[Paper Review] Task representations in neural networks trained to perform many cognitive tasks
Paper Review
목록 보기
46/60
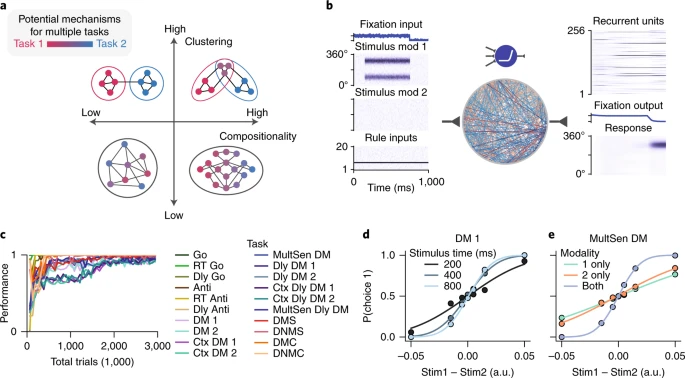
Task representations in neural networks trained to perform many cognitive tasks
-
task representation = RNN weights when performing specific task (?)
-
task explanation and codes are in https://github.com/gyyang/multitask/blob/master/task.py
-
tasks at a glance - there are two modalities of stimulus


-
learn multiple tasks “sequentially” with continual-learning technique
- if there’s some ‘state’ in each task, would there be replay memory?
- is there any biased results on the “sequence” of the task?
- if tested it will take all permutations of that all tasks…
-
RNN model: just one hidden layer & non-negative (with 256 units)
- and calculated task variance. also clustering across units.
- didn’t read much about how they did clustering and clean out the noise
- and calculated task variance. also clustering across units.
-
32 ring (direction-specific recurrent unit)
- how is is possible to force them response to specific directions??
-
(just cameout) one paper using fMRI
- complexity defined as number of choices (but the same task family unlike us)
- more complex task → people tends to do model-based thinking
- https://www.nature.com/articles/s41467-019-13632-1
-
in line with above paper, I think we should think about each task’s complexity
- what amount information (or dimension) should be sufficient for correct answer?
- ‘amount’ and ‘dimension’ → complexity (how does it combine?)
-
task vector
- why do they use only “steady-state” response across stimulus?
- they can’t capture the task variance (sensitive unit activity…)
- how about trying DSA like https://github.com/mitchellostrow/DSA
- I don’t know
- how to combine the ‘task variance’ to this?
-
task vector 2
- tho it’s cool that there could exist algebraic form of compositional representation
-
rule compositionality (combination of rule inputs!!!)
- most important part of this paper
- Dly Anti task = Anti + (Dly Go - Go)
- but failed in DMS != DMC + DNMS - DNMC
- can we use multiplication or convolution??https://neuroai.neuromatch.io/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.html
-
a bit of continual learning
- Dly GO → Ctx Dly Dm1, Ctx Dly DM2 ----- forget Dly Go
- added “penalty for deviations of important synaptic weights” ~ regularizer
-
I didn’t look through much about
- how they clustered
- how they analyzed with different activation functions (tanh, ,,,)
- how they did continual learning (method, regularizer part)

https://jaeheon-lee486.github.io/