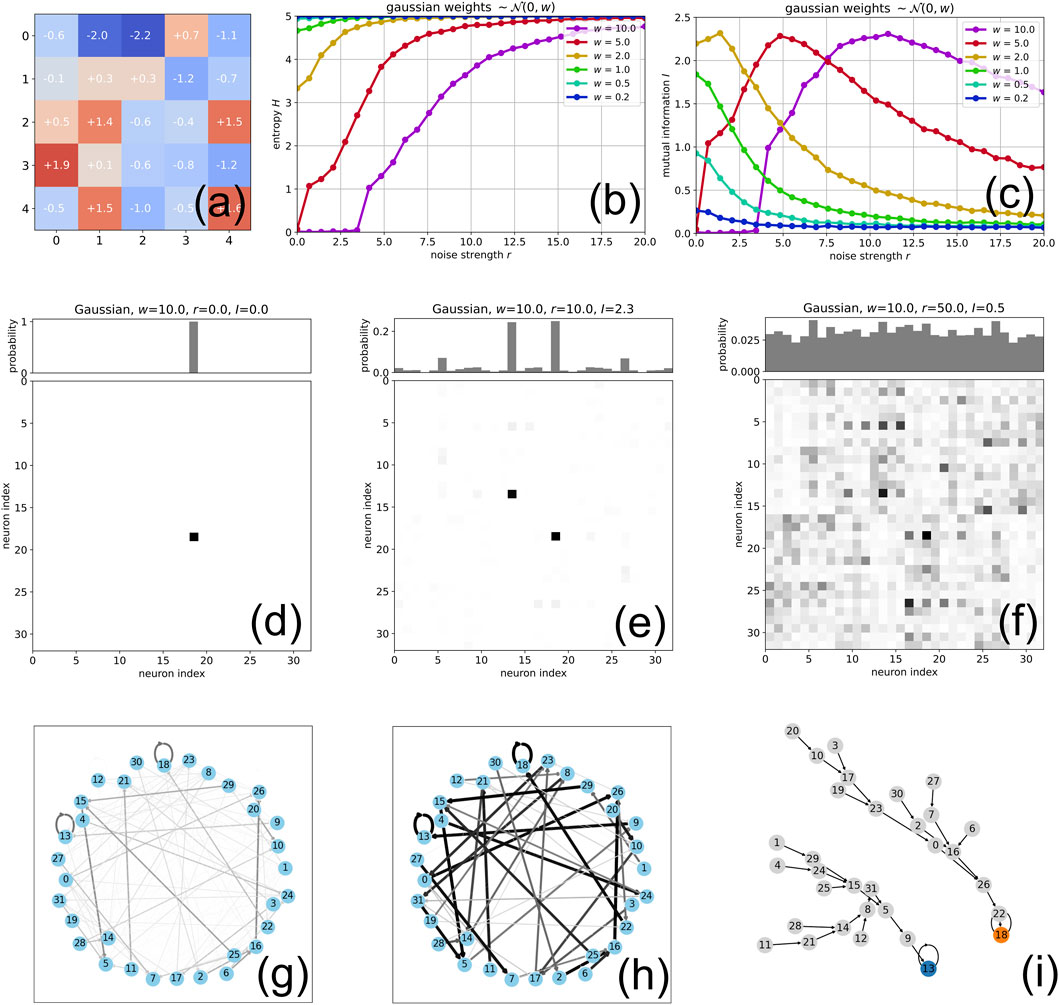
Random Gaussian Matrix
- Design: , scaled by (Section 3.1, Figure 1A).
- Attractors:
- Small : No clear attractors (random walk).
- Large : Fixed points or cycles (e.g., Figure 1I shows 2 fixed points at ).
- Effect: Noise shifts from one attractor () to multiple (), then randomness ().
Autapses-only
- Design: Diagonal , others 0 (Section 3.2.1, Figure 2A).
- Attractors: 32 quasi-stable fixed points (5 neurons, ), each neuron persists independently.
- Plot (Figure 2A):
- : , (2 points).
- (optimal): , (all points visited).
- : , (random transitions).
Hopfield
- Design: Symmetric, stores two patterns (24, 7), no self-connections (Section 3.2.2, Figure 2B).
- Attractors: 2 stable fixed points corresponding to stored patterns.
- Plot (Figure 2B):
- : , (trapped in 24).
- (optimal): , (both visited).
- : increases, drops slightly.
NRooks
- Design: One non-zero () per row/column (Section 3.2.3, Figure 2C).
- Attractors: 4 stable 8-cycles (32 states organized into cycles).
- Plot (Figure 2C):
- : , (one cycle).
- (optimal): , (all cycles).
- : , decreases (randomness).
