https://www.sciencedirect.com/science/article/abs/pii/S002002552400567X
기초 개념 정리
시계열 데이터는 여러 방식으로 분류될 수 있는데, 그중 맥락(Contextual), 시간(Temporal), 변환(Transformation)이라는 개념이 있다. 논문을 읽기 전에 각각의 차이점을 알아 보았다.
1. 맥락(Contextual) 시계열 데이터
- 특정한 사건이나 환경적 요인에 따라 해석이 달라지는 데이터.
- 같은 패턴이더라도 맥락에 따라 의미가 다를 수 있음.
특징
- 외부 요인의 영향을 크게 받음 (예: 날씨, 정책 변화 등).
- 같은 데이터 패턴이더라도 시점이나 상황에 따라 다른 해석이 가능.
- 이상치(outlier)가 특정 맥락에서만 의미를 가질 수 있음.
예시
- 소매업 매출 데이터: 블랙 프라이데이, 설날과 같은 특정 이벤트가 있는 기간에는 매출이 급증하지만, 이는 정상적인 패턴으로 간주될 수 있음.
- 교통량 데이터: 출퇴근 시간에는 차량이 몰려 교통량이 많아지지만, 같은 교통량이 한밤중에 발생하면 사고나 도로 공사와 같은 특수한 상황을 의미할 수 있음.
2. 시간(Temporal) 시계열 데이터
- 시간의 흐름에 따라 구조적 변화가 발생하는 데이터.
- 과거와 현재의 관계를 분석하여 미래를 예측하는 데 사용됨.
특징
- 계절성(Seasonality), 추세(Trend), 순환성(Cyclic) 등의 패턴을 가질 수 있음.
- 데이터의 특정 시점이나 기간에 따른 패턴 변화를 분석하는 것이 중요함.
- 일반적으로 시계열 예측 모델(ARIMA, LSTM 등)에 활용됨.
예시
- 기온 변화 데이터: 계절에 따라 여름에는 온도가 높고 겨울에는 낮아지는 추세를 보임.
- 주식 시장 데이터: 특정 주기의 변동성을 보이며, 장기적인 상승 또는 하락 추세를 가질 수 있음.
- 전력 사용량 데이터: 낮과 밤, 계절별로 전력 사용량이 달라지는 경향이 있음.
3. 변환(Transformation) 시계열 데이터
- 원본 데이터에 특정 연산을 적용하여 새롭게 변환된 데이터.
- 노이즈 제거, 데이터 정규화, 차분(Differencing) 등의 기법이 사용될 수 있음.
특징
- 분석이나 모델 학습을 용이하게 하기 위해 데이터 형태를 변경함.
- 로그 변환, 이동 평균, 차분 등의 기법을 활용하여 패턴을 보다 쉽게 분석 가능하게 함.
- 원본 데이터보다 특징이 부각되거나 새로운 의미가 부여될 수 있음.
예시
- 로그 변환(Log Transformation): 주식 가격처럼 값의 변동 폭이 큰 데이터에 로그를 취하여 변동성을 줄이고 안정적인 패턴을 찾음.
- 차분(Differencing): 시계열 데이터의 추세(Trend)를 제거하여 정상성(Stationarity)을 확보하고 예측 모델에 활용함.
- 이동 평균(Moving Average): 단기 변동성을 제거하고 장기적인 흐름을 분석하기 위해 사용됨.
요약
| 유형 | 특징 | 예시 |
|---|---|---|
| 맥락(Contextual) | 특정 맥락(환경, 이벤트)에 따라 해석이 달라지는 데이터 | 소매업 매출 (명절, 블랙 프라이데이), 교통량 (출퇴근 시간) |
| 시간(Temporal) | 시간 흐름에 따라 변하는 구조적 패턴이 있는 데이터 | 기온 변화, 주식 시장 변동, 전력 사용량 |
| 변환(Transformation) | 분석을 용이하게 하기 위해 원본 데이터에 변환을 가한 데이터 | 로그 변환(주식 가격), 차분(추세 제거), 이동 평균(노이즈 감소) |
개요
이 논문은 자기 지도 학습(self-supervised learning, SSL)을 활용하여 시계열 데이터의 표현 학습(representation learning)을 수행하는 새로운 방법을 제안함.
특히, 다중 작업 학습(multi-task learning)을 적용하여 시계열 데이터를 더 효과적으로 표현할 수 있도록 설계함.
-
배경 및 문제점
-
레이블링된 데이터는 적고 레이블링되지 않은 데이터는 많을 때, contrastive learning이 좋은 성능을 보여줌.
대조 학습(contrastive learning): 유사한 샘플은 가깝게, 다른 샘플을 멀리 배치하는 방식으로 latent space를 학습하는 방식. ex) 개, 고양이 이미지 -> [개1, 개2, 개3, --------------------고양이1, 고양이2, 고양이3] 처럼 유사한 데이터는 가깝게, 다른 데이터는 멀게.
잠재 공간(latent space): 데이터의 중요한 특징(feature)들이 압축된 고차원적인 표현 공간. 원본 데이터보다 더 압축되고 의미 있는 표현을 가지면서도, 데이터 간의 관계를 잘 보존하도록 학습됨. ex) 1. 얼굴 이미지 데이터, 텍스트 데이터 -> embedding -> 얼굴 이미지를 "얼굴", "미소", "나이" 피처로 구분. 2. contrastive learning -> 유사한 데이터는 latent space에서 가까워지도록 다른 데이터는 멀어지도록 학습. 3. 1과 2를 거쳐 데이터의 주요 특징들이 효과적으로 잘 표현된(압축된) latent space를 얻을 수 있음.
-
기존 방법들은 긍정(positive) 쌍을 어떻게 구성하는지에 따라 표현 학습의 일관성 수준이 달라지는 문제가 있음.
-
-
제안하는 방법
- 맥락(Contextual), 시간(Temporal), 변환(Transformation) 일관성을 고려한 자기 지도 학습(self-supervised learning) 방식을 결합.
- 각 일관성 요소에 대해 대조 학습을 수행하고, 이를 합친 멀티태스킹 학습을 통해 최적화.
- 각 학습 목표의 기여도를 반영하기 위해 불확실성 가중치(uncertainty weighting)를 적용.
-
모델 구성
- 데이터 전처리: 긍정/부정 쌍을 생성하여 학습 데이터 준비.
- 세 가지 대조 학습 수행:
- 맥락적 대조 학습(Contextual Contrastive Learning)
- 시간적 대조 학습(Temporal Contrastive Learning)
- 변환 대조 학습(Transformation Contrastive Learning)
- Multi Tasking Learning: uncetainty weighting을 적용하여 위 task들의 기여도를 반영하며 학습.
-
실험 및 결과
- 다운스트림 task: time-series, classification, forecasting, and anomaly detection에 대해서 평가.
- 성능 향상: 기존 모델 대비 뛰어난 성능을 보이며, 도메인 간 전이 학습(cross-domain transfer learning)에서도 높은 효율성을 입증.
-
결론 및 의의
- 기존 시계열 표현 학습 방법보다 다양한 데이터 특징을 효과적으로 학습할 수 있는 모델을 제안.
- 맥락적, 시간적, 변환적 일관성을 모두 고려하는 자기 지도 학습 기법을 적용하여 범용성을 높임.
- 불확실성 가중치를 활용한 멀티태스킹 최적화 전략이 성능 향상에 기여함.
- 분류, 예측, 이상 탐지 등 다양한 작업에서 우수한 성능을 보이며, 도메인 전이 학습에서도 강력한 일반화 능력을 입증.
1. 소개
-
self-supervised learning은 적은 수의 데이터로 효과적인 모델 학습이 가능함. NLP에서는 많은 방법론이 존재하지만 시계열 데이터와 관련해서는 방법론이 적음.
Self-Supervised Learning(자기 지도 학습, SSL)은 데이터에서 레이블 없이 학습하는 방식. 즉, 사람이 직접 라벨(정답)을 달아주지 않아도, 모델이 자신만의 학습 목표를 생성하여 학습하는 방식. 예시: Contrastive Learning(비슷한 데이터는 가깝게, 다른 데이터는 멀리 배치하는 방식), Predictive Learning(데이터의 일부를 가리고, 이를 예측하도록 학습하는 방식), Gerative Learning(원본 데이터에서 새로운 데이터를 생성하는 방식)
-
대표적인 방법들로는 pretext task 기반 접근법과 contrastive learning 기반 접근법이 있음.
pretext task 예시.
- Masked Language Model (BERT): 문장에서 일부 단어를 마스킹하고 모델이 이를 예측 (ex: "I love [MASK] food.")
