https://ieeexplore.ieee.org/document/10636792
해당 서베이 논문의 부록 부분만 따로 정리를 해 두었다.
APPENDIX A. GNNs FOR TIME SERIES FORECASTING
최근 몇 년 동안, 딥러닝 기반 방법(RNN, CNN, Attention)들이 시계열 예측에서 큰 성과를 보이고 있다. 하지만 LSTNet과 TPA-LSTM과 같은 기존 방법들은 시계열 데이터 간의 dynamic spatial correlations를 잘 다루지 못한다는 단점이 존재한다.
대신에, 최근 그래프 신경망(GNN)을 활용한 방법들이 공간적 및 시간적 종속성을 잘 고려하여, 시계열 예측에서 두각을 드러내고 있다.
따라서 다음과 같은 관점에서 GNN 기반 시계열 예측을 알아볼 것이다.
(1) modeling spatial (i.e., inter-variable) dependencies
(2) modeling intertemporal dependencies
(3) the fusion of spatial and temporal modules
A.1 Modeling Inter-variable Dependencies
1. 스펙트럴 GNN 기반 접근법 (Spectral GNN-based Approaches)
- ChebConv (Chebyshev 다항식 기반 그래프 컨볼루션)을 사용하여 변수 간의 의존성을 모델링하는 방법. (주로 초기 연구에서 활용됐다.)
- STGCN (Spatial-Temporal Graph Convolutional Network): 시간적 합성곱(Temporal Convolution)과 ChebConv를 결합하여 공간적 및 시간적 패턴을 동시에 캡처한다.
- StemGNN: temporal and frequency 영역에서의 컨볼루션을 결합하여 복잡한 시계열 패턴을 추출한다.
2. 공간 GNN 기반 접근법 (Spatial GNN-based Approaches)
- 메시지 전달(Message Passing) 또는 그래프 확산(Graph Diffusion) 기법을 활용하여 변수 간의 의존성을 모델링.
- DCRNN과 Graph WaveNet: 그래프 diffusion layer를 GRU(Gate Recurrent Unit) 또는 temporal convolution과 결합하여 시계열 데이터를 모델링.
- STGCN(2nd)와 ST-MetaNet: GCN(Graph Convoluntional Network)과 GAT(Graph Attention Network)를 사용하여 인접한 시계열로부터 정보를 집합.
- MTGNN, SGP, HiGP: 다양한 spatial-temporal 그래프 diffusion 및 message passing 방법을 개선하여, 더 효과적이고 확장 가능한 예측 모델을 구현.
3. 하이브리드 접근법 (Hybrid Approaches)
- SLCNN: ChebConv와 local message passing을 결합하여 다양한 수준에서 공간적 관계를 포착.
- AutoSTGNN: 신경망 아키텍처 검색(Neural Architecture Search)을 이용하여 높은 성능의 GNN 기반 예측 모델을 자동으로 식별. 다양한 GNN 인스턴스들을 spatial-temporal block에 동시에 구현.
4. 기타 연구 및 발전
- 그래프 변환기(Graph Transformer): long-range spatial dependencies를 캡처하는 데 유리하여, STAR, ASTTN, ASTTGN 등의 연구가 이에 해당.
- 하이퍼그래프(Hypergraph): GPT-ST와 같은 연구에서는 다양한 spatial dependencies를 글로벌하게 효과적으로 포착하기 위해 하이퍼그래프를 사용.
- 하이퍼볼릭 GNN (HGNN): 하이퍼볼릭 공간을 활용하여 계층적인 구조를 자연스럽게 모델링.
5. 하이퍼볼릭 GNN
- 하이퍼볼릭 공간은 트리 구조와 비슷한 특징을 가지고 있어, 계층적인 데이터를 모델링할 때 유리하다.
- HGNN을 이용한 연구는 시계열 데이터를 처리할 때 뛰어난 성능을 보여주고 있으며, 여러 연구가 하이퍼볼릭 GNN을 시계열 그래프 학습에 적용하는 방법을 제시 중.
요약
- spectral GNN은 주로 Chebyshev 다항식을 이용해 spatial-temporal 패턴을 모델링하고, 최근에는 다양한 변수 간 관계를 모델링하는 데에 다양한 다항식들을 사용하는 방식으로 발전.
- spatial GNN은 message passing 및 graph diffusion 방법을 통해 변수 간 의존성을 모델링하고 있으며, graph transformer와 같은 최신 기법들이 장거리 의존성을 캡처하는 데 강점을 보인다.
- 하이브리드 모델은 여러 GNN 기법을 결합하여 spatial-temporal 의존성을 동시에 모델링하는 방법을 제시하며, 하이퍼볼릭 GNN을 통해 계층적 구조를 자연스럽게 처리할 수 있는 가능성도 제시되었다.
A.2 Modeling Inter-temporal Dependencies
시계열 데이터에서 시간 종속성(temporal dependencies)을 모델링하는 것은 GNN 기반 예측 모델에서 중요한 요소이다. 이러한 시간적 패턴은 시간(time) 도메인과 frequency 도메인에서 모델링될 수 있으며, 이를 위해 다양한 방법들이 연구되고 있다.
시간 종속성 모델 (TEMPORAL(·))
주어진 길이 의 단변량(univariate) 시계열 이 있을 때, 목표는 효과적인 시간 모델 을 학습하는 것이다. 이를 통해 원본 시계열 의 시간적 종속성을 효과적으로 반영한 을 생성하는 것이 목표이다.
- 시간 도메인: CNN, Attention, RNN(GRU 등) 활용 가능
- frequency 도메인: 푸리에 변환을 이용한 frequency 성분 분석 가능
- 하이브리드 모델: 위 방법들을 결합하여 시간 및 frequency 정보를 모두 반영
시간 종속성을 모델링하는 방식은 순환 모델(Recurrent), 합성곱 모델(Convolution), 어텐션 모델(Attention), 하이브리드 모델(Hybrid) 네 가지로 구분할 수 있다.
1. 순환 모델 (Recurrent Models)
과거의 연구에서는 주로 GRU, RNN 기반 모델이 시간적 관계를 학습하는 데 활용되었다.
- DCRNN: 그래프 확산(diffusion)과 GRU를 결합하여 교통 예측을 수행.
- ST-MetaNet: 두 개의 GRU를 사용하여 지리적 요소를 고려한 다양한 시간적 관계 학습.
- MRA-BGCN: Multi-Range Attention과 GRU를 결합하여 노드 및 엣지 관계 모델링.
- AGCRN: GRU + GCN 조합을 사용하여 그래프 구조 학습을 최적화.
- GTS, RGSL: 서로 다른 그래프 구조 학습 방식을 적용.
- Echo State Networks (ESN): 랜덤 연결 기반의 RNN으로 대규모 데이터에서 성능 유지.
- Graph Kalman Filters: Kalman 필터를 GSS(Graph Signal Processing) 모델에 적용하여 예측 성능 향상.
2. 합성곱 모델 (Convolution Models)
합성곱 신경망(CNN)은 효율적인 시간적 관계 모델링이 가능하며, 주요 연구들은 다음과 같다.
- STGCN: 1D 컨볼루션과 GLU(Gated Linear Units) 활용하여 효율적 학습 가능.
- Graph WaveNet: 팽창된 인과적 컨볼루션(dilated causal convolution)을 활용해 수용 필드(receptive field) 확장.
- MTGNN: 다양한 커널 크기를 활용한 다중 시간 컨볼루션 기법.
