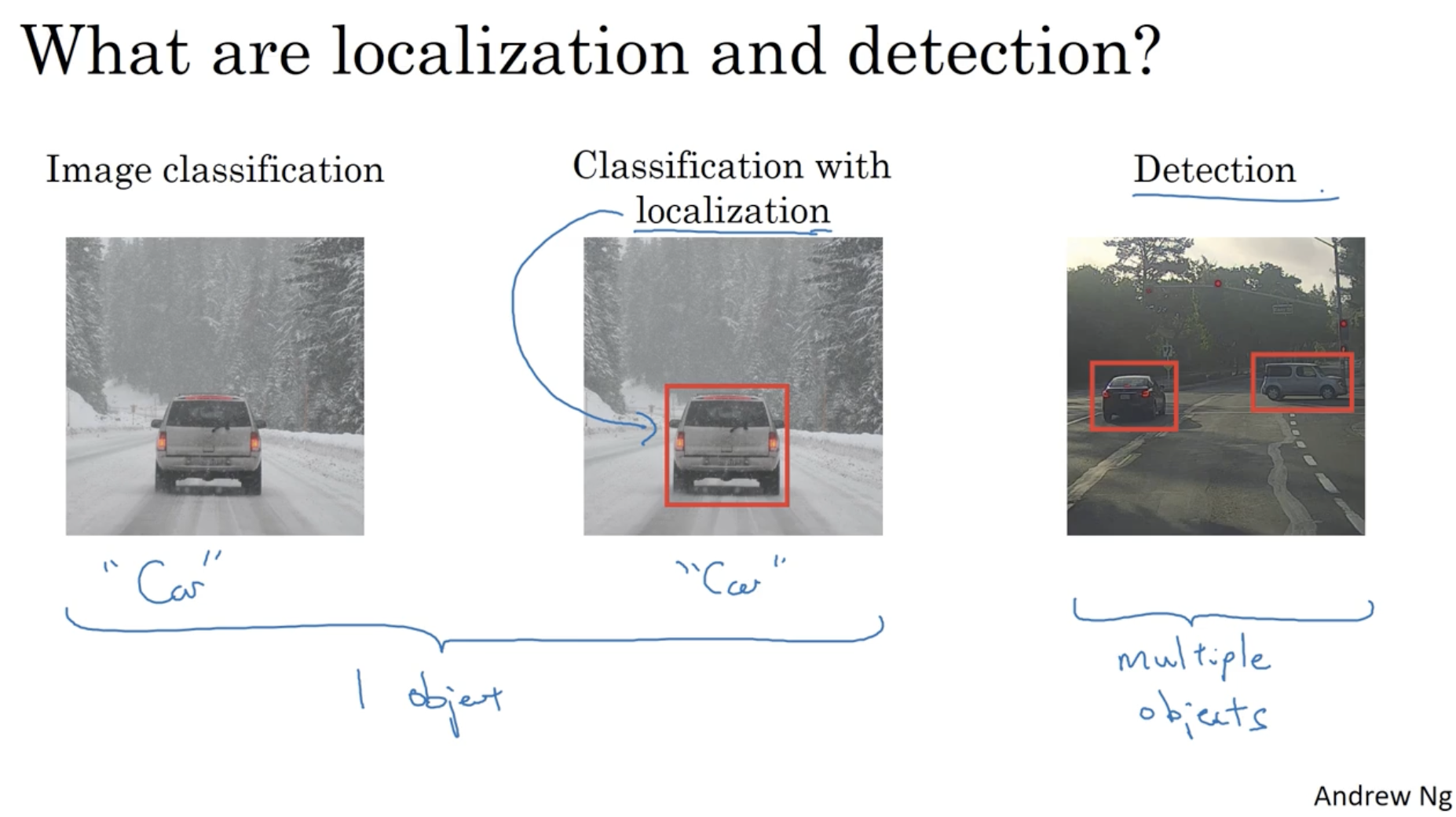
다음은 컴퓨터 비전의 주요 연구 분야 중 하나인 object detection 에 대한 내용이다.
- 좌측과 같이 image classification + localization 을 합쳤을 때, 하나의 object 를 detect 하는 경우가 있으며,
- 우측과 같이 여러 개의 objects 를 detect 하는 경우가 있다.
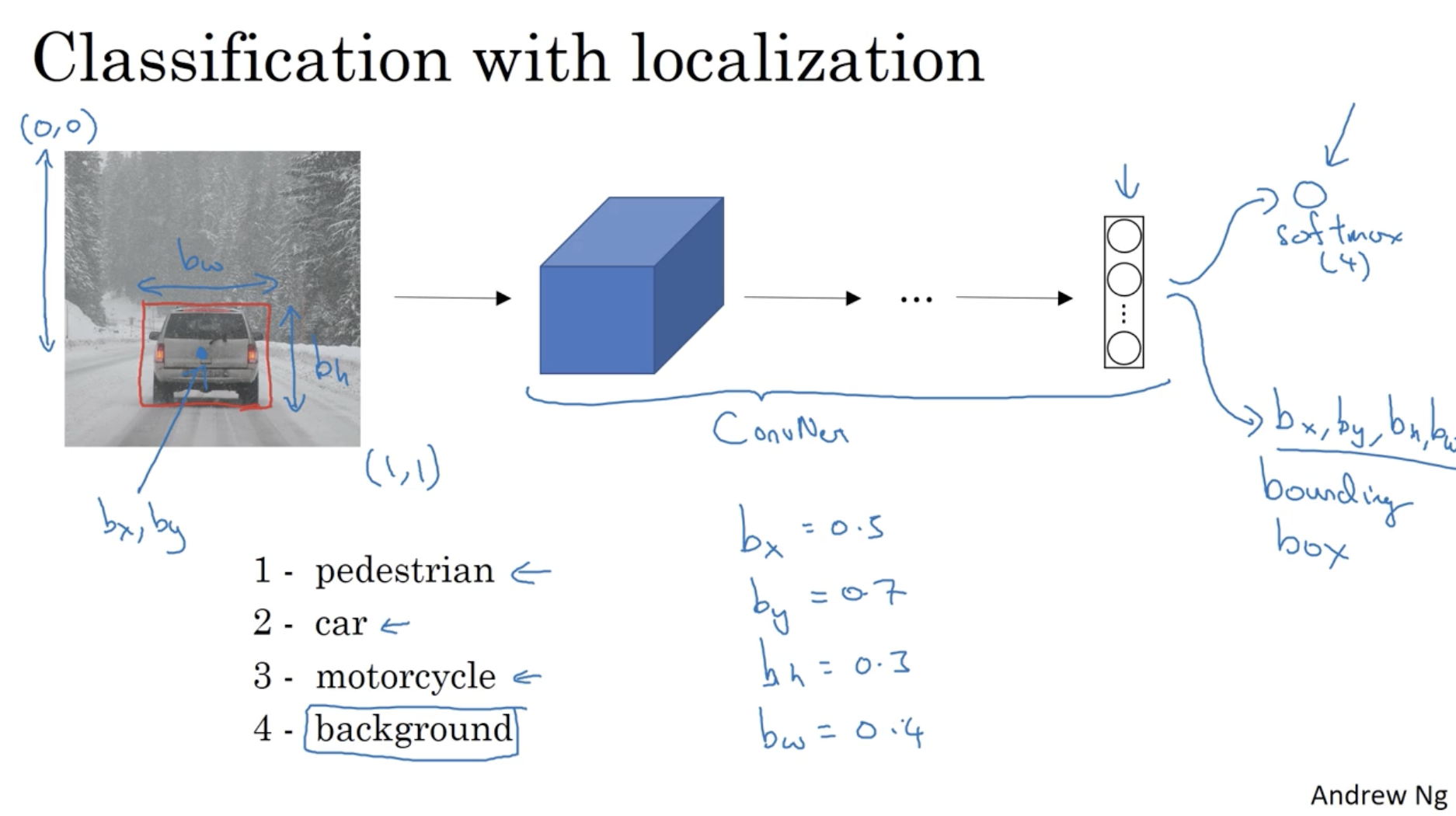
하나의 object 에 대해서 detect 한다고 가정해보자.
- 아래에서 object 에 대한 y 값이 주어졌다고 해보자( supervised learning ). y 값에는 다음과 같은 정보가 포함되어 있어야 한다. (이미지 클래스, bounding box 의 좌표 및 길이와 높이)
- 좌측 그림의 경우 y 데이터는 다음과 같을 것이다. (2, 0.5, 0.7, 0.3, 0.4) (bounding box 값들은 모두 원본 이미지에 대한 비율로 결정된다.)
- 모델의 학습 과정은 비교적 간단하다. conv. -> ... -> softmax (classification) + bounding box 으로 이루어져 있다.
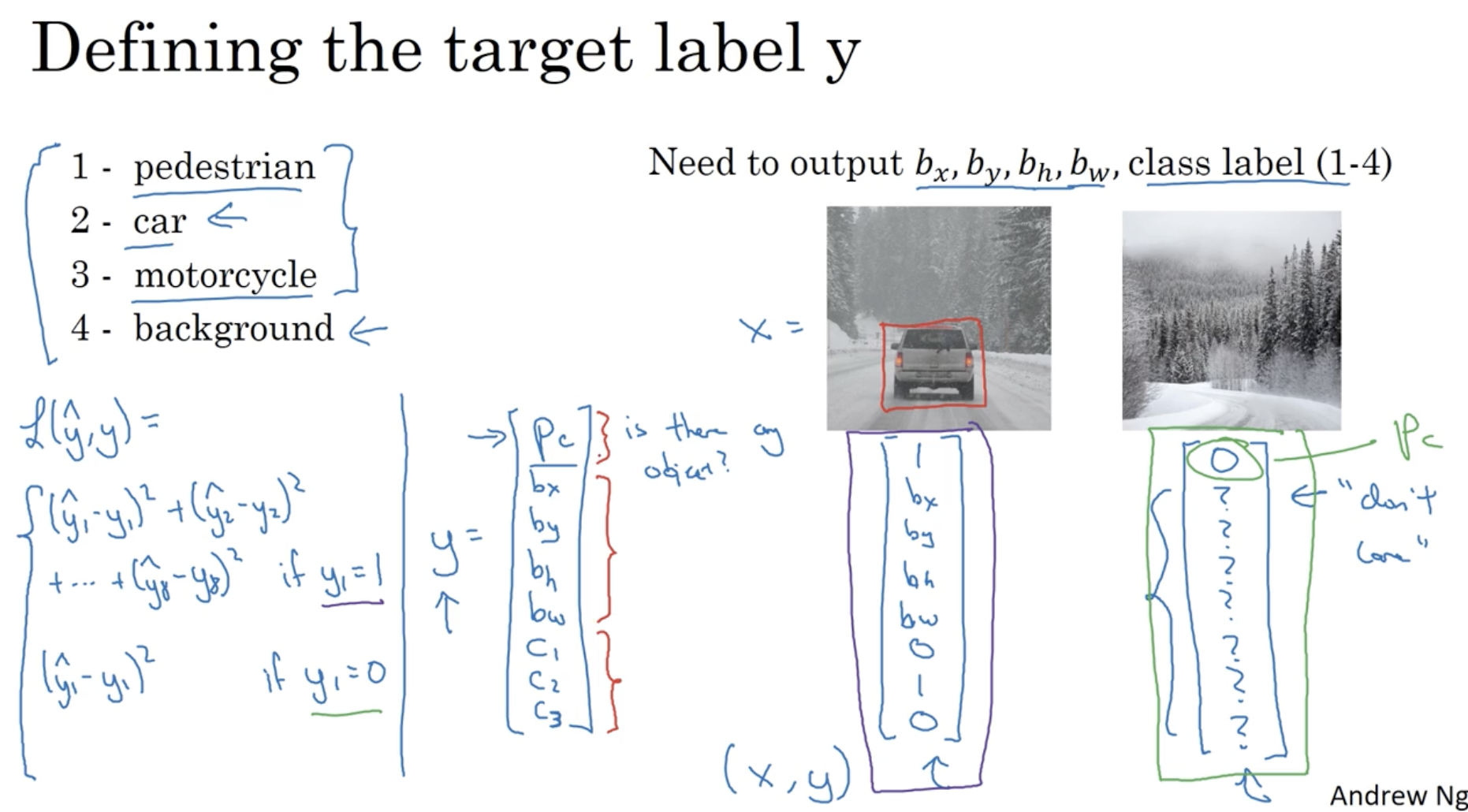
구체적인 예시를 적용하여서 보면 아래와 같다.
- 입력 이미지 에 대한 출력값 는 다음과 같다.
- : 이미지에 object 가 존재할 확률.
- : object 의 bounding box 정보
- : object 의 각 클래스에 대한 확률.
- 그리고 이를 아래 이미지 중 좌측에 적용하면, 는 다음과 같을 것이다.
- 그리고 우측 이미지에 대한 값은 다음과 같다. . 이 경우 이미지 내에 object 가 존재하지 않으므로 값을 제외한 나머지 값은 어떻게 나오든 don't care 이다.
- 그리고 이를 위한 Loss function 은 다음과 같다. (squared error 라고 가정한다.)
- 물론 위와 같이 단순한 squared error 로 적용해도 큰 문제는 없지만 각각 에는 logistic error, 에는 squared error, ... 처럼 각각 적용해도 된다. (하지만 단순하게 전체를 squared error 로 해도 괜찮다.)
