https://www.youtube.com/watch?v=doN5SexZjto&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX&index=12
SVM(Support-Vector-Machine)은 logistic regression 및 neural networks 보다 괜찮은 성능을 보여주는 supervised learning algorithm 중 하나이다.
먼저 logistic regression에 대해서 상기해보자.
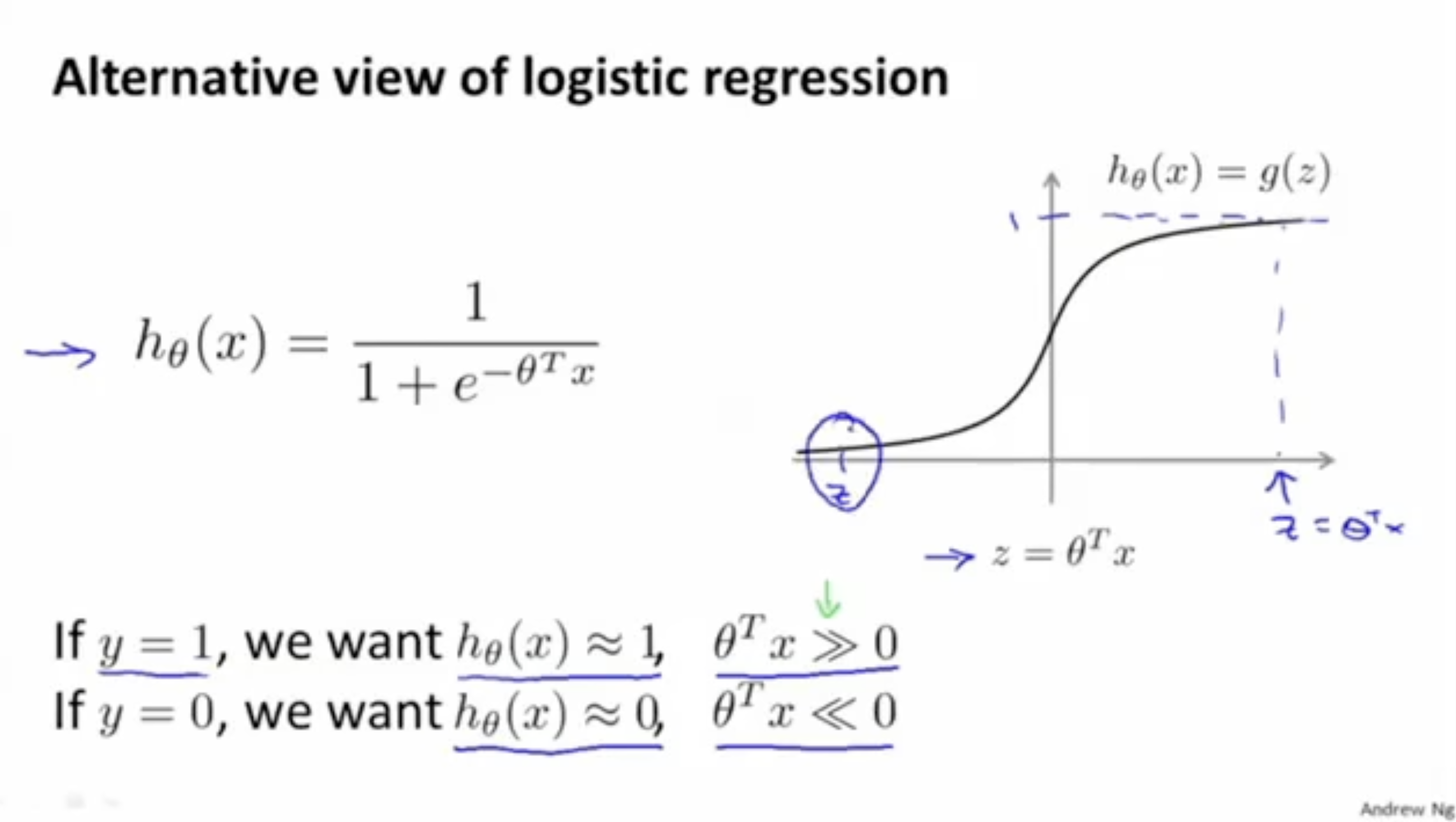
logistice regression은 activation func.인 sigmoid func.으로 예측 함수를 정의하여,
0≤hθ(x)≤1 값을 갖도록 만든다.
- 따라서 만약 y=1이라면, hθ(x)도 1에 가까워져야 하며, 이를 위해 θTx의 값은 0보다 매우 커져야 한다.
- 만약 y=0이라면, hθ(x)도 0에 가까워져야 하며, 이를 위해 θTx의 값은 0보다 매우 작아져야 한다.
그리고 logistic regression의 cost func.의 cost 식은 아래와 같다.
