이제 마지막으로 sequence model 에 대해서 알아본다.
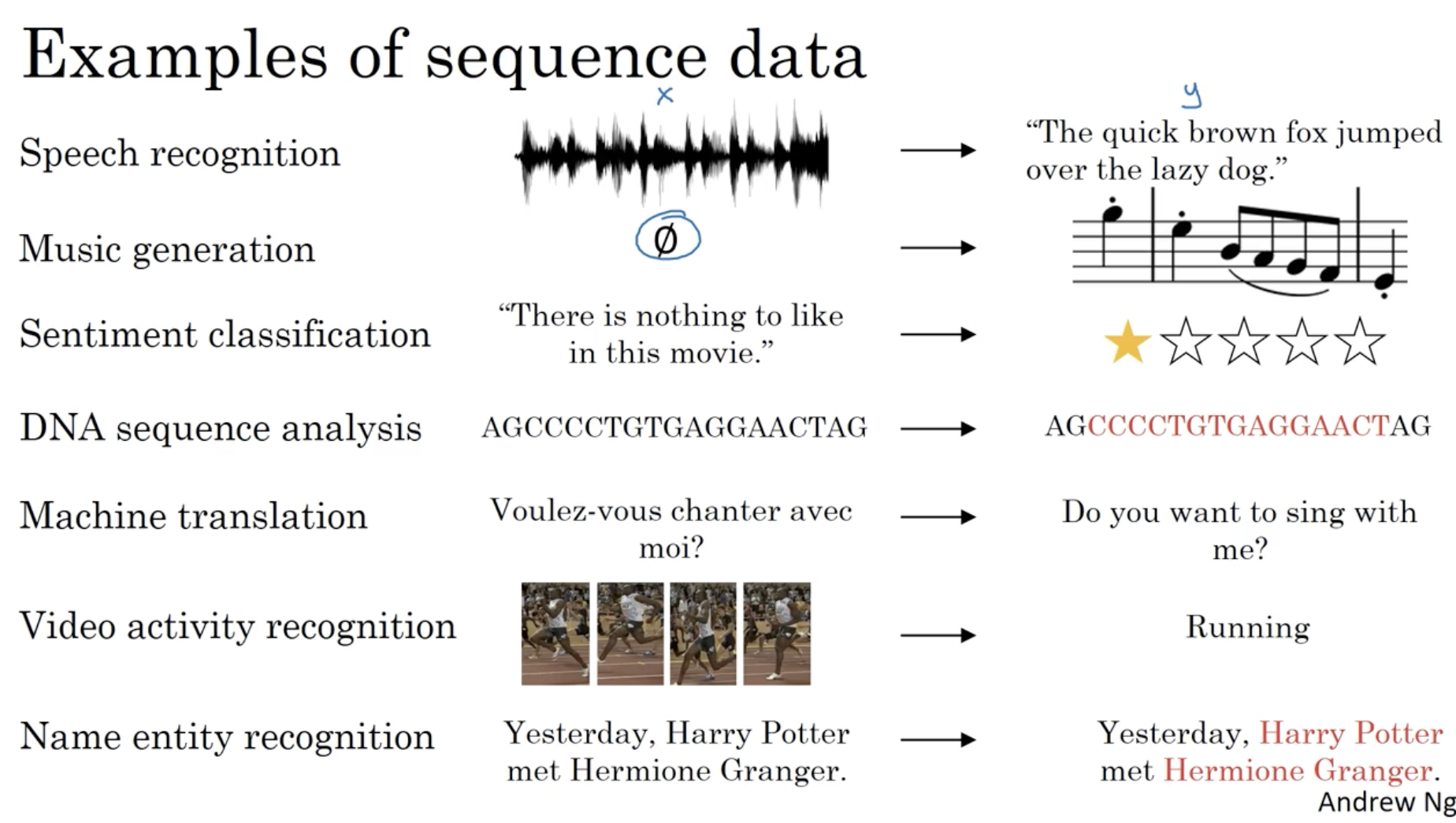
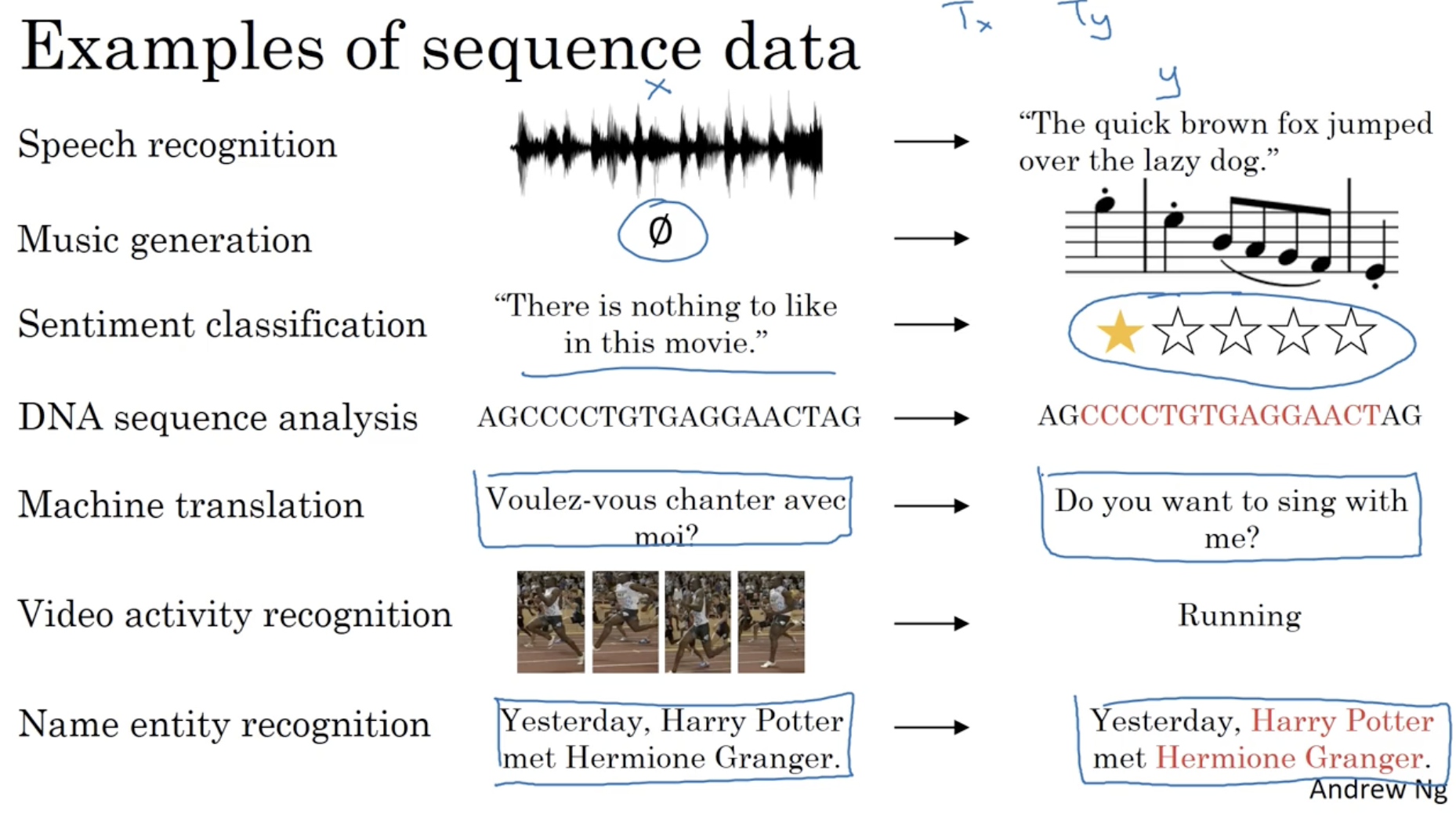
- 아래는 sequence data 들의 예시이다.
squence model의 간단한 데이터 예시를 보자.
- 아래와 같이 문장 가 주어졌을 때, 해당 문장에서 각 단어를 위치로 구분할 수 있다.
- 따라서 아래의 경우 다음과 같다.
- : "Harry" / : -
- : "Potter" / : -
- : "and" / : -
- ... : "spell" / : -
- 따라서 이와 같은 데이터를 다음과 같이 표기한다.
- : length of
- : length of
- : 입력 데이터 의 번째 데이터 중 번째 단어.
- : 결과 데이터 의 번째 데이터 중 번째 단어.
- 그리고 위와 같은 데이터를 활용하여 문장에서 이름에 해당하는 단어를 추출할 수가 있을 것이다. (이러한 경우 NLP 모델에 해당한다.)
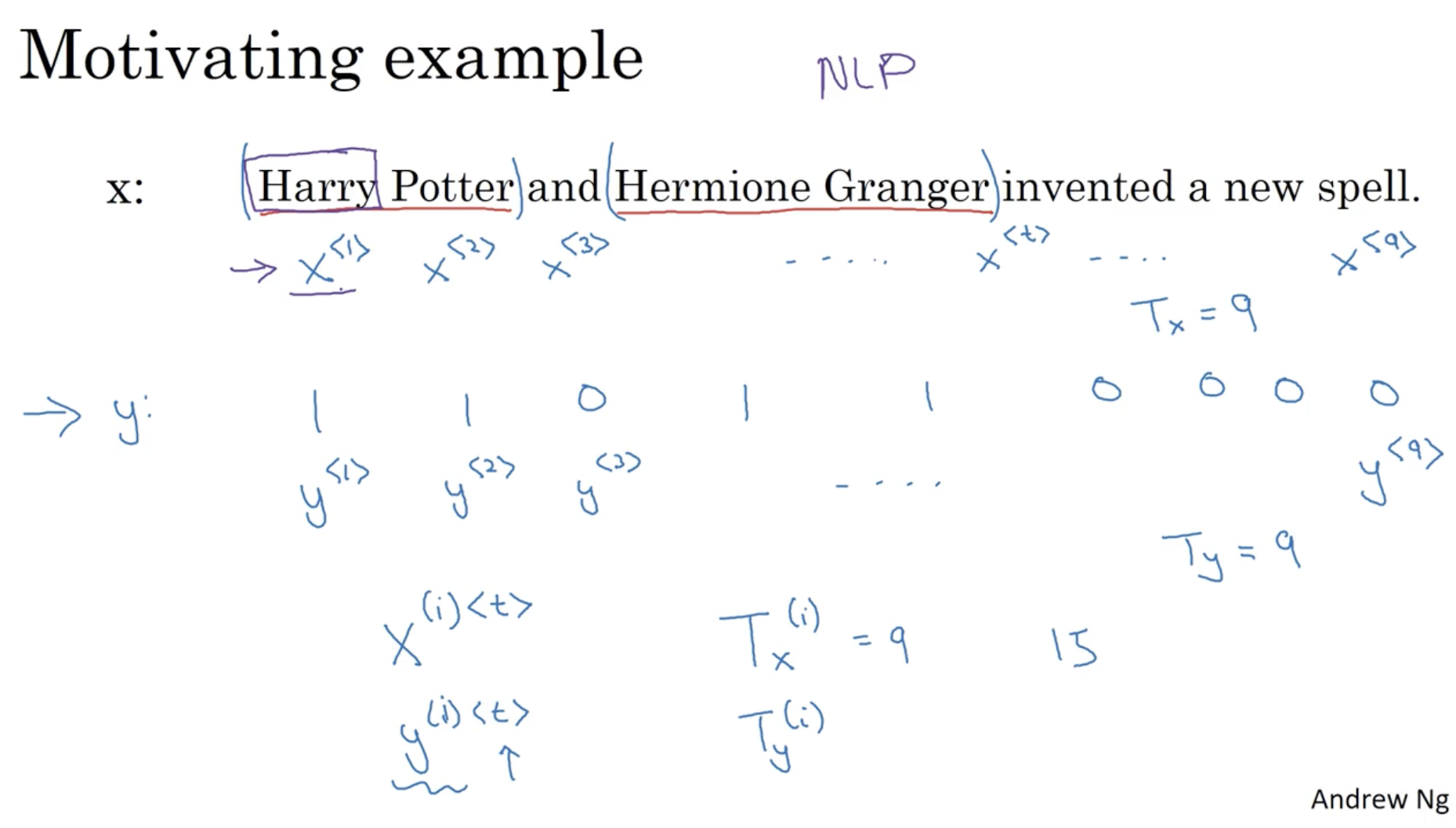
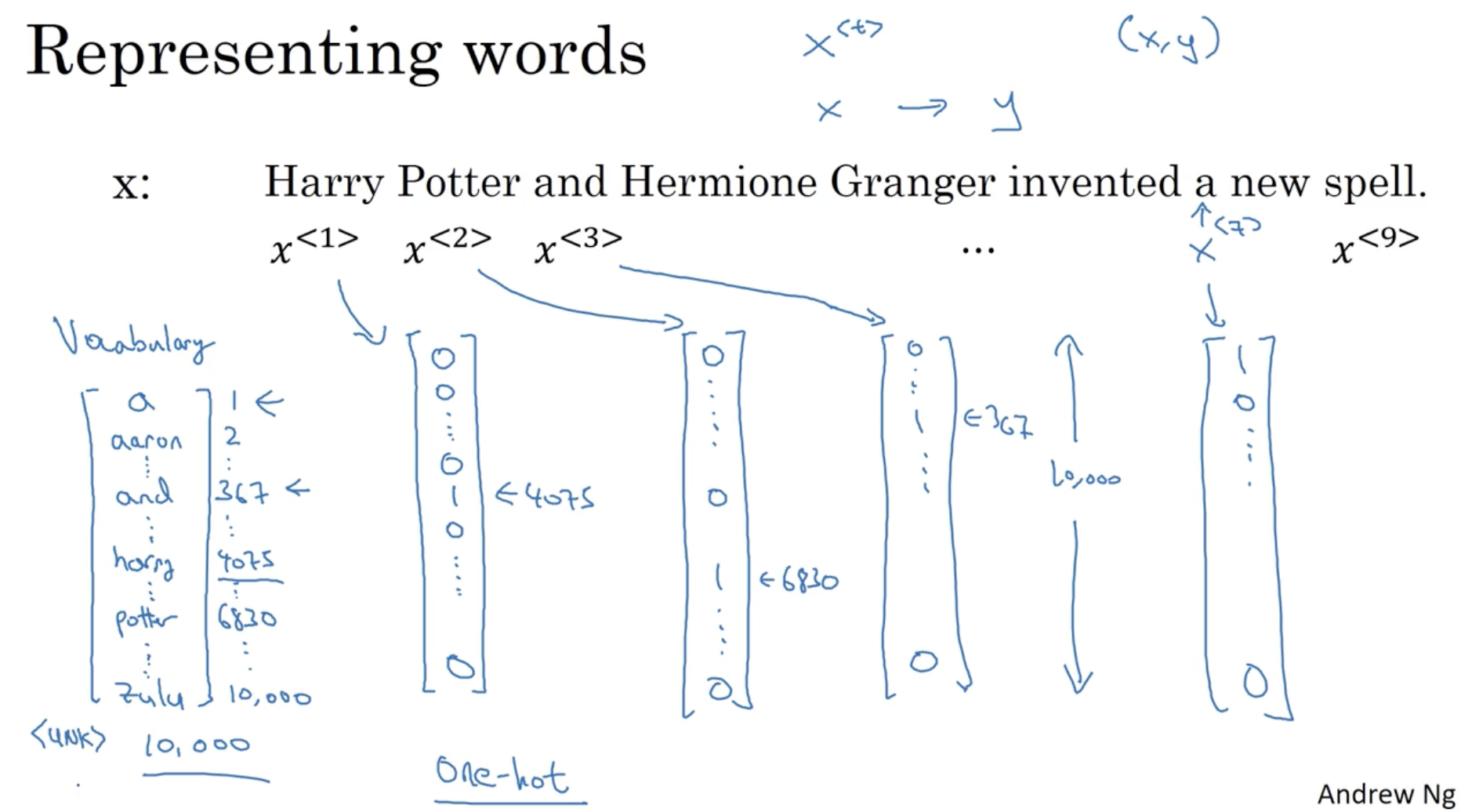
그리고 단어 사전 ( Vocabolary ) 을 이용하여 각 단어에 대해서 one-hot 벡터로 표현이 가능하다.
- 예를 들어, 아래 이미지의 좌측과 같이 단어 사전이 있을 경우, 사전에서 차지하는 각 단어의 index 를 가지고 우측과 같이 one hot vector 로 각 단어를 표현할 수 있다.
- 하지만 이 경우 신조어와 같은 존재하지 않는 새로운 단어가 들어올 경우 문제가 발생할 수 있다. 이 문제를 해결하기 위한 방법은 추후에 나올 예정이다.
