다음으로 word representation 에 대해서 알아보자.
- 아래와 같이 각 단어는 10000개의 단어를 갖고 있는 사전 에 대한 1 hot vector 로 표현될 수 있다.
- 그리고 우측과 같이 orange __ , apple __ 에 대해서 orange juice 라고 예측할 경우, 이와 유사한 apple 뒤에도 juice 가 나오도록 하면 더 빠르게 예측이 가능할 것이다.

이를 위해 각 단어를 featurized 한다. ( word embedding 을 적용한다. )
- 총 300개의 단어 features 가 있고, 각 단어는 아래와 같이 각 feature 들에 대한 값을 갖는다.
- 이걸 word embedding 이라고 부른다. 보다시피 apple 과 orange 는 feature 들의 값이 거의 유사한 것을 볼 수 있다.
- : 단어 사전에서 5391 번 인덱스에 해당하는 단어의 embedding 된 벡터

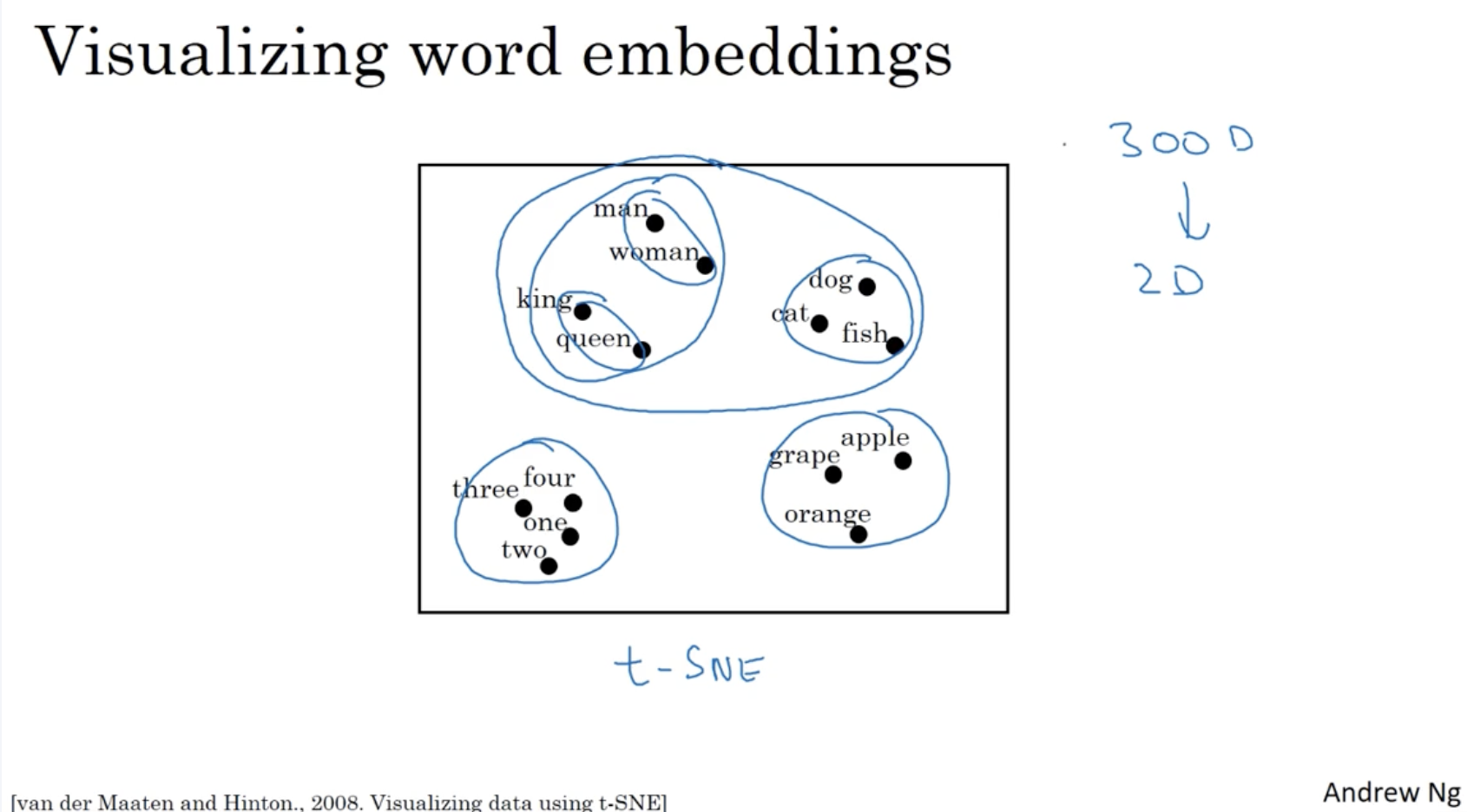
(300, 1) 차원을 갖는 단어의 features 정보를 2 차원으로 표현하면 아래와 같이 나온다.
- 보다시피 유사한 feature 를 갖는 단어들끼리 가깝게 분포되어 있는 것을 확인할 수가 있다.
- 이때 적용된 방법은 t-SNE 이다.
다음으로 word embedding 활용의 구체적인 예시를 생각해보자.
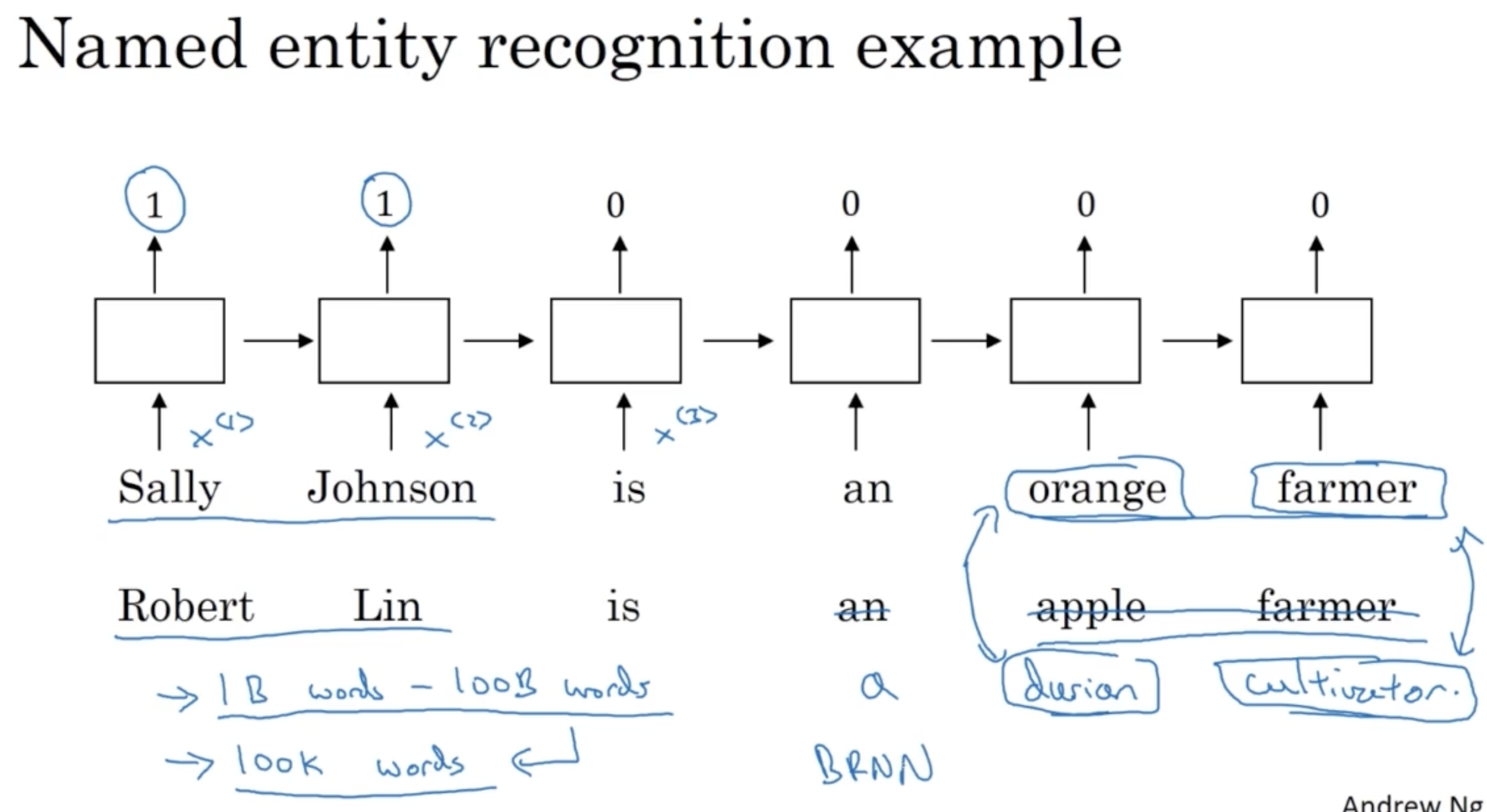
- 아래와 같이 사람 이름에 해당하는 단어를 인지하는 예시를 생각해본다.