−(y log hθ(x)+(1−y) log(1−hθ(x)))
더 정확히 표현하면, hθ(x)=1+e−θTx1이므로 다음과 같다.
−y log 1+e−θTx1−(1−y) log(1−1+e−θTx1)
그리고 cost function의 그래프를 y=1일 때의 그래프와 y=0일 때의 그래프로 나눠서 보면 아래와 같다.
- 그런 다음 logistic regression의 cost fuction 그래프를 최대한 근사하는 직선으로 표현하면 그림의 핑크색 선과 같다. 그리고 이를 costj(z)라고 하자. (j는 클래스 종류를 의미한다.)
- cost0(z) : y=0일 때의 cost 함수.
- cost1(z) : y=1일 때의 cost 함수.

그러면 위에서 구한 costj(z)를 가지고 logistic regression을 SVM으로 정리해보자.
- 우선 logistic regression 식은 다음과 같다.
- θminm1∑i=1m[y(i)(−log hθ(x(i)))+(1−y(i))(−log(1−hθ(x(i))))]+2mλ∑j=1nθj2
- 그리고 위에서 아까 구했던 costj(z)으로 (z=θTx) 근사하면 SVM의 regression 식은 다음과 같다.
- θminm1∑i=1m[y(i)cost1(θTx)+(1−y(i))cost2(θTx)]+2mλ∑j=1nθj2
- 위 SVM 식에서 사실 m1은 최솟값 θ를 찾는 데 영향을 주지 않는다. 따라서 생략이 가능하다.
(예: umin 10(u−5)2+10의 최솟값을 나타내는 u는 5이다. 앞에 10이 없어도 마찬가지다.)
