https://www.youtube.com/watch?v=E882TKnkbM0&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX&index=11
머신러닝 시스템을 디자인해보자. 아래 예시는 스팸 classifier에 대한 예시이다.
- 왼쪽은 spam(class=1)에 해당하는 메일로, "w4aches", "Med1cine", "M0rgages" 등과 같이 이상한 단어들이 섞여 있다.
- 오른쪽은 non-spam(class=0)에 해당하는 메일로, 정상적인 메일이다.

supervised learning의 경우, 이메일에 대한 feature 벡터 와 정답 벡터 를 가지고 머신러닝 모델을 디자인한다.
예를 들어, features x는 100개의 단어에 대한 정보를 갖는다면, 각 단어의 feature를 나타내는 의 값은 다음과 같다.
- if word appears in email.
- otherwise.
예시로 아래 그림에서 벡터 는 처럼 나타냈는데, 이는 각 위치에 대한 단어들의 feature를 의미한다. 즉, 오른쪽 이메일에서 "buy", "deal", "now"의 단어는 표시되었으니 해당 단어의 feature는 1로, 나머지는 0으로 세팅된 것이다.
하지만, 실제 이메일에서는 단어의 종류가 10,000개부터 50,000개까지 나타난다.

그러면 어떻게 에러가 낮게 나오도록 모델을 빌딩할 수 있을까? 제안된 방법은 다음과 같다.
- data를 많이 수집하기. (honeypot 프로젝트처럼 가짜 이메일을 무수히 생성.)
- 이메일의 제목 부분에 대한 정교한 feature 개발하기.
- 이메일의 본문 부분에 대한 정교한 feature 개발하기. (예를 들어, "discount"와 "discounts"를 동일한 단어로 볼 것인지?)
- 오타를 탐지하는 정교한 알고리즘 개발하기. (예, "m0rtage", "med1cine", "w4tches")
그렇다면 위 방법들을 랜덤하게 선택해서 에러를 줄이면 될까? 어떻게 하면 시간-효율적으로 에러를 줄일 수 있을까?

추천하는 절차는 다음과 같다.
1. 간단한 모델로 빠르게 구현한다. 그리고 cross-validation set에 대해서 모델을 테스트한다.
2. learning curve를 그려보면서, high-bias와 high-variance 등을 파악하고 데이터를 추가할지, feature를 추가할지 등을 고려한다.
3. 에러를 분석한다. 에러가 높게 나오는 특정 데이터셋(cross validation set에 있는 데이터셋)을 찾아 이 데이터셋만 중점적으로 분석한다. 그래서 어떤 특징 때문에 해당 데이터셋에서 에러가 높게 나오는지 분석한다.

에러 분석에 대한 예시를 살펴보자. 예를 들어 500개의 데이터를 갖는 cross-validation dataset이 있다고 가정해보자. 해당 데이터셋에 대해서 알고리즘은 100개의 오류를 발견했다. 이는 매우 높은 오류이기에 해당 데이터셋을 집중 분석해보기로 한다.
1. 100개의 오류 데이터에 대해서 각 메일이 어떤 타입의 메일인지에 대한 분류를 먼저 한다.
분류 결과, "steal passwords" 타입이 가장 많다고 나왔다.
2. 100개의 오류 데이터에 대해서 각 feature들을 분석한다.
분석 결과, "Deliberate misspellings"를 탐지하는 feature에 대해서는 에러가 낮게 나왔지만, "Unusual (spamming) puntuation"를 탐지하는 feature에 대해서 에러가 많이 나온 것을 알 수 있다. 따라서 "Unusual (spamming) puntuation" feature를 집중적으로 다룰 필요가 있다.

그리고 "discount", "discounts", "discounted", "discounting" 등을 동일한 단어로 볼지 결정해야 한다. 이 경우 stemming 소프트웨어를 사용하면 되긴하지만, "universe"와 "unversity"를 동일한 단어로 보는 문제점 등이 있다. 따라서 에러 분석만으로는 성능을 제대로 분석하기가 힘들다.
- 따라서, cross validation error와 같은 수치적인 평가가 필요하다. 예를 들어, stemming을 적용x는 5% error, 적용은 3% error가 나왔다고 하면, stemming 적용이 더 좋다는 것을 알 수 있다.
- 또한, stemming에 대문자/소문자를 구분하는 걸 추가했는데 3.2% 에러가 나왔고, 이를 통해 대/소문자는 구별하지 않는 게 더 낫다고 결론을 내릴 수 있다.