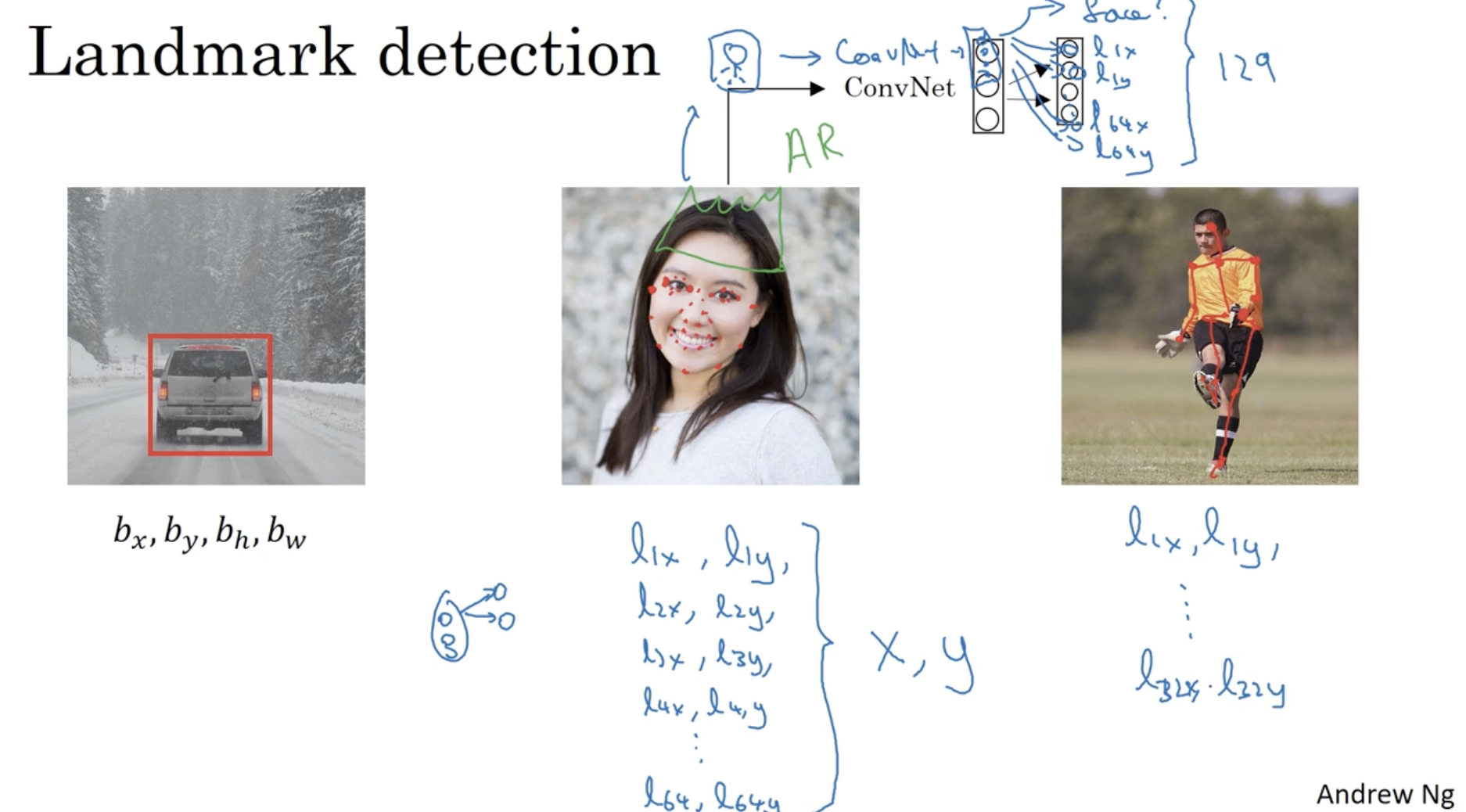
object detection 을 자세히 알아보기 전에 landmark detection 개념을 알아보자.
- 아래와 같이 bounding box 처럼 landmark point 들의 위치를 학습할 수도 있다.
- 중앙 이미지에서 face에 해당하는 landmark point 를 가져올 수도 있고, (그리고 이 경우 landmark 좌표를 활용하여 AR 분야에 적용할 수도 있다. 예를 들어 아래 사진에서 머리에 해당하는 landmerk 좌표에 왕관을 삽입하는 등.)
- 그리고 우측 이미지처럼 몸짓에 해당하는 주요 관절 등의 landmark 좌표를 가져올 수도 있다.
- 이러한 개념이 landmark detection 이다.
다음으로 sliding window detection 에 대해서 알아보자.
- 아래와 같이 window 내 이미지에 ConvNet 을 적용하여 이 클래스가 1인지 (차량인지)를 확인한다.
- 그리고 이를 스텝 사이즈에 맞게 이미지 끝에 도달할 때까지 반복한다.
- window size 를 키우면서 확인한다.
- 이와 같은 과정을 통해서 bounding box 로서 사용이 가능하며, object detection 과정에 활용이 가능하다.
- 하지만 위와 같이 window 마다 ConvNet 을 적용하여 클래스를 추출해야하는 등, sliding window detection 의 경우 비용이 매우 많이 든다는 단점이 존재한다.
- 따라서 이를 보완하는 방법이 필요하다.



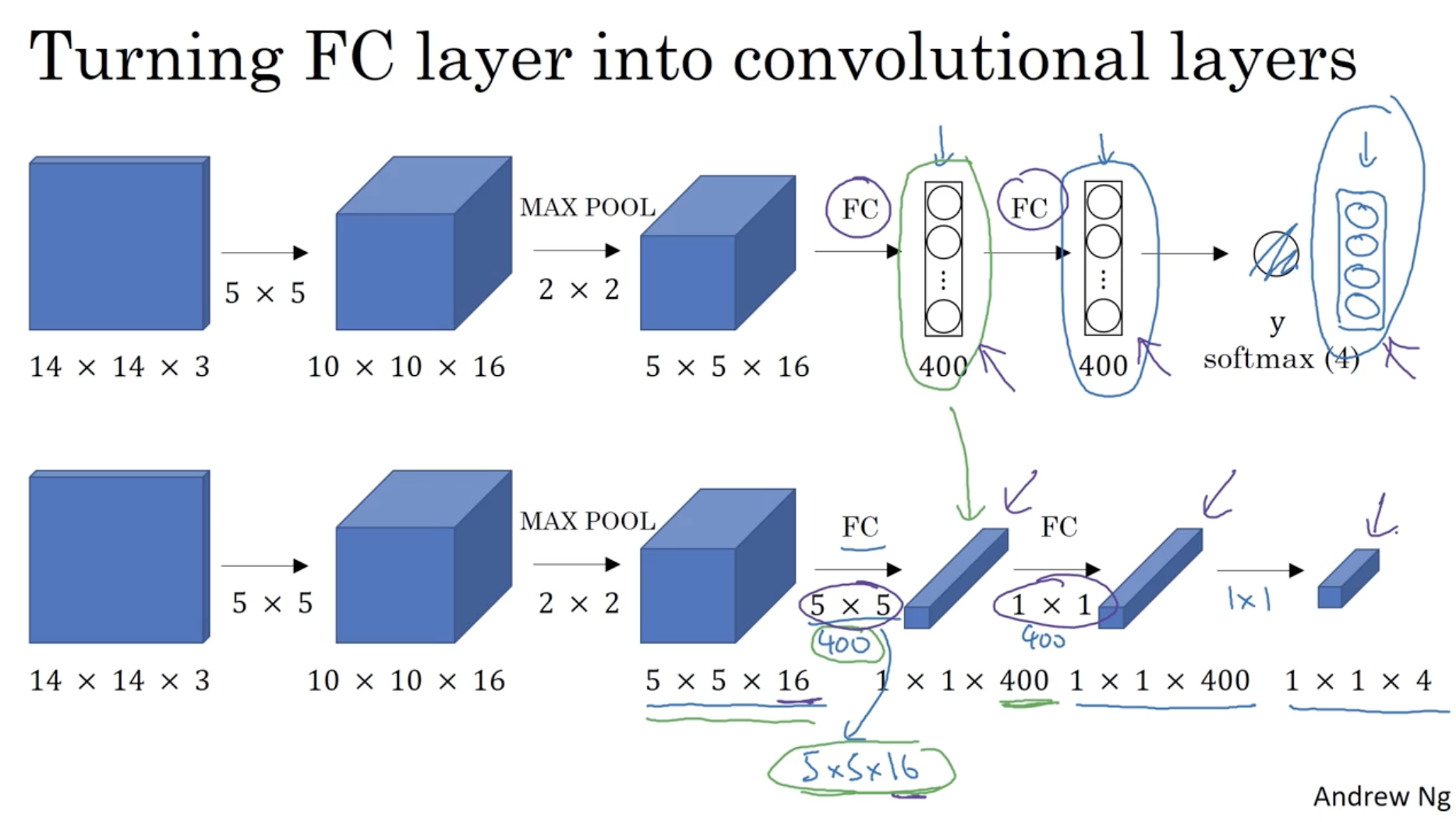
Fully connected layer ( FC layer ) 를 convolutional layer 로 변환하는 방법은 아래와 같다.
- (400, 1) FC 에 대해서 1 x 1 x 400 과 같은 데이터로 만들어주면 된다.
- 이때 사용되는 filter 는 400개의 5 x 5 x 16 사이즈 필터를 적용하면 된다.
- 이처럼 FC layer 를 1 x 1 conv. 으로 적용하여 conv. layer 로 만들 수 있다.
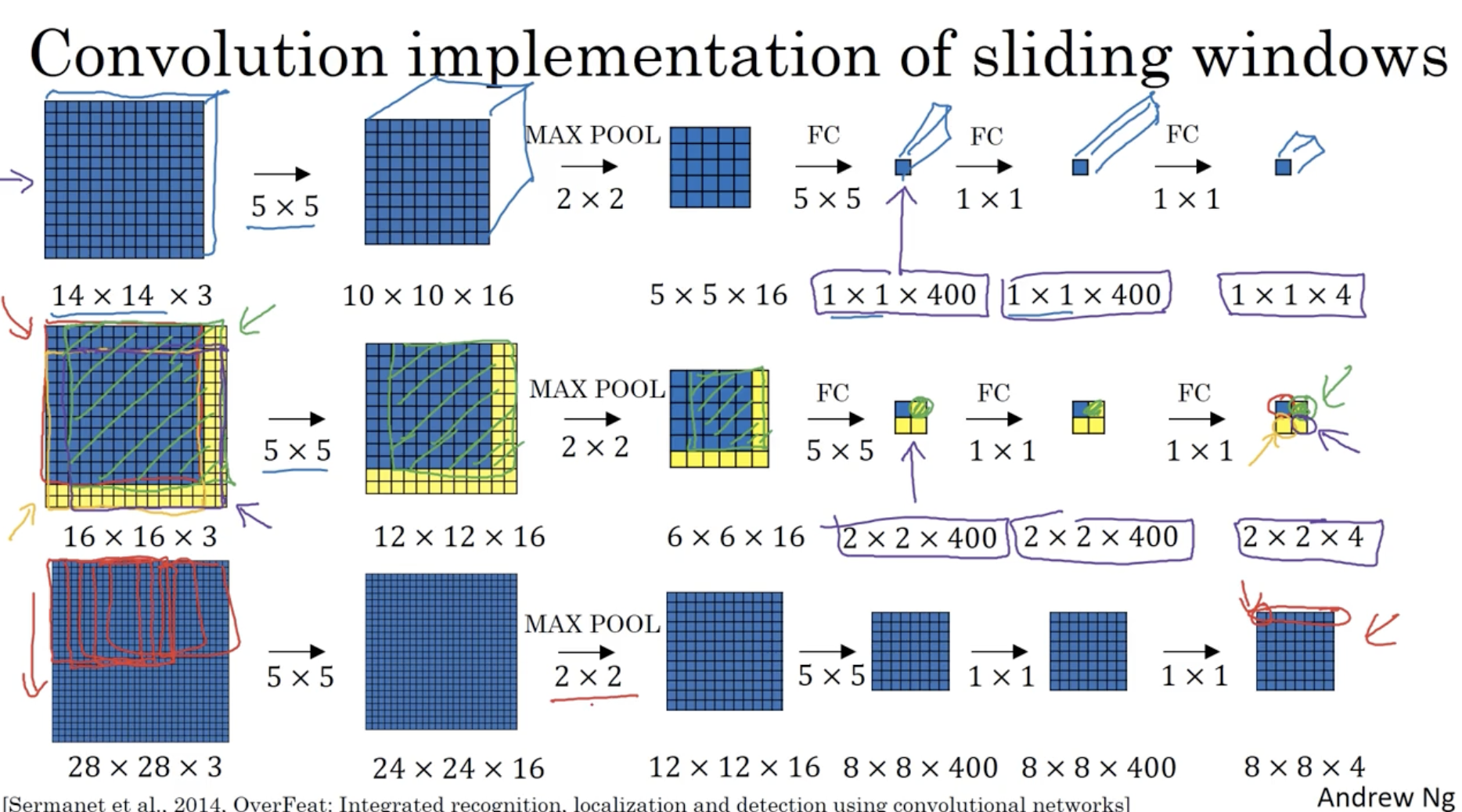
그리고 이 개념을 sliding window 에 적용하여 sliding window 를 convolution layer 로 구현하면 다음과 같다.
- window의 크기가 14 x 14 라고 가정하자.
- 상단 convNet 은 하나의 window 에 대해서 classification 을 하는 convNet 이다.
- 그리고 중간 convNet 은 16 x 16 이미지에 대한 convNet 으로, 14 x 14 window 에 대해서 conv. layer 를 적용하여 한번에 2 x 2 영역에 대한 각 window 의 classification 을 구한다.
- 마찬가지로 하단 convNet 은 28 x 28 이미지에 대해서 14 x 14 window 를 적용하여, 한번에 8 x 8 영역에 대한 각 window 의 classification 을 구현하였다.
- (여기서 max pooling 및 sliding step 사이즈 stride = 2 이다.)