- 그리고 regularization parameter λ값을 나눠서 regularization 부분의 계수는 21로 만들고, costj(θTx) 부분의 계수는 C로 만든다. (C≈λ1)
- 이렇게 되면 최종 SVM의 regression 수식은 아래와 같이 나온다.
θminC∑i=1m[y(i)cost1(θTx)+(1−y(i))cost2(θTx)]+21∑j=1nθj2

이처럼 SVM의 regression 수식 (Cost function)을 구할 수 있으며, 예측은 다음과 같다.
- θTx≥0면 1로 예측.
- θTx<0면 0으로 예측.
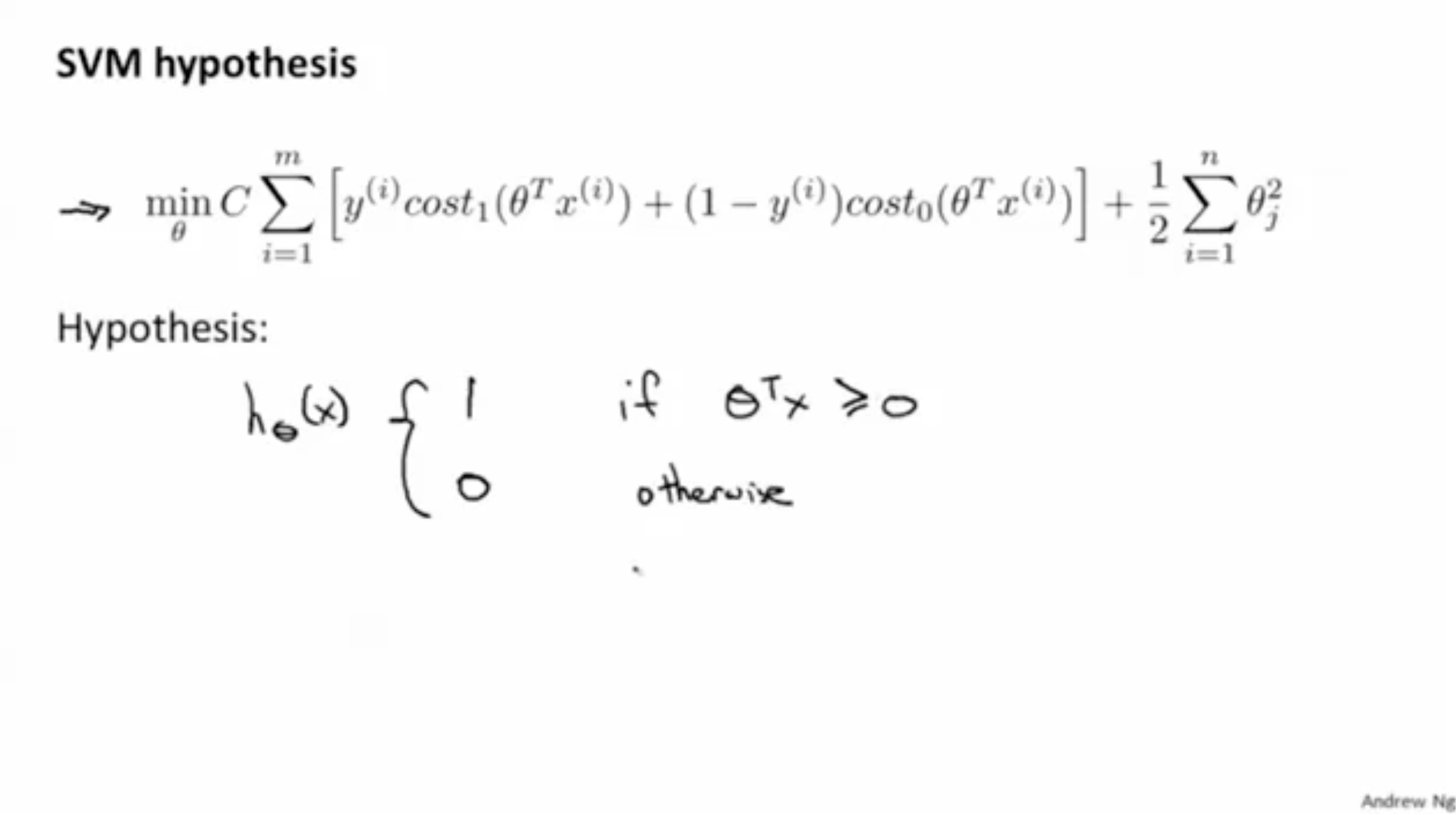
SVM의 cost function을 가지고 분석을 해보자.
- 만약 y=1일 경우, 좌측 그래프 cost1(z)에서 z≥1이어야 cost 값이 0으로 나올 것이다.
- 반대로 y=0일 경우, 우측 그래프 cost0(z)에서 z≤−1이어야(1이 아니라 -1이 맞음. 오타.) cost 값이 0으로 나올 것이다.
- 그리고 z=θTx이므로, 위 두 경우를 다음과 같이 정리할 수 있다.
- y=1이면 θTx≥1이어야 함.
- y=0이면 θTx≤−1이어야 함.
- 그리고 이때 C의 값을 고려해야 한다. 예시로 C=100,000와 같은 매우 큰 값을 넣으면 어떻게 될까?

그렇다면 SVM의 decision boundary는 어떻게 결정될까?
- C의 값이 매우 크기 때문에 cost function을 최소화하려면 C×0과 같이 만들어야 한다.