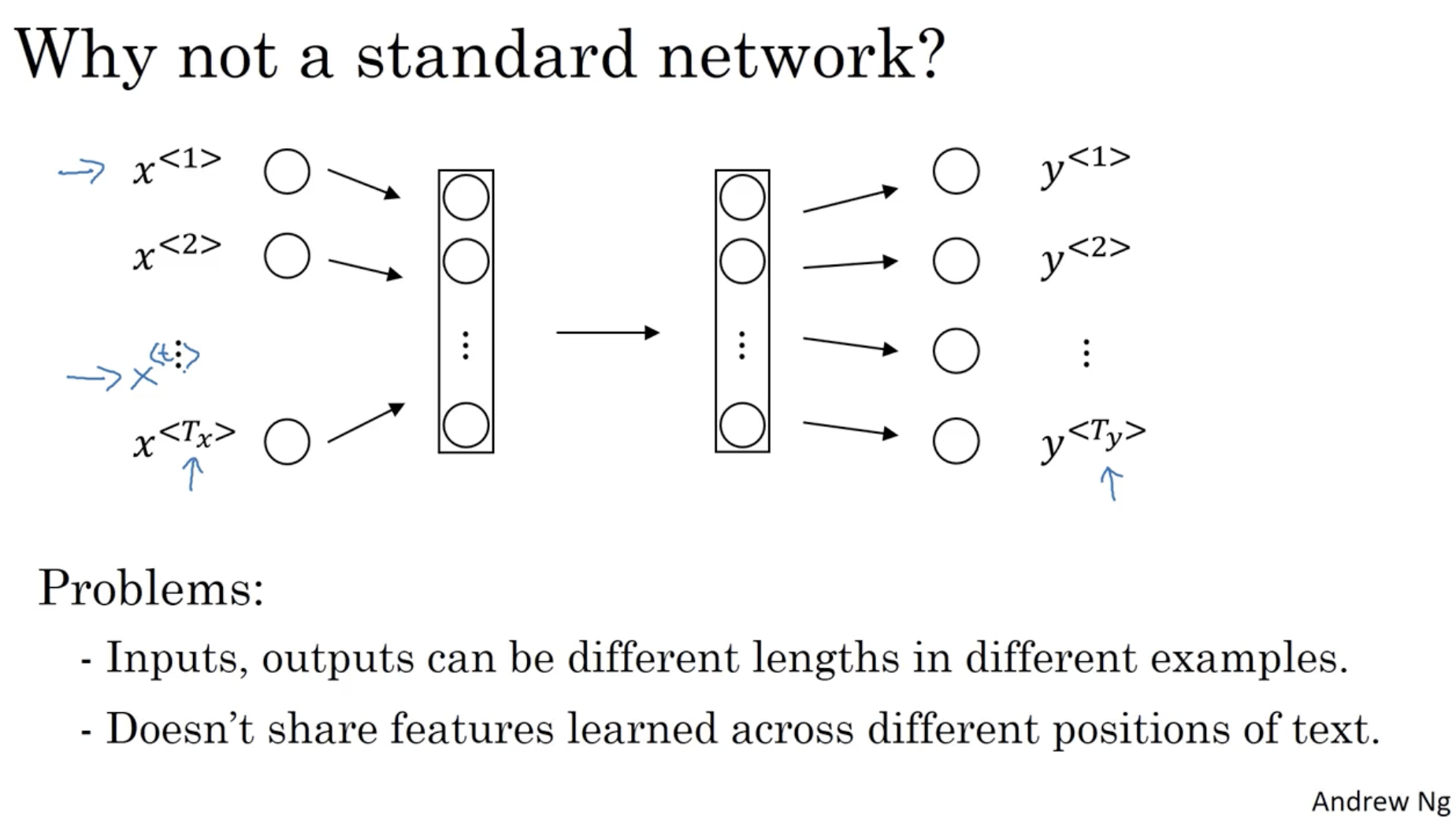
그렇다면 왜 위와 같은 일반적인 neural network 으로 적용하면 안되는 걸까? 아래를 보자.
- one hot 벡터의 경우, 입력값과 출력값의 크기가 문장마다 다르다. (물론 0 padding 과 같은 방법이 있지만 그래도 비효율적이다.)
- 또한 텍스트 마다 feature 를 공유하지 않는다는 단점이 있다. (예를 들어, "Nice to meet you Harry Potter" 와 "Hello Mr. Potter" 라는 두 문장에서 앞 문장은 Potter가 이지만, 뒤 문장은 Potter가 일 것이다.)
따라서 이를 보완하기 위해 Recurrent Neural Network ( RNN ) 이 나왔다.
- RNN 은 아래와 같은 구조로 이루어져 있다.
- 이전 단어의 activation 값이 계속해서 다음 단어로 이어지는 형태로 구성되어 있다.
- 좌측처럼 전체 구조로 표현할 수도 있고, 우측처럼 하나의 입력 + 뉴럴넷 + 출력 + 반복 처럼 하나의 구조로 표현할 수도 있다.
- 각 파라미터의 의미는 다음과 같다.
- : activation 를 받아서 activation 를 출력한다.
- : 입력 단어(데이터) 를 받아서 activation 를 출력한다.
- : activation 를 받아서 예측값 를 출력한다.
- RNN 에서는 각 단어에 적용되는 모든 파라미터가 동일한 파라미터이다.
- 그리고 아래 예시에서는 로 가정했지만 일 수도 있다.
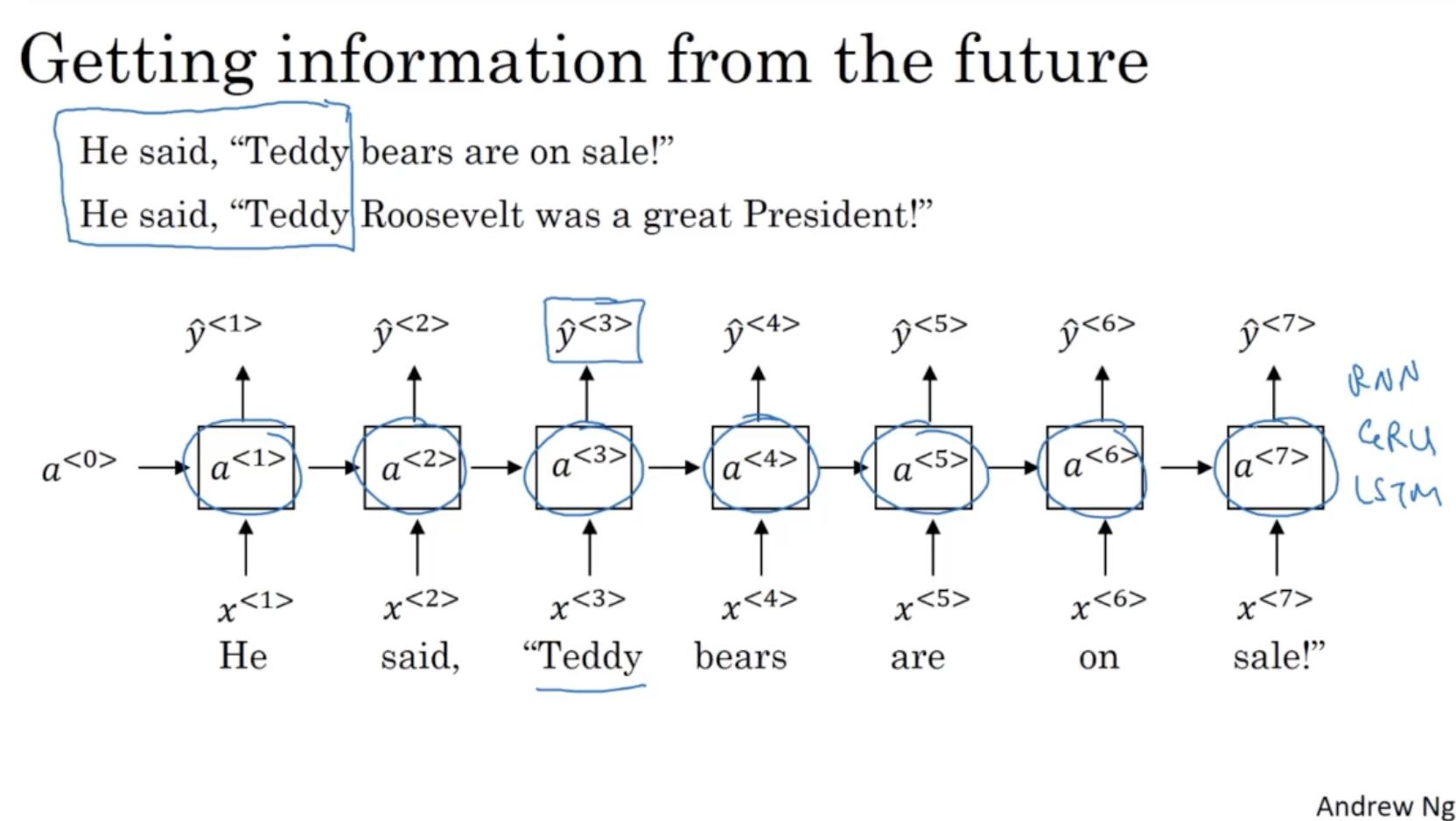
- 하지만 이러한 구조일 경우, 이전 단어들의 파라미터만 반영되고 이후 단어들의 파라미터는 반영이 안 된다는 단점이 존재한다.