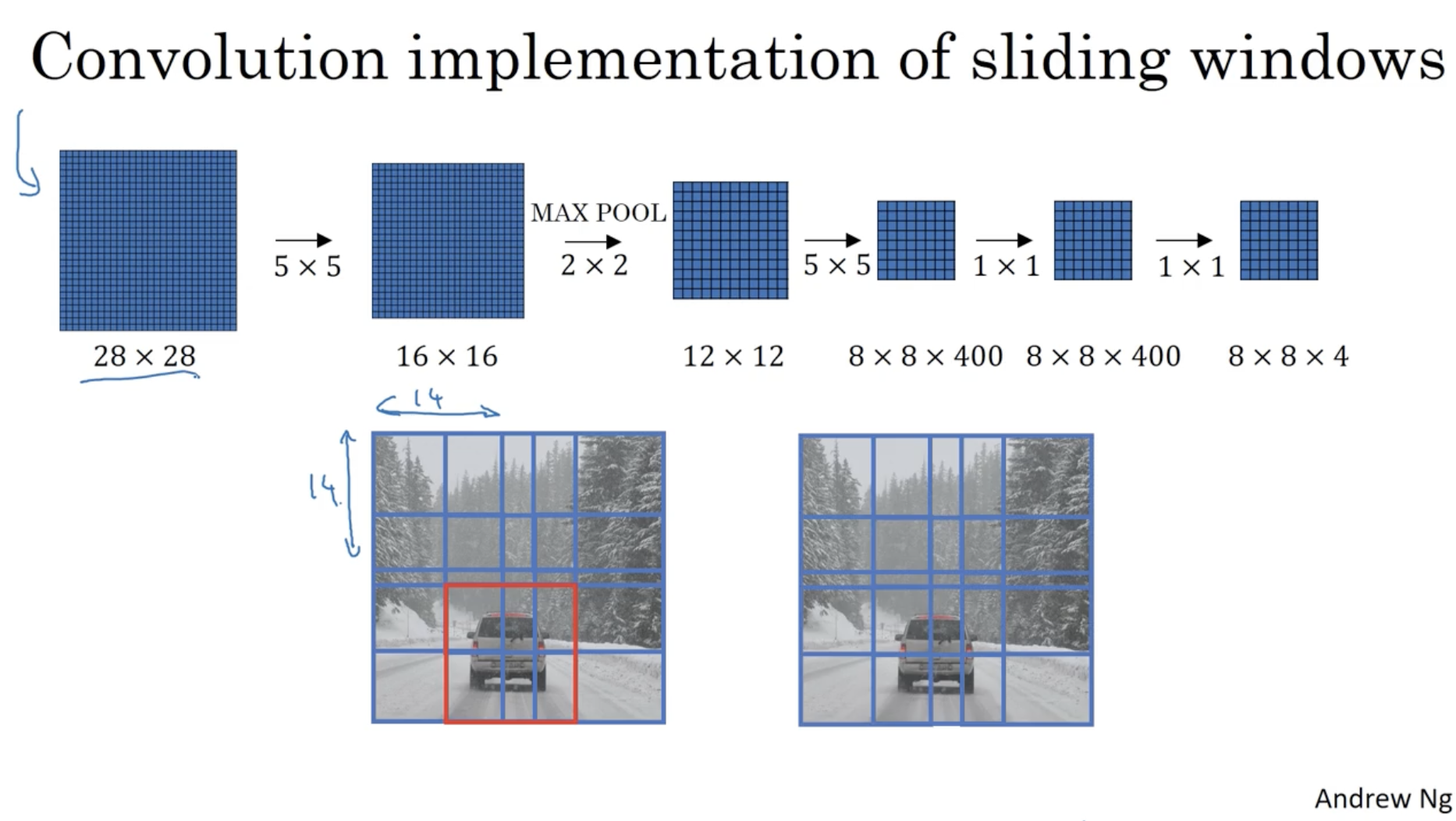
따라서 기존의 sliding window 가 같던 반복되는 연산을 한 번의 convNet 으로 연산하여 한꺼번에 각 window 영역에 대한 classification 이 가능해졌다.
- 그렇다면 어떻게 최적의 bounding box 를 구할 수 있을까? 다음 슬라이드를 보자.
위와 같은 방식으로 적용할 경우, 아래 파란색 bounding box 처럼 정답 bounding box 인 빨간색과는 거리가 먼 bounding box 를 선택할 것이다. 하지만 에러가 있어 보인다. 어떻게 이를 해결할 수 있을까?

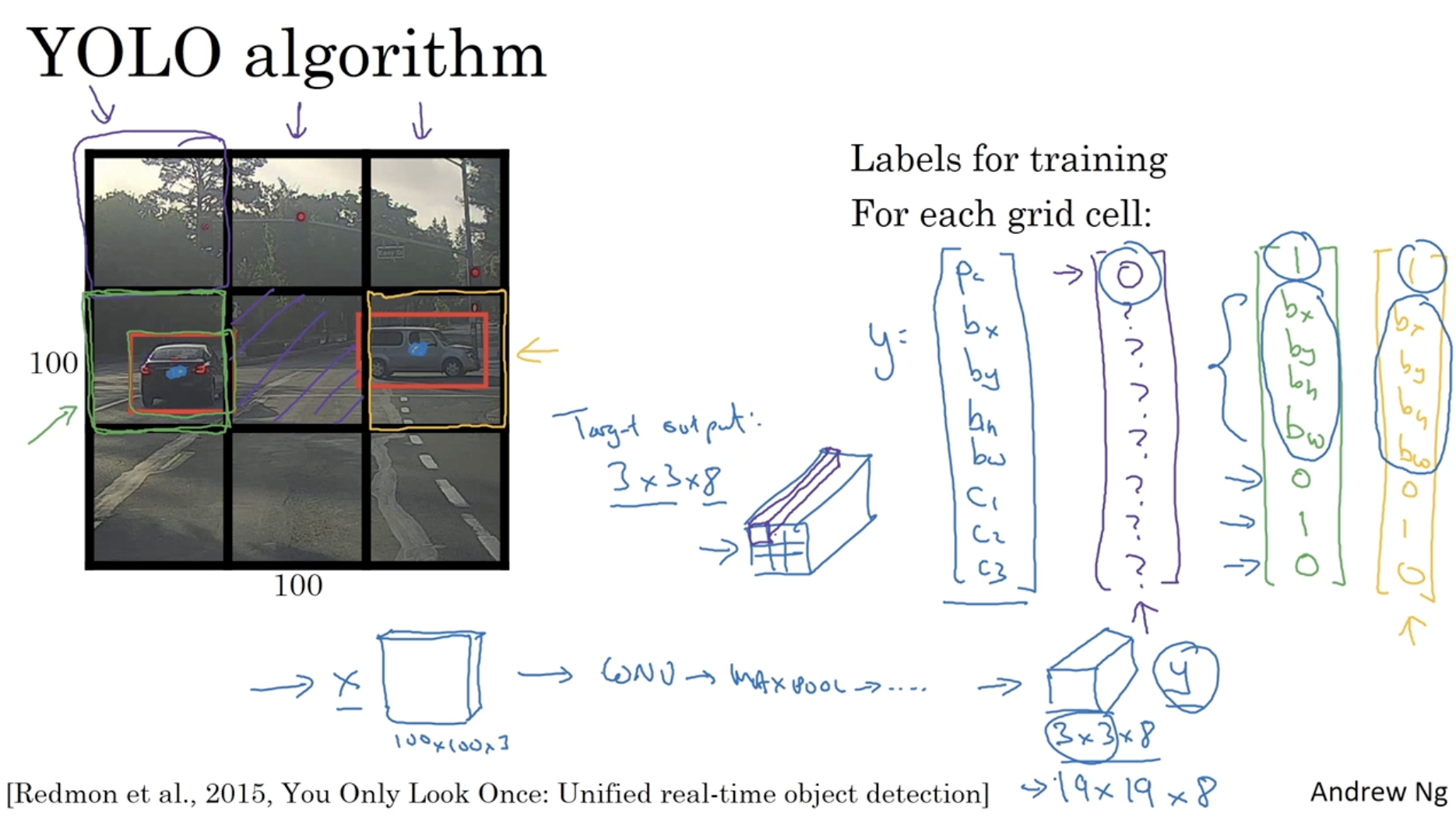
최적의 bounding box 를 찾기 위해 YOLO alg. 을 적용할 수 있다.
- YOLO 는 아래와 같이 이미지를 grid cell 로 나누고, 각각의 cell 에 대해서 object detection 을 수행하는 alg. 이다.
- 아래와 같이 만약 3 x 3 grid 로 나눌 경우, 이때 output 의 차원은 3 x 3 x 8 이 될 것이다.
- 그리고 아까 sliding window 를 convNet 으로 적용하면 중복 연산을 피하며 한번에 결과를 내는 것처럼 각 grid 에 대해서 한번에 연산이 가능하다는 특징도 있다.
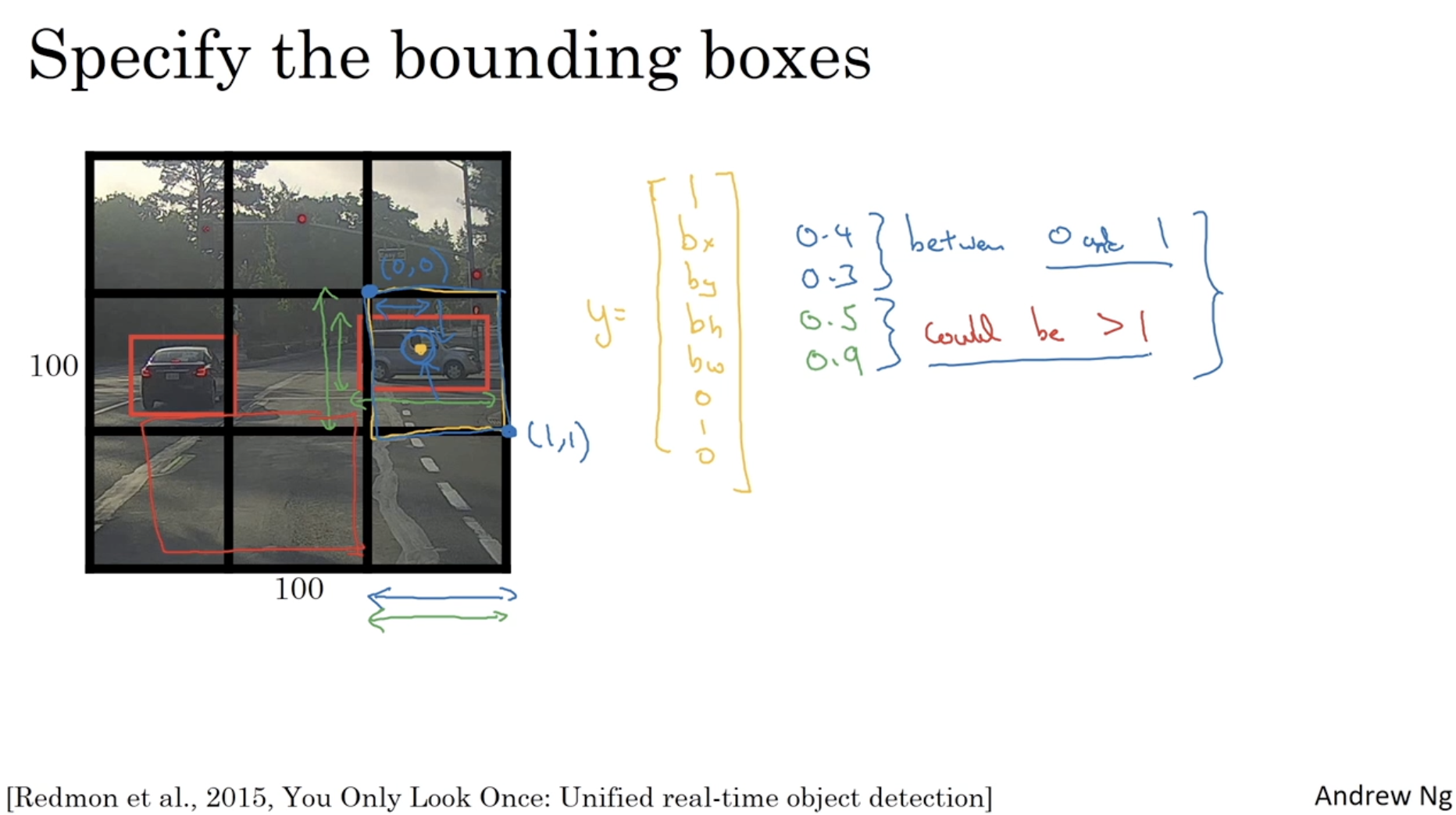
bounding box 의 좌표를 설정하는 방법은 아래와 같다.
- bounding box 의 좌표는 해당 셀을 기준으로 설정한다.
- 그래서 만약 오른쪽 bounding box 의 좌표를 정할 경우, 이 값은 에 해당하는 cell의 범위 내로 지정한다. 즉, (0, 0) ~ (1, 1) 사이의 좌표로 설정될 것이다.
- 그리고 너비와 높이는 셀의 크기 대비 전체 bounding box 의 크기로 설정된다.
- 예를 들어, bounding box 의 width, height 가 cell의 크기보다 작다면 0.0 ~ 1.0 사이의 값을 갖겠지만, 만약 cell의 크기보다 크다면 1.0 보다 큰 값을 가질 수도 있다.
그렇다면 object localization 의 평가 지표는 무엇일까?
- Intersection over Union ( IoU ) 를 통해 평가할 수 있다.
- 이는 과 같다. 즉, 두 bounding box 의 교집합 / 합집합 이다.
- 그리고 아래와 같이 이 값이 threshold (0.5) 보다 크면 이는 올바르게 object localization 했다고 볼 수 있다.

하지만 만약 YOLO 를 적용해서 여러 개의 bounding boxes 가 나온다면 어떻게 해야 할까?