- y=1일 때, cost1(θTx)는 0으로 가야하므로 θTx≥1이 된다.
- y=0일 때, cost0(θTx)는 0으로 가야하므로 θTx≤−1이 된다.
따라서 C가 매우 클 때, SVM의 cost function은 θmin C×0+21∑j=1nθj2이 되어,
θmin21∑j=1nθj2과 같이 나올 것이다.

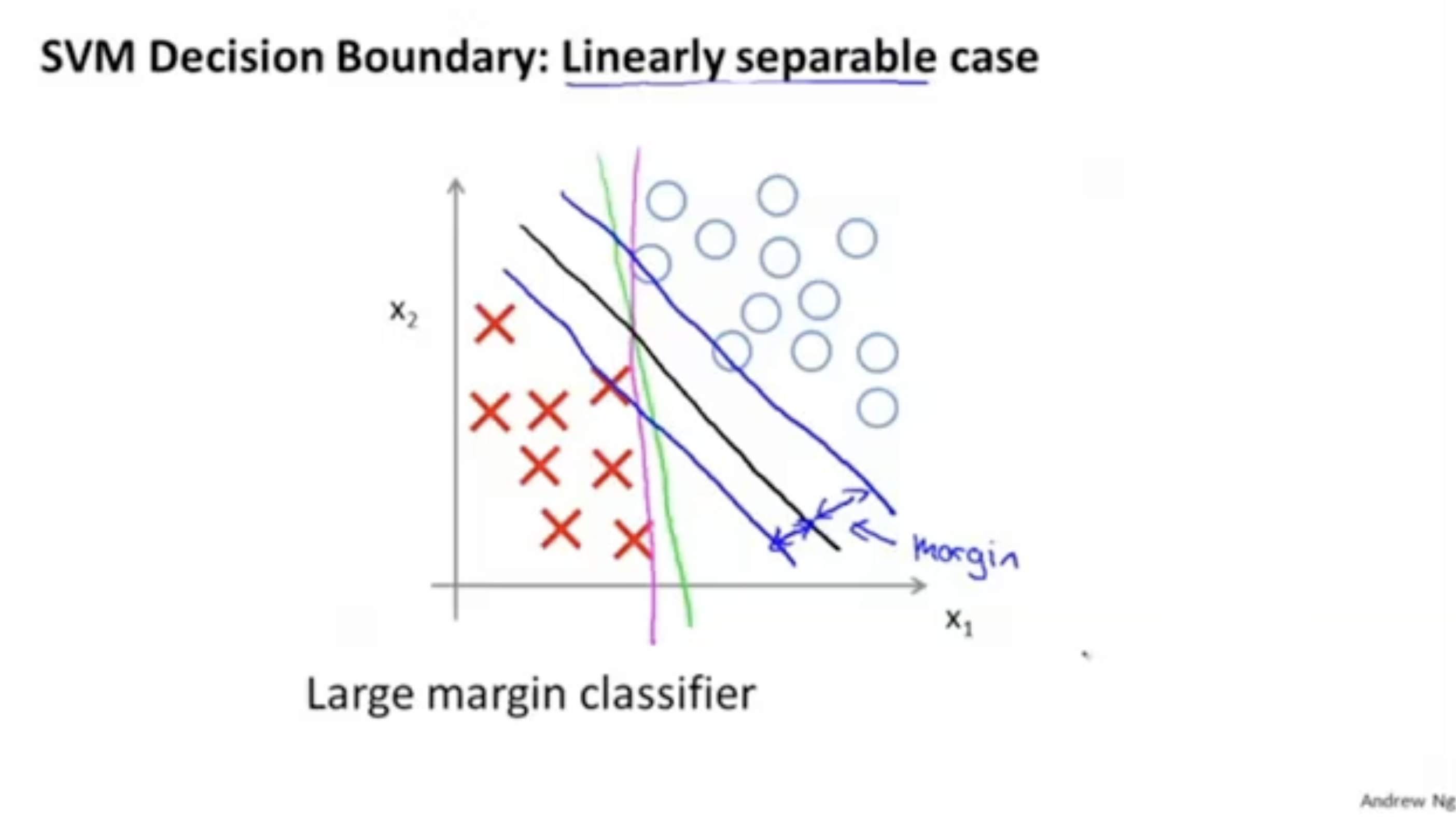
SVM을 적용하다보면 아래 그림과 같이 핑크색, 연두색, 검은색 등 여러 개의 descision boudary들이 나올 것이다. 그리고 이 중에서 검은색 라인이 가장 큰 margin을 갖는다. (margin은 데이터와 decision boundary 간의 공간을 의미한다.)
- 그리고 검은색 라인과 같이 margin이 가장 크게 나오는 decision boundary를 찾는 게 SVM의 목적이다.
- 따라서 이러한 SVM을 "Large margin classifier"라고 부르기도 한다.
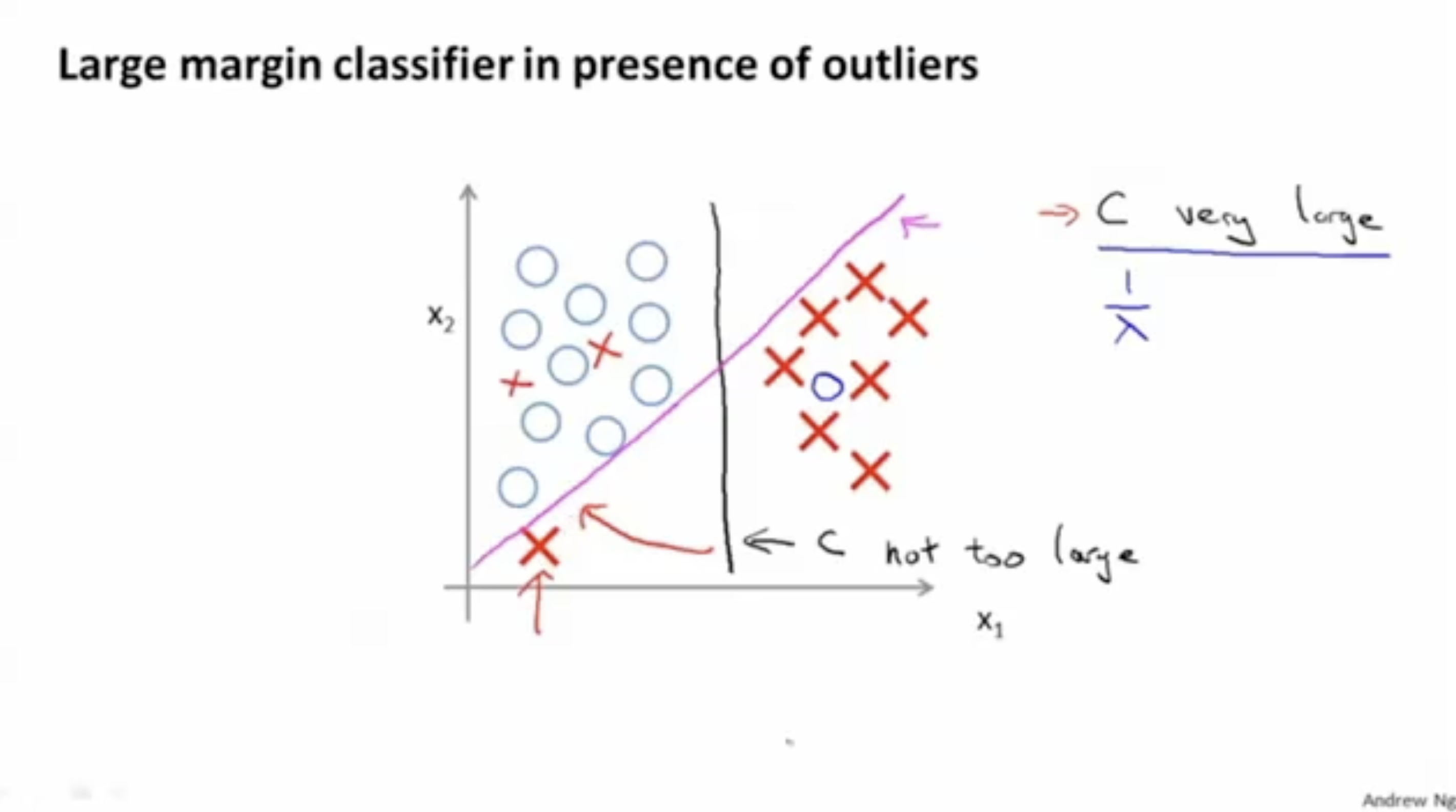
만약 Large margin classifier에서 outlier (이상치) 데이터가 있다면 어떻게 될까?
- Small margin classifier에서 처음에는 검은색 선처럼 decision boundary를 만들지만, 만약 그래프의 좌측 아래 X 데이터가 추가된다면 decision boundary는 검은색에서 핑크색 선처럼 변환될 것이다. 하지만, 이렇게 될 경우 overfitting의 문제점이 있다는 것을 알 수 있다.