- 만약 첫 번째 문장처럼 Sally Johnson is an orange farmer 라는 문장에서 orange farmer 를 보고 앞 단어 Sally Johnson 이 사람 이름이라고 추정이 가능할 것이다.
- 그리고 만약 두 번째 문장과 같은 시퀀스가 주어졌을 때, durian 과 cultivator 라는 단어가 사전에 존재하지 않는다면 해당 모델은 orange-durian, farmer-cultivator 와의 word embedding 유사도를 보고 앞 Robert Lin 이 사람 이름이라고 추정할 수 있다.
- 이처럼 word embedding 을 적용하기 위해 인터넷에서 1억 개에서 100억 개까지의 unlabeld data 를 학습하여 transfer learning을 적용하여 word embedding 이 적용된 100K 개의 단어 사전을 만들 수가 있다.
- 또한 아래 모델은 단순히 unidirectional RNN 의 구조로 그렸지만, BRNN 등을 적용할 수도 있다.
아래는 transfer learning 의 개략적인 절차에 대한 내용이다.
1. 인터넷과 같은 곳으로부터 매우 많은 텍스트들을 통해 word embedding 을 학습한다. (1-100억 개의 단어) (혹은 미리 학습된 embedding 을 다운로드 받는다.)
2. 위 과정에 학습한 word embedding 에 transfer learning 을 적용하여 작은 학습 데이터셋을 만든다. (10만 개의 단어)
3. 계속해서 새로운 단어의 word embedding 을 finetune 할 수도 있다.

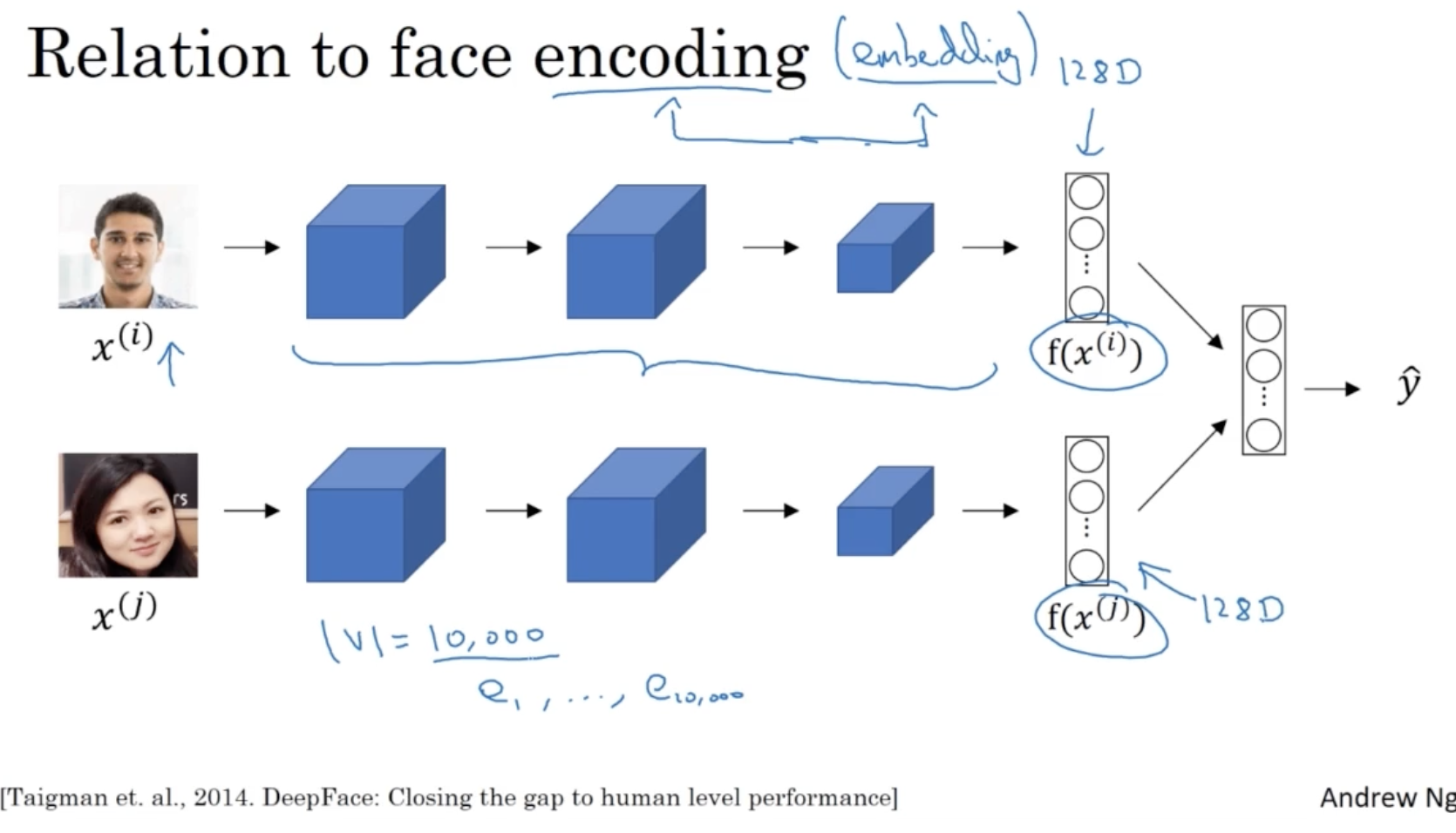
encoding 이라는 용어와 embedding 이라는 용어는 거의 비슷한 의미를 갖는다.
- 아래처럼 이전에 배웠던 Siamemes model 의 경우 마지막 layer 를 비교하면서 두 이미지 간의 유사도를 계산하는데, 이때 encoding 된 activations 벡터를 비교한다.
- 이처럼 보통 이미지 관련해서는 encoding 이라는 용어를 사용하고 NLP 와 같은 언어 처리에서는 embedding 이라는 용어를 사용한다.
word embedding 을 활용하는 구체적인 예시를 생각해보자.