암 환자를 구분하는 classifer 예시를 살펴보자. 학습시킨 logistic regression model이 있다.
그리고 test set에 대해서 테스트를 한 결과 1%의 error를 보여준다.
그렇다면 과연 이 모델은 잘 학습된 모델이라고 할 수 있을까?
그렇지 않다. 이유는 아래와 같다.
- 만약 전체 데이터셋에서 암 환자가 0.50%밖에 없었다고 해보자. (실제 데이터에서도 암환자의 빈도는 낮을 수밖에 없다.)
- 그리고 단순하게 모든 에 대해서 으로 결과를 내는 함수가 있다고 해보자.
그러면 이 함수의 정확도는 99.5%일 것이다. 즉, 에러가 0.50%로 나올 것이다.- 우리가 학습시켰던 모델의 에러는 1%인데, 위처럼 단순한 함수가 0.50%의 에러를 보여준다.
- 따라서 기존의 test set의 test로는 모델의 정확도를 판단하기가 힘들다.
- 이처럼 data skew(데이터 비대칭) 문제가 있을 경우, 어떻게 모델의 정확도를 판단할 수 있을까?

이를 위해 필요한 개념이 "Precision"과 "Recall"이다.
- "Precision"은 "Positive"라고 예측한 것 중에 실제 "Positive"인 것들의 비율을 의미한다.
(예: 암 환자라고 예측한 사람 중에 실제 암 환자가 있는 비율)- "Recall"은 실제 "Positive" 중에 "Positive"라고 예측한 비율을 의미한다.
(예: 실제 암 환자 중 암 환자라고 예측한 비율)
실제값/예측값에 대해서 테이블로 표시하면 좌측 그림과 같이 나온다.- True Positive : 실제 Positivce인데 Positive라고 예측한 경우
- True Negative : 실제 Negative인데 Negative라고 예측한 경우
- False Positive : 실제 Negative인데 Positive라고 잘못 예측한 경우
- False Negative : 실제 Positive인데 Negative라고 잘못 예측한 경우
- 그리고 Precision과 Recall 값은 다음과 같이 나온다.
- 따라서 아까처럼 단순히 을 갖는 함수에 대해서 Recall 값은 0이 나올 것이고, 이 예측은 잘못됐다고 판단할 수가 있을 것이다.

그렇다면 어떻게 최적의 precision과 recall 값을 갖도록 할 수 있을까?
- 예를 들어, 예측 함수 에서 threshold의 값을 높여보자. 이 경우 모델은 에 가까워질 것이고, 이렇게 되면 precision은 높아지겠지만 recall은 낮아진다.
- 그렇다면 반대로 threshold를 낮춰보자. 이 경우 모델은 에 가까워질 것이고, 이렇게 되면 recall은 높아지겠지만 precision은 낮아진다.
- 우측 그래프가 이를 잘 표현한다.
- 따라서 precision과 recall 간의 trade-off를 잘 고려하는 최적의 threshold 값을 찾아야 한다.