- Sequence Ordering: 동영상을 랜덤으로 섞어놓고, 원래 순서를 예측하도록 학습. ex) 영상 프레임 1-2-3을 2-1-3으로 바꾼 후 원래 순서 복원하도록 학습
- Rotation Prediction (회전 예측, RotNet): 이미지를 0°, 90°, 180°, 270°로 회전시킨 후, 원래 각도를 맞추도록 학습
-
pretext 기반 접근법은 다운스트림 태스크의 영향을 많이 받기 때문에 일반화하기가 어려움.
-
contrastive learning은 대조할 타겟과 loss function를 어떻게 정의함에 따라 각각 다름.
- T-Loss [13] mainly pursued the subseries consistency that encourages representations of the input time segment and its sampled sub-series to be close to each other.
- TNC [14] enforced temporal consistency of two adjacent time segments sampled from a temporal neighborhood using stationary properties.
- TS-TCC [16] explored transformation consistency by minimizing the distance between representations of two augmented views from a single time segment.
- TS2Vec [17] proposed a contextual consistency, which treats the same timestamps in two overlapping time segments as positive pairs.
-
위 모델들은 각각의 task에 대해서 잘 학습하지만, 다른 task에서는 좋은 성능을 보여주지 못한다. 따라서 본 논문에서는 multi-task 방식을 제안한다. (contextual + temporal + transformation)
First, contextual consistency [17] hierarchically discriminates positive and negative samples at the instance and timestamp levels to capture contextual information at multiple resolutions. Second, temporal consistency [14] encourages the local smoothness of representations by distinguishing time segments within the neighborhood from non-neighborhood ones. Third, transformation consistency [16] enforces the model to learn transformation-invariant representations by choosing time segments through two transformations as positive samples.
- Contextual Consistency (문맥 일관성)
- 인스턴스 및 타임스탬프 수준에서 양성(Positive)과 음성(Negative) 샘플을 구분
- 여러 해상도(Resolution)에서 문맥 정보를 학습
- Temporal Consistency (시간 일관성)
- 시간적 표현의 지역적 연속성(Local Smoothness) 유지
- 이웃 시간 구간(Neighborhood)과 비이웃 시간 구간(Non-Neighborhood)을 구별하여 학습
- Transformation Consistency (변환 일관성)
- 변환에 강인한(Transformation-Invariant) 표현 학습
- 서로 다른 두 가지 변환을 적용한 시간 구간을 양성 샘플(Positive Sample)로 설정하여 학습
이 세 가지 방법을 결합하여 다양한 다운스트림 작업(분류, 예측, 이상 탐지 등)에 적용할 수 있는 일반적인 시계열 표현을 학습함.
Finally, we simultaneously learn these three contrastive learning approaches to model various consistencies together in time-series data. To jointly learn various self-supervised tasks effectively, we investigate an uncertainty weighting approach [18] that can weigh multiple contrastive loss functions by considering the homoscedastic uncertainty of each task.
- 세 가지 대조 학습(Contrastive Learning) 방법을 동시에 학습하여 시계열 데이터의 다양한 일관성(Consistency)을 모델링.
- 여러 자기 지도 학습(Self-Supervised Learning) 과제를 효과적으로 결합하기 위해 불확실성 가중치(Uncertainty Weighting) 기법 적용. -> (Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics 논문 참고)
2. 관련 연구
2.2 Self-Supervised Time-Series Representation Learning
1. T-Loss (Time-series Loss)
구성 및 동작 원리:
- 목적: 시계열 데이터에서 하위 시퀀스의 일관성을 학습하여 시간적인 패턴을 포착함. 예를 들어, 주식 데이터에서 특정 구간의 패턴이 다른 시점에서도 비슷하게 나타나는지를 학습함.
- 예시:
- 주식 가격 데이터를 생각해 봅시다. 하루의 가격 변화가 다른 날에도 비슷한 패턴을 보일 수 있음. 예를 들어, 주식이 급락하고 급등하는 패턴이 반복된다면,
T-Loss는 이러한 하위 시퀀스(예: 1시간 동안의 급락과 급등 패턴)를 양성 샘플로 보고, 다른 날의 다른 급락 패턴을 음성 샘플로 비교하여 학습함.
- 주식 가격 데이터를 생각해 봅시다. 하루의 가격 변화가 다른 날에도 비슷한 패턴을 보일 수 있음. 예를 들어, 주식이 급락하고 급등하는 패턴이 반복된다면,
학습 과정:
- 양성 샘플: 예를 들어, "2023년 1월 1일 10시부터 11시까지"의 주식 가격 하위 시퀀스가 양성 샘플로 설정됨. 이 구간의 패턴이 같은 인스턴스 내에서 비슷한 다른 구간과 비교됨.
- 음성 샘플: "2023년 1월 2일 10시부터 11시까지"와 같은 다른 주식 데이터의 하위 세그먼트가 음성 샘플로 설정되어, 그 차이를 학습함.
2. TNC (Temporal Neighborhood Contrastive Learning)
구성 및 동작 원리:
- 목적: 시계열 데이터에서 시간적 이웃(nearby segments)의 패턴을 구별하여, 시계열의 인접 구간이 비슷하다는 일관성을 학습함.
- 예시:
- 날씨 데이터에서 "2023년 1월 1일 12시부터 1시까지"와 "12시부터 1시 30분까지"의 온도 변화 패턴은 비슷할 수 있음. 따라서
TNC는 두 시간대가 가까운 이웃 관계에 있다고 보고, 이들이 양성 샘플이 되도록 학습함. - 반면, "2023년 1월 1일 5시부터 6시까지"의 온도 변화는 전혀 다른 패턴을 보일 수 있으므로 이를 음성 샘플로 설정하여 학습함.
- 날씨 데이터에서 "2023년 1월 1일 12시부터 1시까지"와 "12시부터 1시 30분까지"의 온도 변화 패턴은 비슷할 수 있음. 따라서
학습 과정:
- 양성 샘플: 동일한 시간적 이웃 내에서 발생한 시퀀스들이 양성 샘플로 처리됨. 예를 들어, 하루 중 연속된 시간대의 온도 변화 패턴이 유사할 것으로 가정함.
- 음성 샘플: 이웃이 아닌 시간대, 예를 들어 하루와 밤의 온도 차이를 음성 샘플로 설정.
3. TS-TCC (Time-Series Twin Contrastive Coding)
구성 및 동작 원리:
-
목적: 시계열 데이터의 다양한 변환에 불변하는(Transformation-Invariant) 표현을 학습하여, 다운스트림 작업에서의 일반화를 향상시킴.
-
예시:
- 자동차 속도 데이터를 예로 들면, "2023년 1월 1일 10시부터 11시까지"의 속도 데이터를 약한 변환(예: 구간 길이에 따른 조정)과 강한 변환(예: 날씨 상태에 따른 변화)으로 증강 가능함.
TS-TCC는 이러한 두 가지 변환된 뷰가 동일한 시간대에 대한 일관된 표현을 학습하도록 함.
- 자동차 속도 데이터를 예로 들면, "2023년 1월 1일 10시부터 11시까지"의 속도 데이터를 약한 변환(예: 구간 길이에 따른 조정)과 강한 변환(예: 날씨 상태에 따른 변화)으로 증강 가능함.
-
구성:
- 두 개의 대조 모듈(Contrasting Modules): 약한 변환(Weak Augmentation)과 강한 변환(Strong Augmentation)을 적용하여 두 가지 뷰(View)를 생성.
-
학습 과정:
- 첫 번째 모듈: 교차 예측(Cross-View Prediction)을 수행하여, 약한 변환과 강한 변환 간의 일관된 표현을 학습함.
- 두 번째 모듈: 두 변환된 뷰의 표현 간 유사성을 최대화하여, 변환에 불변하는 특징을 학습함.
- Negative 샘플: 배치 내의 다른 인스턴스에서 생성된 변환된 뷰
4. TS2Vec (Time-Series Two-View Contrastive Learning)
구성 및 동작 원리:
- 목적: 시계열 데이터의 다른 문맥(context)을 학습하여, 동일한 시간에 여러 문맥에서 유사한 패턴을 학습함.
- 예시:
- 자동차의 속도 데이터를 예로 들면, "2023년 1월 1일 10시부터 11시까지"의 데이터를 증강하여, 동일한 시간대의 속도 데이터를 두 가지 방식으로 변환할 수 있음. 첫 번째 변환은 온도에 따른 속도 변화 패턴을 강조하고, 두 번째 변환은 도로의 경사도를 반영한 패턴을 강조.
TS2Vec는 동일한 타임스탬프의 두 변환된 속도 데이터가 양성 샘플로 설정되고, 다른 인스턴스의 속도 데이터는 음성 샘플로 학습.