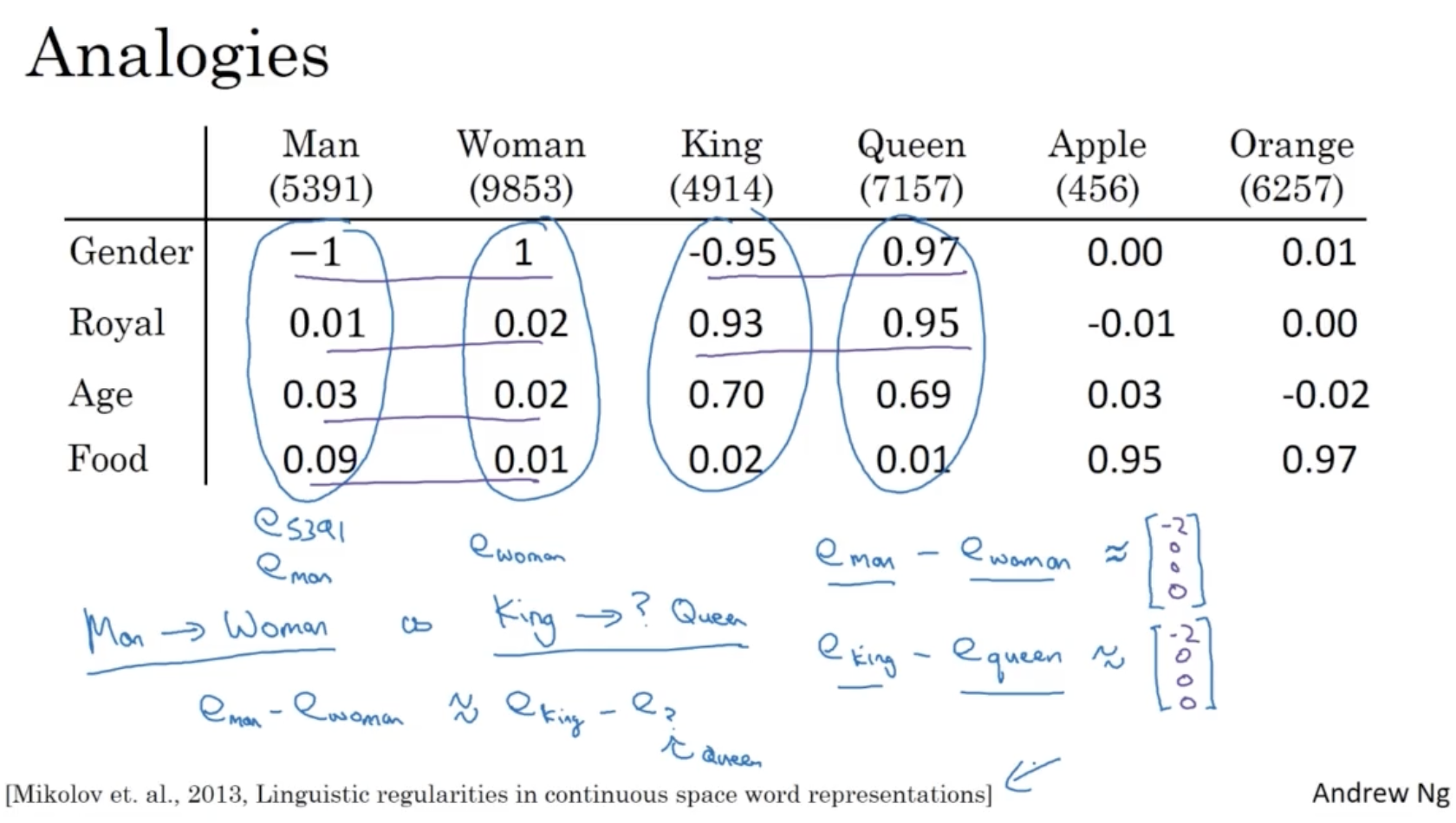
- 아래와 같이 word embedding dataset 이 있다.
- 그리고 다음과 같은 추론이 필요하다고 생각해보자. Man -> Woman , King -> ?
- 이 경우 man과 woman 의 word embedding 벡터의 차이는 gender feature 상의 차이밖에 없을 것이다.
- 그렇다면 King 이라는 단어는 어떤 단어와 비교했을 때 위와 같이 gender feature 차이만 존재하고 나머지 feature 차이는 없을까? 아마도 Queen 이라는 단어가 그럴 것이다.
- 따라서 King -> ? 에서 ?를 추론할 때, 조건을 가장 잘 만족하는 Queen 으로 예측할 수 있다.
아래와 같이 이를 그림으로 보면, man-woman 벡터 간의 차가 가장 유사한 건 king-queen 벡터 간 차라는 것을 알 수 있다.
- 따라서 formulize 하면 다음과 같이 작성할 수 있다.
- 그리고 연구에서 정확도를 검사한 결과 analogies using word vectors 는 30~75%의 정확도를 보여준다고 한다.

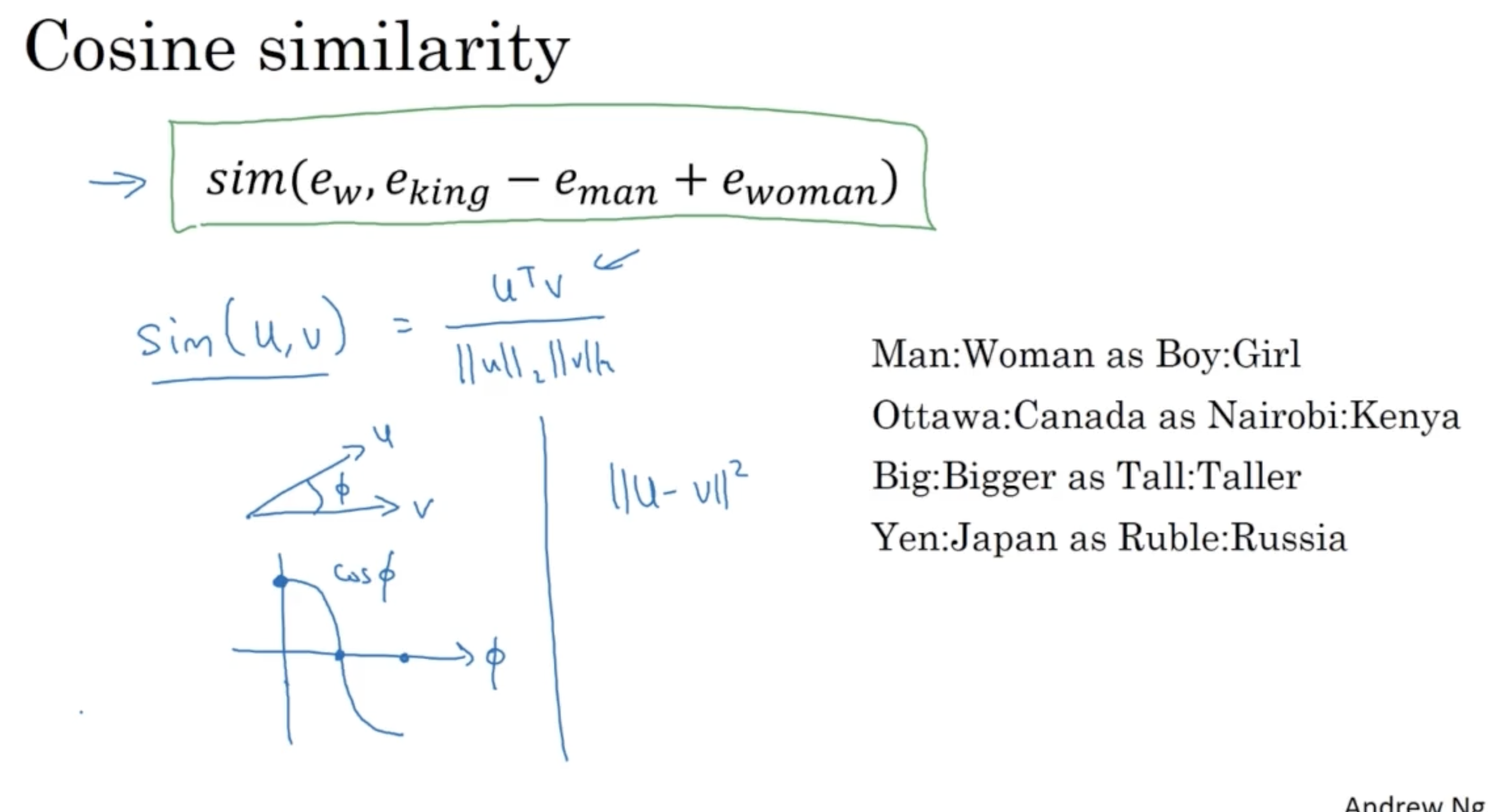
위에서 본 similarity 함수로 가장 많이 사용되는 게 cosine similarity 이다.