- 이 경우 아래와 같이 19 x 19 grid cell 에 대해서 각 object 의 localization 이 높은 게 각각 3개씩 존재한다.
- 즉, 각 object 를 3번씩 중복해서 detect 한다.

이를 위해 Non-max suppression 을 적용한다.
- 아래 예시와 같이 (object가 존재할 확률) 가 가장 높은 bounding box 를 선택하면 된다. 이를 Non max suppression 이라고 한다.

Non-max suppression 의 구체적인 절차는 다음과 같다.
- 각각의 cell 에 대한 output prediction 값을 구한다.
- (0.6 은 threshold ) 조건에 해당하는 box는 버린다.
- box 가 남아 있는 동안 다음 과정을 반복한다.
- 가장 값이 높은 box 를 선택하여 예측값으로 출력한다.
- 그리고 해당 box 와 해당 box 와의 IoU 값이 threshold 이상인 박스들을 버린다. (같은 object 에 해당하는 box 들을 버린다.)

grid cell 에서는 cell 은 하나의 object 만 detect 할 수 있다는 단점이 존재한다. 따라서 하나의 cell 에서 여러 개의 object 를 detect 하기 위해 Anchor Boxes 개념을 도입한다.
- 아래와 같이 두 object 의 bounding box overlap 된 경우 anchor box 를 통해서 이를 표현할 수 있다.
- 이 경우에는 는 아래 그림과 같이 나오게 된다.
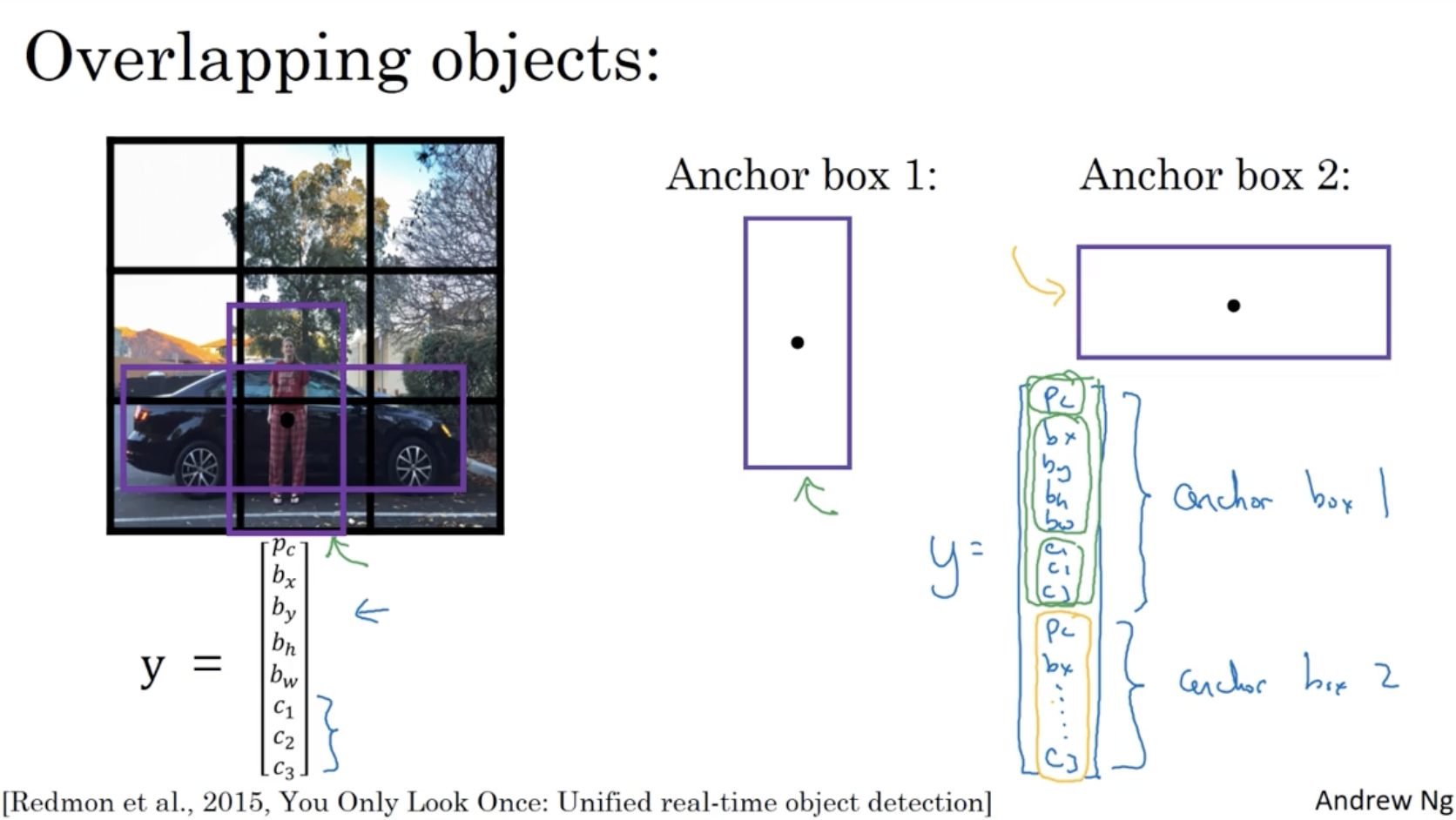
일반적인 bounding box 에서의 는 3 x 3 x 8 크기를 가졌지만, anchor box 에서의 는 3 x 3 x 2 x 8 크기를 갖게 된다.

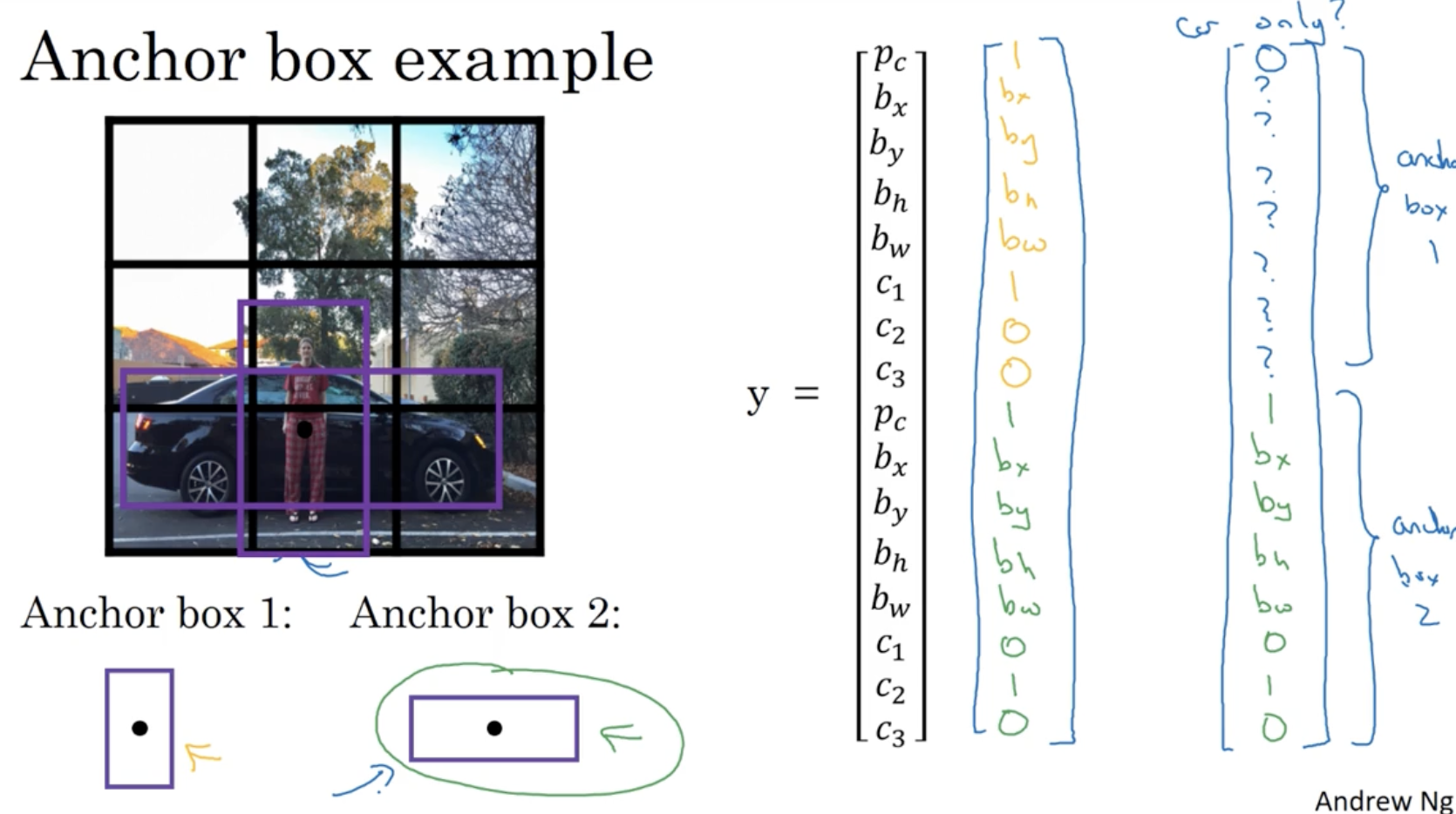
그렇다면 만약 에서 하나의 object 만 갖고 오고 싶다면 어떻게 해야할까?
- 우측과 같이 차량에 해당하는 anchor box 값만 그대로 가져오고, 그 외의 anchor box에 대해서는 인 상태로 가져오면 된다.
- 다만 object 가 더 많이 중첩되어 있거나 anchor box 간의 모양이 비슷할 경우 이는 문제가 될 수 있다. (하지만 이러한 경우는 빈번히 일어나지 않는다.)
그러면 이제 위에서 배운 모든 내용을 가지고 YOLO alg. 을 알아보자.
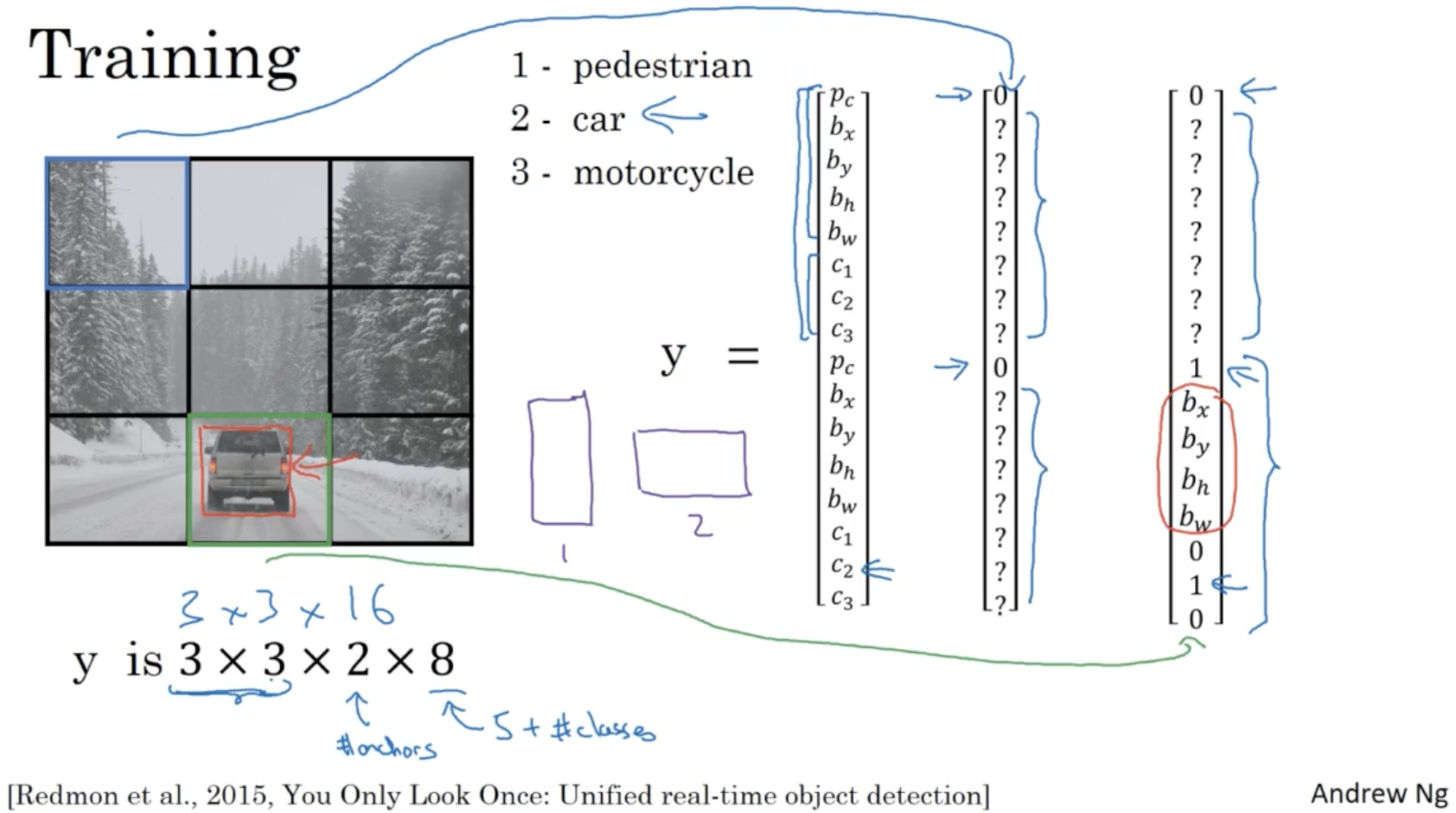
- 우선 학습 데이터는 아래와 같다.
- classes : 1 pedestrian / 2 car / 3 motocycle
- grid cell : 3 x 3
- anchor boxes : 1 세로로 긴 박스 / 2 가로로 긴 박스
- 따라서
- 그리고 각각의 grid cell 에 대해서 를 보면, 아래와 같이 나올 것이다.