학습 과정:
- 첫 번째 대조 학습: 동일한 타임스탬프에서 두 증강된 세그먼트의 표현을 양성 샘플로 설정. 예를 들어, 도로의 경사도에 따른 속도 패턴과 시간대에 따른 속도 패턴을 비교하여 학습.
- 두 번째 대조 학습: 배치 내 다른 인스턴스에서 나온 타임스탬프의 표현을 음성 샘플로 설정하여, 서로 다른 시간대의 속도 패턴을 구별.
3. 방법론
-
unlabeled time-series data에 대해서 맥락(Contextual), 시간(Temporal), 변환(Transformation) 일관성을 고려하여 모델 학습.
-
이전 연구들의 과정을 따라가며, multi-task learning의 일부는 수정함.
3.1 모델 구조
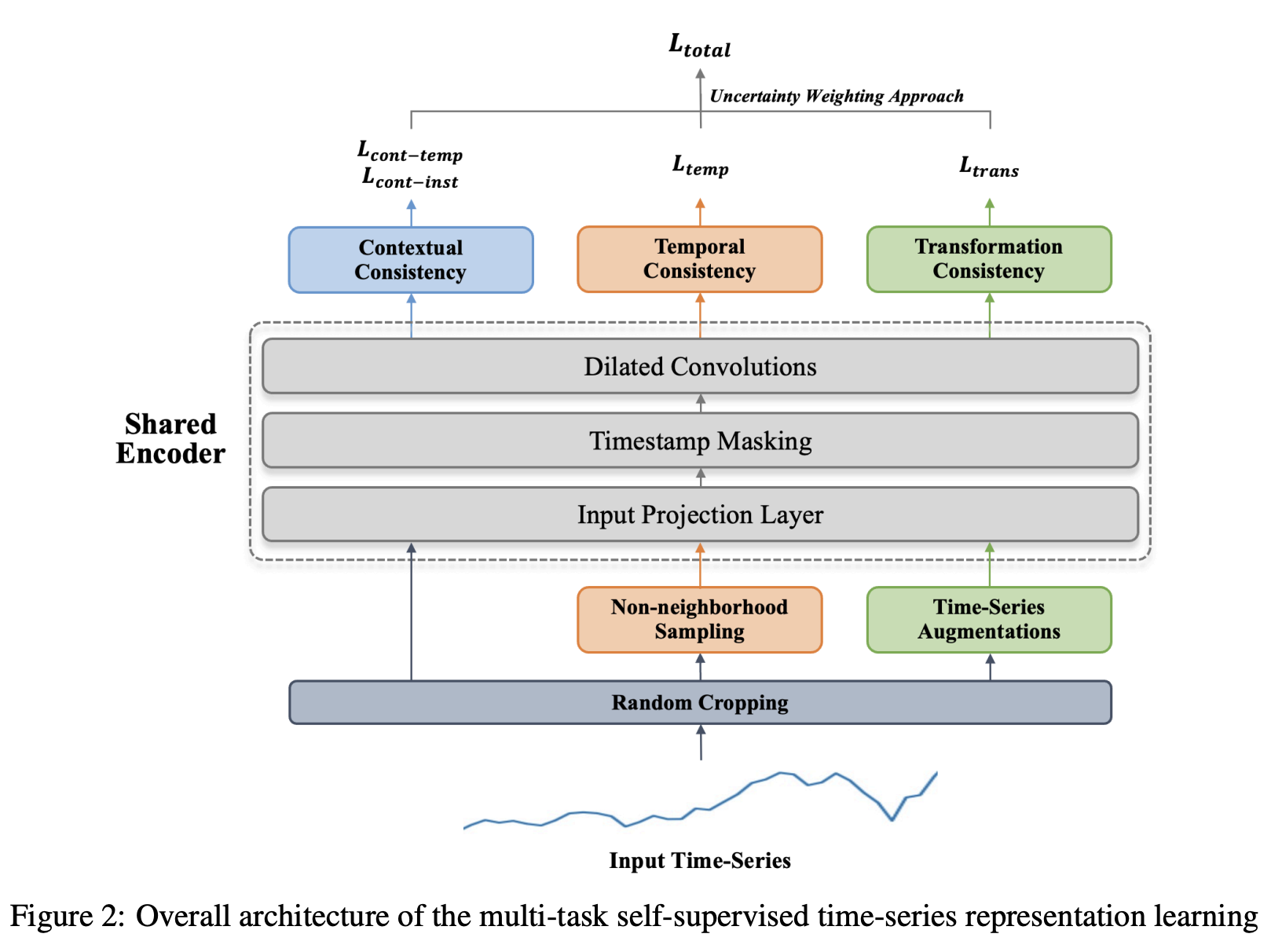
전체 동작 흐름
1. 데이터 전처리: 입력된 시계열 데이터에 두 개의 겹치는(time overlapping) 시간 구간을 선택하여 랜덤 크롭핑 적용 -> 하위 시퀀스 생성.
2. 세그먼트 샘플링 (Additional Segments): 시간적 일관성 (Temporal Consistency)유지를 위해 비인접 구간 (non-neighborhood segments)을 랜덤으로 샘플링 -> 시간적으로 더 이상 동일한 패턴을 따르지 않는 시계열 구간을 선택하여, 시계열 데이터의 일관성을 보장하는 데 사용.
3. 시계열 데이터 입력: 시계열 데이터가 공유 인코더에 입력.
4. 입력 프로젝션: 각 시계열 데이터는 고차원 잠재 특성으로 변환.
5. 시각 마스킹: 무작위로 마스크된 타임스탬프를 통해 중요한 특성을 학습.
6. 시간적 특성 추출: 팽창된 CNN을 사용하여 시계열의 시간적 동적 특성을 추출.
7. 대조 학습: 양성 및 음성 샘플을 사용하여 대조 손실을 계산하고, 여러 일관성을 학습.
8. 다중 작업 손실: 여러 작업의 손실을 결합하여 최종적으로 모델을 학습.
3.2 self-supervised task
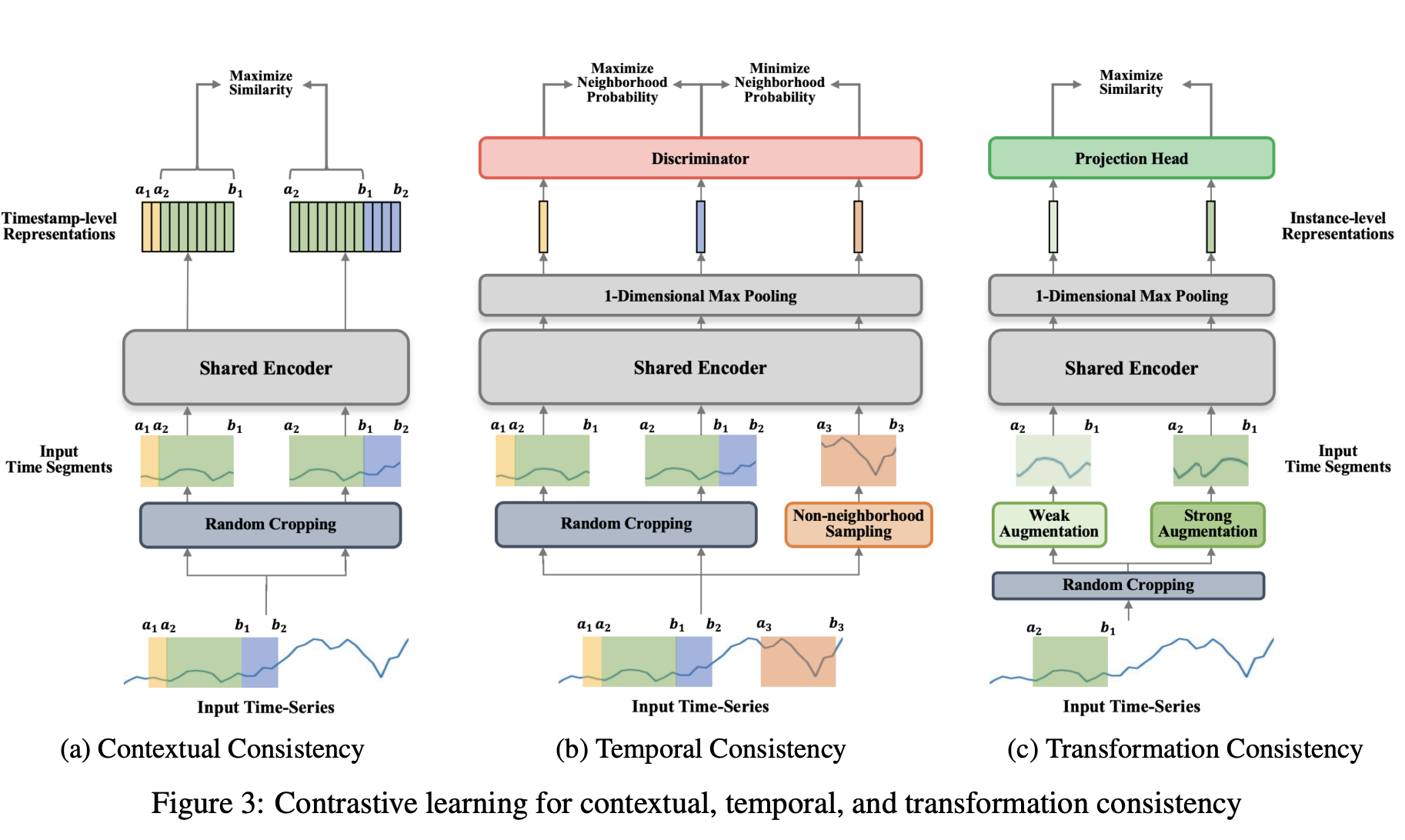
3.2.1 Contrastive Learning for Contextual Consistency (3(a))
타임스탬프별(timestamp-wise)과 인스턴스별(instance-wise)로 시계열 데이터를 대조하며, 겹치는 시간 구간(Overlapping Time Segments)을 사용해 여러 스케일에서 일관성을 유지하도록 유도. 이 모델은 시계열 데이터에서 서로 다른 문맥을 고려하여 각 타임스탬프가 일관되게 학습.