- 예를 들어, 아래 문장 중 첫 번째 Teddy 와 두 번째 Teddy 는 서로 다른 의미로 쓰이지만, 아래와 같은 RNN 구조 상에서는 동일한 parameter 가 적용될 것이다.
- 물론 이를 보완하는 Bidrectional RNN ( BRNN ) 이 있긴 하다.

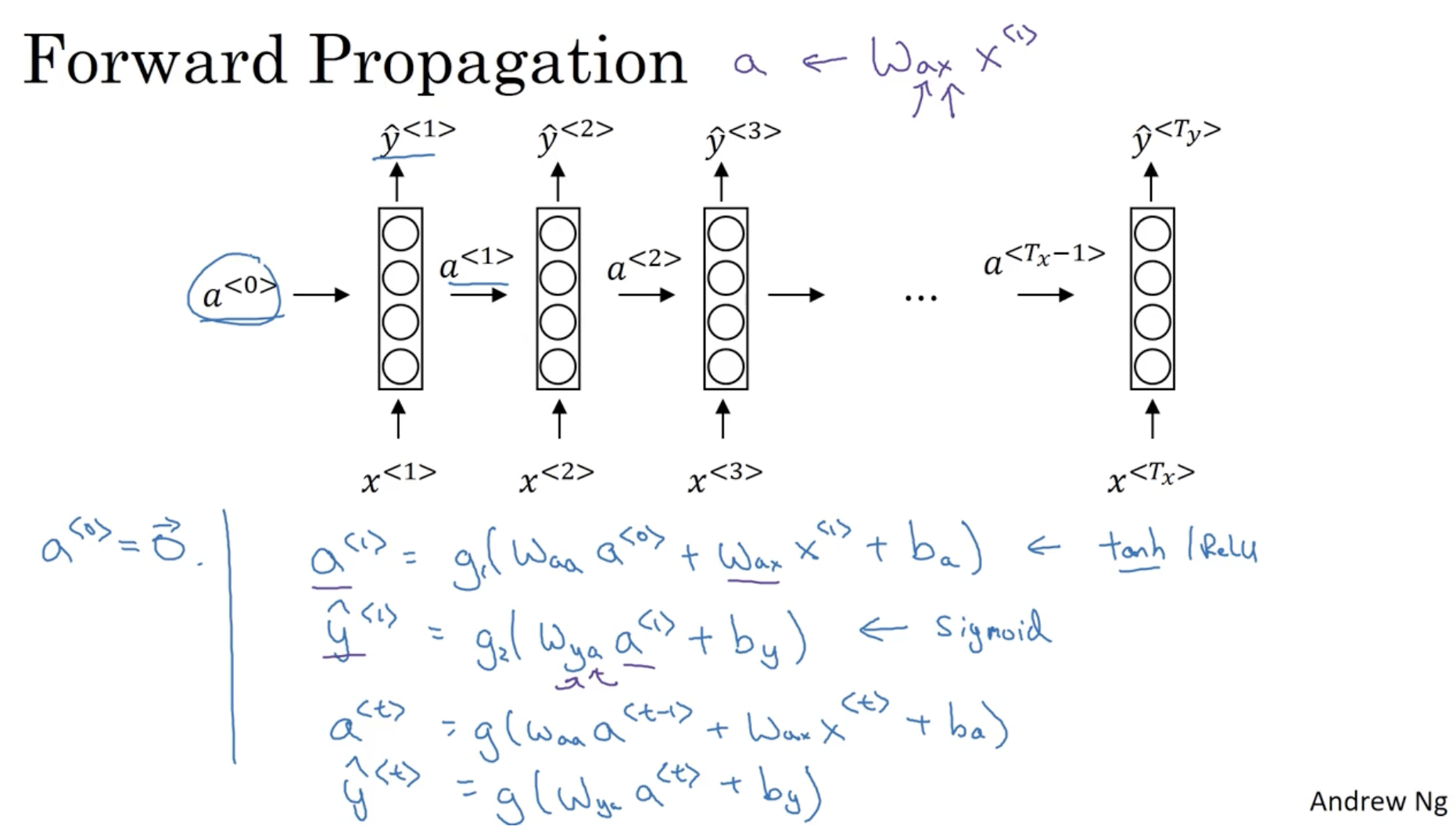
RNN 의 Forward Propagation 은 다음과 같이 진행된다.
- 첫 activation 로 설정한다.
- 그리고 다음과 같은 수식으로 를 구한다.
- 보통 에는 tanh / ReLU 를 쓰며, 에는 sigmoid 를 쓴다.
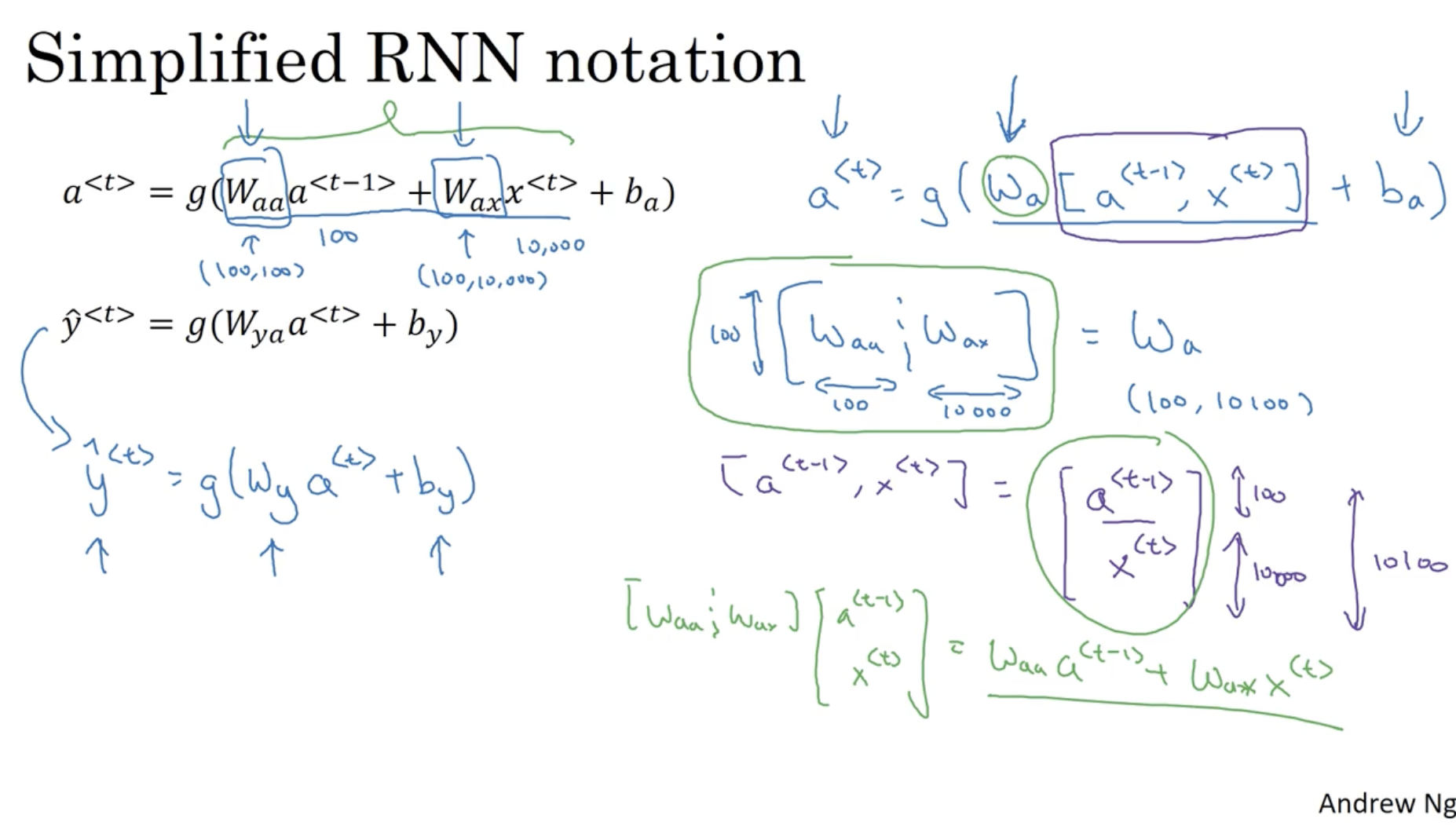
그리고 위 수식 대신 다음과 같이 단순화하여 작성할 수 있다.
- 만약 의 차원이 (100, 1) 이라면, 의 차원은 (100, 100)일 것이다.
- 만약 의 차원이 (10000, 1) 이라면, 의 차원은 (100, 10000)일 것이다.
- 따라서 를 로 묶어서 표현한다.
- 그리고 가 된다.
