[Paper Review] Self supervised contrastive learning for digital histopathology
Paper Review
Self supervised contrastive learning for digital histopathology

Introduction
SSL method의 다양한 hyperparameter를 바꾸고 histopathology에 적용하여 실험을 진행한 논문이다. SimCLR 을 사용했으며 downstream task - classification, segmetnation, regression - 을 통해 pretrain domain, pretrain image 개수, downstream 시 labeled image 비율, optimizer, resolution, augmentation (특히 color jittering 및 random resize crop), pretrain backbone architecture 등 다양한 실험 조건을 적용하여 결과를 리포트 하였다.
Method
SimCLR 에서 NT-Xent loss 를 언급하고 있다.
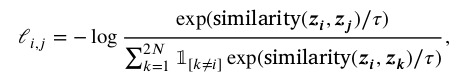
또한, contrastive method 는 image patch 간의 slient feature 를 학습하기에, pretraining 시 samples 이 같은 dataset으로부터 construct 되는 것 보다 다양한 dataset 으로부터 추출되는 것이 더 좋은 representation 을 학습할 수 있을 것이라 설명한다. (그리고 이를 증명한다.)

Experiments
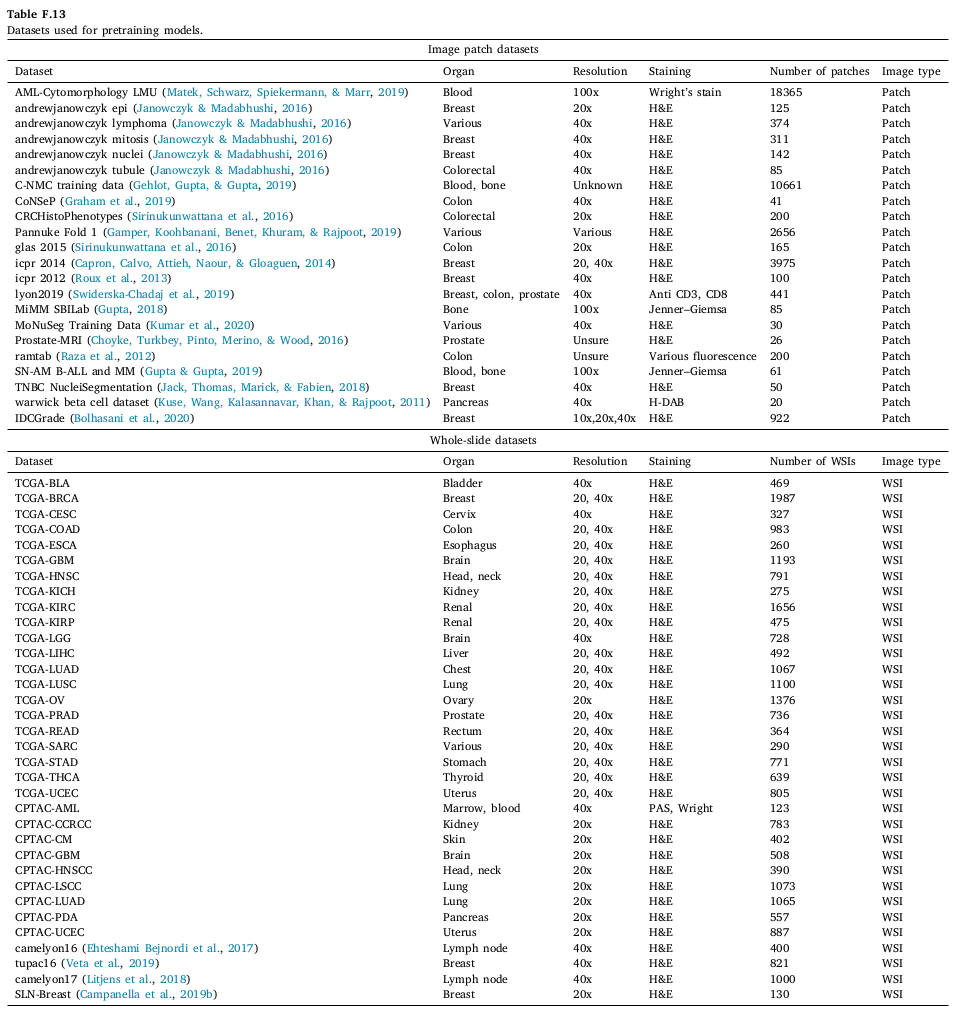
Pretraining datasets
길게 설명되어 있지만, supplement 의 table 하나로 설명된다. 총 57개의 dataset 중 22개는 image patch 로만 이루어진 dataset 이고, 나머지는 TCGA, CPTAC와 여러 challenge 에서 사용된 WSI 들로 구성되어 있다. 20x 부터 100x 까지 23개 장기에 대한 다양한 patch 와 slide 가 존재한다. (총 개수는 언급되지 않았음. 하지만 세어보면 대략 patch 4만장 + WSI 1만장 정도)
Validation datasets
pretrain 후 다섯 개의 dataset 으로 classification, 두 개의 dataset 으로 segmentation, 하나로 regression task 를 진행하였다.