- MTGODE: Neural ODE 개념을 도입하여 모델링 일반화.
- Z-GCNETs: 기본 CNN을 활용하여 시간 패턴을 학습.
또한, 일부 연구에서는 frequency 도메인 기반의 합성곱 기법을 적용하였다.
- StemGNN: 푸리에 변환 후 CNN을 이용하여 frequency 성분을 필터링.
- TGC: frequency 성분을 개별적으로 컨볼루션 처리하여 더 강력한 표현 학습 수행.
3. 어텐션 모델 (Attention Models)
최근에는 Transformer 기반의 Self-Attention 기법이 시계열 데이터 모델링에 많이 적용되고 있다.
- GMAN: 공간 및 시간 정보를 어텐션 기반으로 통합.
- STGRAT: Transformer 구조를 적용하여 멀티 헤드 기법 사용.
- STAR, TPGNN, STEP: Transformer 레이어를 이용해 단변량 시계열의 시간 종속성을 학습.
- ST-GDN: 다중 스케일 기법을 활용하여 정밀한 시간적 관계 모델링.
4. 하이브리드 모델 (Hybrid Models)
두 가지 이상의 모델을 결합하여 시간 종속성을 학습하는 방식.
- ASTGCN, HGCN, DSTAGNN: 어텐션과 합성곱을 결합하여 시간적 관계를 효과적으로 학습.
- STGNN*: GRU와 Transformer를 결합하여 지역(local) 및 글로벌(global) 시간 의존성 학습
- Auto-STGCN: 신경망 구조 탐색(Neural Architecture Search, NAS) 개념을 도입하여 최적 모델을 자동 탐색.
- 비선형 TGC (Nonlinear TGC): 주파수 도메인에서 스펙트럼 어텐션 + CNN 조합 활용.
요약
- 순환 모델(RNN, GRU 기반) → 시간적 관계 학습에 초점 (DCRNN, AGCRN 등)
- 합성곱 모델(CNN 기반) → 효율적인 시간 패턴 학습 (STGCN, Graph WaveNet 등)
- 어텐션 모델(Transformer 기반) → Self-Attention을 활용한 강력한 시계열 예측 (GMAN, STGRAT 등)
- 하이브리드 모델(결합형) → 여러 기법을 결합하여 성능 최적화 (ASTGCN, Auto-STGCN 등)
- 이처럼 시계열 데이터를 효과적으로 모델링하기 위해 다양한 방법들이 연구되고 있으며, 최근에는 어텐션 기반 모델과 하이브리드 방식이 더욱 각광받고 있다.
A.3 Forecasting Architectural Fusion
시계열 데이터에서 시공간 종속성을 효과적으로 학습하는 신경망 아키텍처는 다음 네 가지 범주로 구분된다.
- (1) 이산 분리형 (Discrete Factorized)
- (2) 이산 결합형 (Discrete Coupled)
- (3) 연속 분리형 (Continuous Factorized)
- (4) 연속 결합형 (Continuous Coupled)
이산 모델은 공간(Spatial)과 시간(Temporal) 종속성을 독립적으로 학습하거나 결합하여 모델링하며, 연속 모델은 신경미분방정식(Neural Differential Equation, NODE)을 활용해 연속적인 과정으로 이를 학습한다.
(1) 이산 분리형 (Discrete Factorized)
공간과 시간 종속성을 독립적으로 학습하는 모델이다. 일반적으로 공간과 시간 모듈을 번갈아가며 쌓는 구조를 갖는다.
- STGCN: 그래프 및 시간 게이트 컨볼루션을 사용하여 변수 간 관계를 모델링.
- DGCNN, LSGCN, STHGCN, HGCN: 기존 STGCN 구조를 확장하여 동적 그래프 구조 추론, 하이퍼그래프 컨볼루션 등을 도입.
- STMetaNet: RNN과 GAT(Graph Attention Network)를 조합하여 교통 데이터 학습.
- ASTGCN, DSTAGNN, GraphSleepNet: 시공간 어텐션(attention) 및 컨볼루션 기반 구조 사용.
- Graph WaveNet, StemGNN, MTGNN, STFGNN: 시공간 관계를 학습하지만 attention을 사용하지 않는 구조.
- STAR, ST-GDN, TPGNN: Transformer, 다항 그래프 모듈 등을 활용하여 시공간 패턴을 더욱 효과적으로 학습.
- MTHetGNN, CausalGNN, Auto-STGCN: heterogeneous 그래프 및 causal 그래프를 활용한 모델.
(2) 이산 결합형 (Discrete Coupled)
공간과 시간 모듈을 하나의 과정으로 결합하여 학습하는 모델이다.
- DCRNN: RNN 내부에 그래프 확산(diffusion) 및 attention을 포함하여 시공간 패턴 학습.
- ST-UNet, MRA-BGCN, STGNN*, AGCRN, RGSL, MegaCRN: RNN 기반의 다양한 변형 모델.
- GMAN: 시공간 attention 블록을 게이트 방식으로 통합하여 활용.
- ZGCNETs: 시간에 따른 그래프 위상(topology) 변화를 반영한 학습.
- TAMPS2GCNETS: GCN 레이어와 CNN을 결합하여 시공간 패턴을 학습.
- STSGCN, STG2Seq, METRO, ASTTN: 특수한 그래프 구조를 활용한 컨볼루션 방식 사용.
(3) 연속 분리형 (Continuous Factorized)
공간과 시간 종속성을 각각의 연속적인 과정으로 모델링하는 방법.
- STGODE: 그래프 확산을 연속적인 과정으로 모델링하며 dilated convolution을 적용하여 장기 의존성(long-range dependency) 학습.
(4) 연속 결합형 (Continuous Coupled)
하나의 연속적인 과정으로 공간과 시간을 통합하여 모델링하는 방식.
- MTGODE: 두 개의 NODE를 결합하여 공간과 시간 학습을 하나의 연속적 과정으로 통합.
- STG-NCDE: 신경제어미분방정식(Neural Controlled Differential Equations, NCDE)을 활용하여 시공간 패턴 학습.
- TGNN4I: GRU와 MPNN(Message Passing Neural Network)을 결합하여 연속적인 시공간 동역학 모델링.
요약
- 이산 모델은 공간과 시간 정보를 독립적 또는 결합하여 학습하는 방식이며, RNN, GCN, Transformer 등의 다양한 변형 모델이 존재.
- 연속 모델은 신경미분방정식을 활용하여 공간-시간 패턴을 연속적으로 학습하는 방식으로, 최근 연구에서 점차 활용도가 증가.
- 이산 분리형 모델(STGCN 등)은 독립적으로 학습, 이산 결합형 모델(DCRNN 등)은 하나의 과정으로 학습.
- 연속 분리형 모델(STGODE 등)은 부분적으로 연속적 모델링, 연속 결합형 모델(MTGODE 등)은 하나의 연속적인 과정으로 공간과 시간을 모델링.
APPENDIX B. GNNs FOR TIME SERIES ANOMALY DETECTION
시계열 이상 탐지는 데이터 생성 과정에서 정상적인 패턴과 일치하지 않는 데이터를 식별하는 작업이다. 이러한 비정상적인 데이터 포인트를 이상치(anomaly)라고 하며, 정상적인 데이터를 정상 데이터(normal data)라고 한다.
일부 문헌에서는 새로운 데이터(novelty), 이상값(outlier) 등의 용어가 이상치와 거의 동일한 의미로 사용된다.