-
랜덤 크롭핑(Random Cropping)
- 주어진 시계열 데이터 에 대해 두 개의 겹치는 시간 구간을 랜덤 크롭핑을 통해 샘플링함. 여기서 T는 시계열의 길이, m은 각 시점에서의 특성 수.
- 예를 들어, 두 구간 와 를 샘플링하는데, 이 두 구간은 겹치는 부분이 있어야 함.
- 구간의 최대 길이는 하이퍼파라미터 l에 따라 조정.
-
공유 인코더(Shared Encoder)
- 두 개의 겹치는 구간을 공유 인코더(shared encoder)를 통해 각각 타임스탬프 수준의 표현으로 변환.
- 각 구간에 대해 타임스탬프 마스킹(timestamp masking) 모듈을 사용하여 문맥 정보를 다르게 적용한 후, 대조 학습을 통해 시계열의 문맥적 일관성을 학습.
-
타임스탬프별 대조(Timestamp-wise Contrastive Learning)
- 각 타임스탬프에서의 표현을 서로 다른 문맥에서 대조하여, 시간에 따른 구별 가능한 표현을 학습.
- 예를 들어, 구간 와 에서 각 타임스탬프 t에 대해 양성 샘플(positive sample)을 생성. 이 양성 샘플은 각 구간에서 동일한 타임스탬프 t에 해당하는 표현들임.
- 음성 샘플(negative sample)은 동일 구간 내 다른 타임스탬프에서의 표현들임.
- 이때의 대조 손실 함수는 다음과 같음. 여기서 는 구간에서의 타임스탬프 t에 대한 표현이고, 는 구간에서의 동일 타임스탬프에 대한 표현.
-
인스턴스별 대조(Instance-wise Contrastive Learning)
- 동일 타임스탬프에서 다른 인스턴스의 표현을 음성 샘플로 사용하여, 배치 내 다른 인스턴스와 비교해 학습을 진행.
- 이때의 대조 손실 함수는 다음과 같음.여기서 는 -번째 인스턴스의 타임스탬프 t에 대한 표현이고, 는 다른 인스턴스 에서의 타임스탬프 t에 대한 표현.
-
계층적 대조(Hierarchical Contrastive Learning)
- 타임스탬프별(timestamp-wise)과 인스턴스별(instance-wise) 대조 손실을 결합하여, 여러 스케일에서 문맥적 일관성을 학습.
- 여기서는 최대 풀링(max pooling)을 사용하여, 각 타임스탬프에서 여러 스케일을 결합하고, 이를 통해 더 강력한 표현 학습을 유도.
3.2.2 Contrastive Learning for Temporal Consistency (3(b))
TNC (Temporal Neighborhood Coding)라는 방법을 기반으로 하여, 시계열 데이터에서 이웃하는 시간 세그먼트와 이웃하지 않는 시간 세그먼트의 특성을 구별하고 학습하는 방식. 이 과정은 자기 지도 학습(self-supervised learning) 방식으로 진행되며, 이웃하는 구간과 이웃하지 않는 구간을 구별하여 유용한 시계열 표현을 학습하는 것이 목표.
-
시간적 이웃 관계 학습 (Temporal Neighborhood Coding)
- 이웃하는 구간 (Neighboring segments): 시계열 데이터에서 이웃하는 시간 구간.
- 비이웃 구간 (Non-neighboring segments): 이웃하지 않는, 즉 시간적으로 더 멀리 떨어진 구간.
- TNC는 이웃 구간의 표현을 비이웃 구간과 구별할 수 있는 잠재 공간(latent space)을 학습.
-
랜덤 크롭핑 (Random Cropping)
- 랜덤 크롭핑을 사용하여 두 개의 겹치는 시간 세그먼트를 생성하고, 이를 이웃 관계로 간주.
- 예를 들어, 시간 구간 와 는 겹치는 부분을 가지고 있어 이들을 이웃 관계로 취급.
- 이후, 통계적 검정(Statistical testing)을 통해 비이웃 구간을 샘플링. 비이웃 구간은 겹치는 구간과 상당히 멀리 떨어진 구간.
-
시간적 이웃 관계 및 비이웃 구간 정의
- 시간적 이웃 관계는 Gaussian 분포에 따라 정의.
- 중앙 타임스탬프 ( t )는 Gaussian 분포를 따름:
- 여기서 ( η )는 이웃 구간의 범위를 조정하는 하이퍼파라미터 의미.
- Dickey-Fuller 테스트를 사용하여 이웃 구간의 정성적 특성을 평가하고, 이웃 구간을 결정.
-
비이웃 구간 샘플링
- 겹치는 구간 의 중앙 타임스탬프를 중심으로 비이웃 구간을 샘플링.
- 예를 들어, 와 는 비이웃 구간으로 간주되며, 이들은 서로 다른 특성을 가질 가능성이 높기 때문에 부정적인 예시로 취급.
-
표현 추출 및 대조 학습
- 공유 인코더 (Shared Encoder)는 주어진 세 개의 시간 세그먼트를 타임스탬프 수준에서의 표현으로 매핑:
- (이웃 구간)
- (이웃 구간)
- (비이웃 구간)
- 공유 인코더 (Shared Encoder)는 주어진 세 개의 시간 세그먼트를 타임스탬프 수준에서의 표현으로 매핑:
- 각 세그먼트에서 나온 타임스탬프 표현은 인스턴스 수준으로 변환되며, max pooling을 사용하여 시간 축을 따라 통합된 정보가 생성.
-
대조적 손실 함수 (Contrastive Loss)
- 대조적 손실 (Contrastive loss)은 이웃 구간과 비이웃 구간을 구별하도록 학습.
- 이웃 구간이 비이웃 구간과 구별될 수 있도록, 이웃 구간의 표현은 양성 샘플로, 비이웃 구간의 표현은 음성 샘플로 취급.
손실 함수: - ( D )는 이진 분류기(binary classifier)로, 두 표현이 이웃 구간인지 비이웃 구간인지를 예측.
- ( w_i )는 비이웃 구간에서 샘플링 편향을 조정하는 하이퍼파라미터.
- PU learning(positive-unlabeled learning)을 활용하여 음성 샘플의 가중치를 조정.
-
PU 학습 (Positive-Unlabeled Learning)
- 음성 샘플이 아닌 레이블이 없는 샘플을 부정적인 샘플로 간주하며, 이를 통해 대조 학습이 더 정확하게 이루어지도록 함.
- 이 방법은 비이웃 구간의 샘플을 부정적인 예시로 간주하지만, 그 가중치를 작게 설정하여 모델이 긍정적인 예시를 학습하도록 함.
요약
이 방법은 시계열 데이터에서 시간적 일관성을 학습하는데, 이웃 구간과 비이웃 구간을 구별하도록 학습. 이 때, 비이웃 구간은 샘플링을 통해 생성되며, PU 학습을 통해 샘플링 편향을 줄이는 방법을 사용. 대조적 손실을 통해 모델은 이웃 구간의 표현을 구별하고, 이를 통해 더 강력한 시계열 모델을 학습하게 됨.
3.2.3 Contrastive Learning for Transformation Consistency (3(c))
변환 일관성의 목표
네트워크가 변환 불변 표현을 학습하도록 유도하는 것. 즉, 데이터가 여러 방식으로 증강되거나 변환되어도, 모델이 학습하는 표현이 일관되게 유지되도록 하는 것. 본 논문에서는 동일한 입력의 서로 다른 증강 버전들 간의 일치성을 극대화하려고 함.