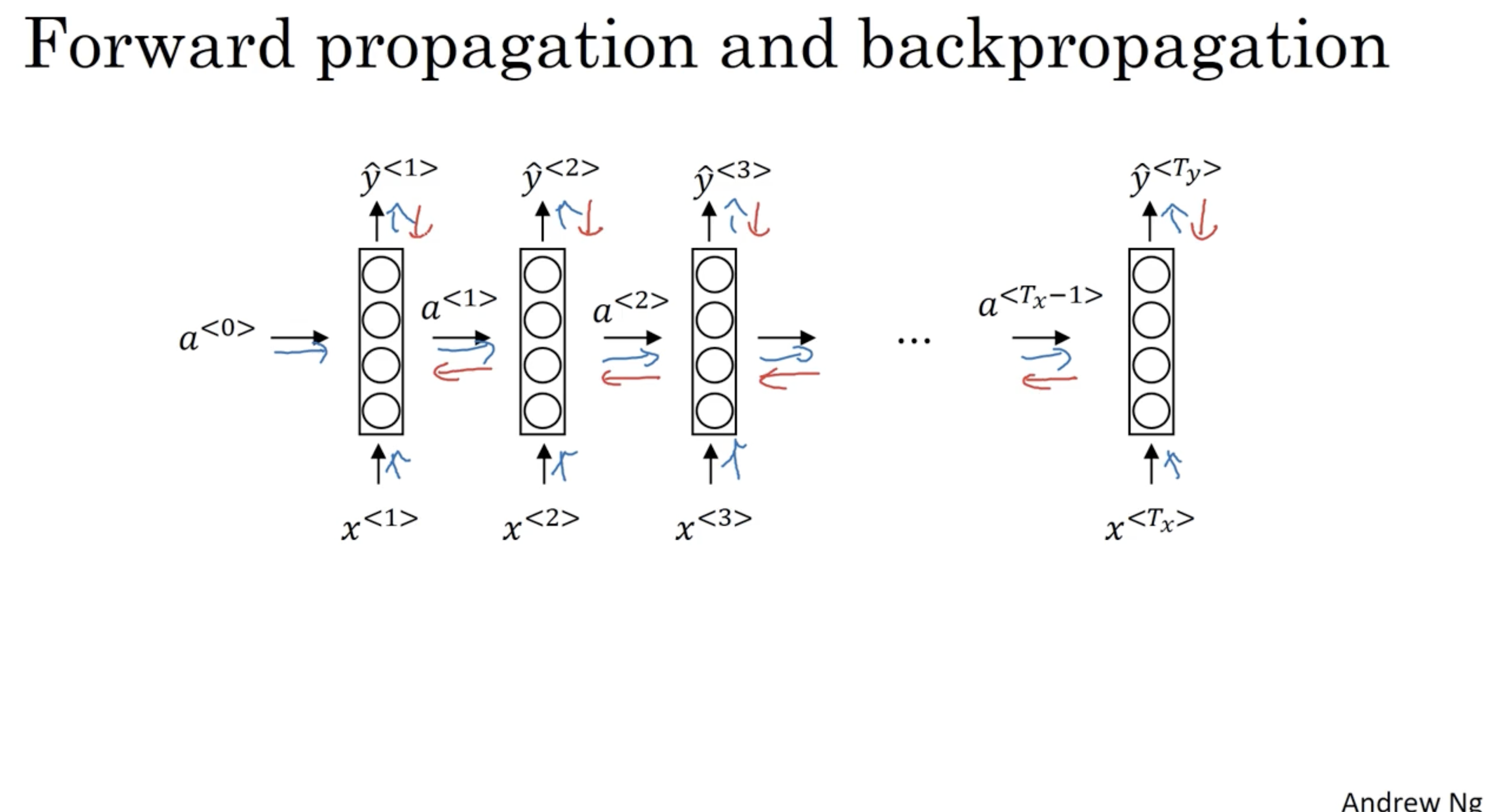
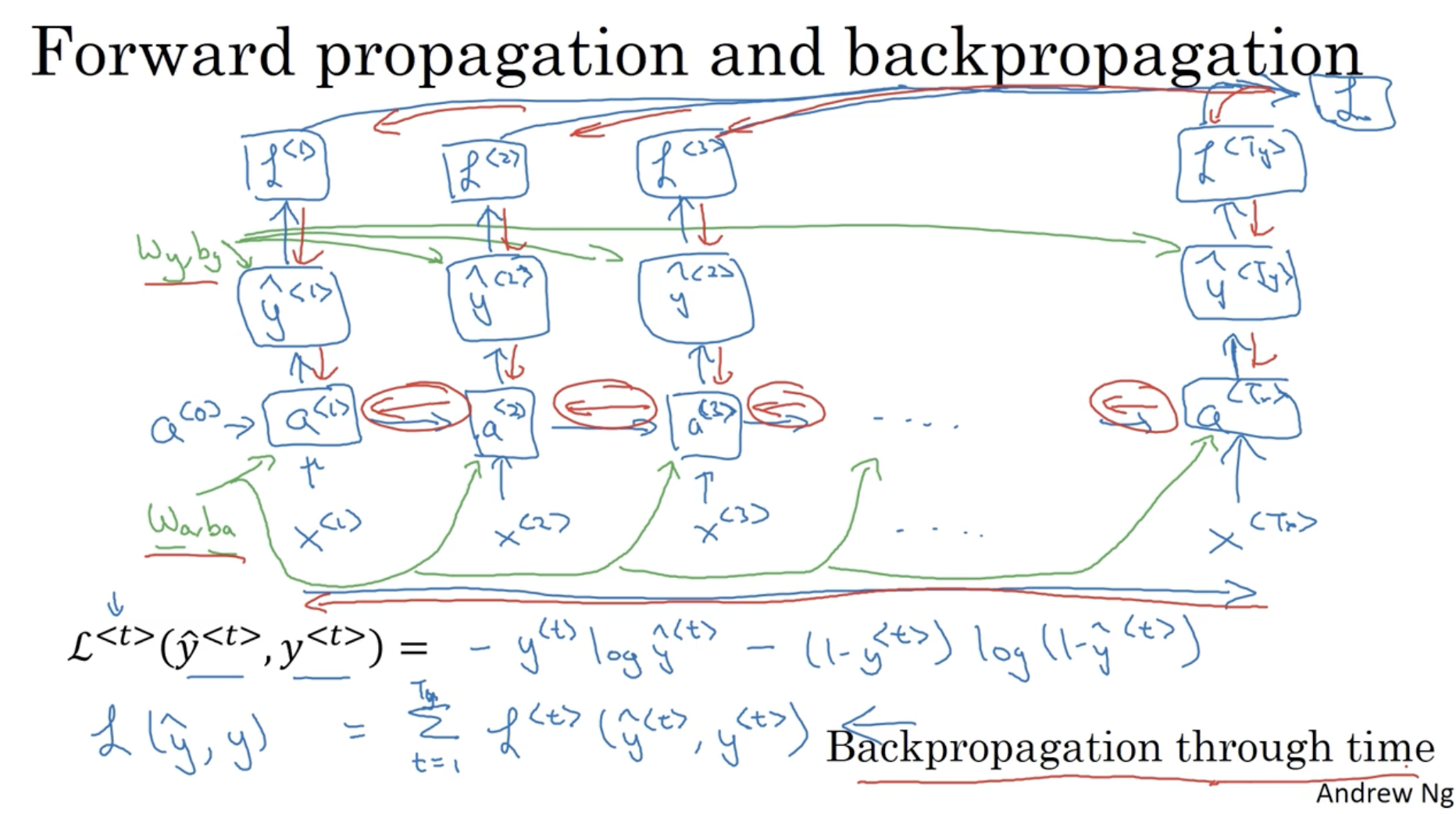
RNN 의 backpropagation 은 forward propagation 의 반대 방향으로 진행하면 된다.
그리고 RNN 의 Loss function 은 아래와 같다.
- 번째 단어에 대한 Loss 값이다.
- 따라서 전체 Loss 값 는 다음과 같이 나온다.
- 그리고 backpropagation은 forward propagation의 반대 방향으로 진행된다. RNN 은 각 에 대해서 backpropagation을 진행한다.
위의 예시들은 모두 인 시퀀스 데이터만 다뤘다.
- 하지만 실제 시퀀스 데이터들은 아래와 같이 인 경우가 많다.
- 따라서 이러한 요소를 고려하여 다양한 구조의 RNN 모델이 존재할 것이다.
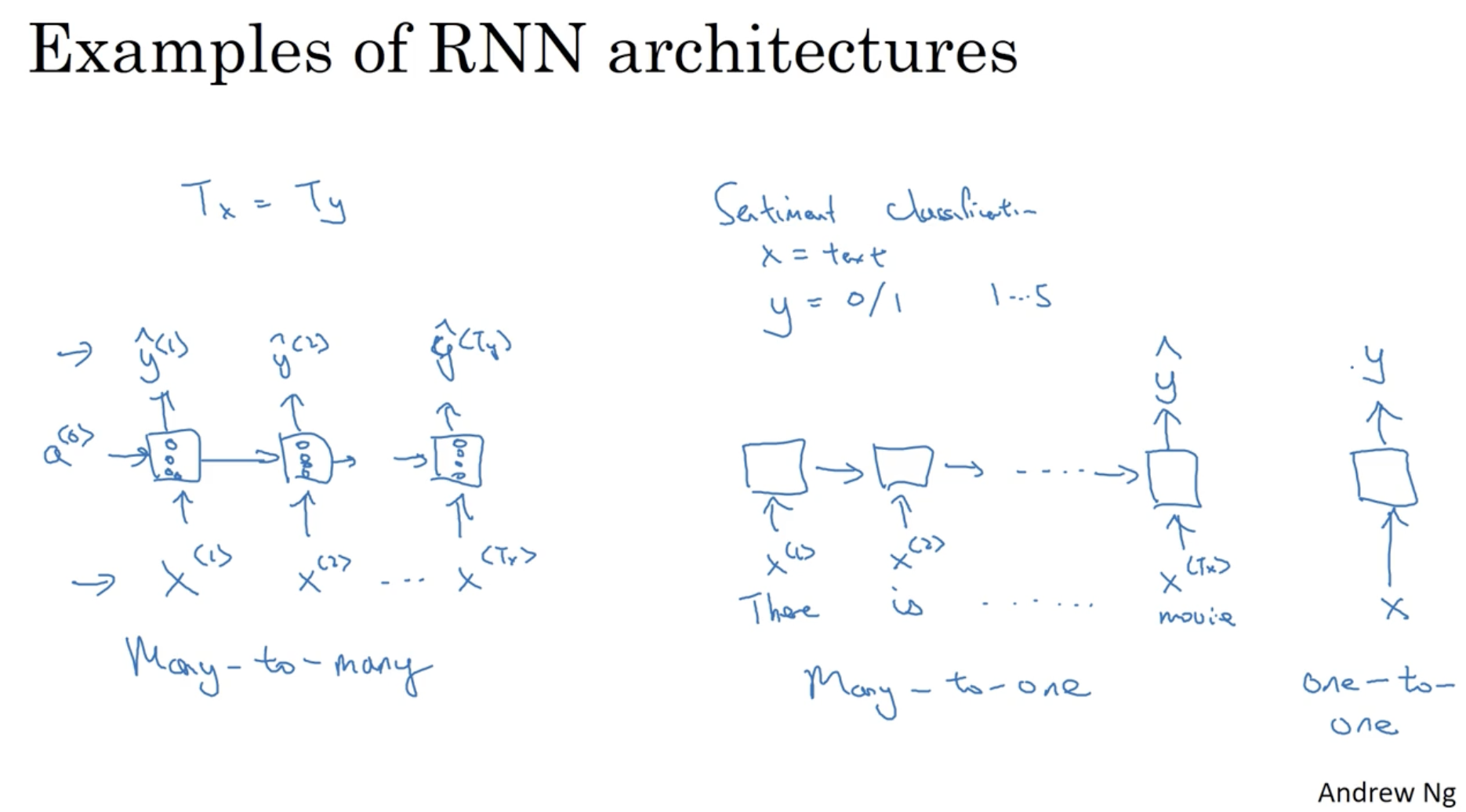
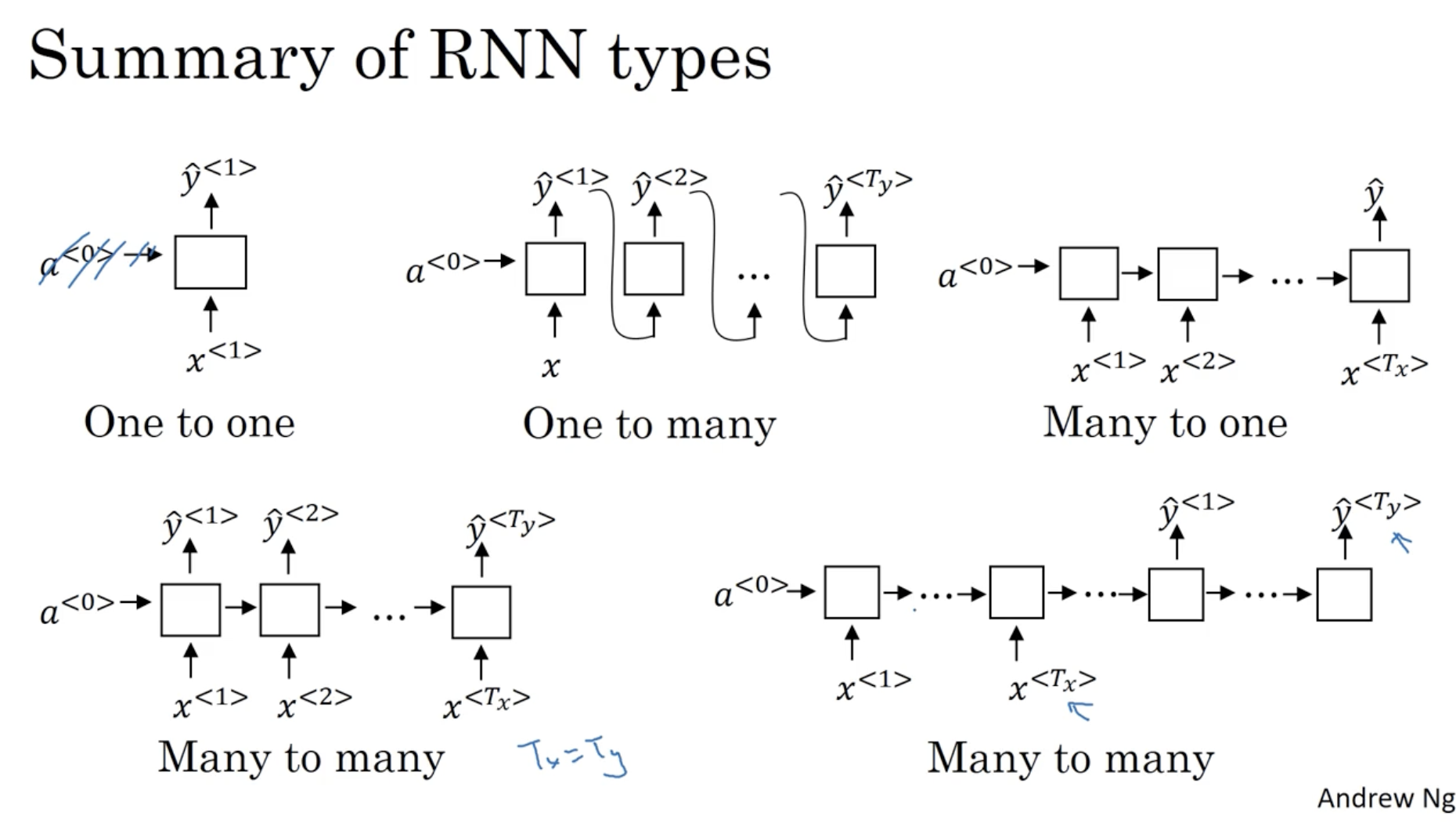
다음은 시퀀스 데이터의 크기에 따른 (에 따른) RNN 구조들이다.