이상치는 단일 관측값(포인트 이상치)일 수도 있고, 여러 개의 연속된 데이터(구간 이상치)일 수도 있다. 그러나 정상적인 시계열 데이터와 달리 이상치를 명확하게 정의하는 것은 어렵다.
그 이유는 다음과 같다:
1. 이상치는 매우 드물어서 데이터 수집과 라벨링이 어렵다.
2. 모든 이상 이벤트를 사전에 정의하는 것이 불가능하여, 지도 학습(supervised learning)의 적용이 어렵다.
따라서, 실무에서는 비지도 학습(unsupervised learning) 기반의 이상 탐지 기법이 널리 활용된다.
과거에는 다음과 같은 방법들이 시계열 이상 탐지에 사용되었다.
- 거리 기반(distance-based) 방법
- 대표적인 정상 데이터와 특정 관측값 간의 거리를 측정하여 이상 여부를 판단한다.
- 분포 기반(distributional) 방법
- 특정 데이터가 전체 데이터 분포에서 얼마나 희귀한지를 분석하여 이상 여부를 결정한다.
1. 딥러닝 기반 이상 탐지 기법
딥러닝의 발전과 함께, 시계열 이상 탐지 분야에서도 다양한 모델이 활용되고 있다.
- 재구성(reconstruction) 기반 모델
- 순환 신경망(RNN, LSTM 등)을 이용하여 정상 데이터만을 학습한 후, 주어진 입력 데이터를 재구성한다.
- 재구성 오류(reconstruction error)가 크면, 해당 데이터가 이상치일 가능성이 높다고 판단한다.
- 예측(forecasting) 기반 모델
- 정상적인 시계열 데이터를 학습한 모델이 향후 데이터를 예측하도록 한다.
- 예측값과 실제값의 차이(예측 오류)가 크면, 이상치로 간주한다.
그러나 순환 신경망(RNN) 기반 모델은 변수 간의 관계를 명확히 모델링하는 능력이 부족하여 복잡한 이상 탐지 문제에서 성능이 제한적이다.
2. 그래프 신경망(GNN) 기반 이상 탐지
최근에는 그래프 신경망(GNN, Graph Neural Networks)을 활용하여 시계열 데이터 내 시간적, 공간적 종속성(temporal & spatial dependencies)을 효과적으로 학습하는 방법이 주목받고 있다.
B.1 General Approach for Anomaly Detection
비지도 학습 기반의 이상 탐지는 크게 백본(backbone) 모듈과 스코어링(scoring) 모듈의 두 단계로 구성된다.
- 백본 모듈 (BACKBONE)
- 정상 데이터(혹은 이상치가 거의 포함되지 않은 데이터)를 학습하여 일반적인 정상 패턴을 모델링한다.
- 스코어링 모듈 (SCORER)
- 모델이 예측한 데이터(𝑋̂)와 실제 입력 데이터(𝑋)의 차이를 계산하여 이상 탐지 점수(anomaly score)를 부여한다.
- 이상 탐지 점수가 높을수록 이상 데이터일 가능성이 크다.
예를 들어, GNN 기반의 이상 탐지 모델에서,
- 백본(backbone)은 GNN 기반의 1-step-ahead 예측 모델이 될 수 있다.
- 스코어링(scoring) 모듈은 예측 오류를 계산하여 이상 탐지 점수를 생성한다.
이상 탐지 점수는 각 변수별 예측 오류의 합으로 계산되며, 특정 변수의 기여도를 분석함으로써 이상 원인을 진단할 수도 있다.
요약
- 시계열 이상 탐지는 정상적인 데이터 패턴에서 벗어난 데이터를 식별하는 과정이다.
- 과거에는 거리 기반, 분포 기반 방법이 사용되었으나, 딥러닝(특히 RNN 기반 모델)의 발전으로 이상 탐지가 향상되었다.
- 하지만 RNN 기반 방법은 변수 간 관계를 명확히 모델링하는 데 한계가 있어, 최근에는 GNN 기반 이상 탐지 기법이 주목받고 있다.
- GNN을 활용하면 시계열 데이터의 시간적, 공간적 종속성을 효과적으로 학습하여 복잡한 이상 탐지를 수행할 수 있다.
B.2 Discrepancy Frameworks for Anomaly Detection
대부분의 이상 탐지 방법은 Backbone-Scorer 아키텍처를 따르지만, 학습 방식과 이상 점수를 계산하는 방법에 따라 크게 세 가지 범주로 나뉜다:
1. 재구성(Reconstruction) 기반 프레임워크
2. 예측(Forecast) 기반 프레임워크
3. 관계(Relational) 기반 프레임워크
1. Reconstruction Discrepancy
- 기본 개념: 정상 데이터는 쉽게 재구성되지만, 이상 데이터는 그렇지 못하다는 가정에 기반한다.
- 동작 방식:
- 백본 모델(Backbone, 예: 오토인코더)은 입력 데이터를 출력으로 복원하는 방식으로 학습된다.
- 정상 데이터에서의 복원 오류는 작고, 이상 데이터에서는 큰 오류가 발생한다.
- Scorer가 재구성 오류를 기반으로 이상 탐지 점수를 계산하여 이상 여부를 판단한다.
- MTAD-GAT 모델
- 변분 목표(Variational Objective)를 활용하여 학습된다.
- Graph Attention Network(GAT)를 사용해 시공간(spatiotemporal) 종속성을 학습한다.
- LSTM-VAE 대비 우수한 성능을 보이며, 그래프의 Attention Score를 활용해 정상/이상 구간 차이를 분석한다.
- 다만, 모든 변수 간에 fully-connected graph를 구성한다는 가정이 현실적이지 않아 오류가 있을 수 있다.
- VGCRN 모델
- 변수별(채널별) 학습 가능한 임베딩을 활용하여 그래프 구조를 자동으로 학습한다.
- 각 변수의 임베딩을 내적(dot product)하여 채널 간 유사성에 관한 행렬을 생성한다.
- FuSAGNet 모델
- Sparse Directed Graph를 학습하여 변수 간 중요한 관계만 유지한다.
- Variational Objective 대신 희소 임베딩(sparse embedding) 방식을 사용한다.
- 그래프 수준 임베딩 기법
- 여러 연구에서 그래프를 벡터로 변환하여 이상 탐지를 수행하는 방법을 탐색하고 있다.
- Zambon et al.: 그래프 간 거리 보존을 목표로 한 저차원 임베딩 방식 도입.
- GIF 모델
- 랜덤 푸리에 특징(Random Fourier Feature)을 활용하여 이상점을 탐색.
- CCM-CDT 모델
- 그래프 오토인코더를 사용하여 Riemannian Manifold에서 이상 패턴을 탐색.
- 통계적 검정을 수행하여 데이터 분포 변화를 감지.
요약
- Reconstruction Discrepancy는 입력을 다시 복원하고, 원본과 사본 간의 차이를 이상 탐지의 핵심 기준으로 사용.
- GNN(그래프 신경망) 기반 모델이 기존 LSTM-VAE보다 시공간적 관계를 더 효과적으로 학습할 수 있다.
- fully-connected graph 가정이 현실적이지 않다는 문제를 해결하기 위해 학습 가능한 그래프 구조(VGCRN, FuSAGNet)가 제안되기도 했다.
- 그래프 임베딩을 활용한 이상 탐지 연구도 진행 중이며, 특정 통계적 기법(CCM-CDT)과 결합한 방식도 등장하고 있다.