이제 위 학습 데이터를 가지고 prediction을 수행한다.
- 아래와 같이 grid cell 에 해당하는 값과 예측값 를 비교하면서 학습을 진행할 것이다.
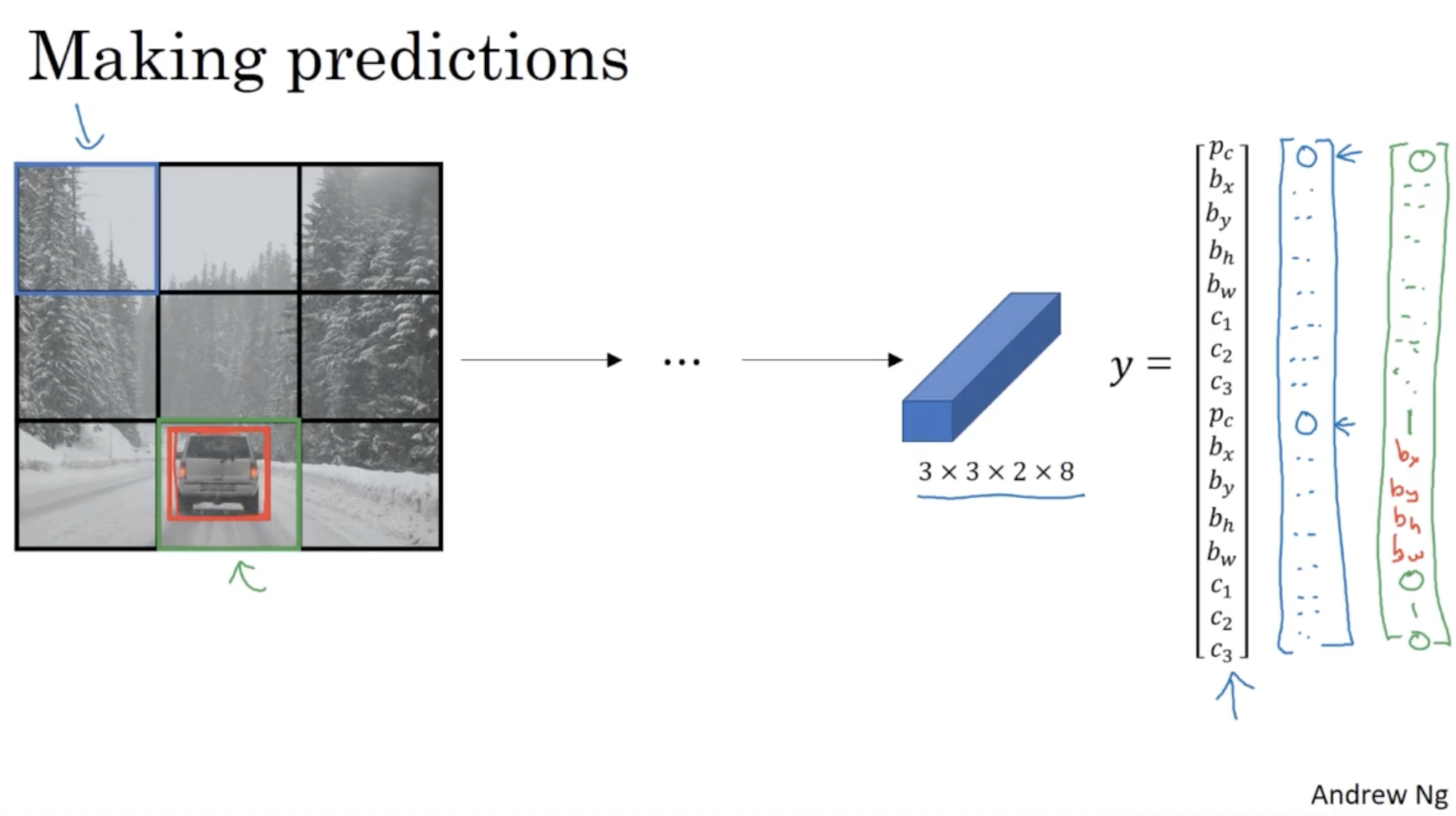
그러고 나서 다음과 같은 절차를 통해 학습된 모델에 대한 object detection 결과를 얻을 수 있다.
- grid cell 마다 2 개의 anchor box 를 예측한다.
- 값이 낮은 box 는 폐기한다.
- 각각의 class 에 대해서 non-max suppression 을 적용하여 확률이 가장 높은 object box 들만 놔둔다.
- 여기까지가 YOLO 모델에 대한 전체적인 내용이다.

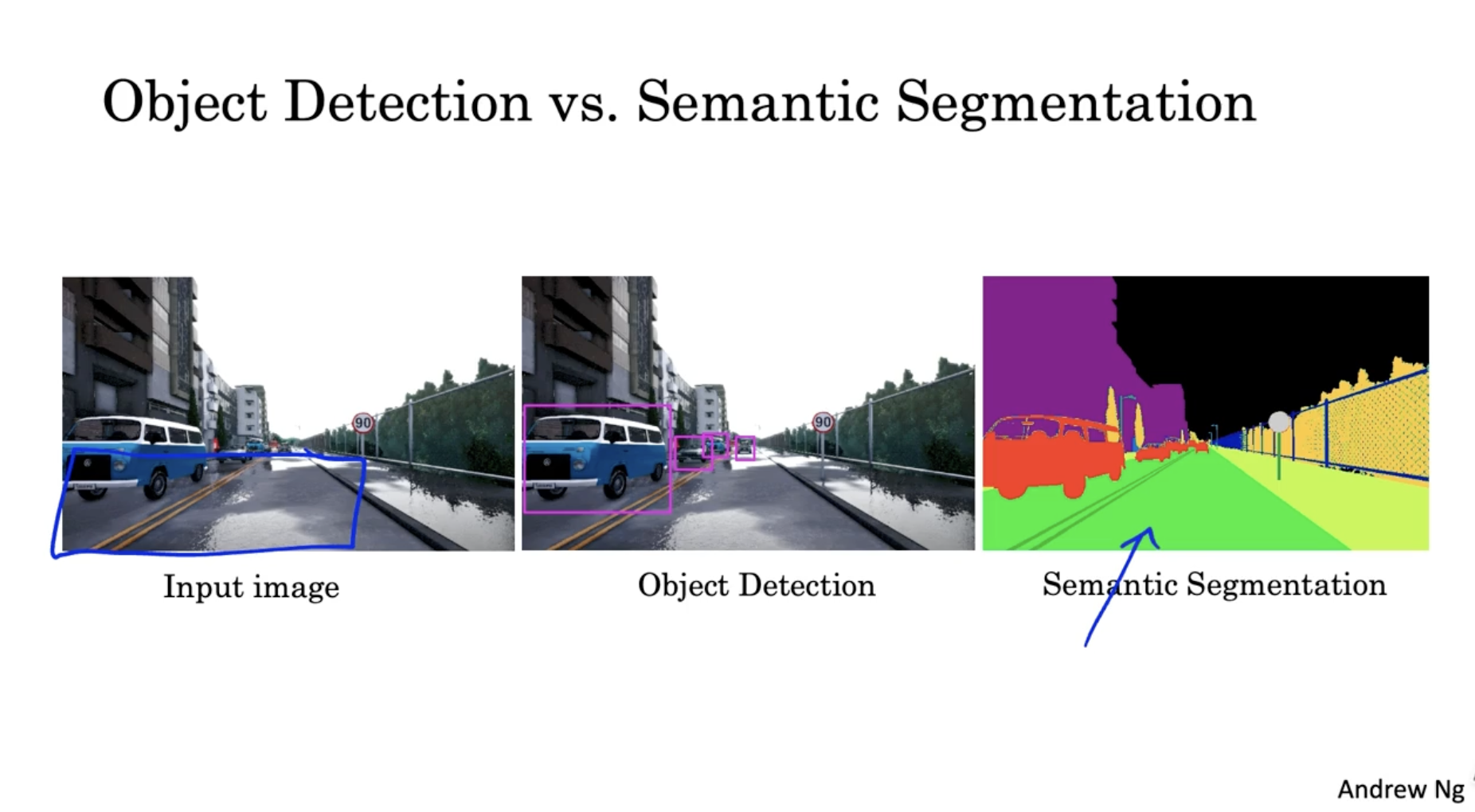
object detection 에 의해서 segmentation 에 대해서 알아보자.
- 아래는 object detecttion 과 semantic segmentation 에 대한 예시이다.
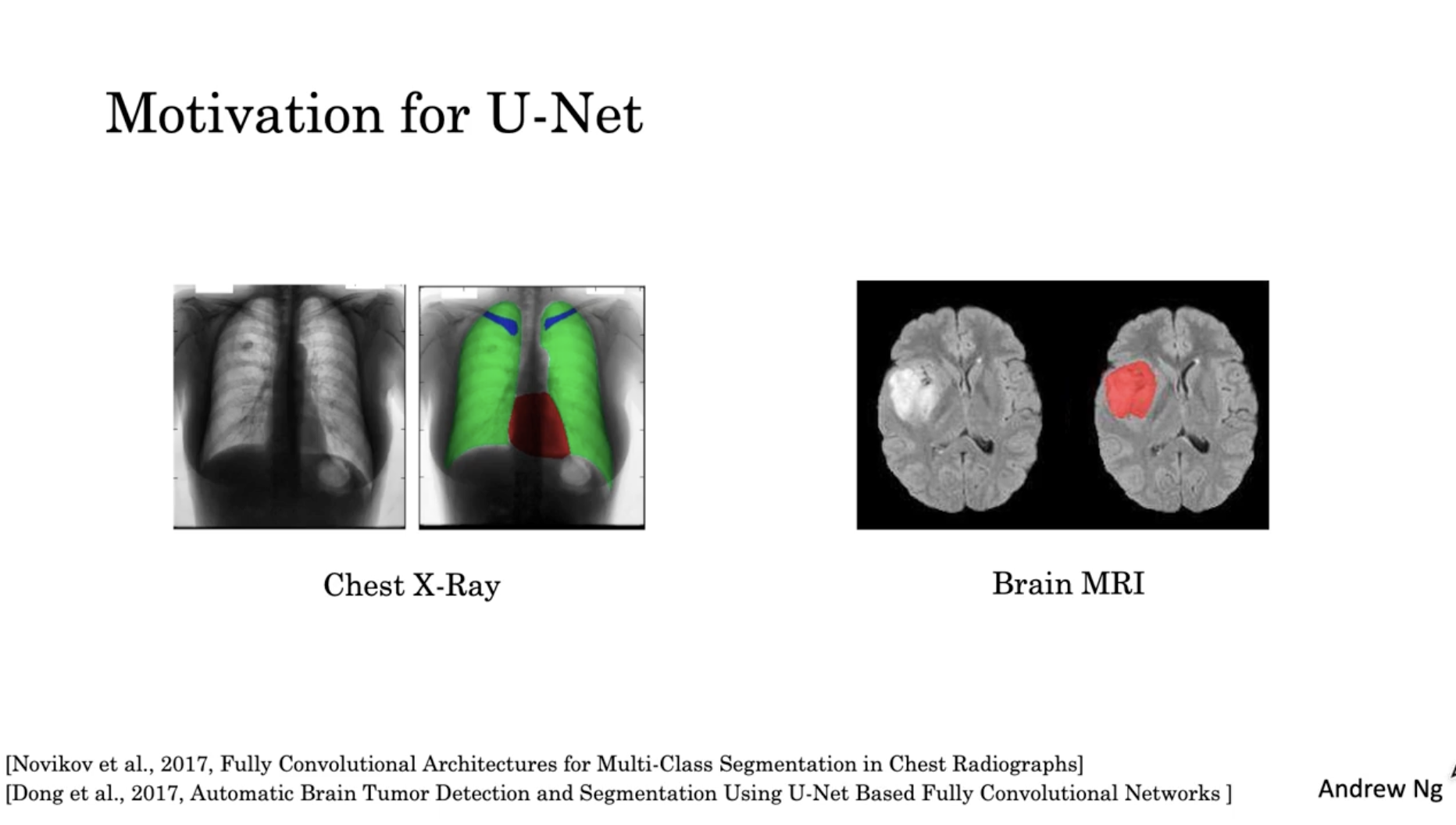
U-Net 은 segmentation 모델 중 하나로, 이는 의료 데이터에서 이상 증세를 확인하기 탐지하기 위해 연구되었다.