- Many-to-many : 인 경우이다. 즉, 많은 시퀀스 데이터가 입력으로 주어지고 같은 크기의 시퀀스 데이터가 출력되는 경우이다. (이전에 계속 다뤄온 경우가 여기에 해당한다.)
- Many-to-one : 인 경우이다. 즉, 많은 시퀀스 데이터가 입력으로 주어지고 하나의 시퀀스 데이터가 출력되는 경우이다. (예시로 위 슬라이드의 Sentiment Classification 를 들 수 있다.)
- One-to-one : 이는 일반적인 neural network 에 해당할 것이다.
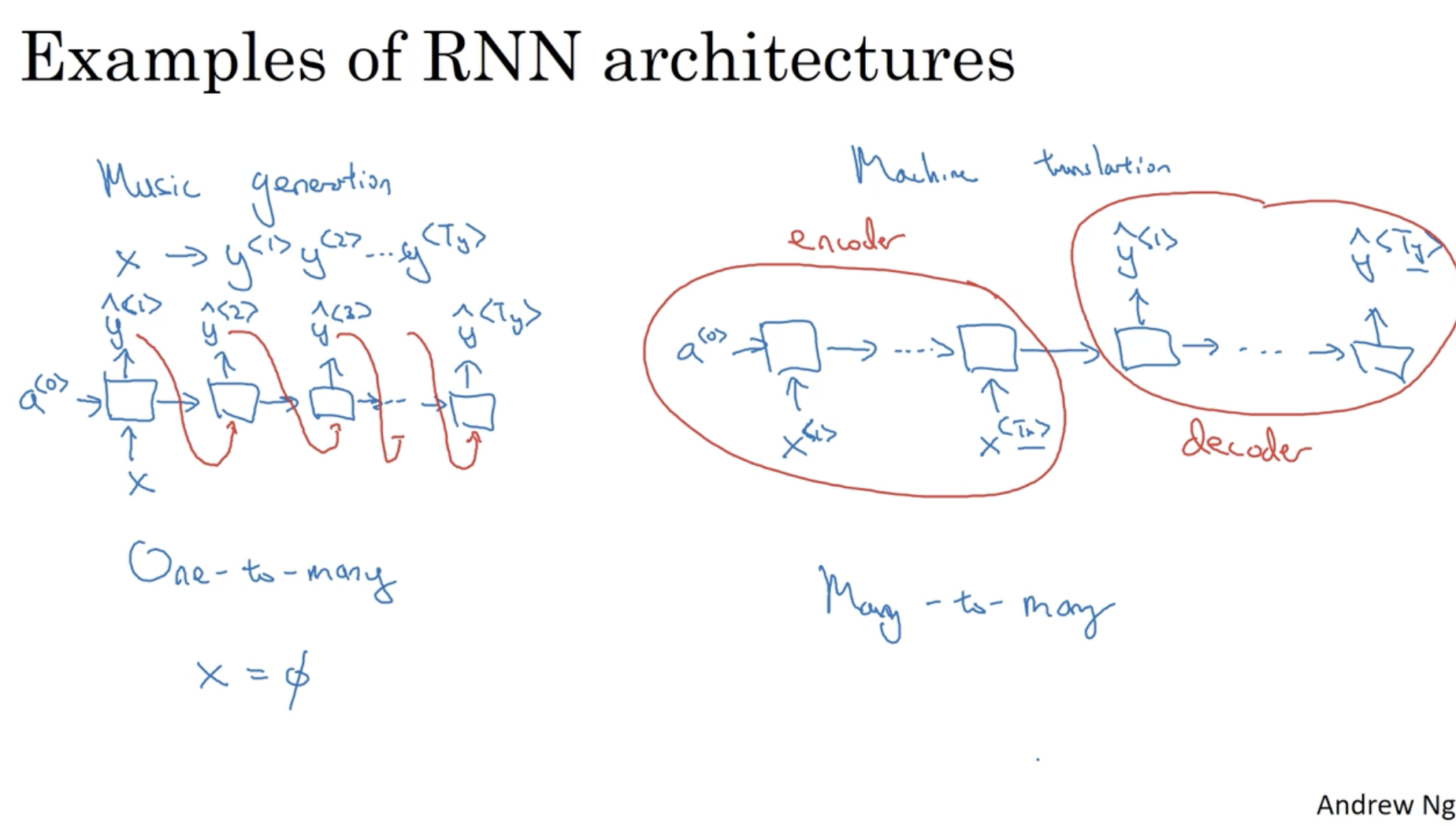
계속해서 시퀀스 데이터의 크기에 따른 RNN 구조들을 보자.
- One-to-many : 인 경우이다. 예시로 music generation 을 들 수 있다. 이 경우 입력 시퀀스 데이터는 이며, 출력 시퀀스 데이터는 매우 많다.
- Many-to-Many : 위에서 본 인 경우 말고 인 경우이다. 예시로 Machine Translation 을 들 수 있다. 이 경우 모델의 구조는 시퀀스의 각 데이터 에 대해서 먼저 학습을 하고 이후, 시퀀스의 각 데이터 를 출력하는 구조로 이루어져 있다.
- 그리고 이 경우 를 학습하는 영역을 encoder , 를 출력하는 영역을 decoder 라고 부른다.
따라서 RNN 의 종류를 요약하면 아래와 같다.
다음으로 RNN 의 대표적인 모델인 language 모델에 대해서 알아보자.
- 아래와 같이 speech recognition 의 경우, "pair", "pear"와 같이 발음이 같은 단어가 있을 수 있다.
- 그렇다면 이 경우 앞뒤 문맥을 고려하여 "pear" 가 들어간 문장이 더 맞을 확률이 높게 나와야 한다.
- 따라서 예측 시퀀스 데이터에 대한 확률이 가장 높은 문장을 선택할 것이다.

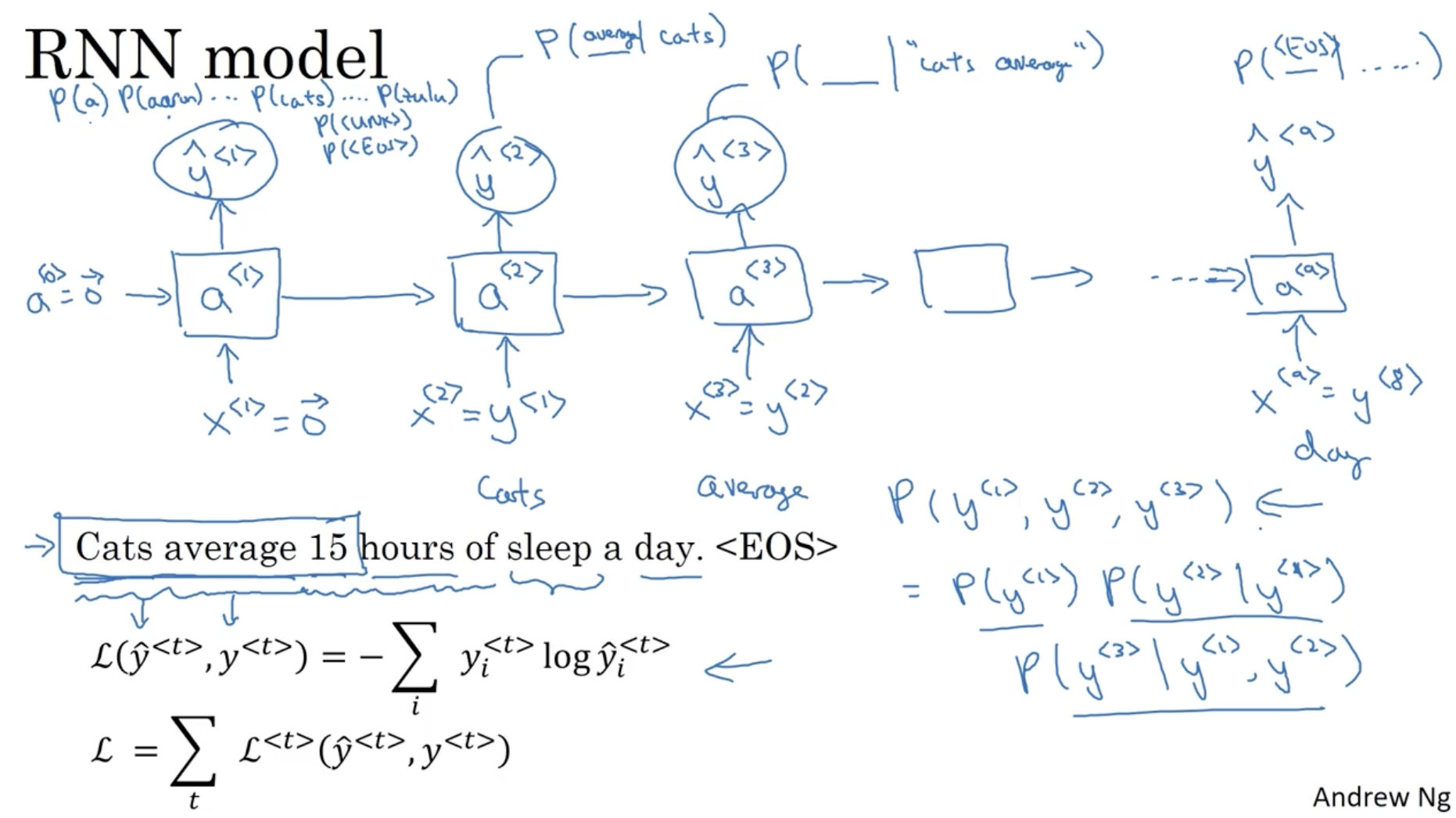
language model 의 학습 데이터는 large corpus 이다. (쉽게 생각하면 단어 사전이다.)
- 그리고 language 모델은 먼저 sentence 에 대해서 tokenize 를 실행한다.
- "Cats average 15 hours of sleep of a day." 라는 문장이 있을 때, tokenize 가 적용된 시퀀스를 다음과 같이 표현한다.
- Cats :
- average :
- ... day :
- 그리고 "." 은 무시하며, 마지막에 문장이 끝났음을 의미하는 <EOS> 토큰을 추가해준다.
- <EOS> :
- 또한, 만약 단어 사전에 존재하지 않는 단어가 들어올 경우 해당 단어를 <UNK> 토큰으로 변경해준다. ( UNK = unkown ) ( ex. Mau -> <UNK> )

그리고 language model 의 예측은 아래와 같은 방식으로 진행된다.
- 먼저 으로 입력을 주고 시작한다.
- 그리고 단어 사전에 존재하는 모든 단어 word에 대해서 확률을 계산한다. (by sigmoid)
(정답값 : )- 그리고 다음 입력값으로 을 입력값으로 넣고 단어 사전에 존재하는 모든 단어 word에 대해서 확률을 계산한다.
(정답값 : )- 그리고 다음 입력값으로 을 입력값으로 넣고 단어 사전에 존재하는 모든 단어 word에 대해서 확률을 계산한다.
(정답값 : )- 이런 식으로 <EOS> 에 도달할 때까지 진행한다.
- 참고로 은 다음과 같이 계산된다.
- 그리고 시퀀스의 번째 단어에 대한 Loss 값은 다음과 같이 구해진다.
- : sigmoid Loss.
- 그리고 전체 Loss 은 다음과 같다.