변환 일관성 과정:
-
원본 입력 데이터: 다중 작업 설정에서
Xi,a2:b1라는 시간-시리즈 데이터 세그먼트가 원본 입력 데이터로 사용. -
데이터 증강:
- 약한 증강(Weak Augmentation): 입력에 랜덤한 변화를 추가하고 그 크기를 증폭시킴.
- 강한 증강(Strong Augmentation): 입력을 여러 개의 하위 시리즈로 나누고 이를 섞은 후, 랜덤한 섞임을 추가.
XW_i,a2:b1(약한 증강)과XS_i,a2:b1(강한 증강)이라는 두 증강된 세그먼트는 서로 다르지만 연관성이 있어 긍정적 페어(positive pair)로 간주. -
표현 학습: 약한 증강과 강한 증강 버전의 입력을 공유 인코더(shared encoder)에 통과시켜 각각의 타임스탬프 수준의 표현(
RW_i,a2:b1와RS_i,a2:b1)을 생성.- 인스턴스 수준의 표현(
rW_i와rS_i)은 타임축을 따라 최대 풀링을 적용하여 고정 크기의 벡터로 변환.
- 인스턴스 수준의 표현(
-
프로젝션 헤드(Projection Head): 대조적 학습(contrastive learning)을 위해 프로젝션 헤드(두 개의 완전 연결층을 가진 다층 퍼셉트론)를 사용하여 인스턴스 수준의 표현들을 대조적 손실을 적용할 수 있는 공간으로 매핑.
-
부정 샘플링(Negative Sampling):
- 배치 크기를 B라고 할 때, 각 배치에 대해 2B개의 인스턴스 수준의 표현이 존재함.
- 각 약한 증강과 강한 증강의 표현은 동일한 입력에서 생성된 긍정적 페어로 간주.
- 배치 내 다른 입력에서 생성된 나머지 표현들은 부정적 샘플(negative sample)로 간주.
대조적 손실(Contrastive Loss):
여기서,
sim은 표현들 간의 코사인 유사도(cosine similarity)를 의미.τ는 분포의 부드러움을 조절하는 온도 파라미터(temperature parameter).- 각 긍정적 페어(같은 입력에서 생성된 약한 증강과 강한 증강)에 대해, 이 손실 함수는 두 표현 간의 코사인 유사도를 크게 하도록 유도하며, 다른 표현들(부정적 샘플)과의 유사도는 최소화하려고 함.
이 작업은 모델이 동일한 입력에 대해 서로 다른 증강 버전들 간의 일관된 표현을 학습하도록 함. 이는 특히 시간이 변화하는 데이터(예: 시간-시리즈 데이터)에서 중요한데, 데이터가 변환되거나 증강되어도 모델이 잘 일반화되도록 도움.
4. 실험
4.1 실험 세팅
4.1.1 데이터셋
제안된 모델을 세 가지 다운스트림(task-specific) 과제에서 평가함:
- 시계열 분류 (Time-Series Classification)
- UEA 아카이브(30개 다변량 시계열 데이터셋)에서 벤치마크 모델과 비교
- HAR 데이터셋(30명의 실험자가 6가지 활동 수행)에서 학습된 표현의 질적 분석
- 고장 진단(Fault Diagnosis) 데이터셋(다양한 작동 조건에서 정상/고장 상태 데이터) 활용하여 모델의 범용성 확인
- 시계열 예측 (Time-Series Forecasting)
- ETT 데이터셋(전력 부하 및 변압기 오일 온도 예측) 사용
- 2년 동안 수집된 세 가지 ETT 데이터셋(ETTh1, ETTh2, ETTm1) 평가
- 이상 탐지 (Anomaly Detection)
- Yahoo 데이터셋(회원 로그인 시스템 관련 367개의 시계열 데이터, 변동점·이상치 포함)
- KPI 데이터셋(여러 IT 기업의 KPI 곡선, 분 단위 샘플링 데이터)
4.1.2 Implementation Details
본 연구에서는 기존의 자기지도학습(Self-Supervised Learning) 연구를 참고하여 하이퍼파라미터를 설정함.
- 공유 인코더(Shared Encoder) 설정 (TS2Vec [17] 기반)
- 입력 투영 레이어(hidden dimension): 64
- 확장 CNN 모듈의 잔여 블록(residual block): 커널 크기 3, 채널 크기 64
- 시계열 표현 벡터 차원: 320
- 각 자기지도 학습 과제별 하이퍼파라미터 설정
- 맥락적 일관성(Contextual Consistency): 하이퍼파라미터 l을 {0.25, 0.5}에서 탐색
- 시간적 일관성(Temporal Consistency): PU 학습 가중치 0.05 (TNC [14] 기반)
- 변환 일관성(Transformation Consistency): TS-TCC [16] 기반 설정
- 약한 변환(Weak Augmentation) 스케일 비율: 0.001
- 강한 변환(Strong Augmentation) 지터링 비율: 0.001
- 훈련 하이퍼파라미터
- 배치 크기(Batch size): 8
- 학습률(Learning rate): 0.001
- 학습 반복 횟수(Training Iterations)
- 데이터 크기 100,000 미만: 200회
- 데이터 크기 100,000 이상: 600회
4.2 실험 결과
4.2.1 Time-Series Classification
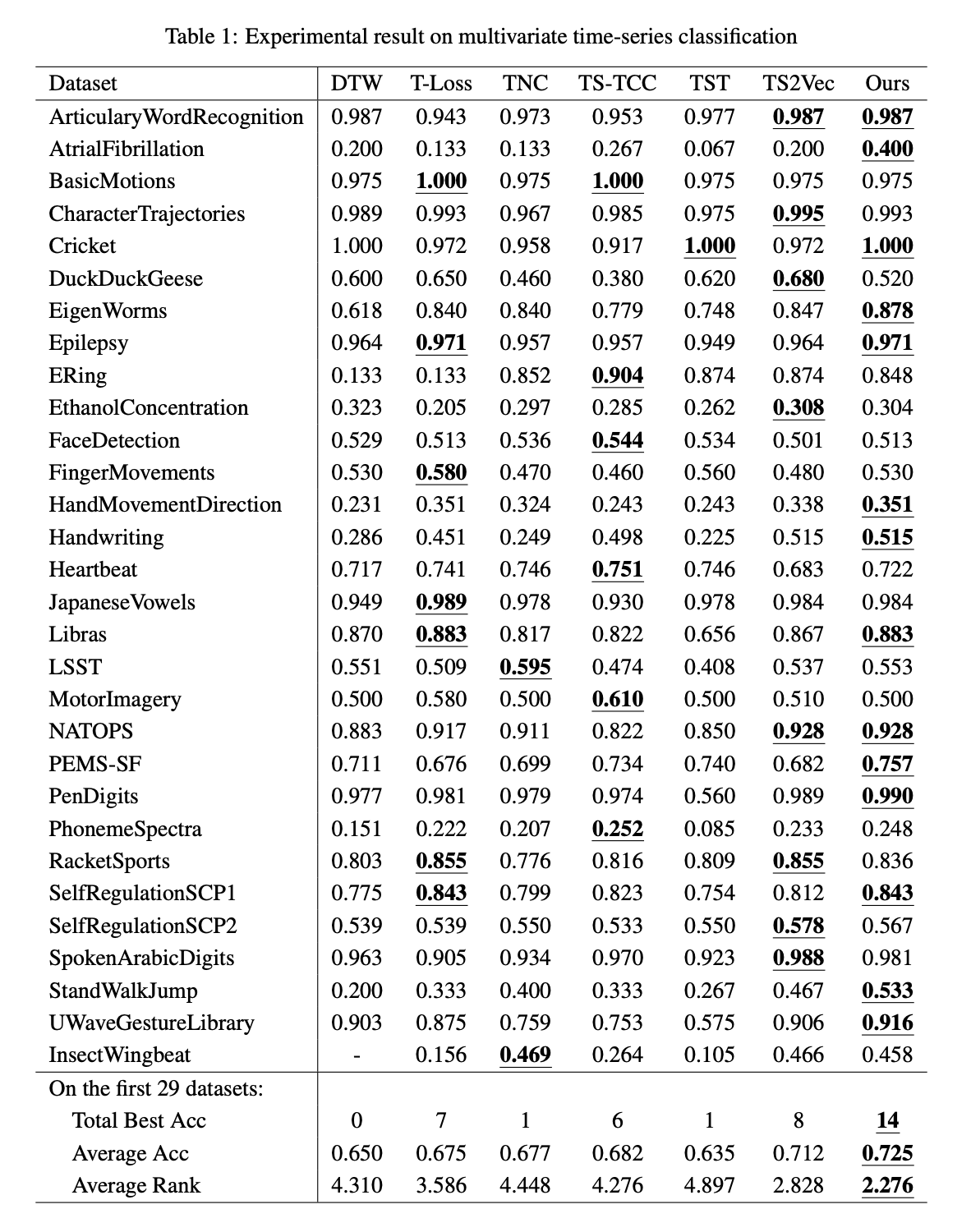
1. 실험 방법
- TS2Vec [17]의 실험 프로토콜을 따름.