classification - BACH (4, breast), Lymph (3, lymph), BreakHisv1 (2, breast), NCT-CRC-HE-100K (9, colorectal), Gleason2019 (5, prostate)
segmentation - BACH (4, breast), DigestPath2019 (2, colon)
regression - BreastPathQ (percentage cancer cellularity score to a given image patch, breast)
Validation tasks & setup
COMPARE with 1) randomly initialized 2) ImageNet pretrained / in Resnet 18, 34, 50, 101
training settings: 1) fine-tuning, 2) last layer 제외 freeze(seg 제외) supervised learning
++ pretrained feature 를 이용한 clustering, feature selection ,,,
100 epochs per experiment, Adam optimizer, batch size 128
training 50%, validation 25%, test 25%
Results
따로 모델 아키텍쳐가 쓰여있지 않으면 Resnet18로 학습된 결과이다.
50만장의 224 x 224 pixel image patch 를 1000 epoch 학습 시키는데 24시간 걸린다.
fine-tuning
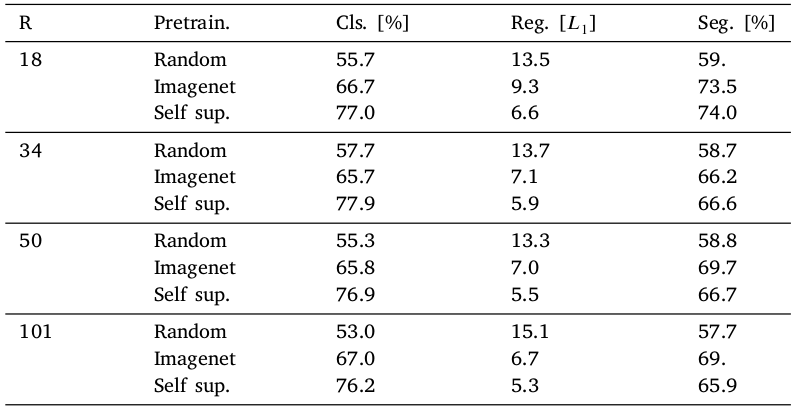
전반적으로 Self sup. setting 에서 가장 성능이 좋았다. 다만 Resnet 50, 101 segmentation 상황에서는 Imagenet pretrain 성능이 높았다.
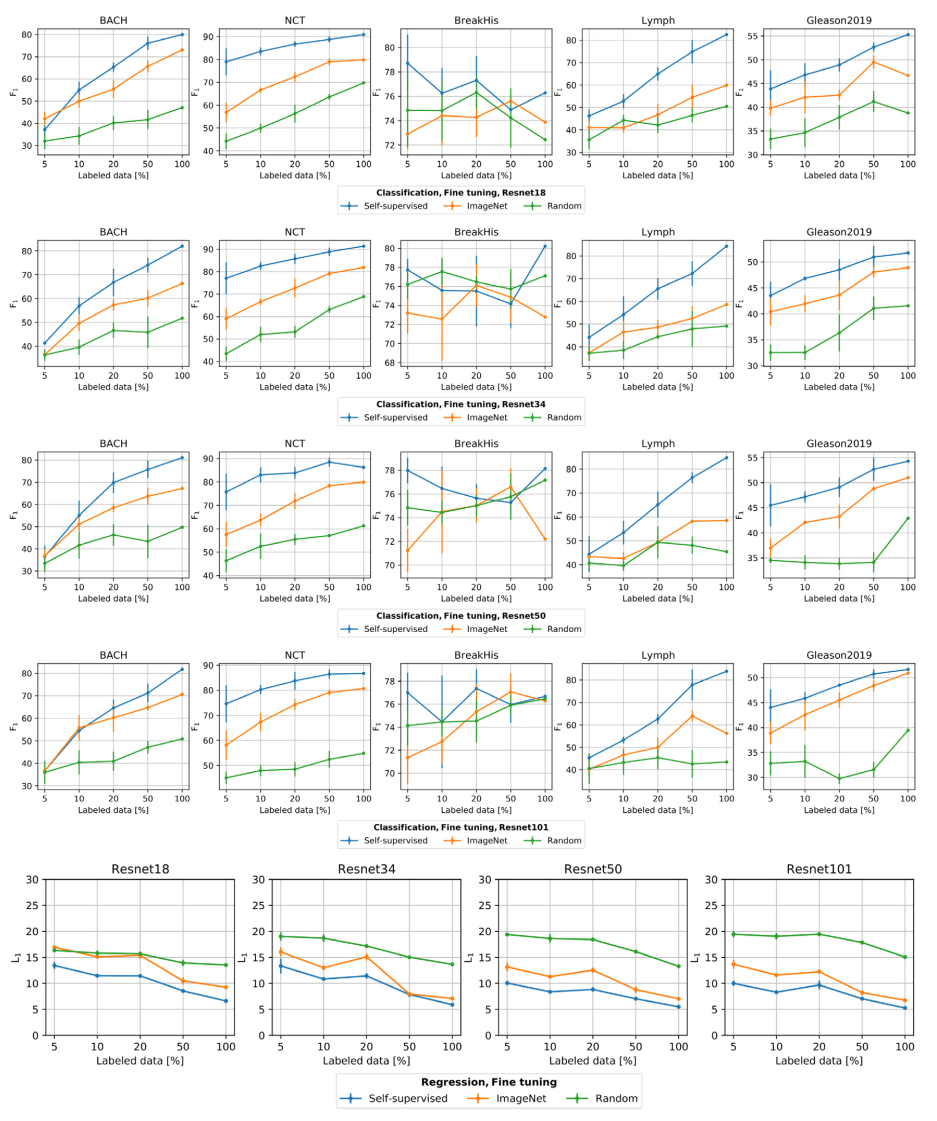
또한 supervised learning setting 에서 labeled data 가 "적을 때" SSL 성능이 다른 방법 (random=from scratch, Imagenet pretrained) 에 비해 크게 높았다. 저자는 NCT 를 예로 들며 설명하였다.
freeze
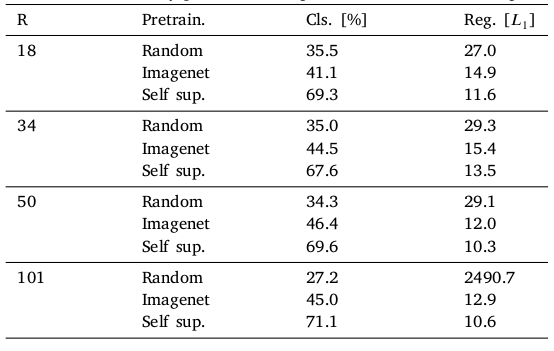
위 테이블의 모든 task, condition 에서 SSL 방식을 사용했을 때 성능이 가장 좋았다.