- 우리는 SVM의 cost function에서 C의 값을 매우 크게 주었다. 그리고 C=λ1이므로,
이는 매우 작은 λ를 의미하기도 한다.
- 따라서 만약 C값이 크지 않았다면 검은색 decision boundary는 outlier data가 추가되도 변화가 거의 없을 것이다.
- 이처럼 SVM에서 overfitting 문제를 방지하기 위해 C값을 잘 선택해야 한다.
- 너무 큰 C 값 : Small margin (overfitting)
- 너무 작은 C 값 : Large margin (underfitting)
SVM에서 비선형 decision boundary의 경우, 예측 함수의 복잡도가 매우 높아진다는 단점이 존재한다.
아래와 같은 decision boundary가 있다고 가정해보자.
decision boundary=θ0+θ1x1+θ2x2+θ3x1x2+θ4x12+θ5x22+...
이 경우, 해당 함수값이 0보다 크거나 같을 경우 y=1로 예측하고, 0보다 작으면 y=0으로 예측한다.
위에서 θ 뒤에 나오는 다항식들을 간편하게 f라고 해보자. decision boundary는 다음과 같이 나온다.
decision boundary=θ0+θ1f1+θ2f2+θ3f3+θ4f4+θ5f5+...

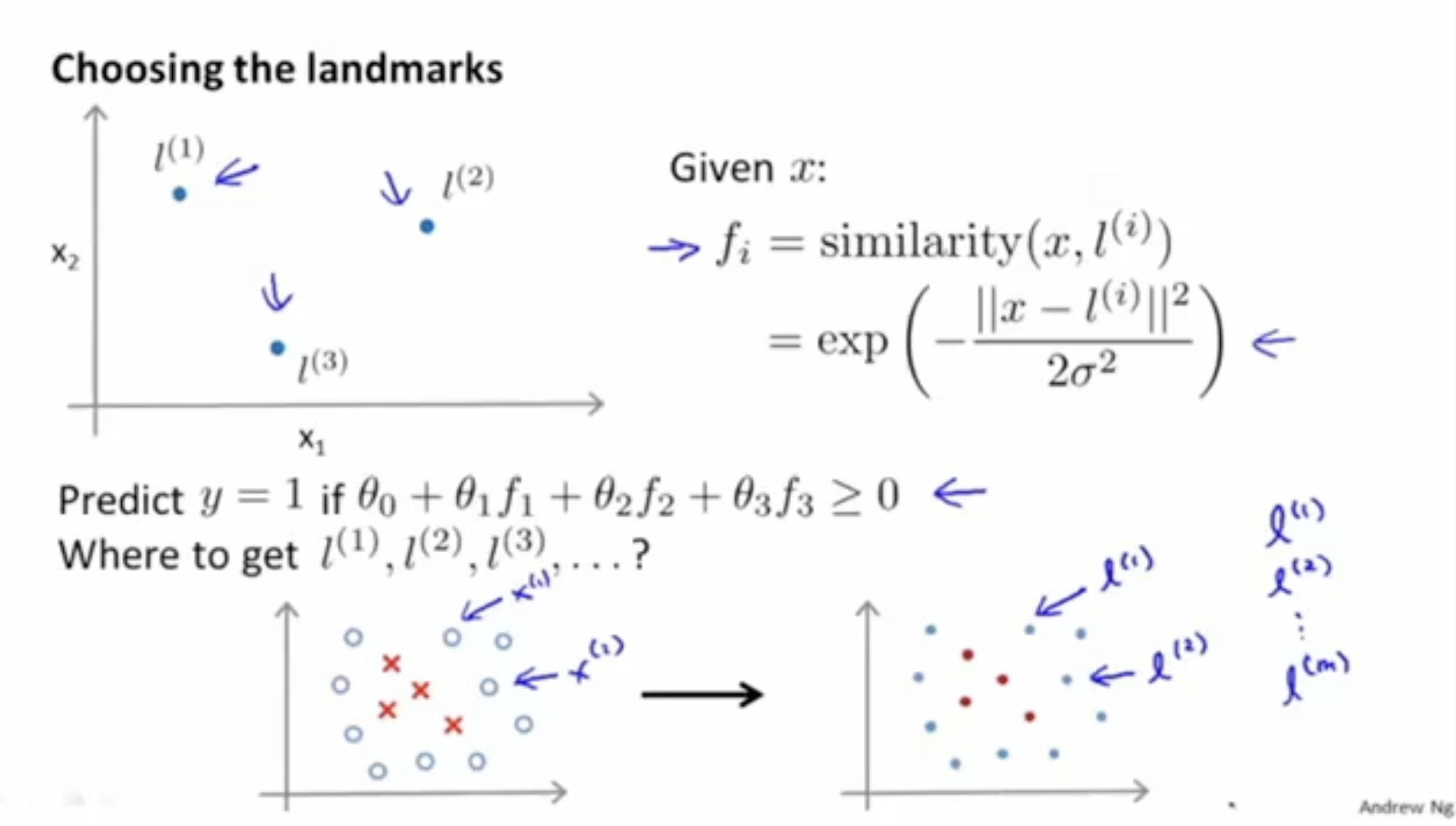
그리고 입력 features x에 대한 랜드마크 l(i)를 설정해보자 (이는 features x가 들어왔을 때 해당 값을 나타내는 landmark를 설정하는 것이다.). 그러고 나서 위에서 다뤘던 fi를 아래와 같이 정의해보자.