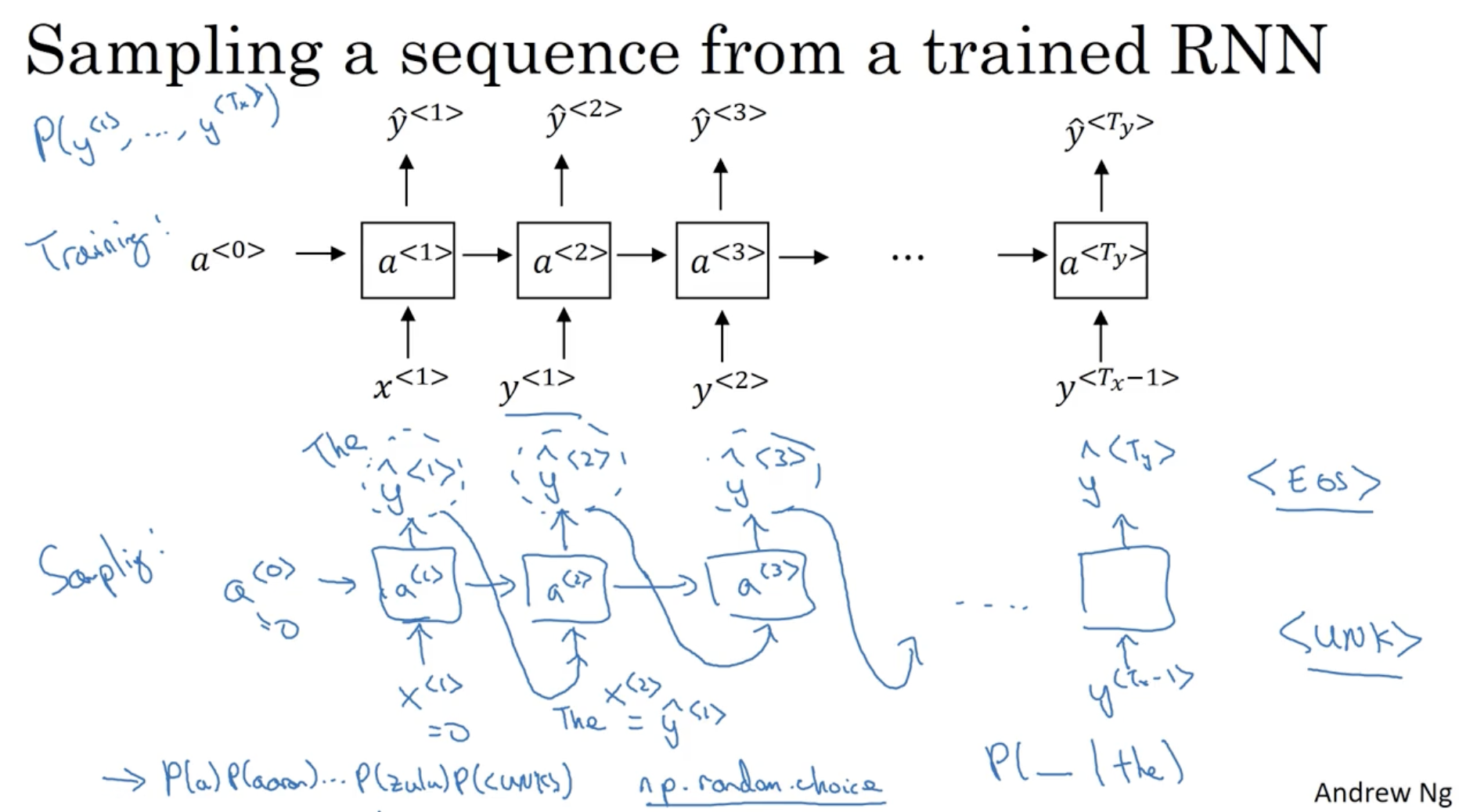
그렇다면 language 모델이 잘 학습되었는지 어떻게 확인할 수 있을까.
- 아래와 같이 학습된 모델에 입력 시퀀스를 주지 않고, 예측 시퀀스 을 다음 입력 시퀀스로 로 둔다.
- 다만 첫번째 단어의 경우 아무 값도 주어지지 않기 때문에
np.random.choice와 같이 랜덤하게 적용해준다.- 위 과정을 통해서 예측된 단어 시퀀스를 확인할 수 있을 것이다.
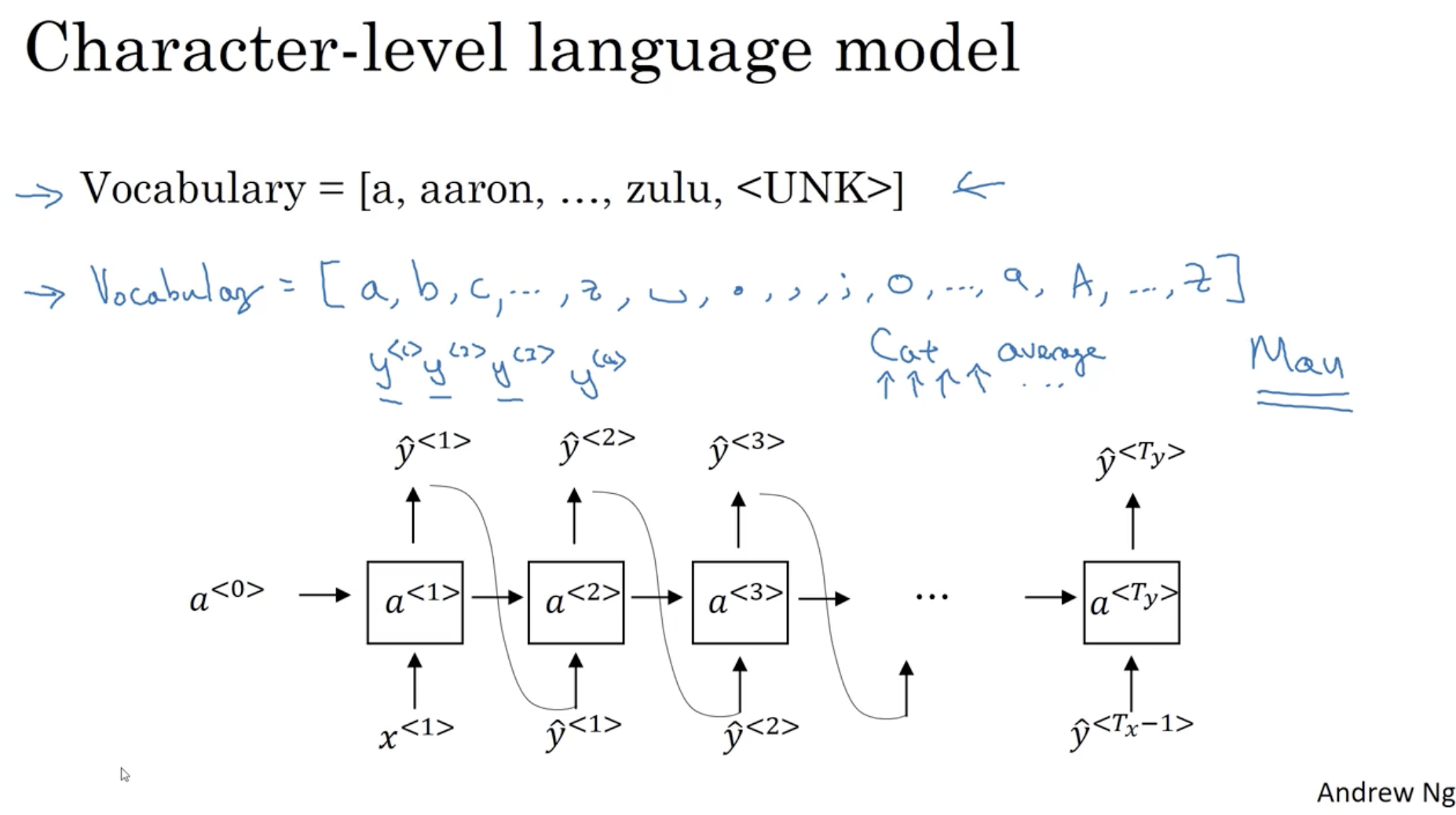
위에서 다룬 language model 은 단어 단위로 학습하지만, character 단위로 학습하는 경우도 있다.
- 아래와 같이 사전에는 알파벳, 기호, 숫자 등등이 포함된다.
- 그리고 마찬가지로 단어 단위와 같은 방식으로 학습을 진행한다.
- 하지만 chracter 단위로 학습하는 경우 모델이 더 복잡하고 난이도가 어려워진다.
아래는 languge model 로 (시퀀스 데이터인) 문장을 생성한 예시이다.
- 좌측은 뉴스 문장 위주로 학습한 모델이 생성한 문장이고,
- 우측은 셰익스피어 책 위주로 학습한 모델이 생성한 문장이다.

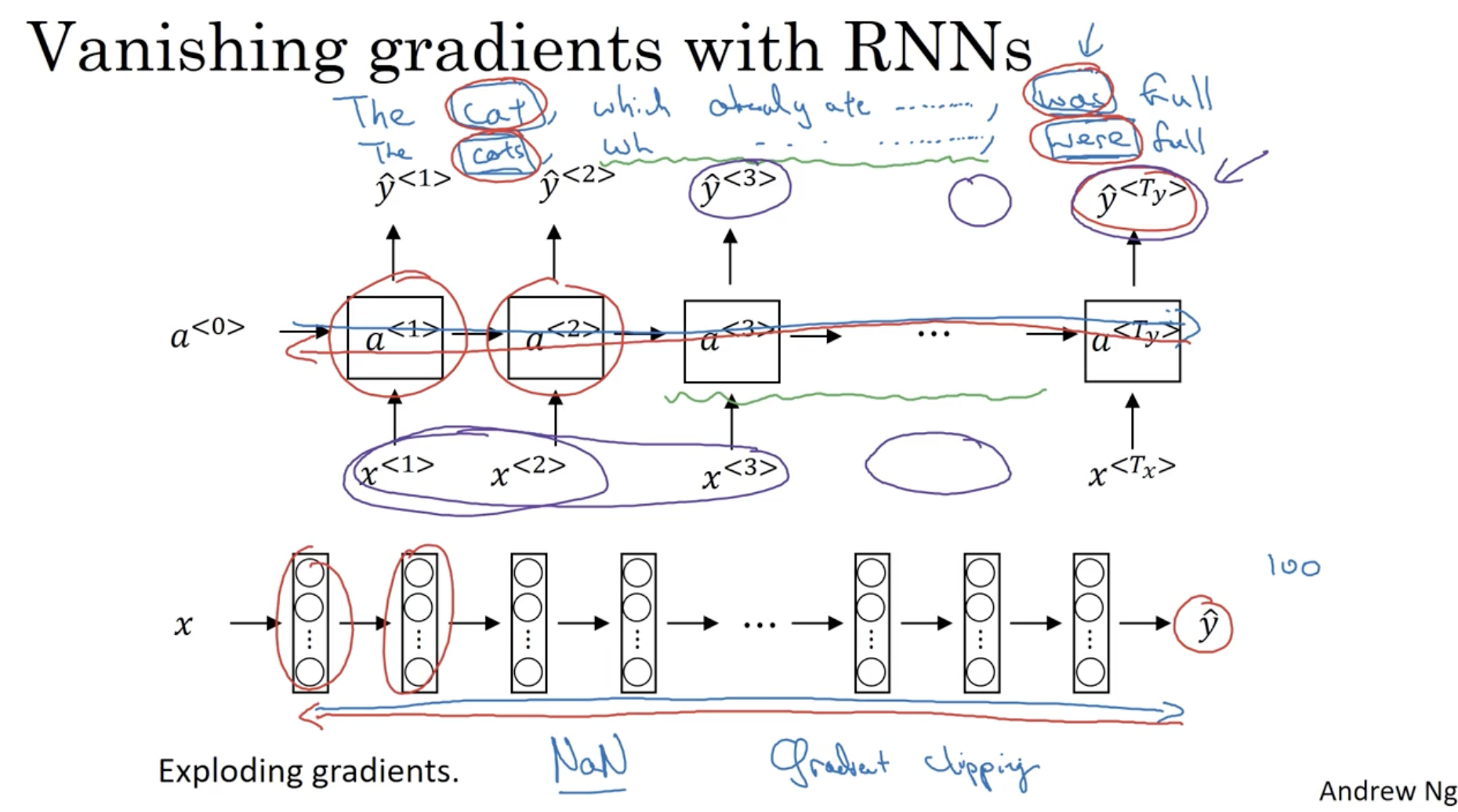
다음으로 RNN 모델의 가장 큰 문제점인 Vanishing gradients 문제점을 다뤄본다.