- cosine similiarity 함수는 다음과 같다.
- 또 다른 similarity 함수로 유클리드 거리도 있다. (하지만 보통 cosine similarity 함수를 더 많이 사용한다.)
- 이를 통해 우측과 같이 단어 간 유사도가 높은 쌍을 학습할 수 있다.
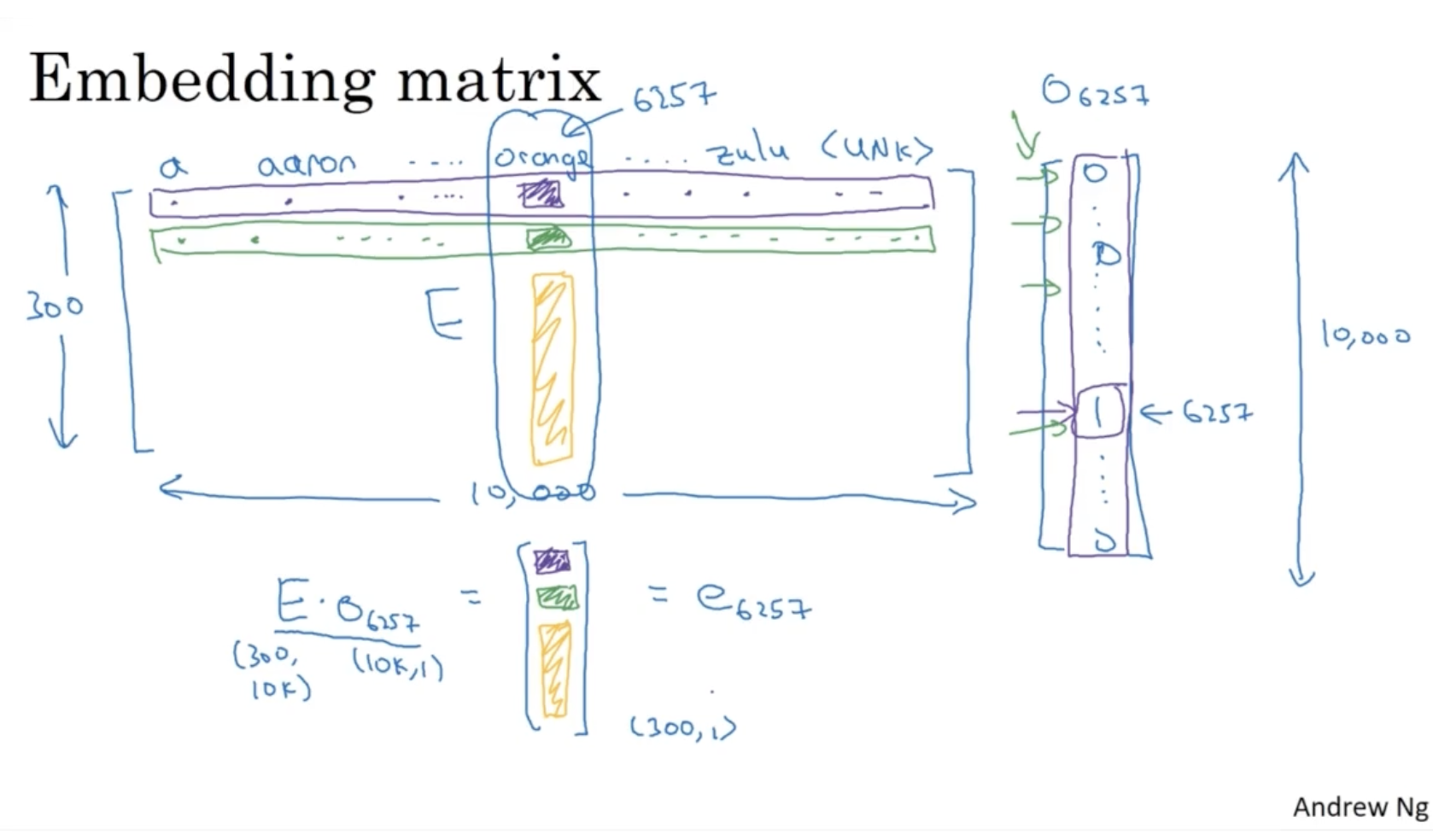
word embedding 행렬 E 는 다음과 같다.
- : 단어 사전에서 6257번째에 해당하는 단어의 1-hot vector.
- : 각 단어의 word embedding vector 를 갖는 행렬. (300: num of features, 10000 : num of words)
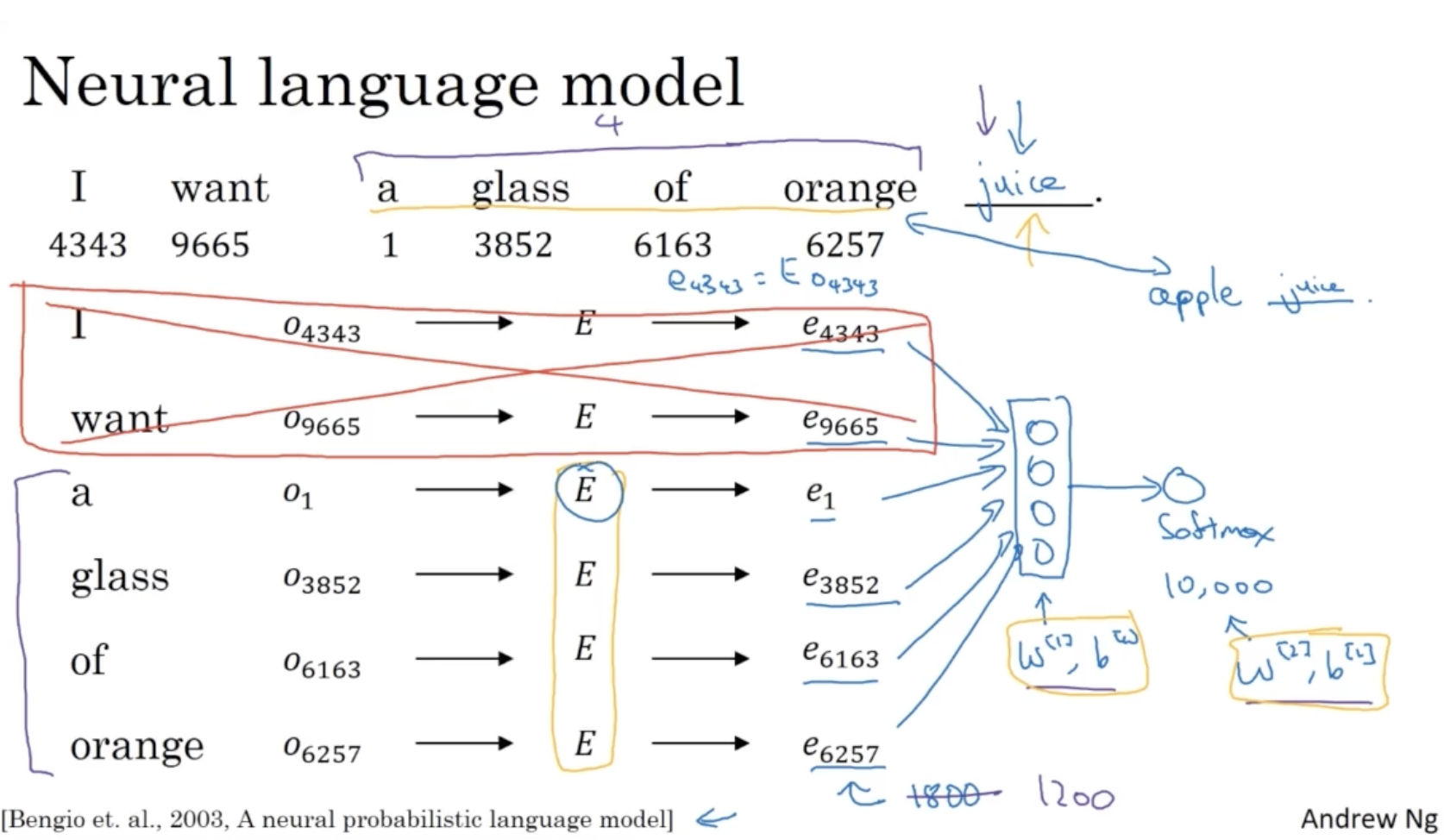
아래는 초기 neural language model 의 구조를 보여준다.