- 사전학습된 표현 모델에서 훈련 데이터의 표현(representations)을 추출.
- 인스턴스 레벨 표현(instance-level representation) 추출 방법
- 타임스탬프 레벨 표현에 1D 맥스 풀링(max pooling) 적용.
- 이는 UEA 아카이브의 데이터셋이 인스턴스 단위로 클래스 레이블을 가지기 때문.
- 분류 모델: RBF 커널(두 데이터 포인트 (, ) 사이의 유사도를 계산하는 함수)을 사용하는 서포트 벡터 머신(SVM) 학습
- 패널티 값: {10⁻⁴, 10⁻³, ..., 10³, 10⁴, ∞}에서 그리드 서치(grid search) 및 교차 검증(cross-validation)을 통해 최적화.
2. 비교 및 성능 결과
- 비교 대상 모델
- DTW [45], T-Loss [13], TNC [14], TS-TCC [16], TST [15], TS2Vec [17]
- 총 30개 시계열 분류 데이터셋에서 성능 비교.
- 평가 결과
- 제안된 모델은 평균 정확도에서 기존 모델보다 우수한 성능을 보였음.
- 특히 AtrialFibrillation 및 StandWalkJump 데이터셋에서 성능 향상이 두드러짐.
- 평균 순위(rank) 2.276, 29개 데이터셋 중 14개에서 최고 정확도 기록.
- 벤치마크 모델별 평균 정확도 비교:
- TS2Vec (0.712) > TS-TCC (0.682) > TNC (0.677)
- 이는 Temporal(시간적), Transformation(변환), Contextual(맥락적) 일관성 학습 모델 순서와 일치.
- 결론적으로, 여러 자기지도 학습 기법을 함께 학습하는 것이 단일 방법보다 효과적임을 입증.
3. 표현 학습의 질적·양적 분석
- t-SNE 시각화 및 Silhouette Score를 활용한 평가
- Silhouette Score: 같은 클래스 내 데이터의 응집도 및 다른 클래스와의 분리를 측정하는 지표.
- 결과 분석
- BasicMotions 데이터셋
- 제안된 모델이 같은 클래스 데이터는 가깝고, 다른 클래스 데이터는 멀어지도록 학습.
- Silhouette Score가 TS2Vec보다 2배 이상 높음.
- 원본 데이터는 음수 점수(클래스 간 데이터가 혼재됨).
- RacketSports 데이터셋
- TS2Vec과 제안된 모델 모두 원본보다 분류 성능이 뛰어남.
- 제안된 모델의 Silhouette Score가 TS2Vec의 2배.
- BasicMotions 데이터셋
- 결론:
- 제안된 모델이 원본 데이터보다 훨씬 유용한 표현을 학습함을 확인.
- 특히, 분류가 어려운 데이터에서도 클래스 간 정보 차이를 효과적으로 반영함.
4.2.2 Time-Series Forecasting
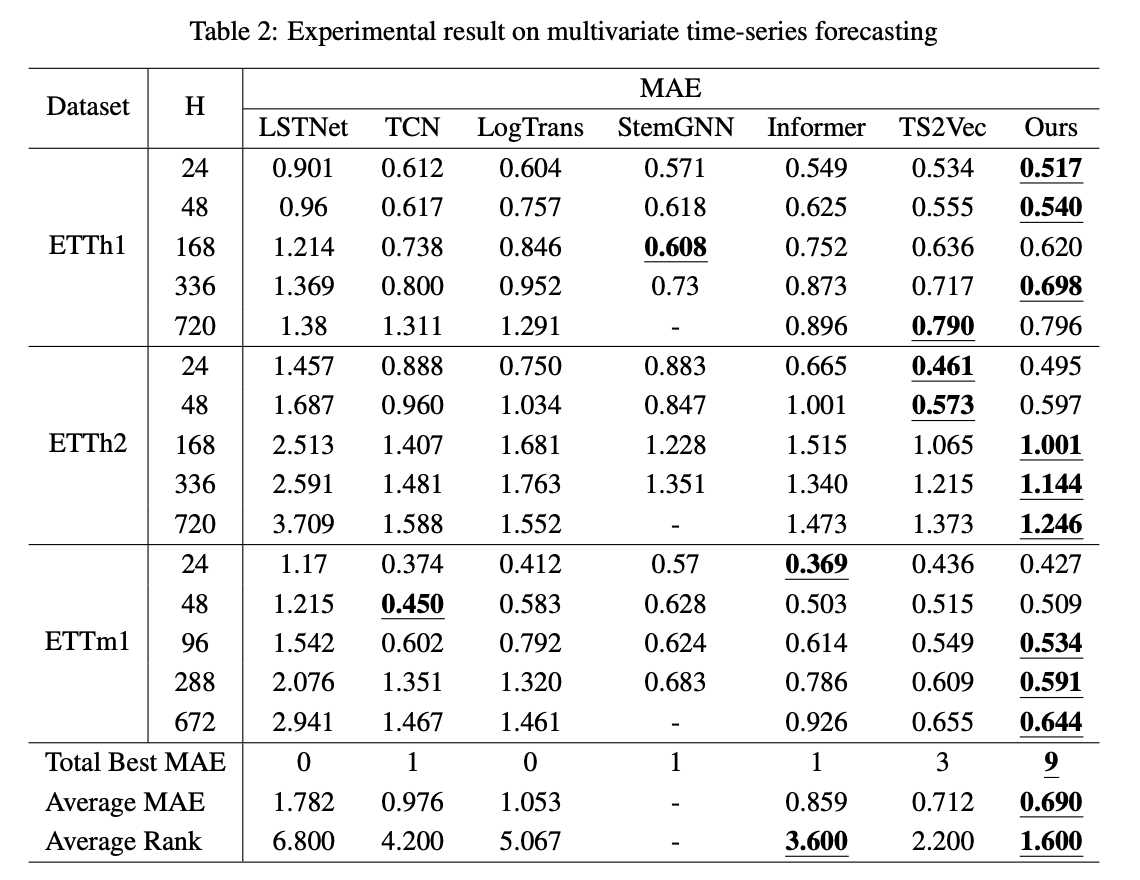
1. 실험 방법
- 다변량(multivariate) 시계열 예측
- 입력 데이터의 마지막 타임스탬프 표현(representation)을 기반으로 미래 길이 H만큼의 데이터를 예측.
- 예측 모델: 릿지 회귀(Ridge Regression) 사용
- 정규화 계수(α): {0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 200, 500, 1000}에서 그리드 서치(grid search)로 최적값 탐색.
- 평가 지표: 평균제곱오차(MSE), 평균절대오차(MAE) 사용.
- 비교 대상 모델:
- LSTnet [47], TCN [48], LogTrans [49], StemGNN [50], Informer [42], TS2Vec [17]
2. 실험 결과
- StemGNN은 H > 672에서 OOM(메모리 부족) 발생, 해당 실험에서는 제외하고 평균 MAE 및 순위(rank) 계산.
- 제안된 모델은 모든 ETT 데이터셋에서 가장 낮은 평균 MAE 및 가장 우수한 순위 기록.
- 예측 길이 H가 커질수록 성능이 더욱 뚜렷하게 TS2Vec을 초월하는 성능을 보임.
- 결론:
- 제안된 모델은 긴 시계열 데이터를 처리하는 데 효과적인 표현 학습 모델임을 입증.
- 특히 장기 예측(long-term forecasting)에서 TS2Vec보다 더 우수한 성능을 보임.