2. Forecast Discrepancy
Forecast discrepancy framework는 정상 데이터에 대해서는 예측 오류가 작지만, 이상 현상이 발생하면 예측 오류가 커진다는 가정을 기반으로 한다. Reconstruction discrepancy framework와 달리, 현재 데이터를 그대로 재구성하는 것이 아니라 GNN 기반 예측 모델을 학습하여 다음 시간 스텝의 값을 예측한다.
1. 예측 기반 이상 탐지 과정
- 모델 학습: GNN 기반의 예측 모델을 훈련하여 다음 시간 스텝의 값을 예측하도록 한다.
- 탐지 과정 (Inference):
- 모델이 다음 시간 스텝의 값을 예측한다.
- 예측값과 실제값의 차이를 계산하여 오류(예측 편차)를 구한다.
- 예측 오류가 클 경우 이상 현상으로 판단한다.
2. 주요 기법 및 모델
- GDN (Graph Deviation Network)
- 그래프 구조 학습 모듈을 사용하여 변수 간 관계를 학습한다.
- Graph Attention Network를 활용하여 시계열 데이터를 인코딩한다.
- 예측 오류(절대 오차 또는 평균 제곱 오차)를 계산하여 이상 여부를 판단한다.
- 이상 원인 진단: 가장 이상값이 큰 변수를 찾아내고, 그 변수와 연결된 다른 변수들을 분석하여 이상 현상의 근본적인 원인을 추적한다.
- AZ-Whiteness Test & AZ-Analysis
- 예측 모델의 잔차(residuals)를 분석하여 이상을 탐지하는 통계적 방법이다.
- 시간적 상관관계(시계열 이상)와 공간적 상관관계(그래프 노드 간 이상)를 구별하여 보다 정밀한 이상 탐지를 수행할 수 있다.
- GST-Pro
- 실제 관측값을 사용하지 않고도 이상을 예측할 수 있는 모델로, 미래 시점의 이상을 사전에 감지할 수 있다.
3. Forecast Discrepancy vs. Reconstruction Discrepancy
| 특징 | Reconstruction Discrepancy | Forecast Discrepancy |
|---|---|---|
| 접근 방식 | 입력 데이터를 재구성 | 다음 시간 스텝 예측 |
| 이상 탐지 기준 | 재구성 오류가 클 경우 | 예측 오류가 클 경우 |
| 학습 데이터 | 현재 시점 데이터 사용 | 과거 데이터를 활용하여 미래 예측 |
| 탐지 방식 | 입력 데이터를 다시 생성하여 비교 | 예측값과 실제값을 비교 |
| 초점 | 정상 패턴을 정확히 복제 | 미래 값을 정확히 예측 |
요약
- Forecast 기반 방법은 예측값과 실제값의 차이를 분석하여 이상을 탐지한다.
- GDN과 같은 GNN 기반 방법은 시계열 변수 간의 관계를 학습하여 이상 탐지를 개선한다.
- Reconstruction 방식과 달리, Forecast 방식은 현재 데이터를 직접 재구성하지 않고 과거 데이터를 기반으로 미래를 예측하여 이상 여부를 판단한다.
- GST-Pro와 같은 최신 기법은 실제 관측값 없이도 이상을 예측할 수 있어 미래의 이상을 사전에 감지할 수 있다.
3. Relational Discrepancy
Relational discrepancy framework는 변수 간의 관계가 정상 혹은 비정상에 따라 중요한 변화를 나타낸다고 가정한다. 즉, 변수들 간의 관계가 정상적인 패턴에서 이상적인 패턴으로 급격히 변화하는 시점을 감지하여 이상을 탐지하는 방식이다.
1. MTAD-GAT에서의 Relational Discrepancy
- MTAD-GAT 연구에서, 노드 이웃의 attention weights가 이상 기간 동안 정상적인 패턴에서 크게 벗어나는 경향이 있음을 관찰했다.
- 이 연구는 변수 간 관계가 변할 때 이상을 탐지할 수 있는 가능성을 제시하며, Spatiotemporal GNN(공간-시간 GNN)의 활용 가능성을 보여준다.
- Spatiotemporal GNN은 그래프 구조를 학습하여 이상 탐지 및 진단에 사용될 수 있다.
2. GReLeN 모델
- GReLeN은 동적으로 학습된 그래프를 이용하여 relational discrepancy를 기반으로 이상을 탐지하는 첫 번째 방법이다.
- reconstruction 모듈은 시간에 따라 변화하는 그래프 구조를 동적으로 학습한다.
- 그래프 구조는 채널 노드의 in-degree와 out-degree 값의 변화를 계산하는 scorer로 전달된다.
- 핵심 아이디어: 각 시점에서 구조적 관계의 급격한 변화(즉, relational discrepancy)를 집중적으로 다루면, 이상 이벤트를 탐지하는 강력한 지표를 만들 수 있다.
3. DyGraphAD 모델
- DyGraphAD는 forecasting 기반으로 relational discrepancy를 계산한다.
- 이 방법은 다변량 시계열 데이터를 서브시퀀스로 나누고, 각 서브시퀀스를 동적으로 변화하는 그래프로 변환한다.
- 각 서브시퀀스의 그래프는 DTW(Dynamic Time Warping) 거리 기반으로 구성되며, 이를 ground truth(정답)로 사용한다.
- 네트워크는 다음 시점의 그래프 구조를 예측하는 방식으로 학습되고, 예측된 그래프와 실제 그래프 간의 예측 오류가 relational discrepancy로 계산된다.
- 이 예측 오류를 이상 탐지에 활용한다.
요약
- Relational Discrepancy는 변수 간 관계의 급격한 변화를 감지하여 이상을 탐지하는 방식이다.
- GReLeN은 동적으로 학습되는 그래프 구조를 사용해 구조적 관계의 변화를 추적하고, 이를 기반으로 이상을 탐지한다.
- DyGraphAD는 예측 모델을 사용하여 DTW 거리를 통해 그래프 구조를 만들고, 예측 오류를 통해 이상을 탐지한다.
4. Hybrid and Other Discrepancies
Discrepancy 기반 프레임워크는 다양한 이상 이벤트를 탐지하고 진단하는 데 있어 각기 다른 장점을 갖고 있다.
1. Spatial 및 Temporal Anomalies 탐지
- Relational discrepancy는 변수 간 관계에서 공간적 이상을 발견할 수 있다. 이는 서로 다른 채널 간 관계에서 숨겨진 이상을 찾아내는 데 유용하다.
- 반면, forecast discrepancy는 시간적 이상(예: 급격한 상승, 계절적 불일치 등)을 탐지하는 데 유용하다.
2. 복합적인 접근법
- MTAD-GAT와 FuSAGNet은 재구성(reconstruction) 및 예측(forecast) discrepancy를 모두 활용하며, DyGraphAD는 예측과 relational discrepancy를 결합하여 이상 탐지를 강화한다.
- 이 경우, 스코어링 함수는 재구성, 예측, 또는 relational discrepancy를 결합하여 설계된다.
- 일반적으로 이상 점수는 로 계산되며, 여기서 와 는 타겟 신호 및 변수 간 관계, 와 는 예측된 신호 및 변수 간 관계를 나타낸다.
3. Prior Knowledge 활용
- GraphSAD는 여섯 가지 유형의 이상(spike, dip, resizing, warping, noise injection, left-right, upside-down)을 고려하여 훈련 데이터에 가짜 라벨을 생성한다.