- 총 10000개의 단어를 갖는 사전이 있다고 가정한다.
- 각 단어에 대해서 word embedding matrix 와 one-hot vector 를 product 하여 embedding vector 를 구한다.
- 그리고 각 단어 를 stack 하여 하나의 vector 로 만든다.
- 그리고 이 vector 를 가지고 뉴럴넷에 적용하여 학습을 진행한다.
- 만약 학습이 잘 되었다면, orange 대신 새로운 단어인 apple 이 들어가도 juice 와 같이 예측을 할 것이다.
또한 전체 문장에 대해서 target 을 유추 (analogy) 하는 것 말고, 여러 context 기반으로 target 을 유추할 수도 있다.
- 아래와 같이 context 를 다양하게 두면서 target 을 유추할 수 있다.

다음으로 Word2Vec 모델에 대해서 알아보자.
- 아래와 같이 context 와 target 을 설정할 때, window size 에 따라 결정할 수 있다.
- ex. Index of orange + 1 -> juice , orange - 2 -> glass, ...
- 따라서 context 와 target 단어를 제외한 나머지 단어는 skip 하므로 skip grams 라고 부른다.

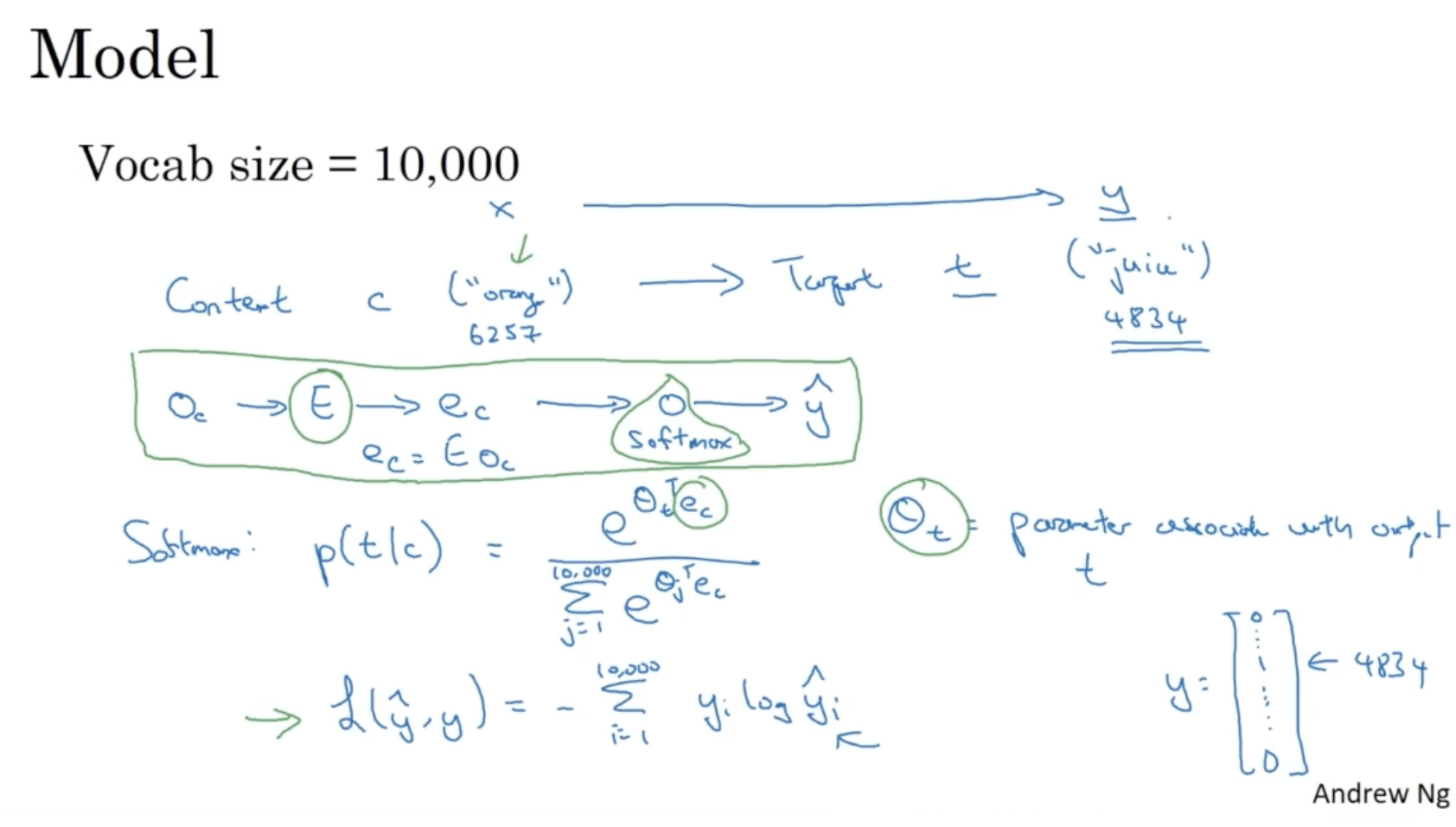
Word2Vec Model 은 다음과 같이 간략하게 설명할 수 있다.
- 예를 들어 단어 사전의 크기가 10000 이라고 가정한다.
- 모델은 context c 를 가지고 target t 를 예측한다.
- 먼저 Embedding Matrix 와 one-hot vector 를 product하여 embedding vector 를 구한다.
- 그리고 embedding vector 를 softmax layer에 적용하여 예측값 를 구한다.
- softmax 함수는 다음과 같다. ( 는 마치 와 같다.)
- 그리고 softmax의 Loss function 은 다음과 같다.