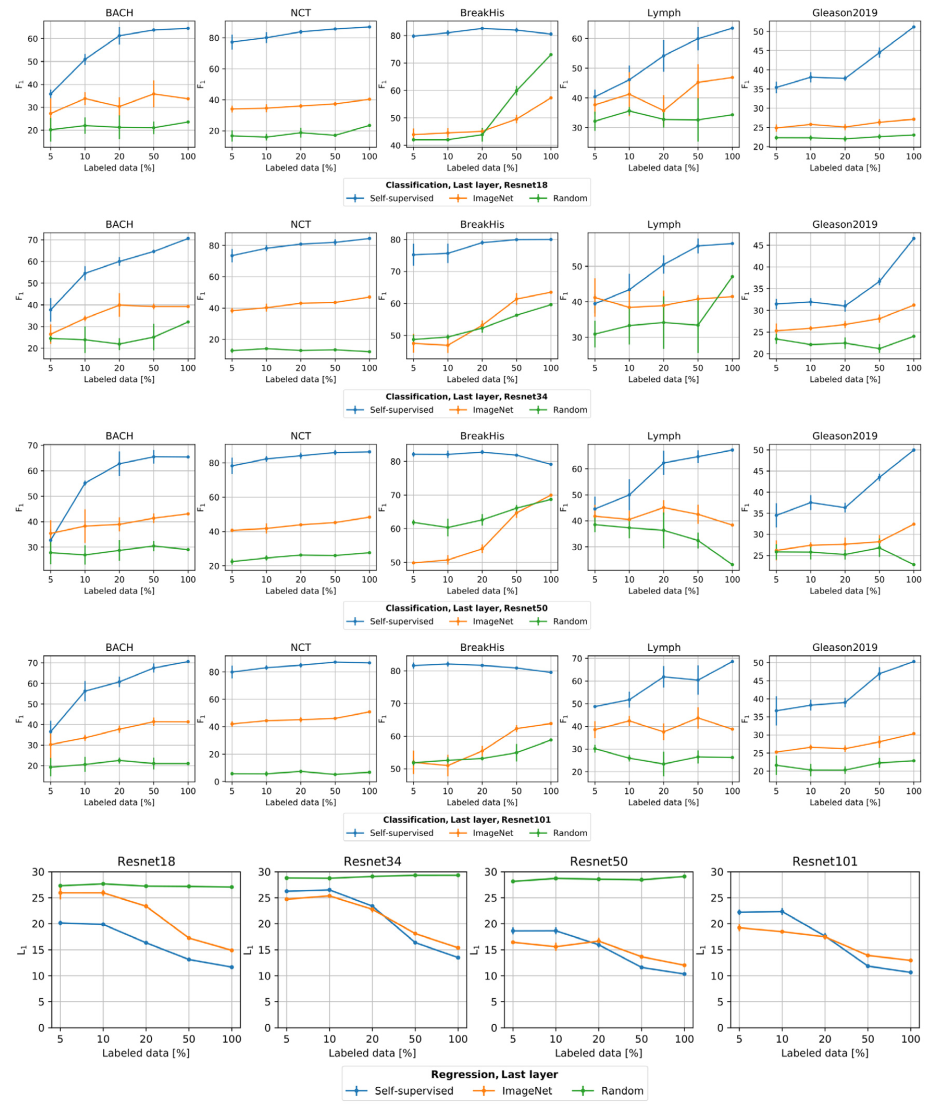
segmentation 의 경우 따로 freeze experiment 결과를 리포트 하지는 않았다. (since a decoder can contain millions of parameters that can be trained to achieve satisfactory performance regardless of the encoder weights.)
unsupervised clustering using the learned representations
learned representation can also be used for querying an image to its nearest neighbors without clustering the dataset, which is useful in applications such as active learning for sample selection and various data retrieval systems.
randomly sampling patch 방식은 class imbalance 문제를 야기할 수 있기 때문에 representative patches 를 뽑기 위해 clustering 좋다. 특히 저자는 69 WSI 로부터 1.4 million image patch 를 뽑고, 3000개의 cluster로 데이터를 나누었다. (Elbow heuristic 방식을 이용해 1000, 1500,,, 10000 중 3000 선택) 그 방식으로 mini-batch K-means algorithm 을 사용하였다.