- 이를 통해 비지도 학습 기반의 이상 탐지 작업을 표준 분류 작업으로 변환하고, 클래스 차이를 이상 지표로 사용한다.
요약
- Relational discrepancy는 공간적 이상을, forecast discrepancy는 시간적 이상을 잘 탐지한다.
- Hybrid 접근법을 사용하여 여러 discrepancy를 결합하고, 이를 통해 이상 탐지 성능을 향상시킬 수 있다.
- Prior knowledge를 활용하여 훈련 데이터에 가짜 라벨을 추가하고, 이를 바탕으로 이상 탐지를 분류 문제로 변환할 수 있다.
APPENDIX C. GNNs FOR TIME SERIES CLASSIFICATION
초기 시계열 분류는 거리 기반 방법과 앙상블 방법을 사용했으나, scalable하지 못하다는 한계가 존재했다.
딥러닝 기술을 활용한 시계열 분류가 이전보다 더 좋은 성능을 보여주며, 특히 대규모 데이터셋에서 효과적이다.
그리고 GNN을 활용한 시계열 예측이 좋은 성능을 보여주고 있다. GNN은 시계열 데이터를 그래프 형태로 변환하여 local 및 global 패턴을 학습하고, 서로 다른 시계열 간의 관계를 분류하는 데 효과적이다.
C.1 Univariate Time Series Classification
univariate 시계열 분류는 주어진 시계열 데이터에서 각 클래스에 맞는 패턴을 식별하여 시계열을 분류하는 작업이다. 이 작업은 시계열 내의 패턴을 분석하는 다른 시계열 분석과 차별화되며, 주로 클래스별로 구별되는 패턴을 찾아내는 데 중점을 둔다.
예를 들어, 심박수 데이터를 이용한 건강 상태 분류에서, 건강한 사람은 안정적이고 규칙적인 심박수 패턴을 보이지만, 심혈관 질환 환자는 불규칙한 리듬이나 높은 평균 심박수와 같은 패턴을 보일 수 있다. 이는 예측이나 이상 탐지와는 달리 시계열 데이터 샘플 간의 패턴 차이를 구분하는 작업이다.
univariate 시계열 분류는 Series-as-Graph와 Series-as-Node라는 두 가지 접근법이 존재한다.
Series-as-Graph
- 이 접근법은 시계열 데이터를 그래프로 변환하여 GNN(그래프 신경망)을 사용해 정확한 분류를 수행한다.
- 시계열을 서브시퀀스로 나누어 노드를 만들고, 각 서브시퀀스 간의 관계를 엣지로 표현한다.
- 예를 들어 Time2Graph 방법에서는 시계열을 연속적인 세그먼트로 나누고, 데이터 마이닝 기법을 사용해 대표적인 shapelet을 서브시퀀스에 할당한다. 이 shapelet들은 노드로 사용되고, 전이 확률을 기반으로 엣지가 형성된다.
- Time2Graph+는 이렇게 변환된 시계열을 GAT와 풀링 연산을 사용해 global representation을 얻고, 이를 classifier에 입력하여 시계열을 분류한다.
- 이 접근법은 multivariate 시계열 분류에도 적용될 수 있다.
Series-as-Node
- 이 방법은 시계열 데이터를 각각의 노드로 보고, 노드 간의 관계를 연결하는 방식을 사용한다.
- SimTSC는 시계열 샘플을 노드로 변환하고, DTW(동적 타임 워핑) 거리를 사용하여 노드 간의 관계를 엣지로 연결한다. 그 후 GNN을 적용하여 각 노드를 표현하는 벡터를 생성하고, 이 벡터를 classifier에 입력하여 클래스를 할당한다.
- LBSimTSC는 SimTSC를 확장하여 DTW의 전처리 효율을 개선하며, 계산 시간을 줄였다.
- Series-as-Node는 시계열 분류 작업을 노드 분류 작업으로 변환하며, 고전적인 거리 기반 접근법과 GNN을 결합한 방식이다.
요약
- univariate 시계열 분류는 각 시계열의 패턴을 통해 클래스별로 구별된 특징을 찾아내는 것이다.
- Series-as-Graph는 시계열 서브시퀀스를 노드로 변환하고, GNN을 사용하여 분류를 수행한다. 예시 모델로 Time2Graph가 있으며, 여기서는 shapelet 기반의 그래프 구조를 활용한다.
- Series-as-Node는 시계열 데이터를 각각의 노드로 보고, 시계열 간의 관계를 그래프 형태로 연결하여 GNN을 통해 분류한다. 이 방법은 DTW 거리 기반의 관계 설정을 사용하여 노드 간의 유사성을 확인한다.
C.2 Multivariate Time Series Classification
multivariate 시계열 분류는 univariate 시계열 분류와 기본적으로 유사하지만, 변수 간의 상호 의존성(inter-variable dependencies)을 따진다는 차별점이 존재한다.
예시)
건강 데이터 분석: 예를 들어, 심박수만 고려하는 대신, 환자의 여러 건강 데이터(혈압, 혈당, 산소포화도 등)을 사용한다. 각 건강 데이터는 환자의 특정 건강 지표를 반영하는 독립적인 시계열을 제공하며, 이를 다변량 분석을 통해 함께 고려하면, 단일 시계열에서 나타나지 않는 복잡하고 상호 연관된 건강 패턴을 포착할 수 있다.
그래프 기반 접근법 (GNN 활용)
- 위 예시에서 여러 변수들 간의 관계는 네트워크 그래프로 생각할 수 있다. 이는 변수들 간의 관계를 모델링하는 데 효과적이다.
- 공간-시간 GNN (STGNN): 시계열 분류에서 공간적 및 시간적 의존성을 포착하는 STGNN 구조는 매우 유용하다. 이 구조에서는 최종 레이어를 classify 구성요소로 교체하여 multivariate 시계열 분류를 수행할 수 있다.
- 이러한 STGNN 아키텍처는 시계열 데이터의 복잡성을 쉽게 해석할 수 있도록 고차원 시계열 데이터를 더 간결하고 표현력 있게 변환하여, 시계열을 각 클래스에 맞게 구분할 수 있게 해준다.
Raindrop 아키텍처
- Raindrop은 불규칙하게 샘플링된 데이터에 대해 잘 동작하는 모델이다. 일부 변수의 값 중 특정 시간에 결측값이 발생할 경우, 그래프 구조를 적응적으로 학습하여 결측된 값을 예측한다. 이를 통해 샘플링의 불규칙성에도 불구하고 정확한 분류를 유지할 수 있다.
- Raindrop은 이런 유연성을 통해 불규칙한 샘플링과 결측 데이터가 있는 상황에서도 강력한 분류 성능을 유지할 수 있다는 것이 입증되었다.
요약
- multivariate 시계열 분류는 단일 시계열 분석에 비해 변수 간 관계를 추가로 고려해야 하는 복잡성을 가진다.
- 공간-시간 GNN (STGNN)은 시간적 및 변수 간 의존성을 잘 포착할 수 있는 강력한 구조다.
- Raindrop 아키텍처는 결측값과 불규칙한 샘플링에도 강한 성능을 보이며, 이를 통해 multivariate 시계열 분류에서 GNN의 유연성과 효과성을 강조한다.