- f1=similarity(x,l(1))=exp(−2σ2∣∣x−l(1)∣∣2) : 이는 입력값 x에 대한 feature f1과 랜드마크 l(1)간의 유사도를 나타낸다.
exp는 ex를 의미하고, σ는 kernel parameter를 의미한다.
∣∣x−l(1)∣∣2은 입력 features x와 landmark l(1) 간의 거리(유클리드 거리)를 의미한다.
- f2=similarity(x,l(2))=exp(−2σ2∣∣x−l(2)∣∣2) : 이는 입력값 x에 대한 feature f2와 랜드마크 l(2)간의 유사도를 나타낸다.
- f3=similarity(x,l(3))=exp(−2σ2∣∣x−l(3)∣∣2) : 이는 입력값 x에 대한 feature f3과 랜드마크 l(3)간의 유사도를 나타낸다.
- 이처럼 similarity(x,l(i))를 "(gaussian) kernel function"(커널 함수)이라고 한다.
- 위 f의 값을 통해서 어떤 feature를 선택하는 게 좋을지 확인할 수 있다.

f1를 예시로 더 살펴보자.
위 수식에서 있었던 exp(−2σ2∣∣x−l(1)∣∣2)은 exp(−2σ2∑j=1n(xj−lj(1))2)과 같이 바뀐다.
- 만약 x≈l(1)이라면, f1≈exp(−0)≈1과 같이 결과가 나올 것이다.
- 반면에 x가 l(1)에서 멀리 떨어졌다면 (유사도가 매우 낮다면),
f1≈exp(−Big Number)≈0과 같이 결과가 나올 것이다.