하지만 softmax classification 은 다음과 같이 연산 비용이 매우 크다는 단점이 존재한다.
- 10000개 정도의 데이터는 계산할 수 있겠지만, 만약 100만개라면 어떨까? 아마 연산이 오래 걸릴 것이다.
- 따라서 이를 보완하기 위해 Hierarchical softmax 를 적용한다. 이 경우 이진 트리로 구성될 경우 log(N) 의 속도로 계산이 가능하다. (root->left/right_node->left/right_node->...->leaf_node(class)와 같이 확률을 점차적으로 곱해가며 최종 class 에 대한 확률을 구할 수가 있다. 이전에는 한번에 모든 확률을 다 곱한 방식이었다.)
- 그리고 context 를 샘플링할 때는 보통 uniform 하게 random sampling 방식을 적용한다. 그래서 the, of, a, and, to 와 같은 단어들이 더 자주 등장한다.

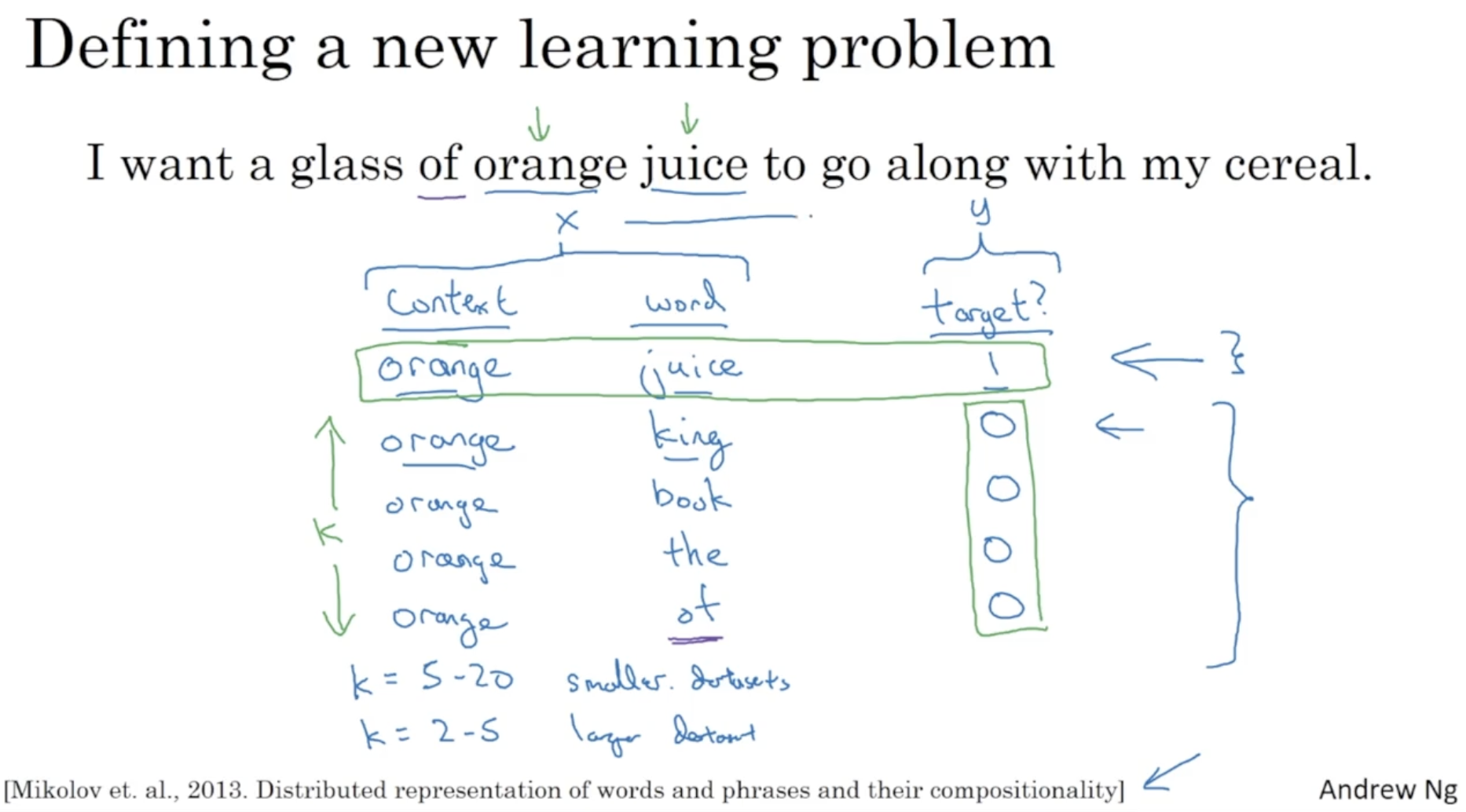
다음은 Negative sampling 에 대한 예시이다.
- 아래와 같이 content 와 (target=1) word 를 정한다.
- 그리고 사전에서 k 개 만큼의 단어를 랜덤하게 뽑아서 이를 (target=0) word 로 지정한다.
- 이렇게 하여 target = 1 인 데이터 행을 가지고 target = 0 인 여러 개의 데이터 행을 샘플링한다.
- 아래 논문에서는 k = 5 ~ 20 을 추천한다.
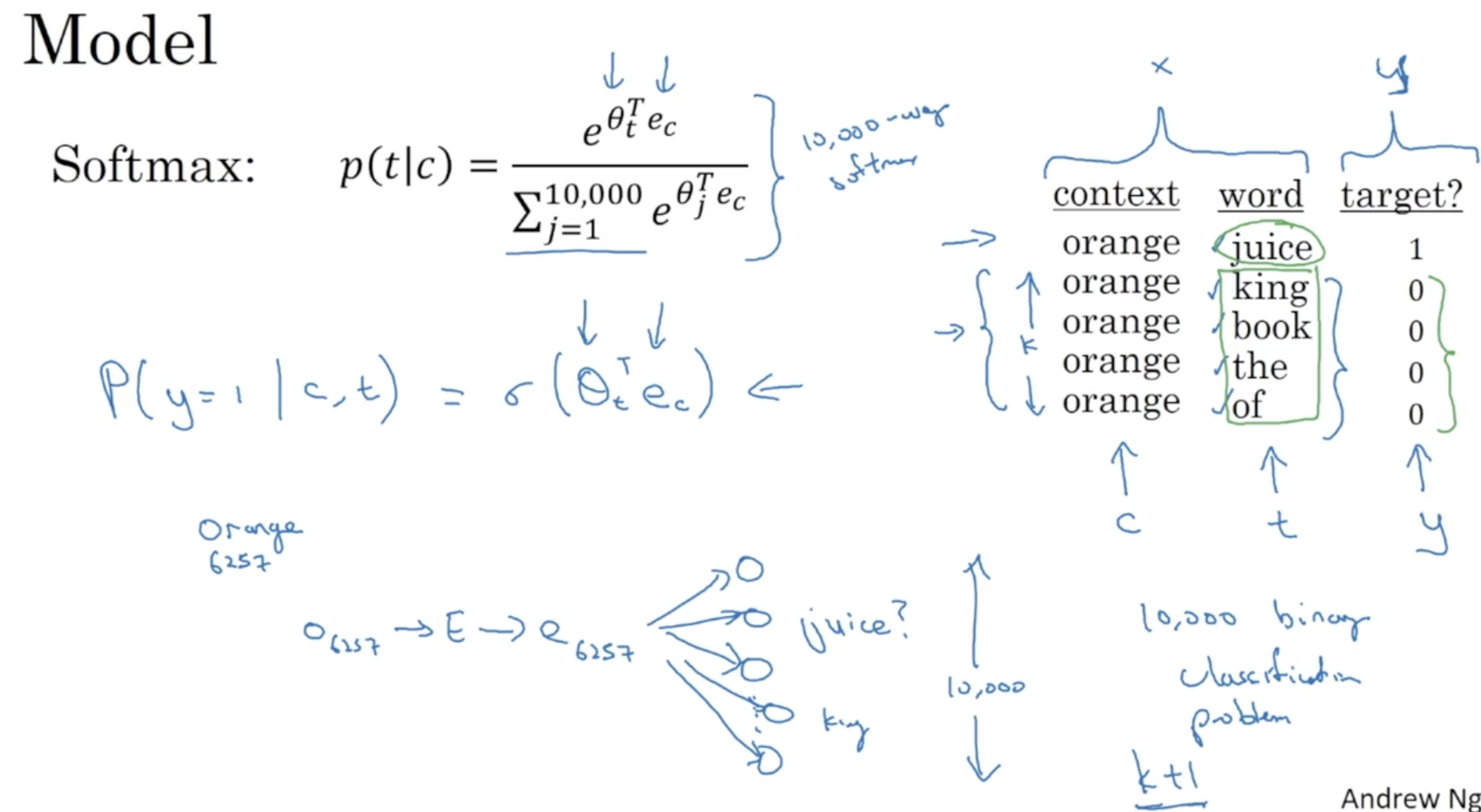
모델은 다음과 같다.