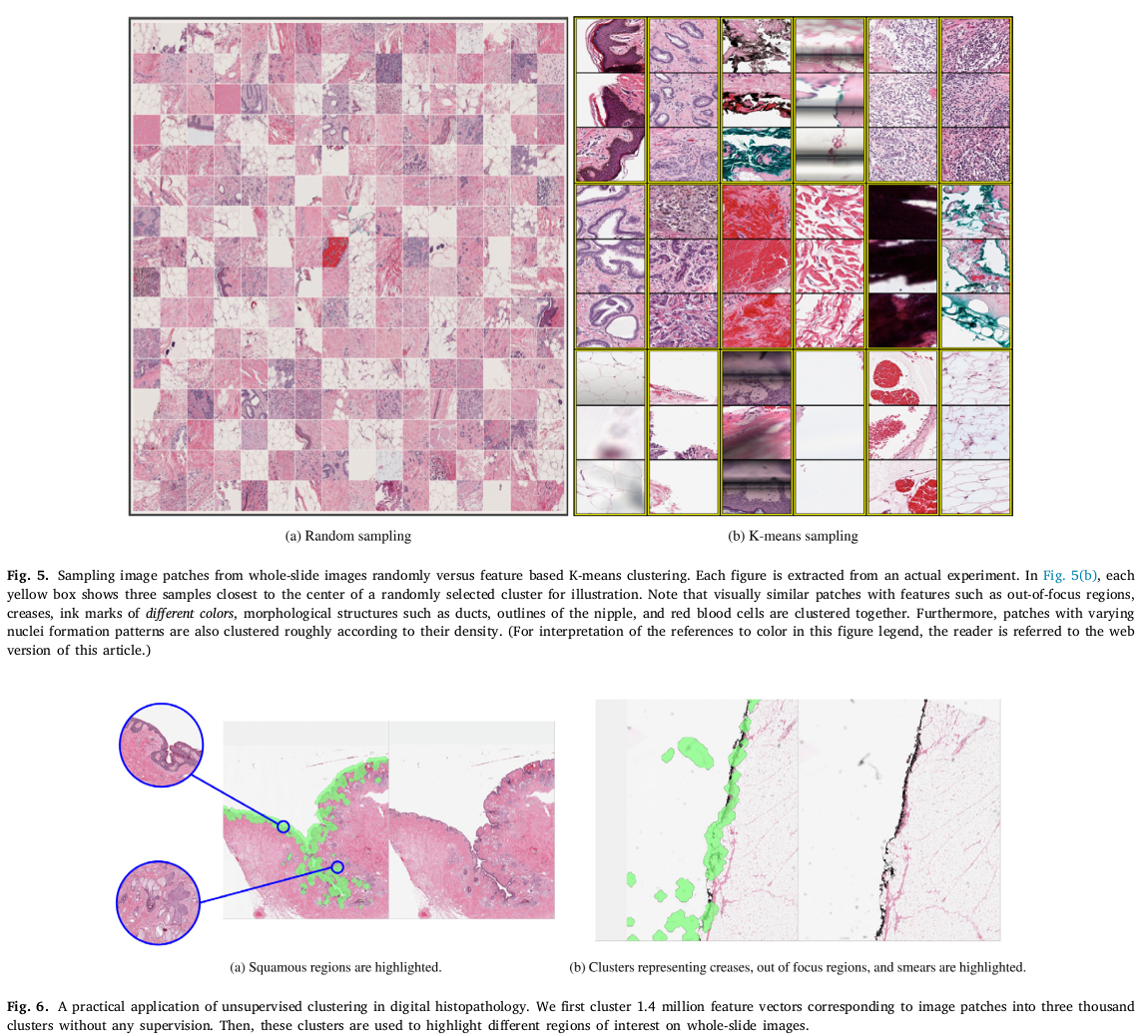
figure 6 에서, 약간의 cluster 를 뽑아 highlight 했더니 any supervision 없이 segmentation 도 어느정도 되었다고 주장한다.
pretrain 시 image patch 개수와 resolution 바꿔서 실험
1) 0.01, 0.1, 1, 10% 의 image 만을 사용해 pretrain
2) IDCGrade (breast, 10x, 20x, 40x, 922 patches ??) 로 pretrain
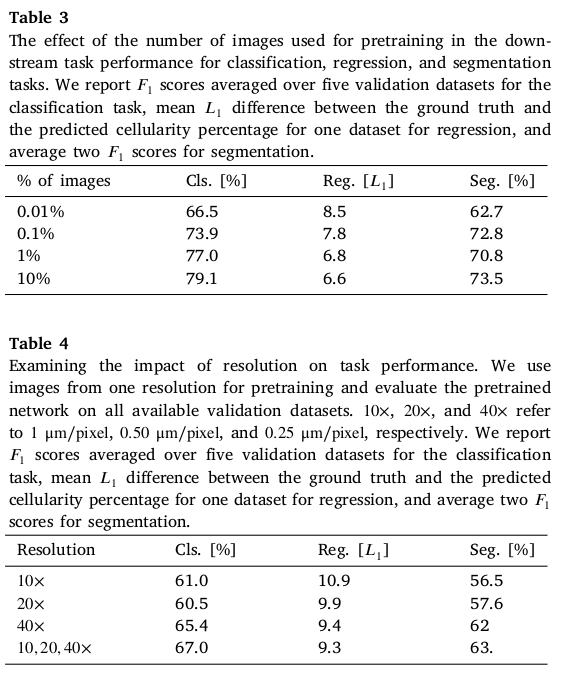
더 많은 데이터를 사용해 pretrain 할 수록 성능이 좋았고, 더 높은 resolution data로 학습했을 때 성능이 더 좋았다. 물론 다양한 resolution을 이용해 학습했을 때가 성능이 제일 좋았다.
transferability of features between tissue types and staining
breast, lymph node, prostate 모두 4000개 정도씩 사용.
breast: TCGA-PRAD, TUPAC16, TNBC, ICPR,,, / lymph nodes: Camelyon 16, 17 / prostate: Prostate-MRI

site-specific pretraining 에도 불구하고, pretrained model 과 validation performance 사이의 strong correlation 은 관찰되지 않았다. 또한, 가장 첫번째 table 의 결과 (77, 6.6, 74) 와 비교했을 때, 특정 domain 에 대해 실험한 결과보다 성능이 떨어졌다.