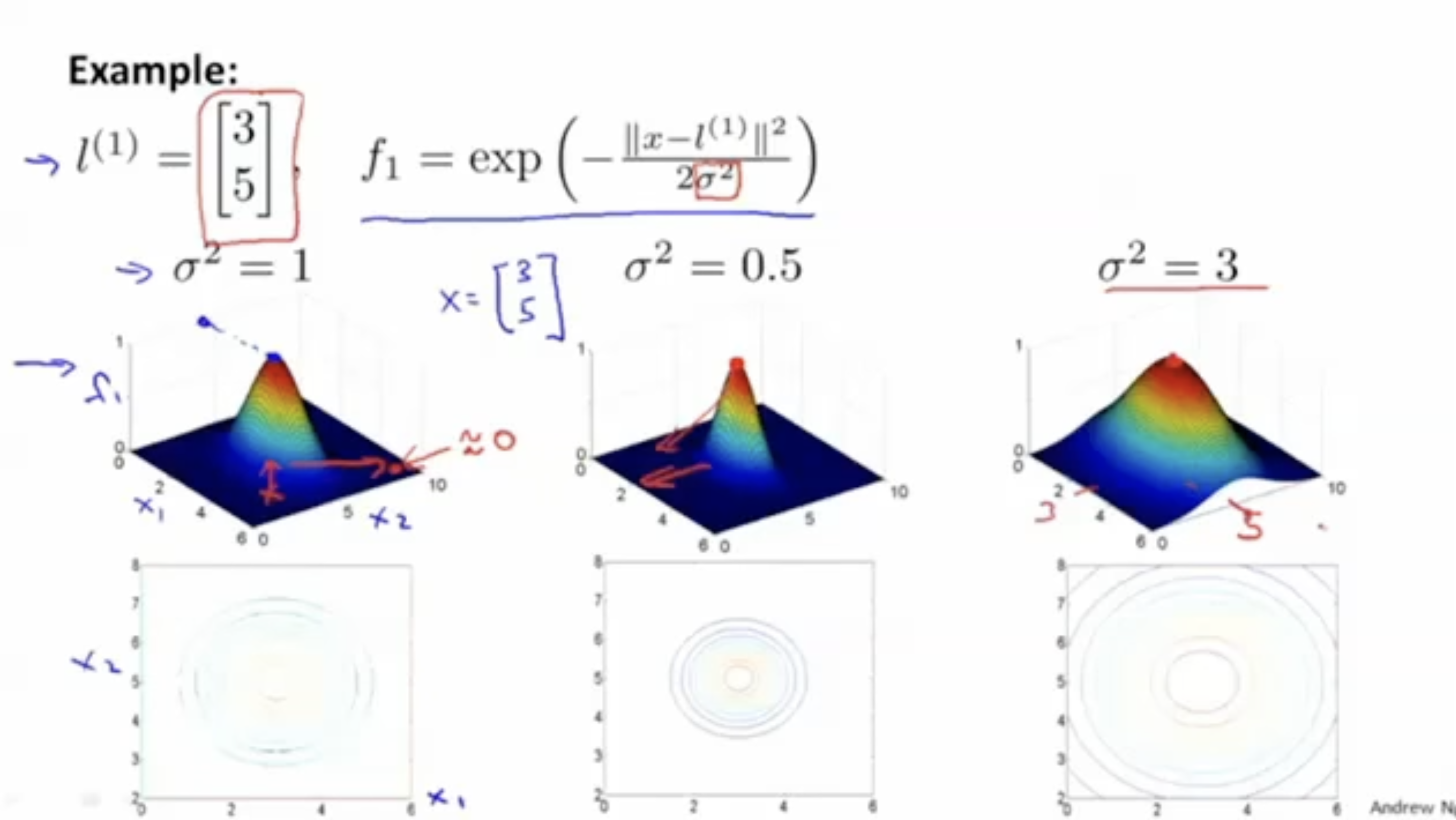
그래프를 예시로 그리면 아래와 같다.
- x≈[35]=l(1)이면, f1≈1인 것을 볼 수가 있다.
- 이때 kernel parameter σ의 값에 따라서 그래프의 모양이 달라지는 것을 확인할 수 있다.
σ가 작을수록 가파른 모양을 보이고, σ가 클수록 완만한 모양을 보인다.
이제 여러 개의 데이터 x=[x1x2]를 적용해보자. landmark인 l(i)와의 유사도에 따라 fi를 선택한다.
- 먼저 parameter θ의 값은 ⎣⎢⎢⎢⎡−0.5110⎦⎥⎥⎥⎤이라고 가정하자.
- 다음으로 핑크색 점과 같은 x가 들어왔다고 해보자. 이 경우 x는 l(1)과 가장 가깝고(f1≈1), 나머지 landmark와는 멀다(f2,f3≈0). 따라서 decision boundary는 다음과 같이 나올 것이다. θ0+θ11+θ20+θ30=θ0+θ1=0.5 이는 0보다 크거나 같으므로 y=1로 예측할 것이다.
- 그리고 하늘색 점 x를 생각해보자. 이 경우 x는 모든 landmark와 멀다(f1,f2,f3≈0). 따라서, decision boundary는 다음과 같이 나올 것이다. θ0=−0.5 이 값은 0보다 작으므로 y=0으로 예측한다.