- 이전의 softmax 의 경우 때문에 연산 비용이 많이 든다는 단점이 존재했다.
- 따라서 softmax 대신 logistic regression 모델을 적용한다.
- 따라서 10000 개의 binary classfication 문제를 k + 1 개로 줄일 수 있다.
다만 단어들의 분포가 uniform 하지 않다는 단점이 존재한다. (ex. the, of, and 등의 단어는 분포가 많다.)
- 논문에서는 heuristic 한 방법으로 아래와 같이 분포 확률을 unform 하게 지정하기도 했다.

다음으로 skip grams 모델이 아닌 GloVe 모델에 대해서 알아보자.
- 이는 skip grams 보다 덜 정확할 수 있지만 단순화 측면에서 이점이 존재한다.
- : 단어 의 context 에서 단어 가 나타난 횟수. (슬라이드 오타)
- 때로 인 경우도 있다.

GloVe 모델은 다음과 같다. (강의 내용에 오류가 있을 수 있으니 논문을 참고하는 게 나을 것 같다.)
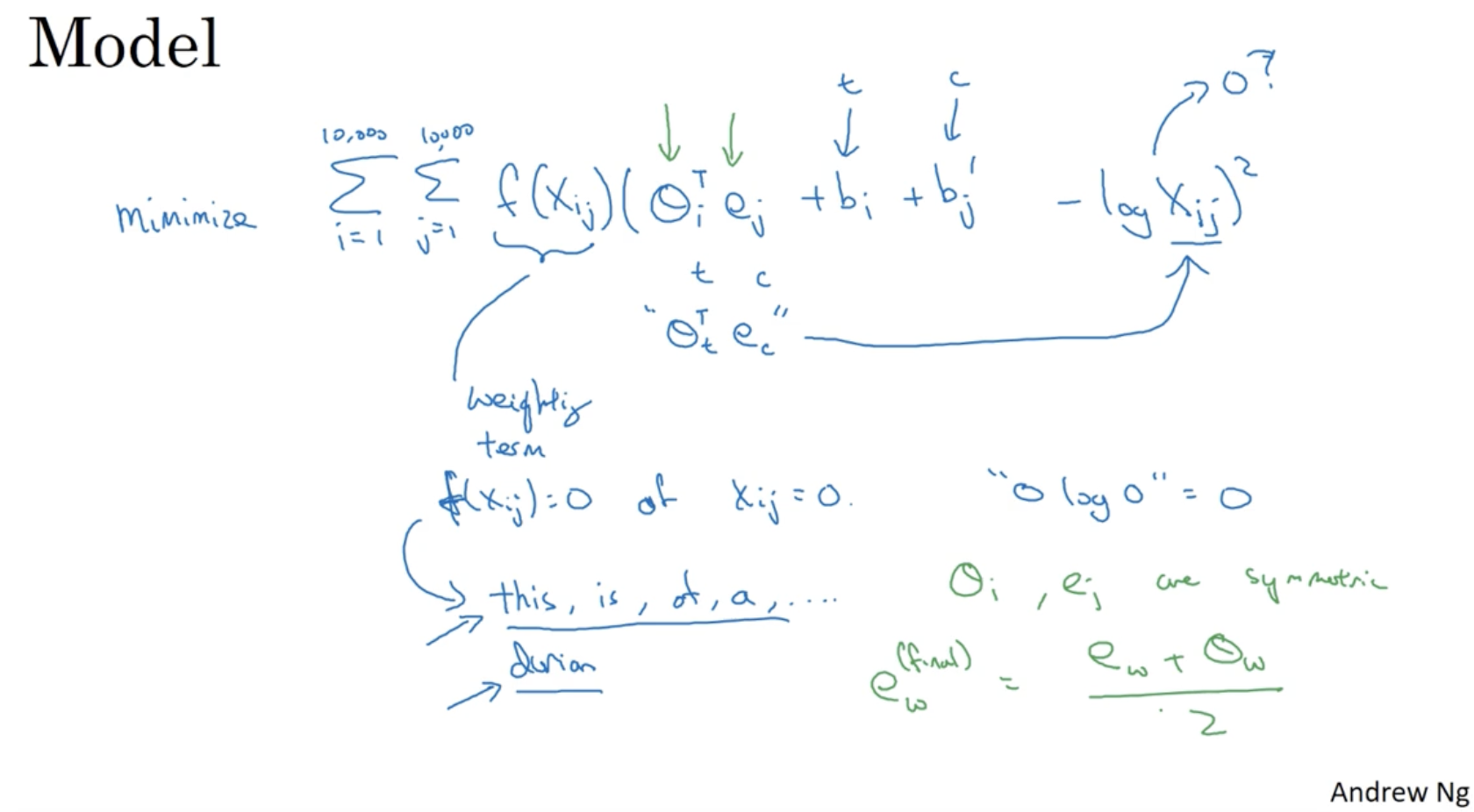
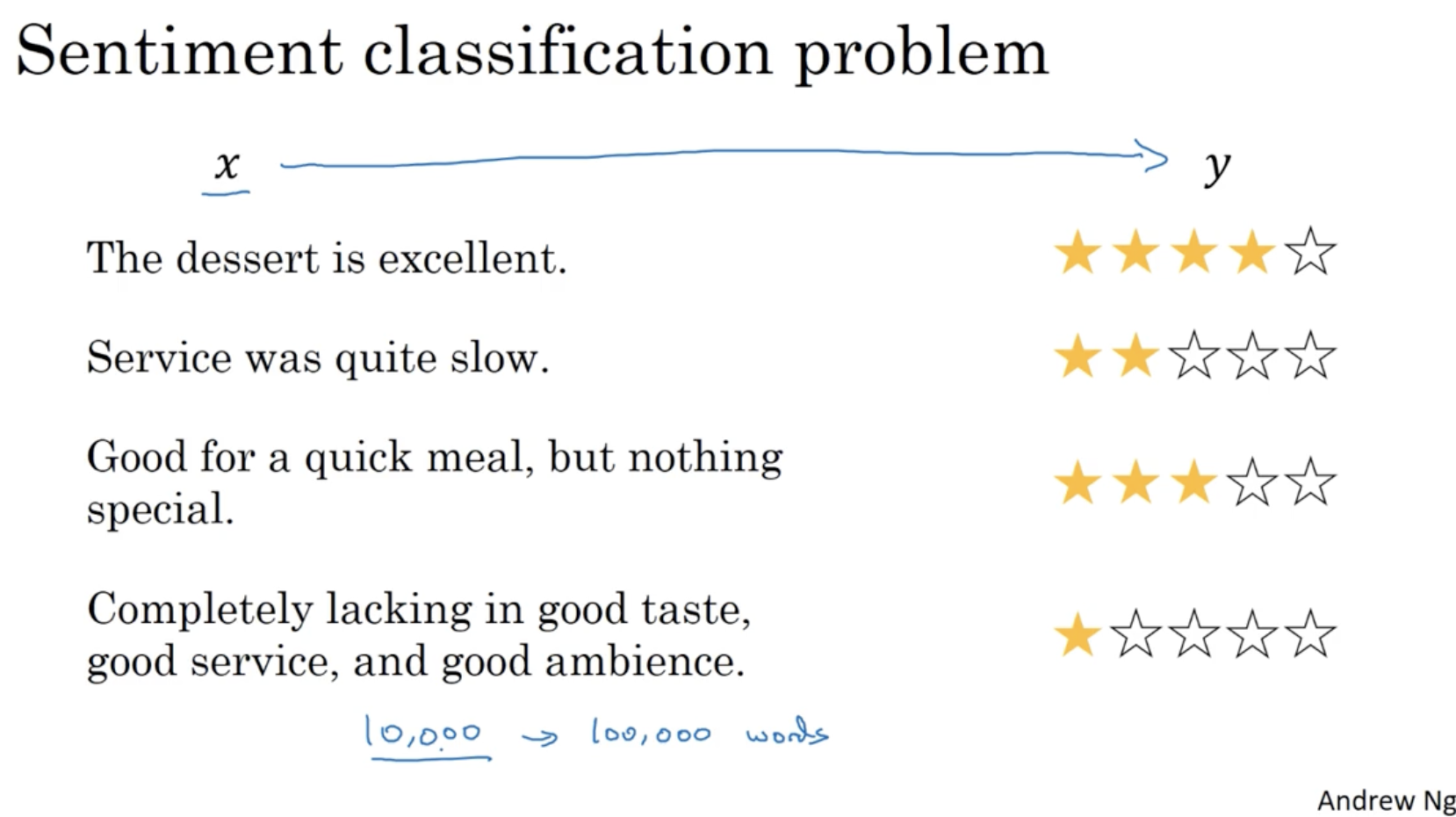
다음은 Sentiment classification 에 대한 예시이다.