4.2.3 Time-Series Anomaly Detection
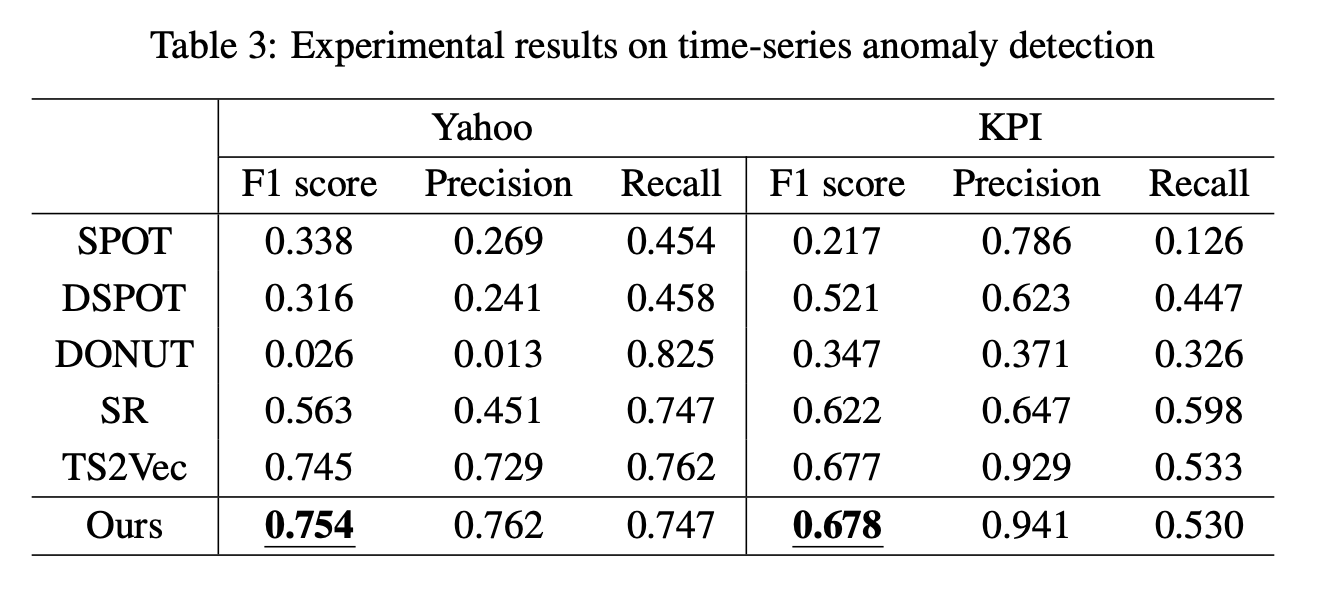
1. 실험 방법
- 이상 탐지 방식
- 입력 시계열 데이터의 마지막 타임스탬프 표현(representation)을 사용하여 이상치(outlier) 여부 판단.
- 이상치 점수(anomaly score) 정의
- L1 거리(L1 distance): 타임스탬프 마스킹 전후 표현의 차이를 기반으로 계산.
- 평가 지표:
- F1-score, Precision, Recall
- 비교 대상 모델:
- SPOT, DSPOT [51], DONUT [52], SR [44], TS2Vec [17]
2. 실험 결과
- Yahoo 및 KPI 데이터셋에서 F1-score 최고 기록
4.3 분석
4.3.1 모델 컴포넌트 효과
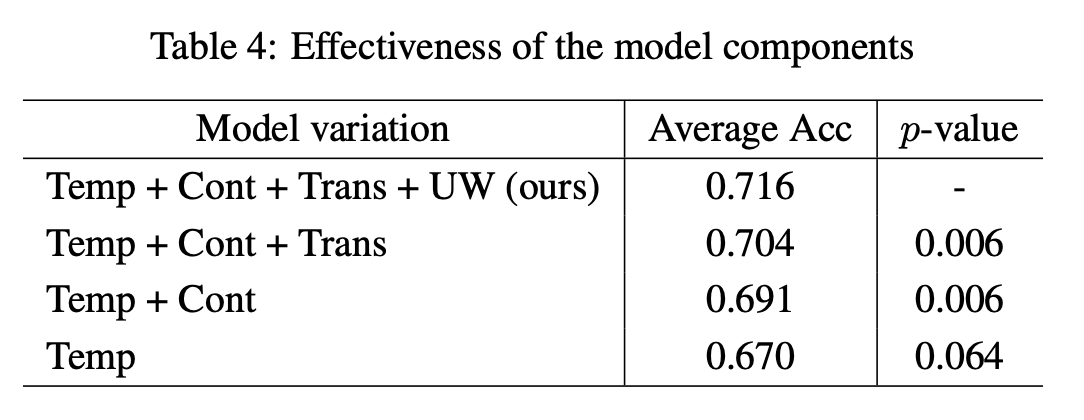
모델의 각 구성 요소가 성능에 미치는 영향을 평가하기 위해 실험을 수행하였으며, 시계열 분류(task)에서 다양한 모델 변형(variants)을 테스트함.
1. 실험 방법
- 비교 대상 모델 구성 요소
- Temp: Temporal consistency (시간적 일관성)
- Cont: Contextual consistency (문맥적 일관성)
- Trans: Transformation consistency (변환 일관성)
- UW: Uncertainty weighting (불확실성 가중치 적용 방법)
- 성능 비교 방법
- 각 구성 요소를 순차적으로 추가하며 평균 정확도(accuracy) 분석.
- Paired t-test를 수행하여 추가 전후의 성능 차이가 유의미한지(p-value 측정) 평가.
- 데이터셋: UEA archive의 30개 데이터셋 사용
2. 실험 결과
- 각 자가지도 학습(self-supervised) 기법을 추가할수록 평균 정확도 증가
- 모든 데이터셋에서 낮은 p-value(유의미한 성능 향상)를 보이며, 각 모델 구성 요소가 성능 개선에 기여함을 확인.
- 불확실성 가중치(Uncertainty weighting) 기법은 멀티태스크 학습의 안정성 향상에 효과적.
3. 결론
- 각 자가지도 학습 기법은 시계열 표현 학습 성능을 개선하는 데 기여함.
- 불확실성 가중치 방법이 멀티태스크 학습의 안정성을 높이는 데 효과적임을 확인.
4.3.2 Visualization
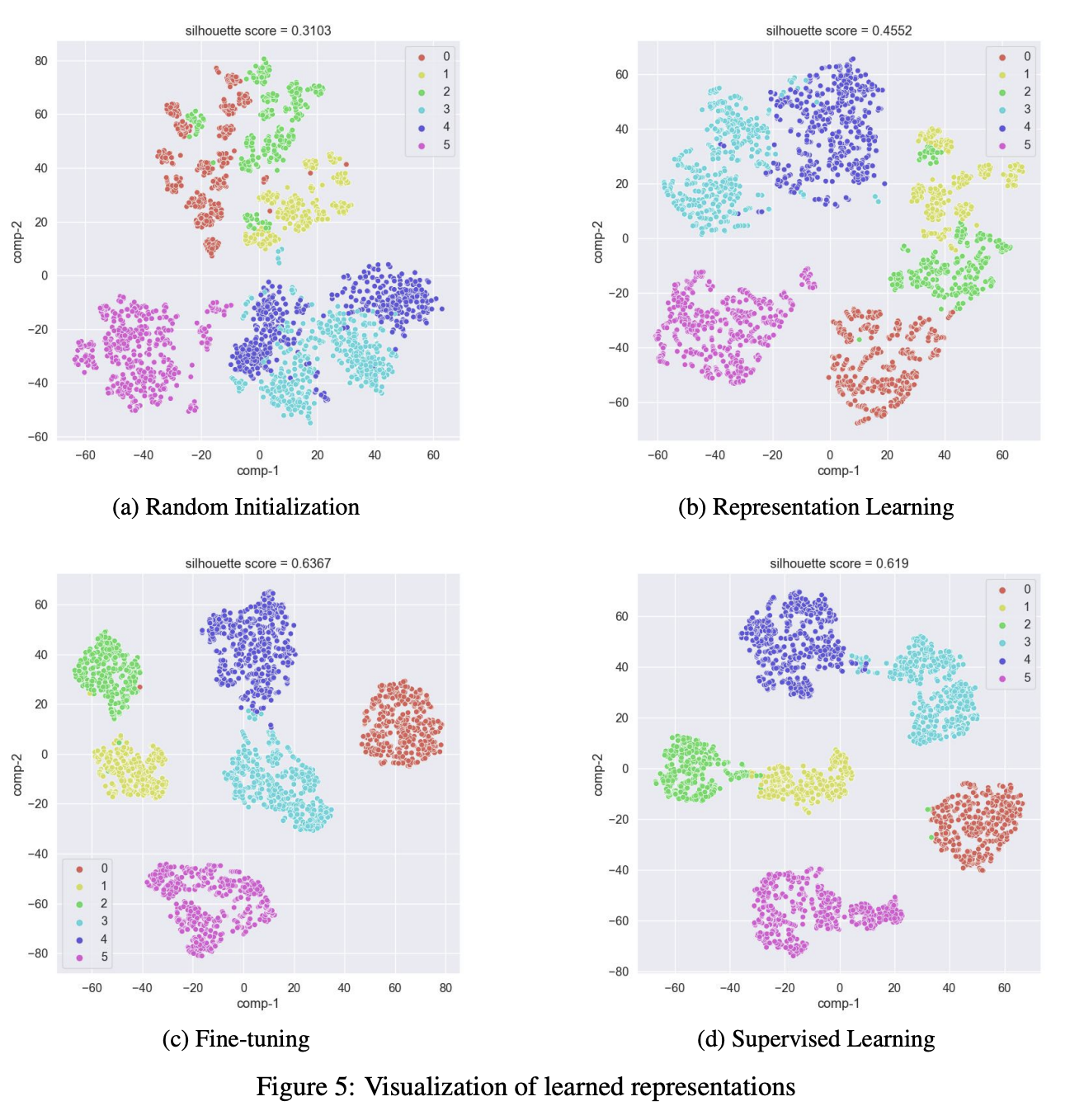
HAR(Human Activity Recognition) 데이터셋을 기반으로 모델이 학습한 표현을 이해하기 위해 정성적 및 정량적 평가를 수행함.