- "The cat, which already ate ..................., was full." 라는 문장과 "The cats, which already ate ..................., were full." 라는 문장이 있을 때, "cat"에 대해서는 "was"로 "cats"는 "were" 로 예측을 해야 한다.
- 하지만 일반적인 RNN 의 경우, 각 예측값 은 다른 의존성이 매우 지역적이다. 따라서 위와 같은 문장이 주어질 경우, 나중에는 초반에 주어진 단어의 의존성은 거의 없을 것이다.
이러한 문제점이 바로 vanishing gradients 문제이다.- 따라서 RNN에서 긴 sequence 에 대해서 초반 sequence 의 의존성이 유지될 필요가 있다. 이를 위해 뒤에서 GRU 및 LSTM 을 배운다.
- (물론 gradients 가 증폭하는(exploding) 문제점도 있지만, 이 경우에는 gradient clipping 을 적용하여 문제를 해결할 수 있다.)
다음으로 GRU (Gated Recurrent Unit) 에 대해서 알아보자.
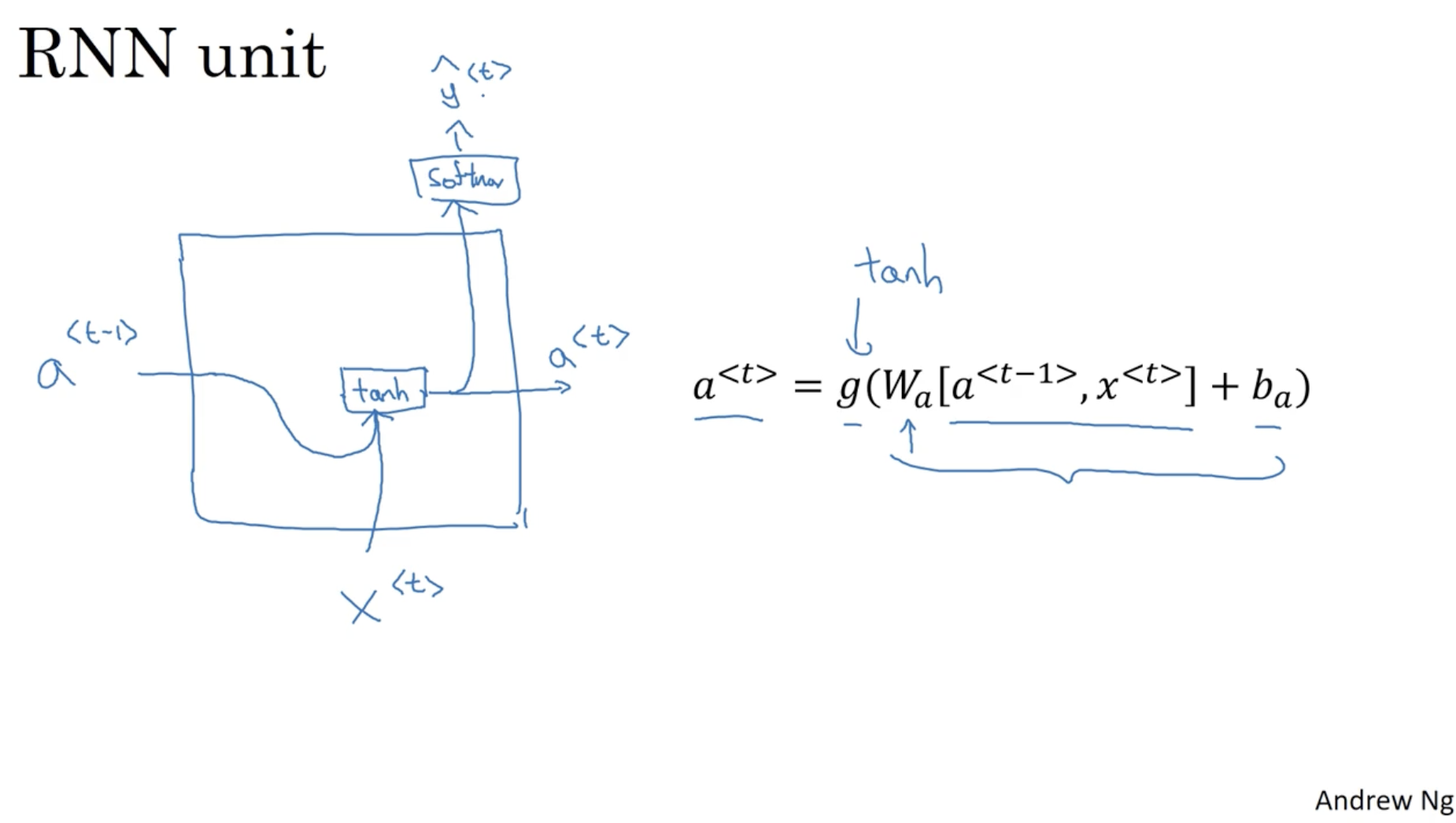
- 우선 기존의 RNN unit 의 구조를 복기해보자.
- 우측 수식과 같이 activation은 다음과 같다.
- 그리고 예측값 수식은 다음과 같다.
- 그리고 이를 그림으로 표현하면 아래와 같은 구조를 보여준다.
이제 GRU (unit) 의 구조를 알아보자.
- 는 memory cell 을 의미하며, 이다.
- 이다. (이전 memory cell의 값이 반영되는 것을 알 수 있다.)
- ( 거의 0 또는 1의 값을 가지며, 이전 memory cell의 값을 가지고 update 유무를 판단한다. )
- (다음 시퀀스에 전달할 memory cell은 update 가중치에 따라 새로운 memory cell의 값과 이전의 memory cell 의 값을 더해준 값이다. 여기서 은 element-wise product 를 의미한다.)
- 그리고 그 구조는 아래 그림과 같다.
- 만약 이전의 예시에서 봤던 The cat, which already ate ...., was full 문장에 대해서 GRU 를 적용하면, cat 단어에서 처럼 단수형을 의미한다는 memory cell 이 업데이트되어, 계속 이어지면서 was 단어를 만나고, was 에서 해당 memory cell 과 입력 시퀀스를 함께 고려하여 해당 위치의 단어는 was 라고 예측할 것이다.
- 결론적으로 GRU 를 활용하면 긴 시퀀스의 모델도 학습이 가능하다는 장점이 있다. ( gradient vanishing 문제를 해결하였다. )

더 나아가 GRU 에 새로운 게이트 을 추가해보자. 이는 relevant (연관성) 를 의미한다. 이게 최종적인 GRU 이다.
- : 이전의 memory cell 과의 연관성 게이트를 추가하였다. (다른 논문에서는 대신 로 표기하기도 한다.)
- ( 로 표기하기도 한다.)
- ( 로 표기하기도 한다.)
- ( 로 표기하기도 한다.)
- 이처럼 GRU 을 응용하여 다양한 연구들이 발전할 수도 있다.
- 그리고 GRU 와 비슷한 아이디어를 가진 연구들도 있으며 가장 대표적으로 LSTM 을 꼽을 수 있다.
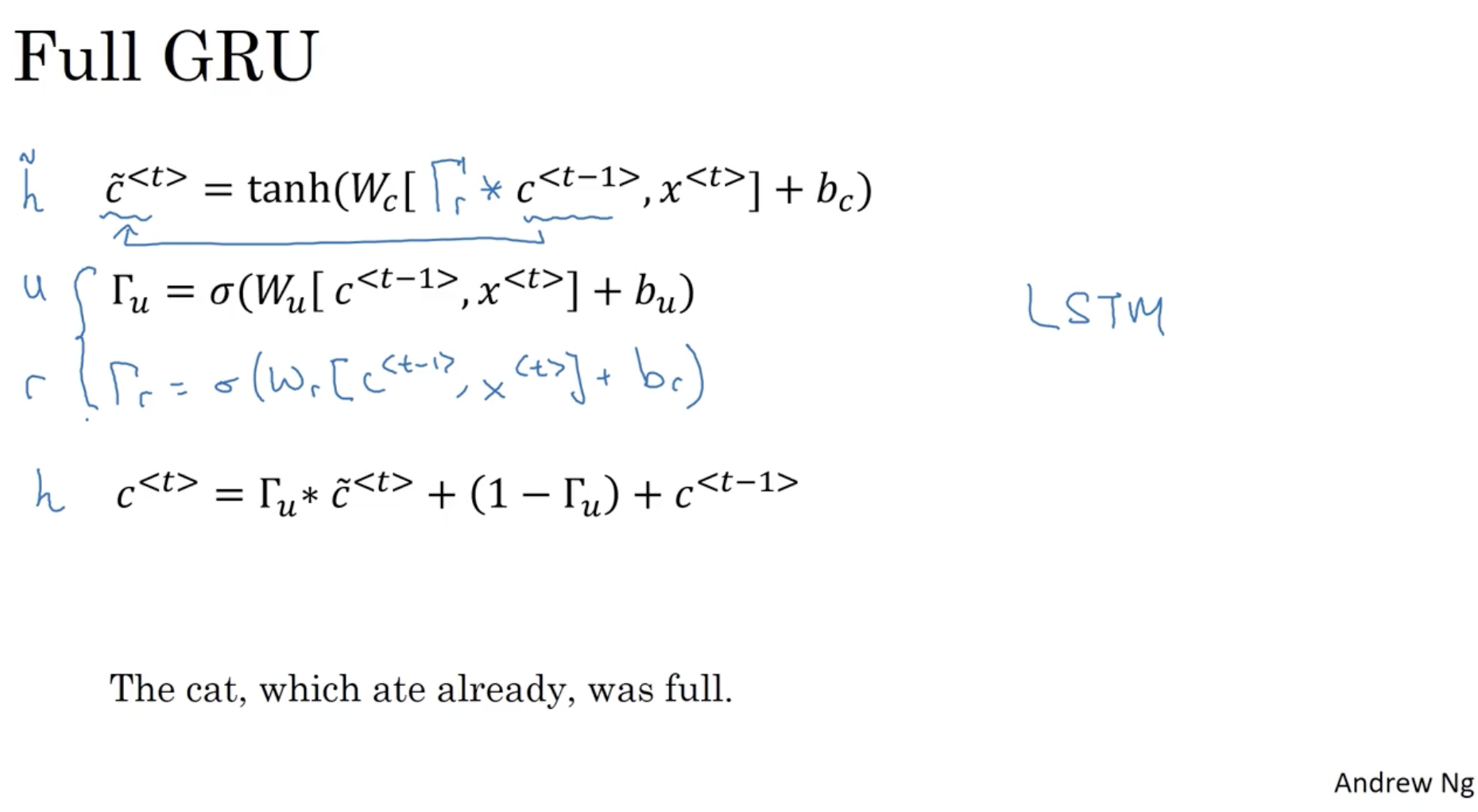
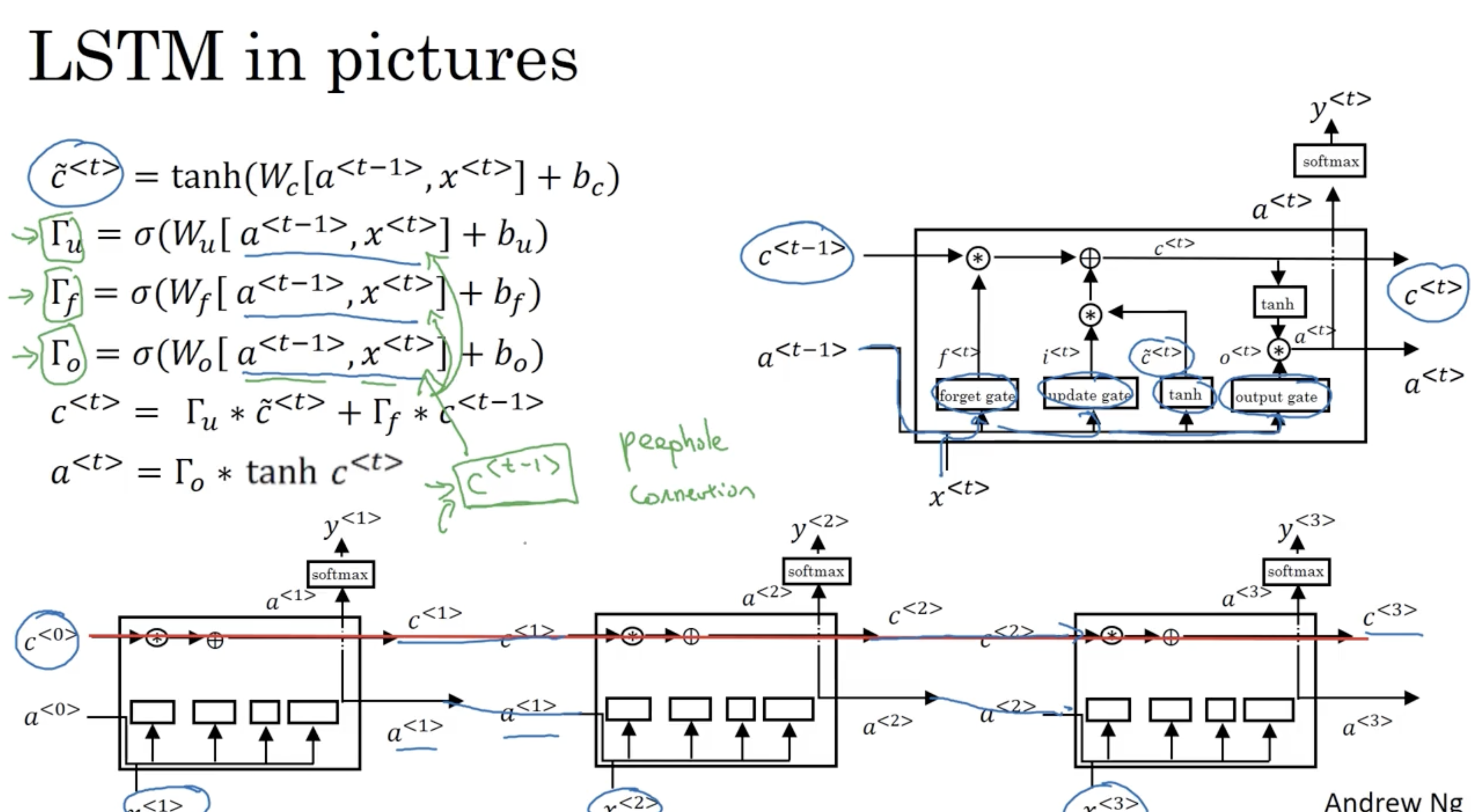
LSTM 은 GRU 와 비교했을 때 다음과 같은 수식으로 진행된다.