APPENDIX D. GNNs FOR TIME SERIES IMPUTATION
시계열 데이터 imputation은 결측값을 추정하는 중요한 작업으로, 여러 실제 응용 분야에서 사용된다. 초기의 시계열 imputation 방법에는 통계적 기법을 사용해 왔습니다. 예를 들어, 평균 imputation, 스플라인 imputation, regression 모델 등이 있다. 하지만 이러한 방법들은 복잡한 시간적 의존성과 비선형 관계를 잘 포착하지 못하는 제약이 있다. 최근에는 그래프 신경망(GNN)을 활용한 방법들이 등장하면서 이러한 한계를 극복할 수 있게 되었다. GNN 기반 시계열 imputation은 공간적 및 시간적 의존성을 더 잘 모델링하여 실제 시나리오에 적합한 해결책을 제공한다.
1. GNN을 활용한 시계열 imputation의 종류
- In-sample Imputation:
- In-sample imputation은 주어진 시계열 데이터 내에서 결측값을 채우는 작업이다.
- 예시:
- GACN은 GAT (Graph Attention Network)와 temporal convolution 계층을 결합하여 시계열의 공간-시간적 의존성을 모델링하고, 결측값을 채운다.
- SPIN은 과거 관찰치와 센서 데이터를 결합하여 시계열 표현을 얻고, 이를 다층 sparse 공간-시간 어텐션 블록을 통해 처리하여 결측값을 보완한다.
- GRIN은 그래프 순환 신경망(Graph Recurrent Imputation Network)을 도입하여 공간-시간 인코더와 다양한 imputation executor를 사용해 결측값을 보완한다.
- PriSTI와 같은 probabilistic imputation 방법은 imputation을 generation task으로 보고, 공간-시간적인 denoising 네트워크를 사용해 결측값을 효과적으로 샘플링한다.
- Out-of-sample Imputation:
- Out-of-sample imputation은 주어진 데이터와 다른 시점이나 변수에서 결측값을 보완하는 작업이다.
- 예시:
- IGNNK는 새로운 변수나 "가상 센서"와 같은 미관측 시계열의 신호를 복원하기 위해 유도적 GNN 크리깅 모델을 제안하고 있다.
- SATCN은 공간 집합 네트워크와 시간 합성곱을 결합하여 공간-시간적 의존성을 모델링하고, 실시간으로 시계열 크리깅을 수행한다.
- INCREASE는 이질적인 공간적 및 다양한 시간적 관계를 고려하여 유도적 공간-시간 크리깅의 성능을 향상시켰다.
2. imputation 방법의 분류
- Deterministic Imputation: 결측값에 대해 하나의 최적 추정값을 결정한다.
- Probabilistic Imputation: imputation 과정에서의 불확실성을 고려하여 결측값의 분포를 제공한다.
요약
- 초기 전통적인 시계열 imputation 방법은 비선형 관계와 복잡한 시간적 의존성을 잘 처리하지 못하는 반면, GNN 기반 방법은 시계열 데이터의 공간적 및 시간적 의존성을 잘 포착한다.
- GNN을 활용한 시계열 imputation은 샘플 내와 샘플 외 imputation으로 나뉘며, 각각 결측값을 채우는 작업과 다른 시계열에서 예측하는 작업을 수행한다.
- 결정론적(deterministic)과 확률적(probabilistic) imputation 방법으로 나뉘며, 확률적 방법은 결측값 예측에서 불확실성을 고려하여 보다 유연한 모델링을 가능하게 한다.
APPENDIX E. PRACTICAL APPLICATIONS
- Smart Transportation
- 교통 속도 및 교통량 예측: 공간-시간 GNN을 활용하여 정확한 교통 예측을 수행함으로써 경로 계획 및 교통 혼잡 관리에 기여.
- 교통 데이터 보완(Traffic Data Imputation): 누락된 데이터를 보정하여 교통 데이터베이스의 신뢰성을 유지하고 분석 정확도를 향상.
- 자율주행(Autonomous Driving): GNN을 활용한 3D 객체 탐지 및 이동 경로 계획을 통해 도로 안전 및 교통 효율성을 개선.
- 항공기 지연 예측(Flight Delay Prediction): 날씨, 항공 교통량, 기체 유지보수 일정 등을 분석하여 항공기 지연을 예측하고 운영 효율성을 증대.
- On-demand Services
- 차량 호출 서비스(Ride-hailing): GNN을 통해 지역별 수요 패턴을 분석하여 차량 배치를 최적화.
- 공유 자전거(Bike-sharing): 공간-시간 패턴을 분석하여 수요를 예측하고 자전거 배치 및 유지보수 일정 최적화.
- 에너지 수요 예측(Energy Demand Prediction): 에너지 사용 패턴을 모델링하여 자원 관리 효율성을 향상.
- 관광 수요 예측(Tourism Demand Prediction): 시계열 및 공간 의존성을 분석하여 관광 수요를 예측하고 관광 인프라를 최적화.
- 배송 수요 예측(Delivery Demand Prediction): 공간-시간 동적 패턴을 모델링하여 물류 및 배송 계획을 최적화.
- Environment & Sustainable Energy
- 풍력 및 태양광 발전 예측: GNN을 활용하여 바람 및 태양광 에너지 패턴을 분석하고 발전량을 예측하여 에너지 관리 최적화.
- 시스템 모니터링: 풍력 터빈 및 태양광 패널의 성능을 분석하여 유지보수 및 결함 감지 수행.
- 대기 오염 예측(Air Pollution Prediction): 공기질 데이터의 공간-시간 패턴을 모델링하여 오염 수준을 예측하고 관리 전략 수립.
- 기상 예측(Weather Forecasting): 기후 데이터의 복잡한 패턴을 분석하여 정밀한 날씨 예측을 수행.
- IoT, Internet-of-Things
- GNN을 활용하여 IoT 네트워크의 공간-시간 관계를 모델링하고, 다양한 산업 분야(로봇, 공장, 공공서비스, 스포츠 분석 등)에서 IoT 데이터 해석 및 활용.
- Physical Systems
- N-body 시스템 시뮬레이션, 입자 물리학, 인간 동작 모델링, 분자 역학 시뮬레이션 등 다양한 물리 시스템에서 GNN을 활용하여 객체 간의 상호작용을 모델링.
- Healthcare
- 의료 진단 및 치료: 전자의무기록(EMR), EEG, MRI, 신경영상 데이터 등의 복잡한 관계를 분석하여 질병 진단 및 치료 지원.
- 공중 보건 관리: 의료 장비의 수명 예측, 구급차 수요 예측, 전염병 확산 모델링 및 대응 전략 수립.
- Fraud Detection
- GNN을 활용하여 사기 네트워크의 관계 및 시간적 패턴을 분석하고, 소셜 네트워크, 금융 시스템, 기타 산업에서 이상 탐지 수행.
- Others
- 금융(Finance), 도시 계획(Urban Planning), 전염병 통제(Epidemic Control), 추천 시스템(Recommender Systems), 제조업(Manufacturing) 등 다양한 산업에서 GNN4TS(Graph Neural Networks for Time Series) 기술이 활용될 전망.