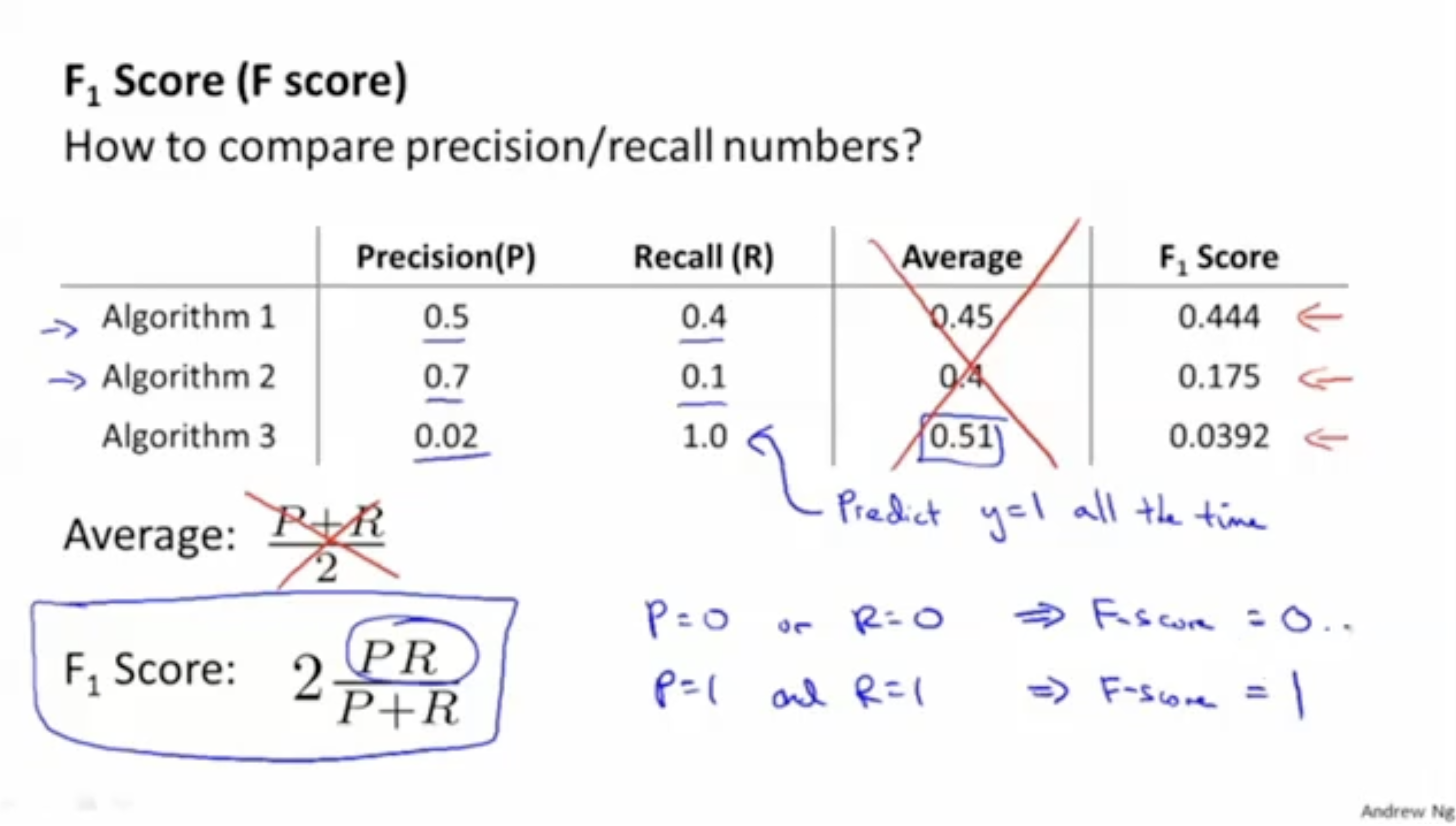
그렇다면 precision과 recall 모두 잘 표현하는 수식은 어떤 게 있을까?
- 먼저 평균으로 따져보자. .
이 경우, 평균값이 높은 게 좋은 모델이라고 볼 수 있을까? 그렇지 않다.
예를 들어, 과 같은 함수에 대해서 recall은 1, precision 0에 가까운 값이 나온다.
그리고 평균값이 약 0.5로 나오면서 다른 모델과 비교했을 때 평균값이 더 높다.
하지만, 과 같은 모델은 절대 좋은 모델이 아니다.- 따라서 precision과 recall 값이 한쪽으로 치우쳐지지 않도록하는 수식이 필요하다.
- 이를 잘 표현하는 수식이 F1-score(F-score)이다.
- (만약 한 값이 0으로 간다면 스코어 값도 0으로 간다.)
- 따라서 이상적인 f1 score 값은 1이 나올 것이다. (, 두 값 모두 높게 나오도록 세팅.)
따라서 모델을 디자인하고 학습할 때, 다음과 같이 high-bias와 high-variance 문제를 해결하면 좋다.
- 모델에 많은 parameter를 적용함으로써 bias를 줄인다.
- 모델에 많은 학습 데이터셋을 적용하여 학습함으로써 variance를 줄인다.