1. 비교 대상 모델 (4가지 학습 방식)
- Random Initialization
- 훈련 전 초기화된 인코더(encoder) 상태.
- Representation Learning
- 제안된 멀티태스크 자가지도 학습(self-supervised learning)을 통해 학습된 모델.
- Fine-Tuning
- 사전학습된 인코더(pretrained encoder)를 활용하여 라벨 데이터를 이용해 미세 조정(fine-tuning) 한 모델.
- Supervised Learning
- 라벨 데이터를 사용하여 처음부터 훈련된 모델.
2. 실험 방법
- 정성적 평가 (Qualitative Evaluation)
- t-SNE를 활용하여 각 모델이 학습한 표현을 시각화함.
- 클래스 간 데이터 분포와 구별 가능성 분석.
- 정량적 평가 (Quantitative Evaluation)
- Silhouette Score를 활용하여 각 모델이 학습한 표현의 군집 품질(clustering quality) 비교.
- 높은 Silhouette Score일수록 잘 구별된 표현 학습이 이루어졌음을 의미.
3. 실험 결과
1. Figure 5 분석
- Figure 5a (Random Initialization)
- 초기 인코더는 클래스 간 구별이 어려운 상태.
- Figure 5b (Representation Learning)
- 제안된 모델을 적용한 후, 같은 클래스 인스턴스들이 더 가까운 위치에 매핑됨(유사 특성 보유 데이터들이 그룹화됨).
- Figure 5c (Fine-Tuning)
- 분류(classification) 작업에 더욱 적합한 표현으로 발전함.
- Figure 5d (Supervised Learning)
- Representation Learning + Fine-Tuning 방식이 Supervised Learning보다 일부 클래스(0~2번 클래스)에서 더 뛰어난 표현 학습 결과를 보임.
2. Silhouette Score 분석
- Random Initialization < Representation Learning < Fine-Tuning 순으로 증가, 즉 학습을 거칠수록 표현이 분류에 적합하게 발전함.
- Representation Learning이 Supervised Learning보다 특정 클래스에서 더 뛰어난 표현을 학습한 것으로 나타남.
4. 결론
- Representation Learning + Fine-Tuning을 적용할수록 다운스트림(task-specific) 작업에 더 적합한 표현을 학습할 수 있음.
- Supervised Learning보다 Representation Learning이 일부 클래스에서 더 효과적인 표현 학습을 수행.
- Silhouette Score와 t-SNE 시각화 결과를 통해 제안된 모델의 효과성을 검증함.
4.3.3 Transfer Learning
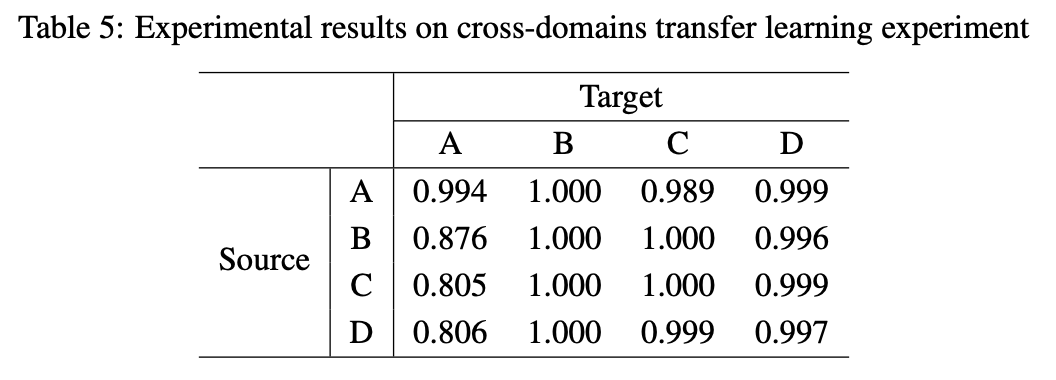
제안된 방법이 다양한 도메인(domain)에서 일반적인 표현을 학습하는지 검증하기 위해 전이 학습(transfer learning) 실험을 수행함.
1. 실험 데이터
- 고장 진단(fault diagnosis) 데이터셋을 활용하여 4개 도메인(domain)에서 실험 진행.
2. 실험 방법
- 사전학습(Pretraining)
- 소스 도메인(source domain)의 비라벨 데이터(unlabeled data)를 사용하여 인코더(encoder)를 사전학습함.
- 미세 조정(Fine-Tuning)
- 타겟 도메인(target domain)의 라벨 데이터(labeled data)를 사용하여 사전학습된 모델을 미세 조정함.
- 테스트(Test)
- 미세 조정된 모델을 타겟 도메인의 테스트 데이터에 적용하여 정확도(accuracy) 평가.
평가 지표) 타겟 도메인에서의 분류 정확도(accuracy) 측정.
3. 실험 결과(table 5)
- 소스 도메인에서 학습된 표현이 대부분의 타겟 도메인에 효과적으로 적용됨.
- 단, 타겟 도메인이 'A'인 경우 성능 저하 발생.
- 이를 제외하면, 제안된 방법이 다양한 도메인에서도 일반적인(time-series) 표현을 학습하는 데 효과적임을 확인.
4. 결론
- 제안된 모델은 특정 도메인에 한정되지 않고 다양한 도메인에서도 일반화 가능한 표현을 학습할 수 있음.
- 소스 도메인에서 학습한 표현이 타겟 도메인에서도 잘 적용되며, 전이 학습(transfer learning)에 효과적임.
- 일부 도메인(A)에서는 한계가 있었지만, 전반적으로 높은 전이 가능성(transferability)을 보임.
5. 결론
본 논문에서는 자기 지도 학습(self-supervised learning)을 통한 시계열 표현 학습을 제안하며, 이를 통해 시간에 따른 복잡한 동적 특성과 희소한 라벨 데이터에서 유용한 정보를 추출하는 방법을 제시함.
1. 문제 정의
- 기존의 시계열 분석에서는 복잡한 시계열 데이터와 희소한 라벨로 인해 좋은 성능을 얻기 어려움.
- 기존 방법은 대부분 대조 학습(contrastive learning)을 기반으로 긍정적인 쌍(pair) 간 일치를 최대화하는 방식이었으나, 하나의 일관성(consistency)만을 탐색하여 학습된 표현에 한계가 있었음.
2. 제안된 방법론
- 다중 작업 자기 지도 시계열 표현 학습(Multi-task Self-supervised Time-series Representation Learning)을 제시함.
- 목표: 시계열 데이터에서 여러 일관성(consistency)을 동시에 학습하여 일반화된 표현(general representations)을 학습.
- 제안된 세 가지 일관성:
- 컨텍스트 일관성(Contextual Consistency): 다양한 문맥(context)에서 겹치는 타임스탬프(timestamp)를 긍정적인 쌍으로 간주하여 표현 일관성을 유지.
- 시간적 일관성(Temporal Consistency): 연속적인 두 시간 구간(time segments)을 긍정적인 쌍으로 선택하여 표현의 지역적 매끄러움(smoothness)을 활용.
- 변환 일관성(Transformation Consistency): 유사한 샘플들의 표현이 가까워지도록 하여 변환 불변적(transformations-invariant) 표현 학습.
3. 모델 최적화
- 세 가지 일관성은 불확실성 가중치 방법(uncertainty weighting approach)을 사용하여 다중 작업 학습(multi-task learning)으로 최적화됨.
4. 실험 결과
- 다운스트림 작업(시계열 분류, 예측, 이상 탐지)에서 우수한 성능을 보였음.
- 전이 학습(transfer learning) 실험에서 다양한 도메인에서 일반화된 표현을 학습할 수 있음을 증명.
5. 결론
- 제안된 모델은 다양한 일관성을 동시에 학습하여 일반화된 표현을 학습할 수 있고, 다양한 다운스트림 작업 및 도메인에서 효과적임을 보임.