APPENDIX F. DATASETS AND IMPLEMENTATIONS
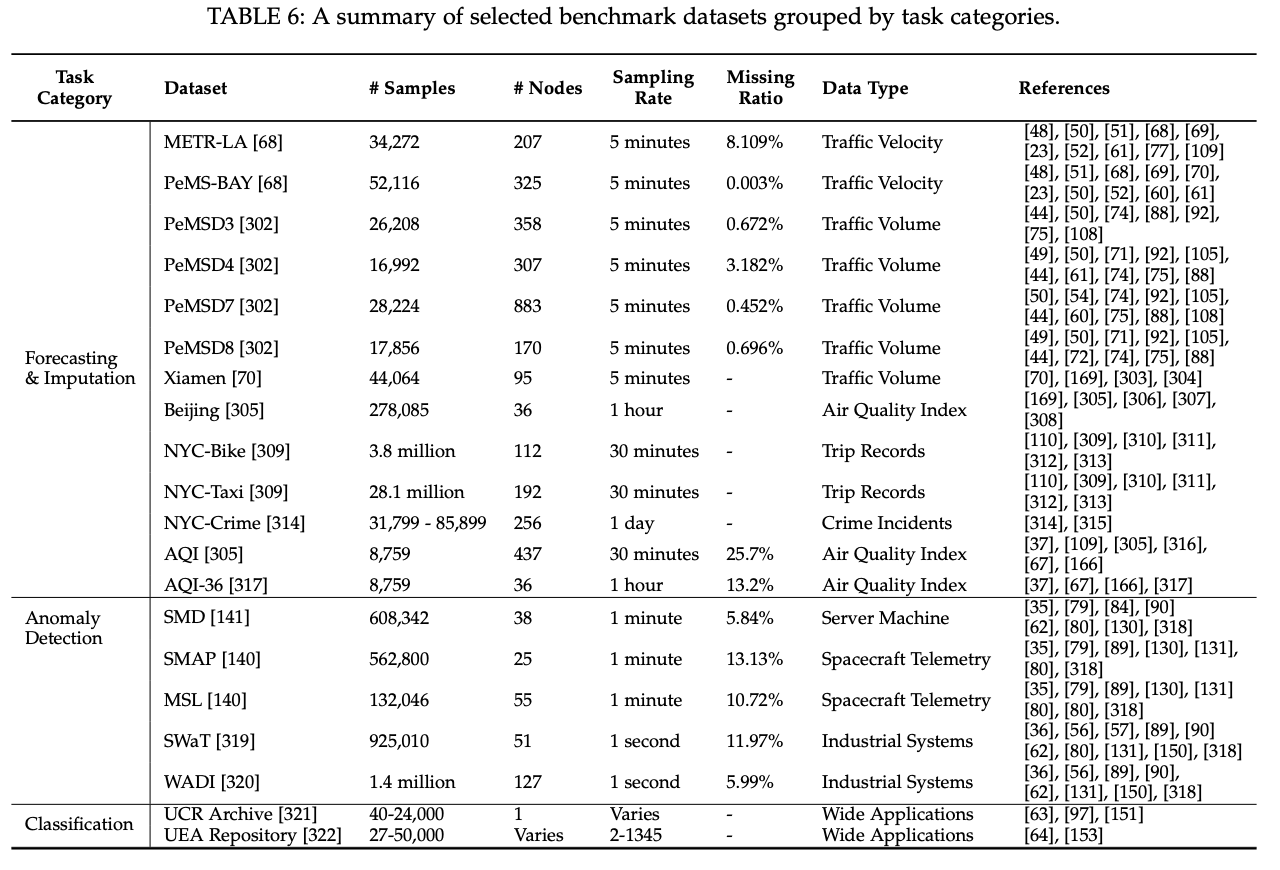
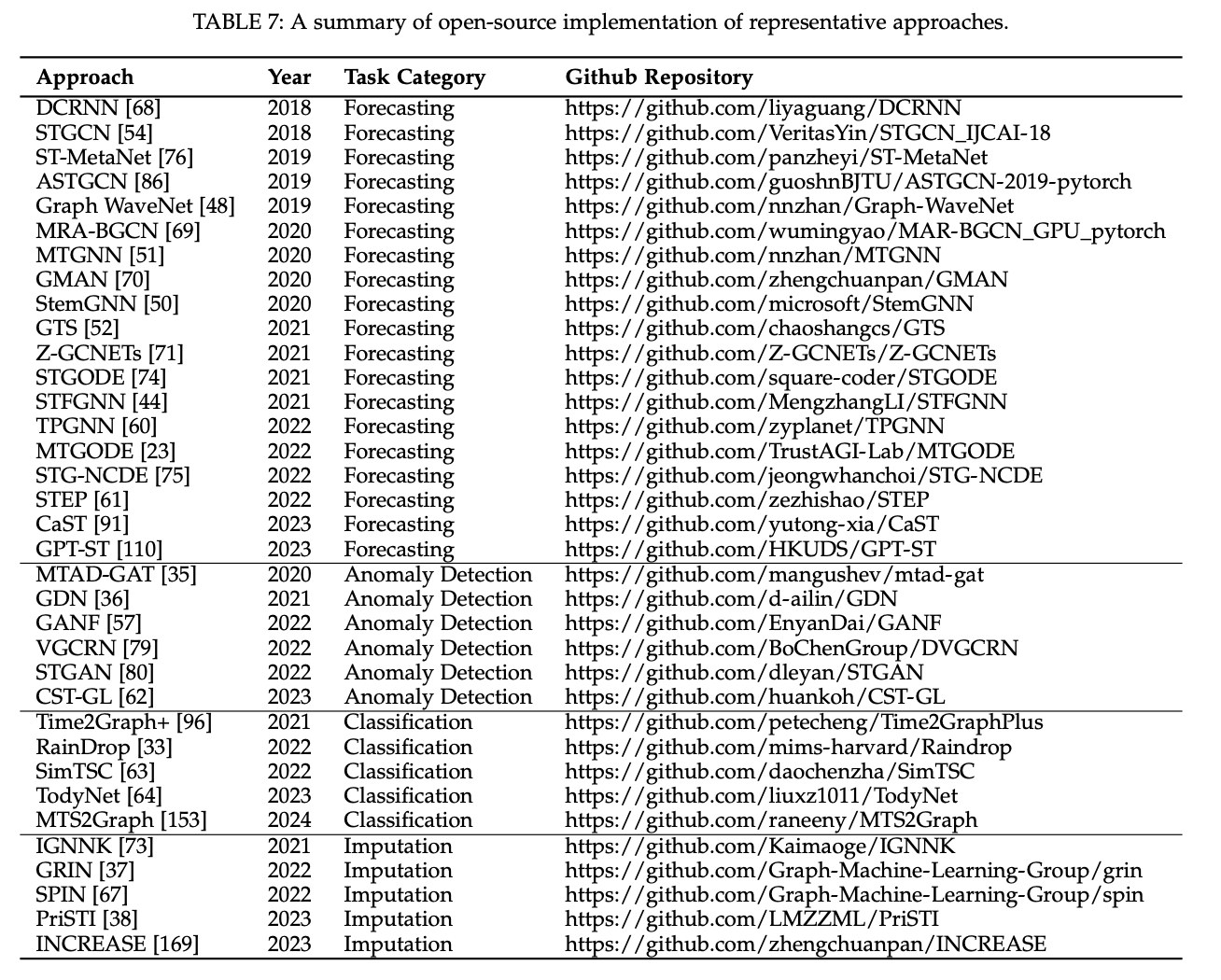
대표적인 시계열 분석 모델과 이를 평가하는 공개된 벤치마크 데이터셋을 정리하였다. 주요 벤치마크는 Forecasting & Imputation, Anomaly Detection, 분류Classification로 구분된다.
1. Forecasting & Imputation 벤치마크
- 교통 예측 데이터셋
- METR-LA: 2012년 3월 1일부터 6월 30일까지 LA 고속도로 207개 센서에서 수집한 속도 데이터.