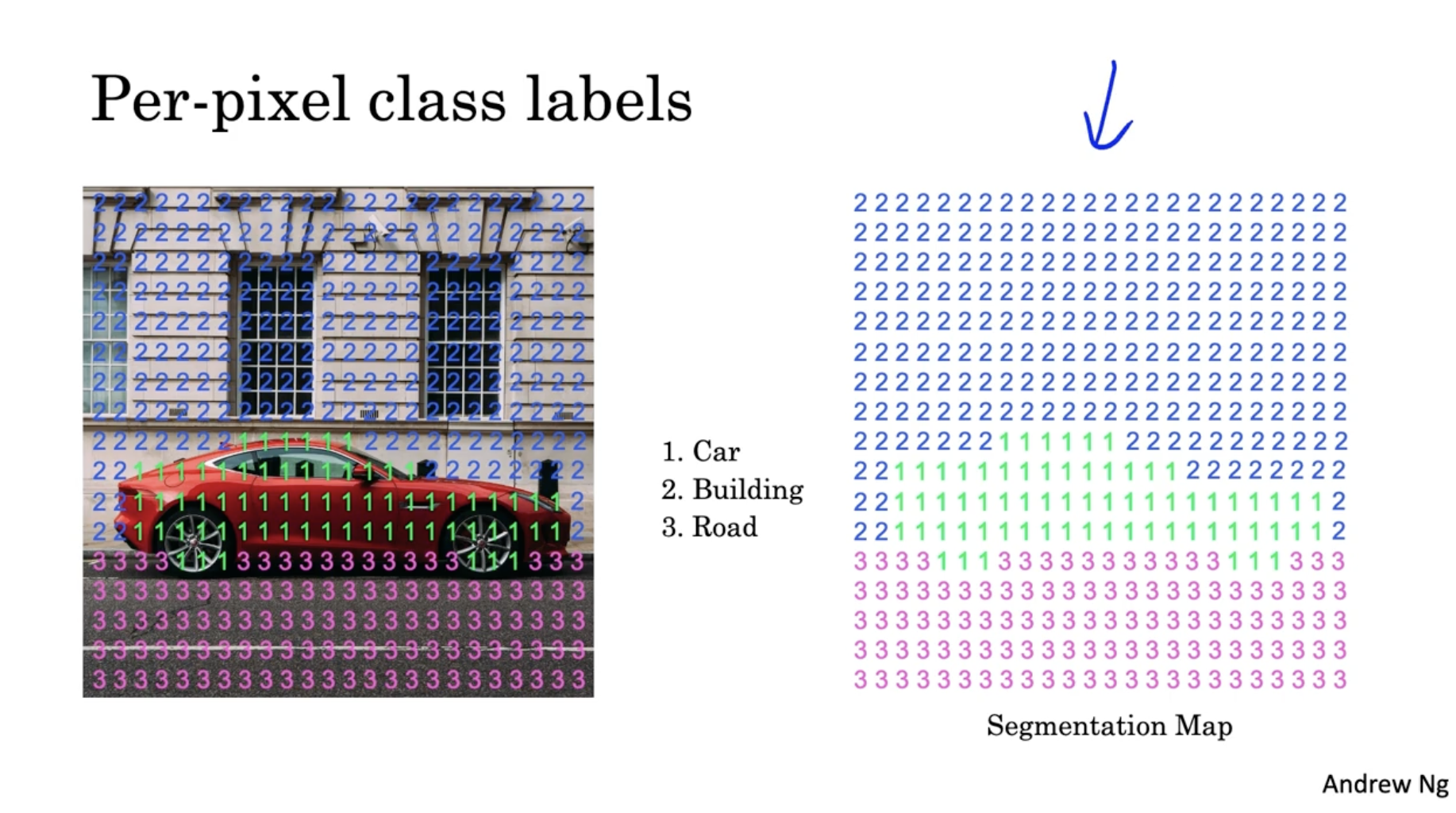
다음은 pixel 단위의 segmentation 의 예시이다.
- 아래와 같이 각 픽셀은 class number 를 갖고 있다. 그리고 이 클래스 번호를 가지고 우측처럼 segmentation map 을 만들 수가 있다.
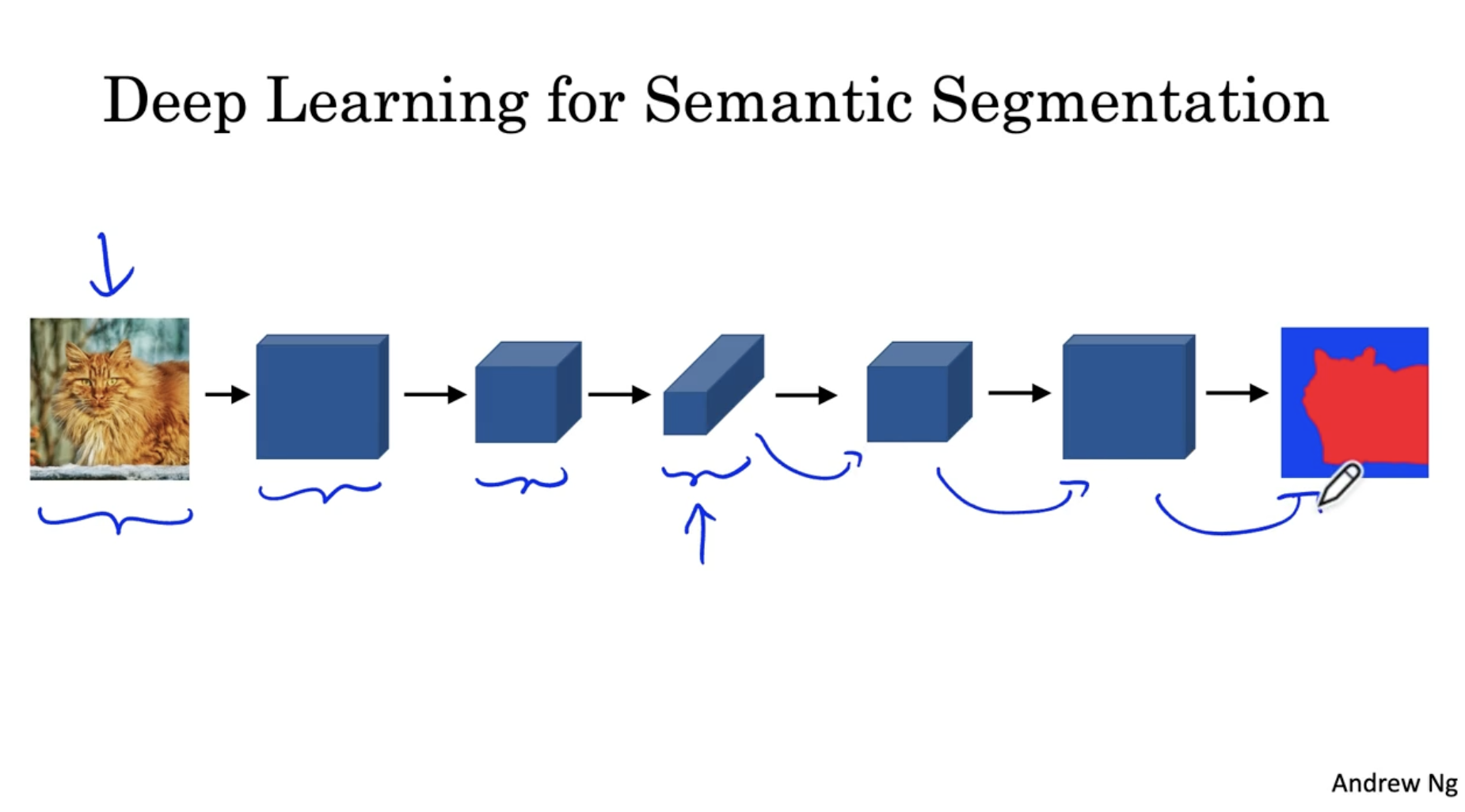
딥러닝 모델에서 semantic segmentation 은 다음과 같은 구조를 띈다.
- 일반적인 ConvNet. 처럼 conv. 연산을 하다가 FC layer 로 가지 않고, 이미지 크기를 늘리고 차원을 줄이면서 원본 이미지 크기로 복원한다. 그리고 이 결과로 segmentation map 을 예측한다.
- 크기를 확장하는 부분에서 transpose convolution 이 적용된다.
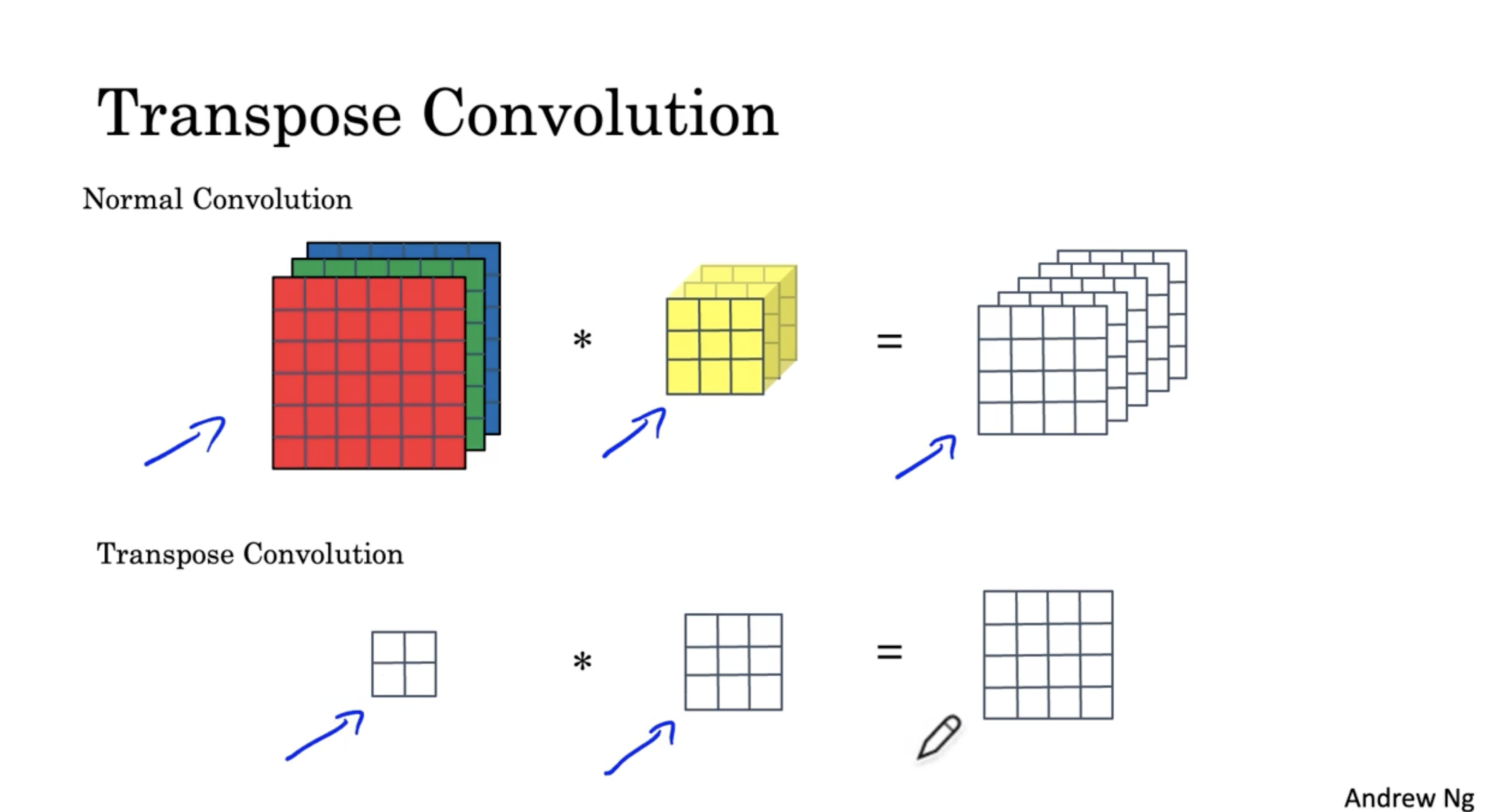
Transpose Convolution 은 아래와 같다.
- 일반적인 convolution 은 입력 데이터에 필터를 convolution 하여 입력 데이터의 크기를 줄이지만,
- Transpose convolution 은 입력 데이터에 필터를 convolution 하여 입력 데이터의 크기를 늘린다.