- 이 경우 학습 데이터가 10000 ~ 100000 단어처럼 많지 않을 경우, word embedding 을 통해 문제를 해결할 수 있다.
아래와 같은 모델로 sentiment classification 을 적용할 수 있다.
- 하지만 이 모델의 경우 단어들의 feature 들의 avg. 로 적용되기 때문에, 아래 문장과 같이 좋지 않은 문장에 good 과 같은 단어가 많이 포함되어 있을 경우 제대로 예측을 하지 못할 것이다.
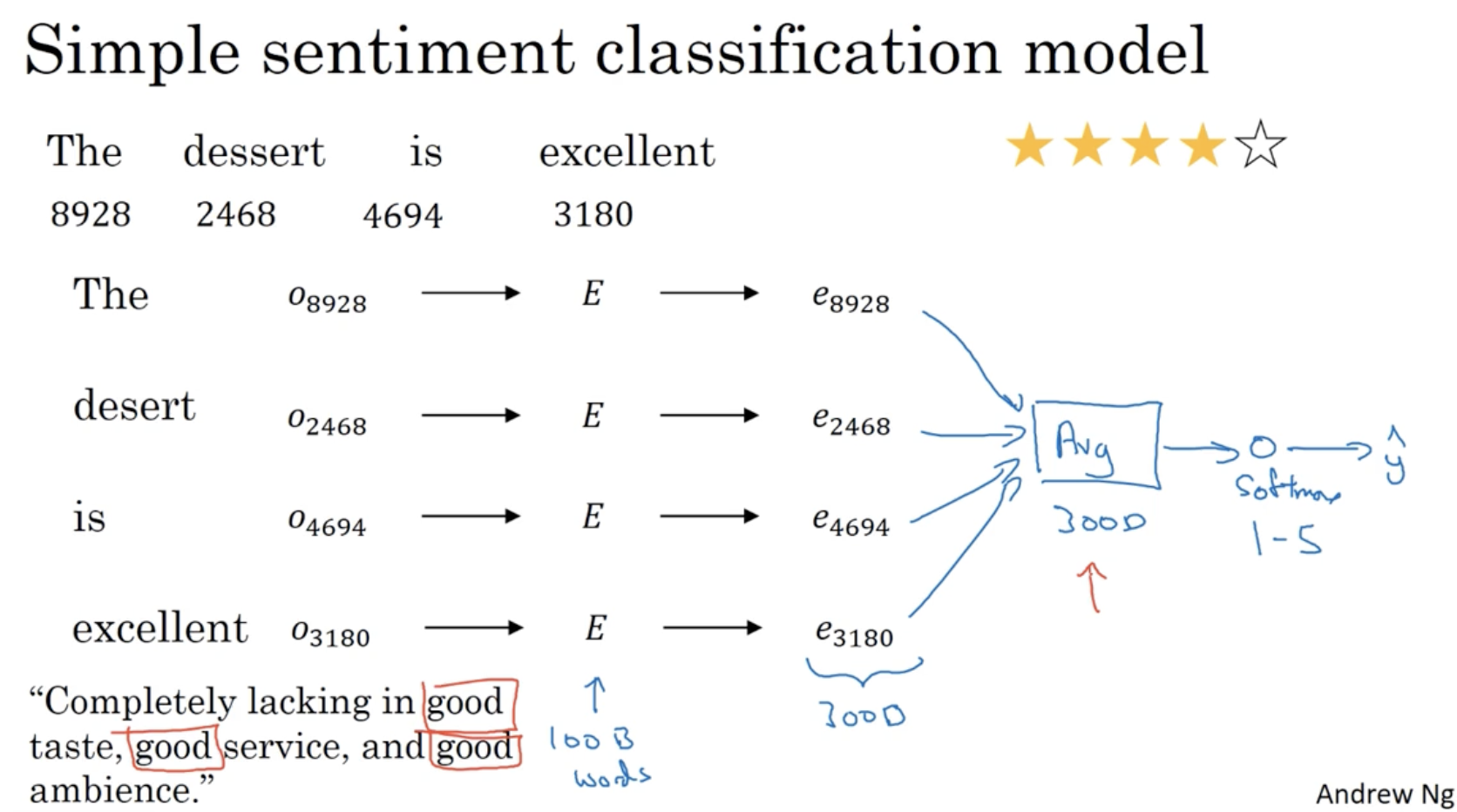
따라서 이를 보완하기 위해 RNN 을 적용할 수 있다.

word embedding 의 경우 아래와 같이 인종차별적인 혹은 성차별적인 내용이 있을 수 있다. 따라서 이를 막기 위한 debiasing word embedding 이 필요하다.

debiasing word embedding 은 아래와 같은 절차를 따른다.
- non-bias direction 을 그린다.
- bias 가 있을 수 있는 단어들을 해당 non-bias direction 으로 projection 한다.
- 해당 단어를 다른 단어들에게 동일한 거리로 부여한다. 예: (여자 - 단어 - 남자)