- 우선 LSTM 에서는 GRU 와 달리 이다.
- : update gate
- : forget gate
- : output gate
- : 새로운 memory cell 로 얼마나 업데이트 할지 + 기존의 memory cell 을 얼마나 잊을지를 결정
- (그림은 오타)
- 비교적 GRU 는 간단한 게이트 구조를 이루며 LSTM 은 좀더 복잡하고 유연한 게이트 구조를 이루고 있음을 알 수 있다.

LSTM 의 구조를 그려보면 아래와 같다.
- GRU 와 마찬가지로 LSTM 도 값이 계속 유지될 수 있기에 긴 시퀀스 모델도 학습이 가능하다. ( vanishing gradient 문제를 해결할 수 있다. )
- LSTM 이 GRU 보다 더 먼저 나온 기술이지만, 일반적으로 더 유연하고 복잡한 구조를 띄고 있기에 성능이 더 좋은 편이다.
- 반면에 GRU 는 LSTM 을 단순화한 구조로, 연산 비용이 더 저렴하다는 장점이 있다.
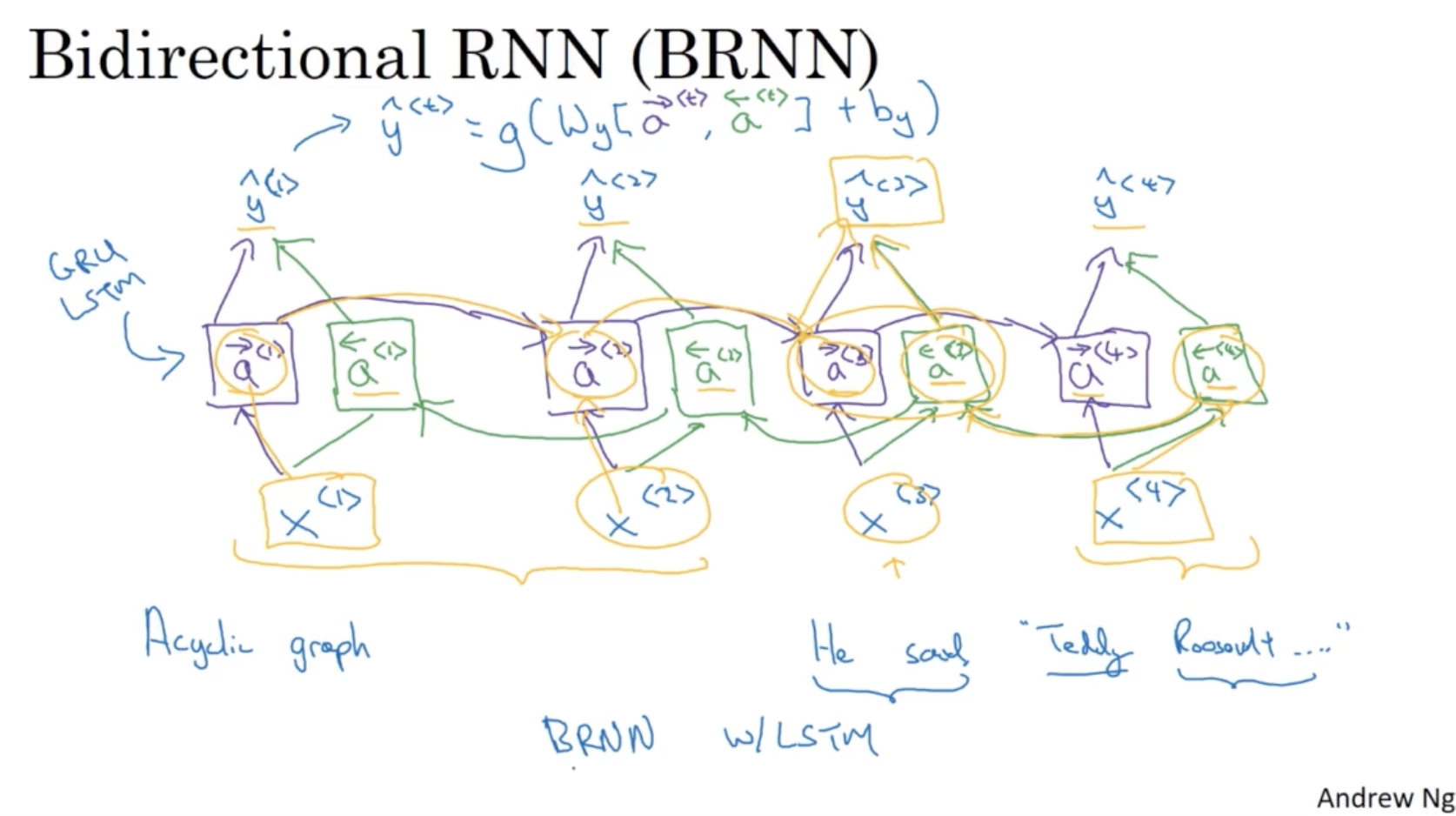
다음으로 Bidirectional RNN ( BRNN ) 에 대해서 알아본다.
- 아래와 같이 두 문장에서 Teddy 가 사람 이름을 의미하는지, 아니면 곰 인형을 의미하는지 당시 시퀀스에서는 알 수가 없다.
- 따라서 이를 위해 forward connection 뿐만 아니라 backward connection 이 추가된 BRNN 이 개발되었다.
BRNN 의 구조는 아래와 같다.
- forward + backward connection 을 통해서 예측을 진행한다.
- 따라서 이 경우 전체 시퀀스 데이터가 주어진 상태에서 예측을 할 수가 있다. (ex. 음성 인지의 경우, 발화자의 말이 끝날 때까지 기다렸다가 끝나면 총 시퀀스 데이터를 입력해야 함. )
- 일반적인 RNN Unit 과 더불어, GRU 혹은 LSTM 유닛으로도 적용할 수 있다. (Ex. BRNN with LSTM )
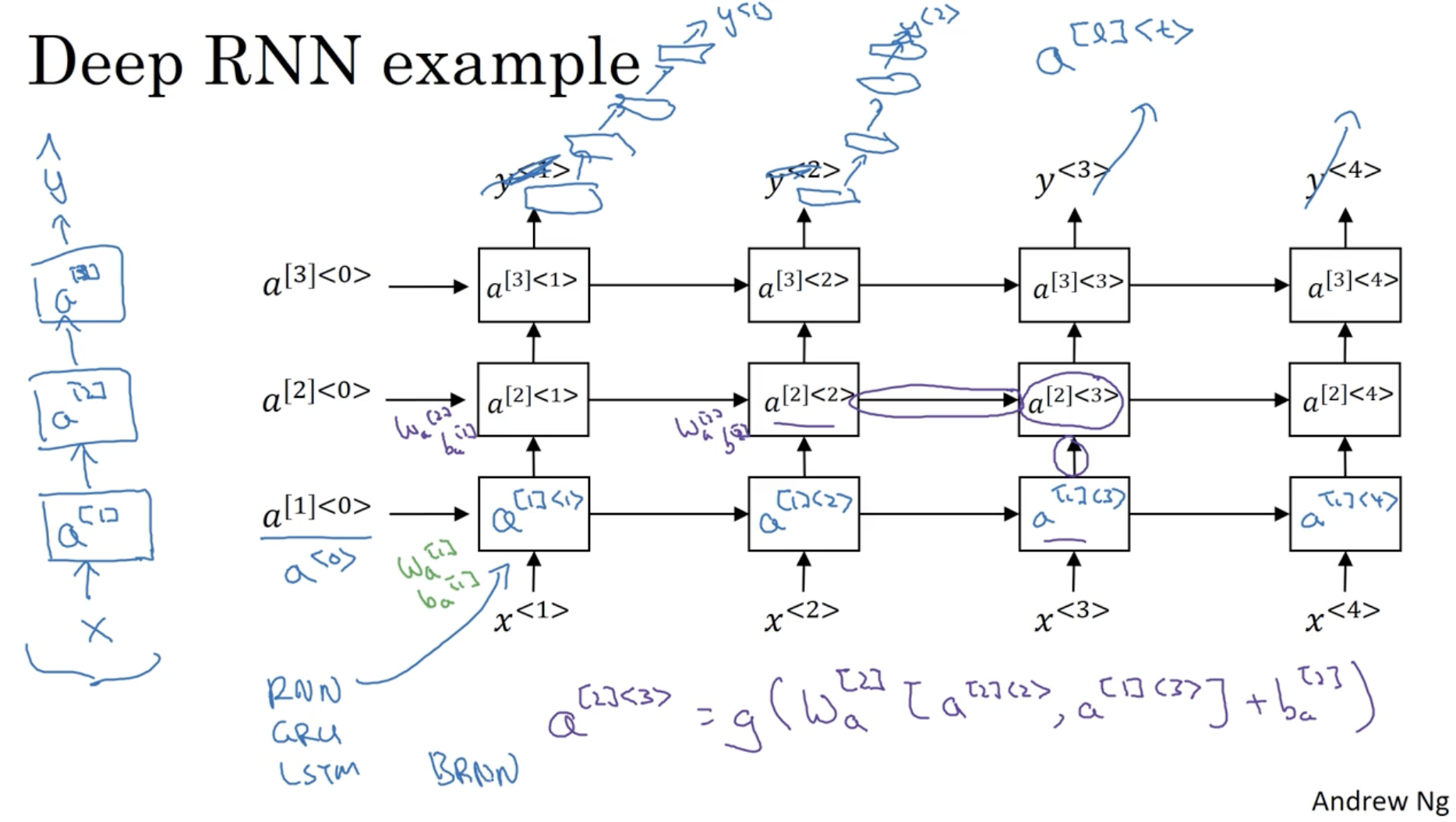
그리고 위에서 봤던 RNN 모델들은 모두 하나의 레이어에 대한 RNN 이었다. Deep RNN 은 다음과 같은 구조를 띈다.
- : 번째 레이어의 번째 시퀀스 데이터에 대한 activation.
- ex.
- 다만 RNN 의 경우 그 자체만으로 매우 복잡한 구조를 띄며 연산 비용이 많이 들기에, 다른 DNN 처럼 100개 이상의 히든 레이어를 구성하는 등의 구조는 거의 힘들다.
- 그리고 RNN 유닛 대신 GRU, LSTM, BRNN 유닛 등을 적용할 수도 있다.