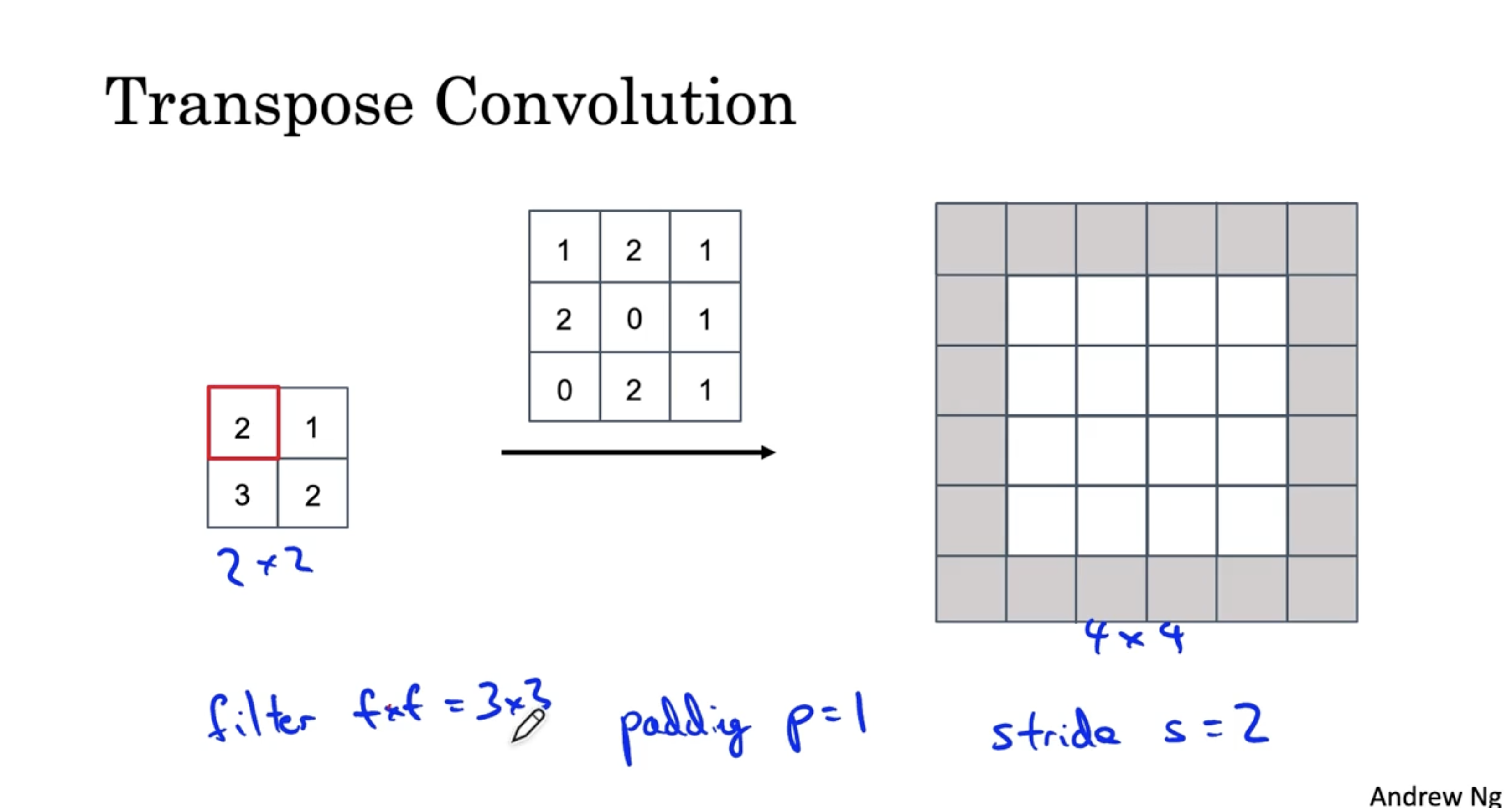
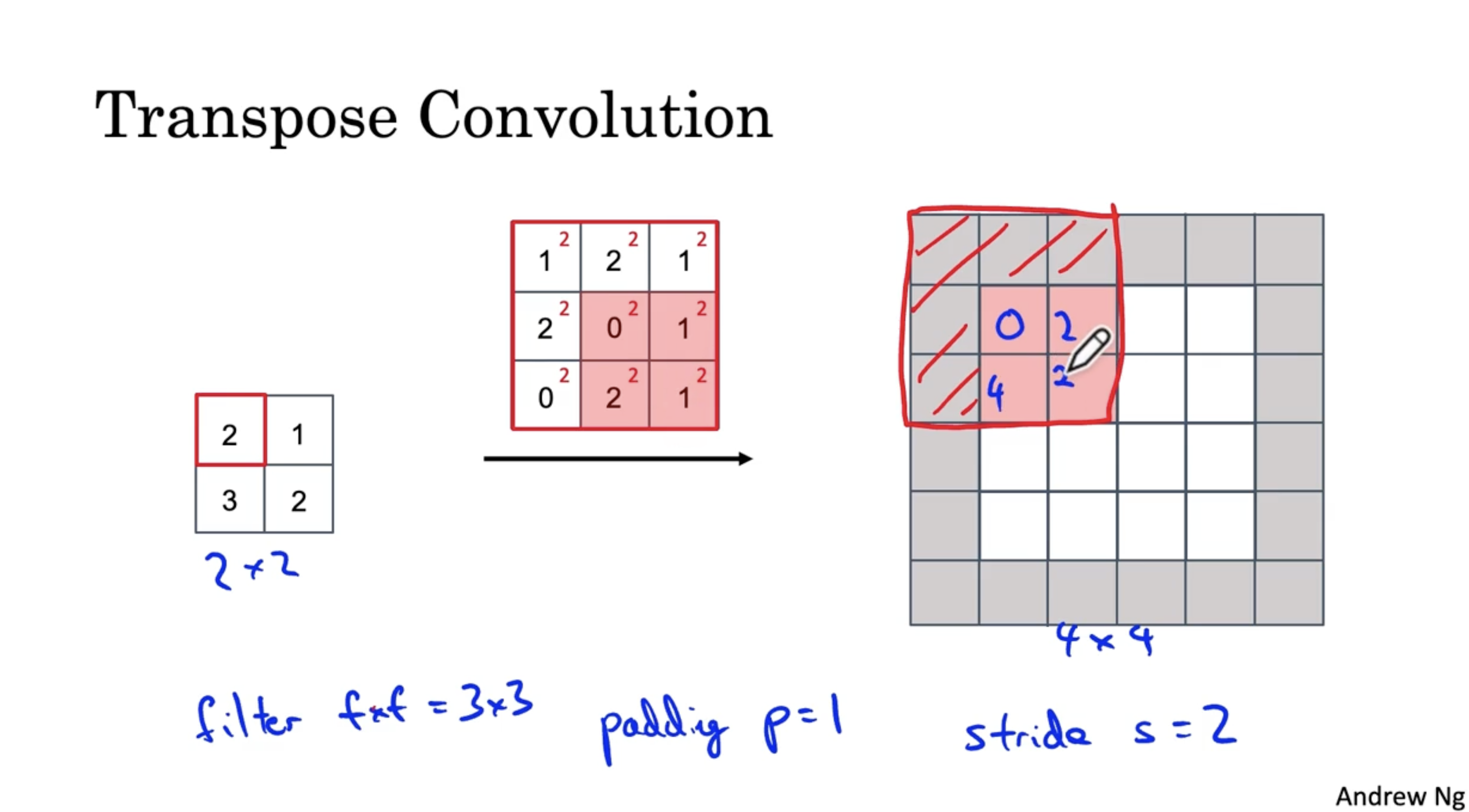
예를 들어, 다음과 같이 2 x 2 입력 데이터와 3 x 3 필터가 있다고 가정해보자.
- 이때 padding size p는 1이며, stride s는 2이다.
- 우선 입력 데이터의 가장 첫번째 값에 대해서 필터를 적용한다. (이때 패딩의 영역은 제외한다.)
- 따라서 입력 데이터의 첫번째 값에 대해서 필터를 적용하면 아래와 같은 결과가 나온다. (패딩 부분은 제외하고 연산을 진행한다.)
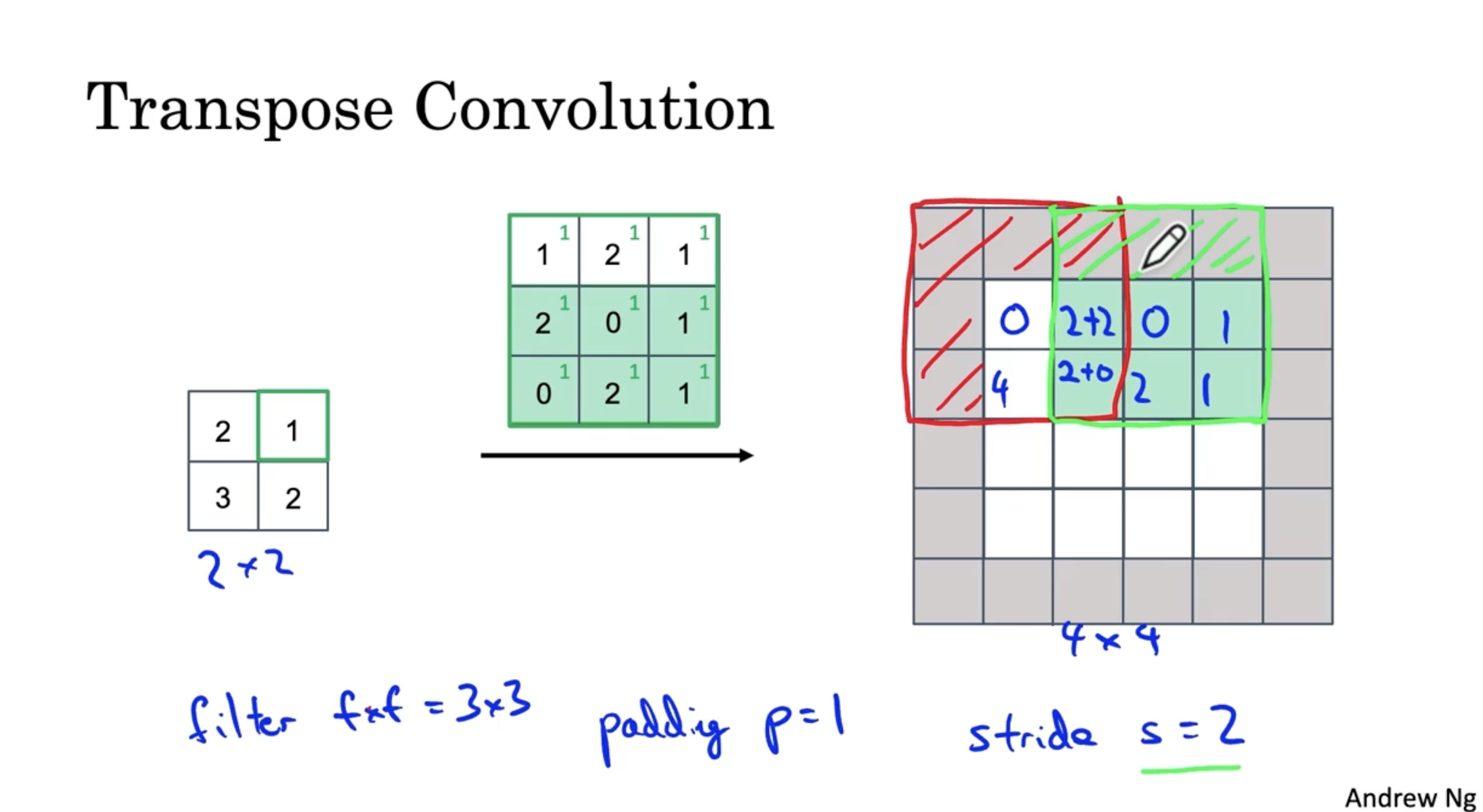
- 이제 입력 데이터의 다음 값에 대해서 필터를 적용하면 아래와 같다. (이때 중복되는 부분은 단순히 sum 으로 구현해준다.)
- stride 이므로, 2 칸 이동한 모습이다.
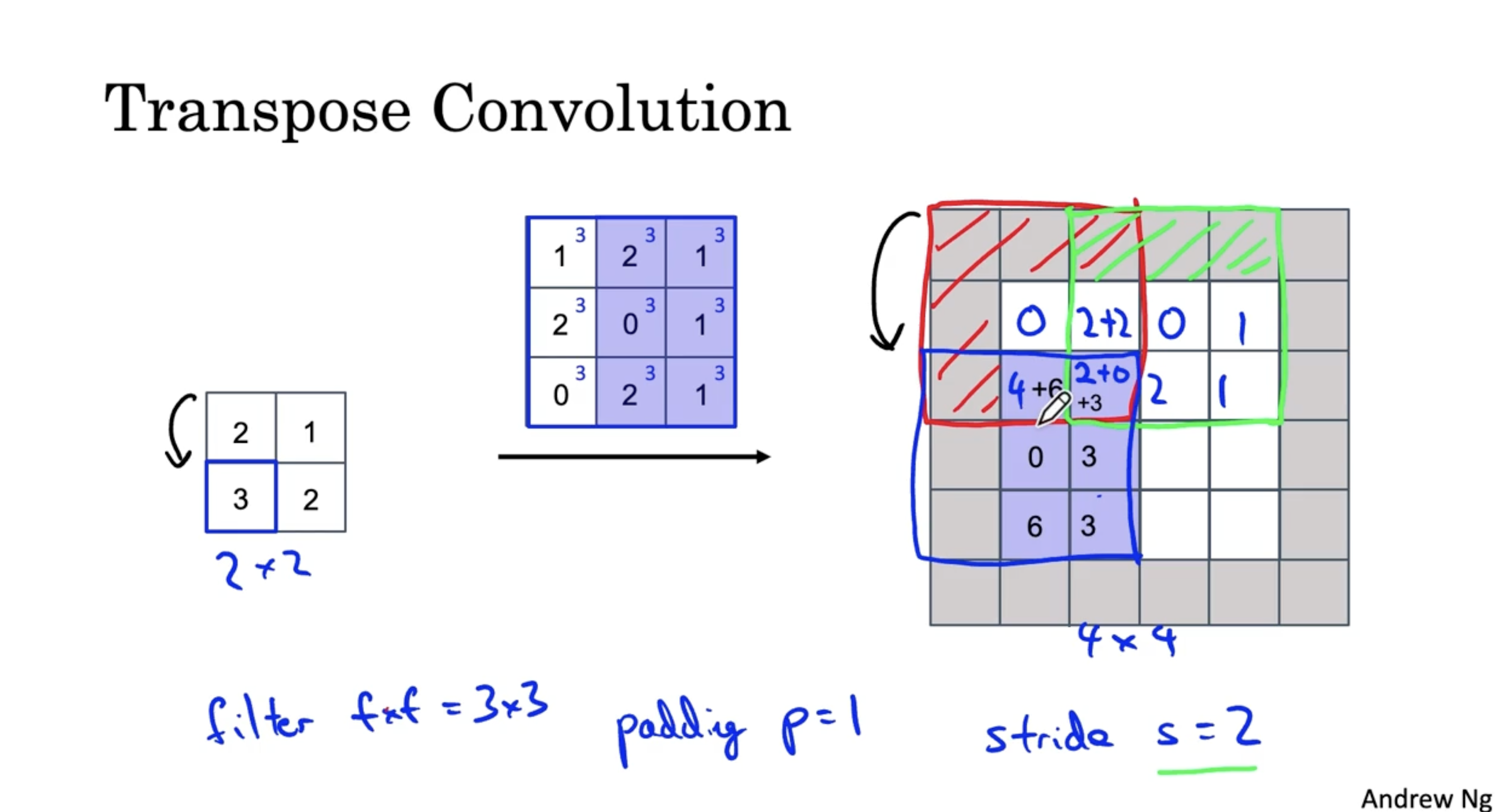
- 마찬가지로 입력 데이터의 다음 값에 대해서 필터를 적용하면 아래와 같으며, 이때 입력 데이터의 값의 위치가 아래로 내려갔으므로 output data 도 아래로 2(stride)칸 내려간다.