hyperparameter and suitable augmentation selection
(여기부턴 supplment 에 나와있는 내용으로, 위 result 에 공통적으로 들어가는 setting 이다.)
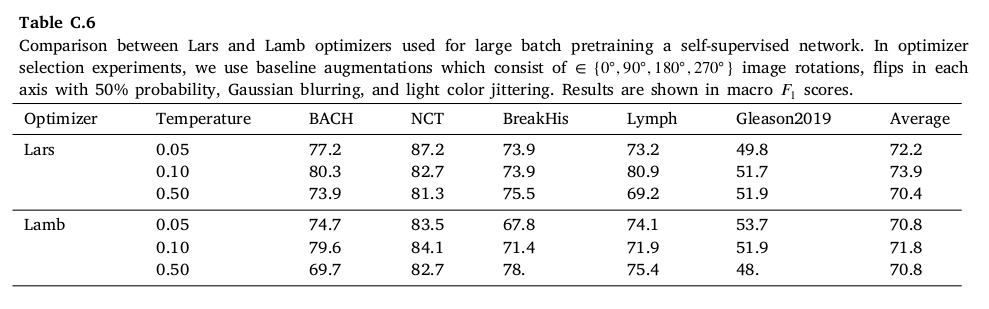
optimizer and temperature
pretraining 과정에서 Adam + batch size>256 세팅으로 했을 때 converge 하지 않았고, Lars 가 Lamb 보다 성능이 조금 더 높게 나왔으며, smaller temperature 에서 학습이 전반적으로 더 잘 나오는 것을 확인하였다.
augmentation
사용한 augmentation 기법은, randomly resized crops, 90 rotation, flips, color jittering, Gaussian blurring 을 사용하셨고, 그 중 특히 color jittering 과 random resize crop 조건을 달리하여 실험을 진행하였다. color jittering 조건 light, medium, heavy 는 각각 (brightness, contrast, saturation, hue) 기준 (0.4 0.4 0.4 0.2) (0.8 0.8 0.8 0.2) (0.8 0.8 0.8 0.4) 을 의미한다. randomly resize crop 의 퍼센트는 그만큼의 patch size로 crop 했다는 뜻이다.
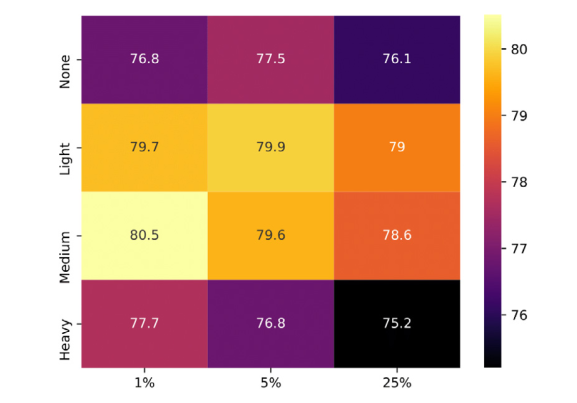
결과 더 강한 augmentation 이 적용될 수록 성능도 높아졌다. 심지어 1% random resize crop 은 224 x 224 pixel 기준 20 x 20 pixel 만 가져온 것임에도 불구하고, 다른 random resize crop 비율 실험보다 성능이 더 높았다...
Conclusion
방대한 양의 데이터셋과 여러 조건을 바꿔 SSL 로 실험한 노력이 대단한 .. 논문이었다. 논문에선 no prior research on histopathological image analysis with a ... consistently reaches or surpasses supervised training. 이라고 하는 걸 보면.. 정말 방대한 양을 썼긴 했나보다. 는 생각이 든다. SSL 방식을 사용할 때 어떤 setting 을 사용할지 고민하다가 찾은 논문인데 대신 여러 실험을 진행해줘서 참고할 때 좋을 것 같아 고마운 생각도 들었다. 암튼 굿.