- PEMS-BAY: 2017년 1월 1일부터 5월 31일까지 캘리포니아 교통국(CalSTA)에서 수집한 Bay Area 325개 센서의 속도 데이터.
- PeMSD3, PeMSD4, PeMSD7, PeMSD8: 캘리포니아 교통 측정 시스템(PeMS)에서 30초 간격으로 수집한 데이터를 5분 단위로 집계. 주요 변수는 교통량.
- Xiamen: 2015년 8월 1일부터 12월 31일까지 중국 샤먼의 95개 센서에서 수집한 5분 단위의 교통 데이터.
- 공기질 및 도시 데이터셋
- Beijing: 2014년 5월 1일부터 2015년 4월 30일까지 중국 베이징 36개 센서에서 수집한 PM2.5 농도 데이터.
- AQI: 중국 43개 도시의 437개 모니터링 스테이션에서 수집한 공기 질 지수(PM2.5 중심). AQI-36은 36개 센서만 포함한 축소 버전.
- 기타 도시 데이터셋
- NYC-Taxi: 2015년 1월 1일부터 3월 1일까지 뉴욕시 택시 운행 기록 데이터.
- NYC-Bike: 2016년 7월 1일부터 8월 29일까지 NYC Citi Bike 시스템에서 수집한 자전거 이동 데이터.
- NYC-Crime: 뉴욕시에서 발생한 범죄 기록 데이터(강도, 절도 등). 공간 해상도는 1km × 1km 그리드.
2. Anomaly Detection 벤치마크
- 주요 데이터셋:
- SMD, MSL, SMAP, SWAT, WADI: 시계열 이상 탐지를 위한 대표적인 데이터셋.
- 연구 동향:
- 기존 데이터셋이 현실적인 이상 탐지 시나리오를 충분히 반영하지 못한다는 비판이 있다.
- 이를 보완하기 위해 내부적으로 수집한 데이터셋과 새로운 벤치마크 개발이 이루어지고 있다.
3. Classification 벤치마크
- UCR Archive: 단변량(Univariate) 시계열 분류를 위한 대표적인 데이터셋.
- UEA Repository: 다변량(Multivariate) 시계열 분류를 위한 데이터셋.
- 연구 동향:
- 다양한 도메인에서 수집한 데이터셋을 기반으로 시계열 분류 연구가 활발히 진행되고 있다.
- 다양한 방법론을 비교 분석하는 Bakeoff 연구가 진행되며, 평가 기준 개선 및 모델 간 공정한 비교가 강조되고 있다.
APPENDIX G. FUTURE DIRECTIONS
- Pre-training and Transfer Learning
- 기존에 학습한 표현을 다른 유사한 도메인에 적용하여 성능을 개선하는 방식이다.
- 데이터가 부족하거나 다양한 경우, pre-training과 transfer learning이 GNN의 성능을 향상시키는 중요한 전략으로 떠오르고 있다.
- 예시:
- COVID-19 확산 예측을 위한 모델-독립적 메타 학습(schema) 적용.
- 공간-시간 GNN의 사전 학습 강화 프레임워크.
- 대규모 pre-training을 위해서는 충분한 시계열 데이터가 필요하지만, LLM 대비 데이터가 부족한 것이 한계점으로 꼽힌다.
- Robustness
- GNN의 robustness는 데이터 변형 및 분포 변화에 대한 강인함을 의미하며, 특히 의도적인 공격(adversarial attacks)에도 잘 방어할 줄 알아야 한다.
- smart city(교통 관리), healthcare(치료 시기 결정) 등에서는 GNN의 오류가 심각한 문제를 초래할 수 있다.
- GNN의 신뢰성을 높이고, 실패 관리 전략을 개발하는 것이 중요하다.
- Interpretability
- GNN의 의사결정 과정을 이해하고 신뢰할 수 있게 만드는 것이 중요하다.
- Interpretability(해석 가능성)가 높아지면, 데이터 내 숨겨진 패턴을 발견하고 투명한 모델 운영이 가능해진다.
- 예시:
- 신약 개발에서 인과 관계를 분석하여 보다 나은 의사결정을 지원.
- 금융 시계열 분석에서 원인을 밝히고, 투자 전략 수립에 도움을 준다.
- Uncertainty Quantification
- 시계열 데이터는 본질적으로 노이즈가 많고 불확실성(Uncertainty)이 크다.
- 모델의 불확실성을 정량화하면 예측의 신뢰도를 높이고, 위험을 줄이는 데 도움을 줄 수 있다.
- 금융 예측, 의료 모니터링, 스마트 시티 트래픽 예측 등 고위험 환경에서 특히 중요하다.
- 현재 대부분의 GNN 모델은 단일 값(point estimate)만 제공한다는 한계가 있다. 따라서, 불확실성을 고려한 새로운 접근법이 필요하다.
- Privacy Enhancing
- GNN이 관계 데이터(노드 및 엣지)를 학습하면서 민감한 정보를 포함할 수 있다.
- 특히 금융, 의료 등 데이터 보호가 중요한 분야에서는 GNN의 학습 과정에서 프라이버시를 보장하는 것이 필수적이다.
- interpretability 강화가 보안 취약점을 초래할 수도 있어, interpretability와 privacy enhacing 간의 트레이드 오프를 잘 고려해야 한다.
- Scalability
- 대규모 시계열 데이터(예: 수십억 개의 소셜 네트워크 관계)를 다룰 때 GNN은 scalability(확장성) 관련 문제점이 있다.
- 전통적인 GNN은 전체 인접 행렬(adjacency matrix)과 노드 임베딩을 계산하여 메모리 사용량이 매우 크다는 한계가 있다.
- 샘플링 기법(node-wise, layer-wise, graph-wise)을 적용하더라도 시간 의존성을 유지하는 것은 힘들다.
- 따라서 이를 보완하기 위해, 엣지 디바이스 환경에서 GNN을 효율적으로 실행할 수 있도록 최적화하는 연구가 대두되고 있다.
- AutoML and Automation
- GNN 모델은 아키텍처 설계 및 하이퍼파라미터 튜닝이 필요하므로, 이를 자동화하면 효율성과 확장성을 향상할 수 있다.
- 다양한 모델 아키텍처가 존재하기 때문에, 최적의 모델을 선택하는 것은 어렵다.
- AutoML은 이러한 GNN의 선택 및 최적화를 자동화하여, 보다 효과적인 시계열 분석이 가능하도록 지원할 수 있다.
- 그러나 항상 최적의 선택이 아닐 수 있기에, 다른 기법과의 비교 및 평가가 필요하다.
느낀 점
본 서베이 논문을 읽으면서 GNN4TS(GNN for time-series) 모델에 대한 전체적인 구조와 그 종류를 배웠다. GNN은 이제 막 활발히 연구되고 있는 분야이기에, 이를 시계열 데이터에 활용하면 기존의 딥러닝 모델보다 더 좋은 성능을 보여줄 수 있는 모델을 만들 수 있을 것 같다는 생각이 든다. 이제 막 연구 분야를 구체화하고 있는 나로서는 읽기 잘했다는 생각이 드는 서베이 논문이었다. 해당 서베이 논문을 기점으로 앞으로 어떤 걸 공부해야 하는지에 대해 방향이 서서히 잡히는 것 같다.
해당 논문에 대한 정보와 논문에서 나오는 데이터셋 및 모델에 대한 정리는 다음 github 주소에서 볼 수 있다. https://github.com/KimMeen/Awesome-GNN4TS/tree/main