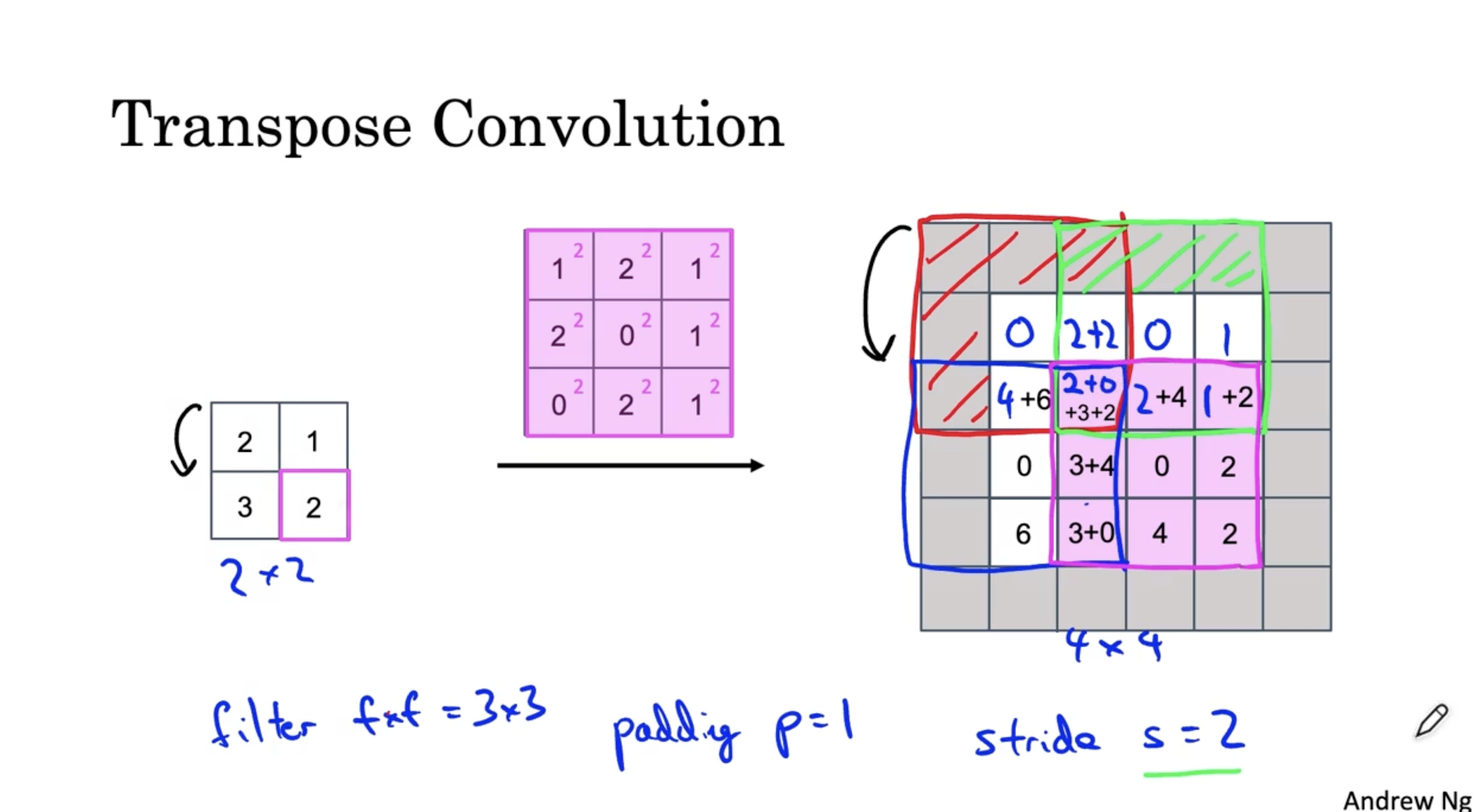
- 그리고 입력 데이터의 마지막 값에 대해서 필터를 적용하면 최종적으로 아래와 같은 결과가 나온다.
- 이러한 방법을 Transpose Convolution 이라고 한다.
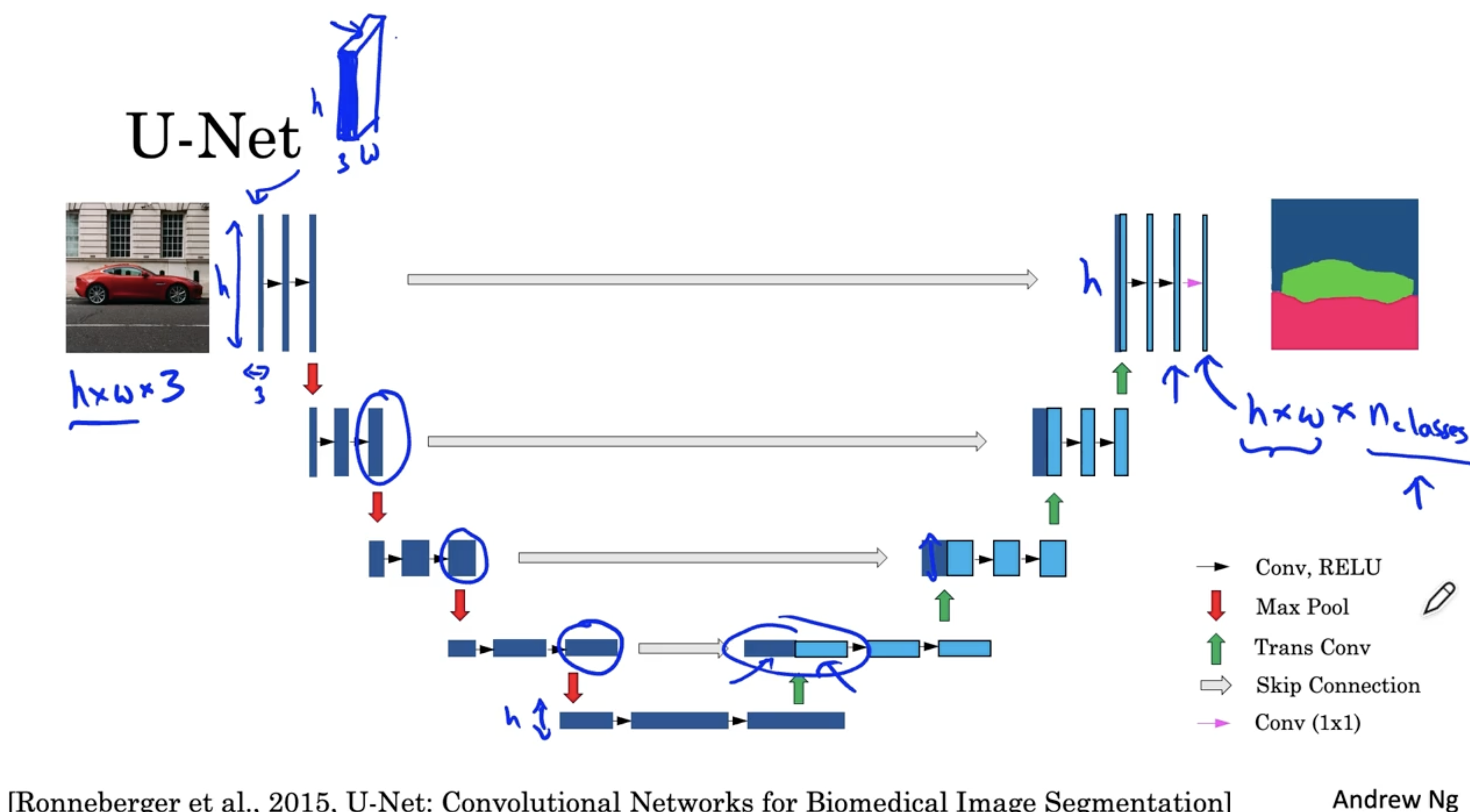
U-Net 의 직관적인 구조는 아래와 같다.
- 일반적인 ConvNet. 이 이어지다가 Transpose ConvNet. 이 적용되며, output layer 직전 layer에서 skip connection (like residual ) 이 적용되어 output segmentation map 을 출력한다.
- 이때 skip connection 이 적용되는 이유는, 초반 conv. 결과는 비교적 고화질 데이터를 가지고 있지만, conv.가 반복되고 여기에 transpose conv. 를 적용하면 데이터의 해상도가 낮아지는 문제가 있다. 따라서 초반의 conv. 값을 통해 데이터의 고 해상도를 유지해줄 수 있다.
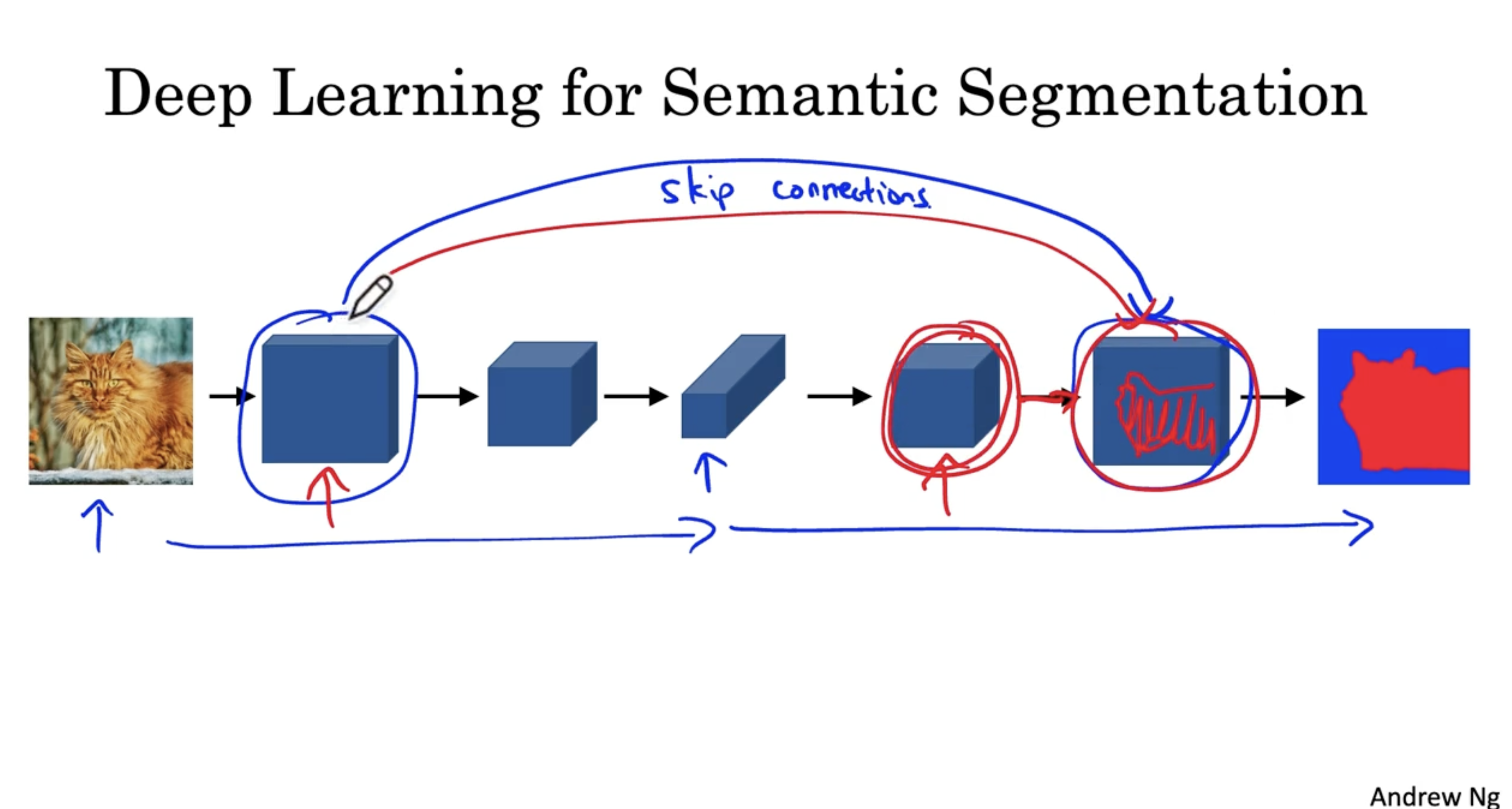
U-Net 의 구체적인 구조는 아래와 같다.
- 우선 일반적인 ConvNet. 과 달리 activation 의 크기가 h x # channel x w 로 이뤄진다.
- 우선 입력 데이터에 대해서 Conv. 및 ReLU 를 적용하여 activations 를 구한다. (이 과정에서 activations 의 크기는 유지되고 # channels 만 커진다.)
- 그런 다음 Max pooling 을 적용한다. (이 경우 activations 의 채널의 크기는 커지고 사이즈는 작아진다. )
- 그리고 마찬가지로 Conv. 및 ReLU 를 적용하여 activations 를 구한다.
- 이 과정을 반복하면서 제일 하단에 보이는 layer 까지 진행한다.
- conv. 및 ReLU 와 Max pooling 이 적용된 activation 에 대해서 conv. 를 2번 더 적용하여 채널의 크기를 늘린 후, 해당 activation 에 Transpose Convolution 을 적용한다. (첫 trans conv. 에서는 채널의 크기만 절반으로 줄이고, activation 의 너비 및 높이는 (크기는) 유지한다.)
- 그리고 이에 대응하는 이전 layer의 activation 을 가져와 skip connection 을 진행하고 두 activation 을 결합한 후, conv. 및 ReLU 를 적용한다.
- 그리고 다시 trans conv.를 적용하여 채널은 줄이고 크기를 늘린다. 그리고 아까의 과정을 반복한다.
- 그리고 마지막 layer에서도 입력 데이터와 같은 크기를 갖는 activation 에 conv. 및 ReLU 를 적용하여 크기는 유지하고 채널의 수만 줄인다.
- 그리고 마지막에 1 x 1 conv. 를 적용하여 최종 output activation 을 얻는다.
- 이렇게 함으로써 입력 데이터와 같은 크기를 갖고, class 수에 따른 segmentation map 을 구할 수가 있을 것이다.