- 정리하면 parameter θ를 봤을 때, f1,f2의 값이 1에 가까워야 (x가 l(1),l(2)에 가까워야) y=1로 예측하고, 이 외에는 y=0으로 예측한다. 따라서 아래 빨간색 경계선처럼 decision boundary가 나올 것이다.
경계 내부는 y=1로 외부는 y=0으로 예측한다.

그렇다면 landmark는 어떻게 세팅하고, kernel function은 어떤 걸 선택해야 할까?
landmark를 선택하는 것부터 알아보자. 위 예시에서는 landmark를 임의로 선택했다.
컴퓨터로 이를 적용하려면 어떤 방식으로 landmark를 선택하면 될까?
- 총 m개의 입력 데이터(x(1),x(2),...,x(m))에 대해서, 각 x(i)를 landmark l(i)로 선택하자. 이는 충분히 타당하다고 볼 수 있다.
따라서 새롭게 정의하는 feature f는 x에 대해서 m개의 fi를 갖는다.
- 이를 벡터로 표현하면 다음과 같다. f=similarity(x,l)=⎣⎢⎢⎢⎢⎢⎡f0f1..fm⎦⎥⎥⎥⎥⎥⎤(f0=1)
- 그리고 각 학습 데이터셋 (x(i),y(i))에 대해서 f(i)의 값들은 아래와 같이 나온다. m+1개의 각 landmark들과의 유사도를 나타낸다.
f(i)=similarity(x(i),l(i))=⎣⎢⎢⎢⎢⎢⎢⎡f0(i)f1(i)..fm(i)⎦⎥⎥⎥⎥⎥⎥⎤(f0=1)
- 그리고 입력 데이터 x(i)의 landmark l(i)와의 유사도는 1이 되어 fi(i)=1로 나올 것이다.
- 입력 데이터 x(i)는 Rn+1 or Rn 차원을 갖는다. (x0,x1,...,xn, n+1개의 features(columns).)
- 따라서 새롭게 정의한 feature 벡터 f도 Rm+1 차원을 갖는다. (f0,f1,...,fm)

따라서 f(kernel)를 통해 SVM을 다음과 같이 표현할 수 있다.
"y=1 if θTf≥0"
그리고 이를 학습하는 것도 이전의 SVM cost function과 유사하다. x 대신 f로 바꿔준다.
- SVM : costj(θTx(i))
- SVM with kernel : costj(θTf(i))
- 그리고 parameter regularization 항에서 ∑n인데 이를 ∑m으로 바꿔준다. 왜냐하면 기존 feature들의 칼럼 차원이 n이었다면, 현재 새롭게 정의한 feature f의 차원은 m이기 때문이다.
- 그리고 별개의 내용으로, ∑jθj2은 θTθ로 선형대수를 이용해 한번에 계산할 수가 있으며, 이 경우, 학습 데이터셋이 많아질 수록 연산 비용이 많이 든다는 문제점이 있다.
따라서 이를 θTMθ와 같이 연산하도록 하여 연산 비용을 줄이는 방법이 존재한다. (θTM이 scala 값으로 나와서 cθ와 같이 연산을 할 수 있음.)

SVM의 파라미터를 정리하면 다음과 같다.
- C(=λ1) (regularization parameter in cost func.) :
- C 값이 크면, parameter regularization이 줄어들고, 이로 인해 bias는 낮아지지만, variance가 높아지는 문제가 있음.
- C 값이 작으면, parameter regularization이 커지고, 이로 인해 variance는 낮아지지만, bias가 높아지는 문제가 있음.
- σ2(kernel parameter) :
- σ2 값이 크면, feature fi의 값은 매우 완만한 경사를 보여주며 (웬만하면 다 landmark에 가깝다고 판단), 이로 인해 variance는 낮아지지만, bias가 높아진다는 문제점이 있음.
- σ2 값이 작으면, feature fi의 값은 매우 가파른 경사를 보여주며 (landmark에 진짜 가까운 것들만 선택), 이로 인해 bias는 낮아지지만, variance가 높아진다는 문제점이 있음.

이제 logistic gression과 SVM을 언제 사용해야 하는지 비교해보자.
n : feature들의 개수(차원), m : 학습 데이터셋의 개수(차원)
- n>m : logistic regression 및 SVM without a kernel 사용.
- n<m : SVM with Gaussian kernel 사용.
- n<<m : feature 차원을 더 늘린 후, logistic regression 및 SVM without a kernel 사용.
- 반면에 Neurl Networks는 n,m과 상관없이 좋은 성능을 보여주지만, 학습 시간이 오래 걸린다는 단점이 있다.

