https://www.youtube.com/watch?v=SZktZdzTHxM&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX&index=13
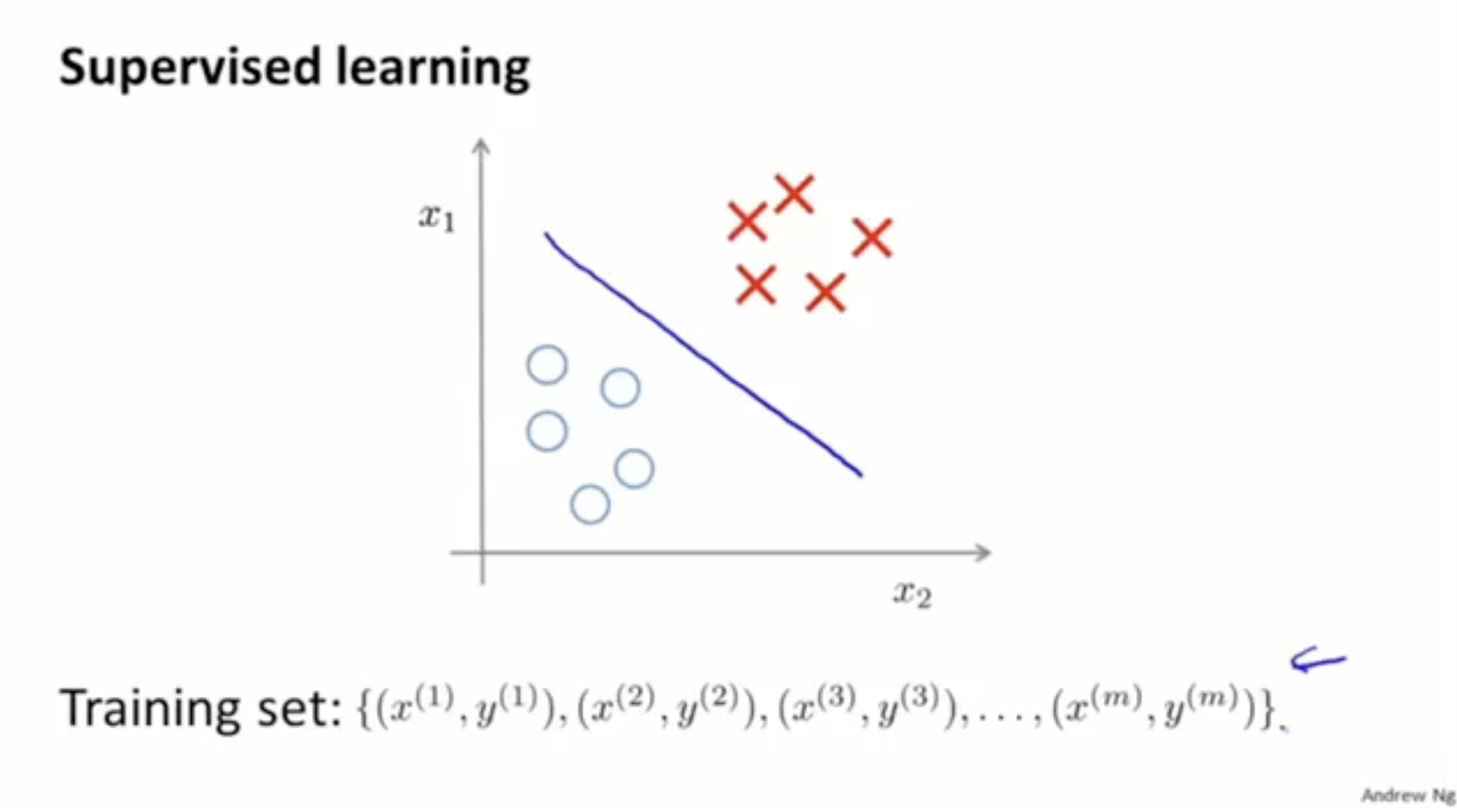
우선 supervised learning의 경우 아래와 같이 입력 데이터 에 대해서 레이블 가 주어진다.
training set : {}
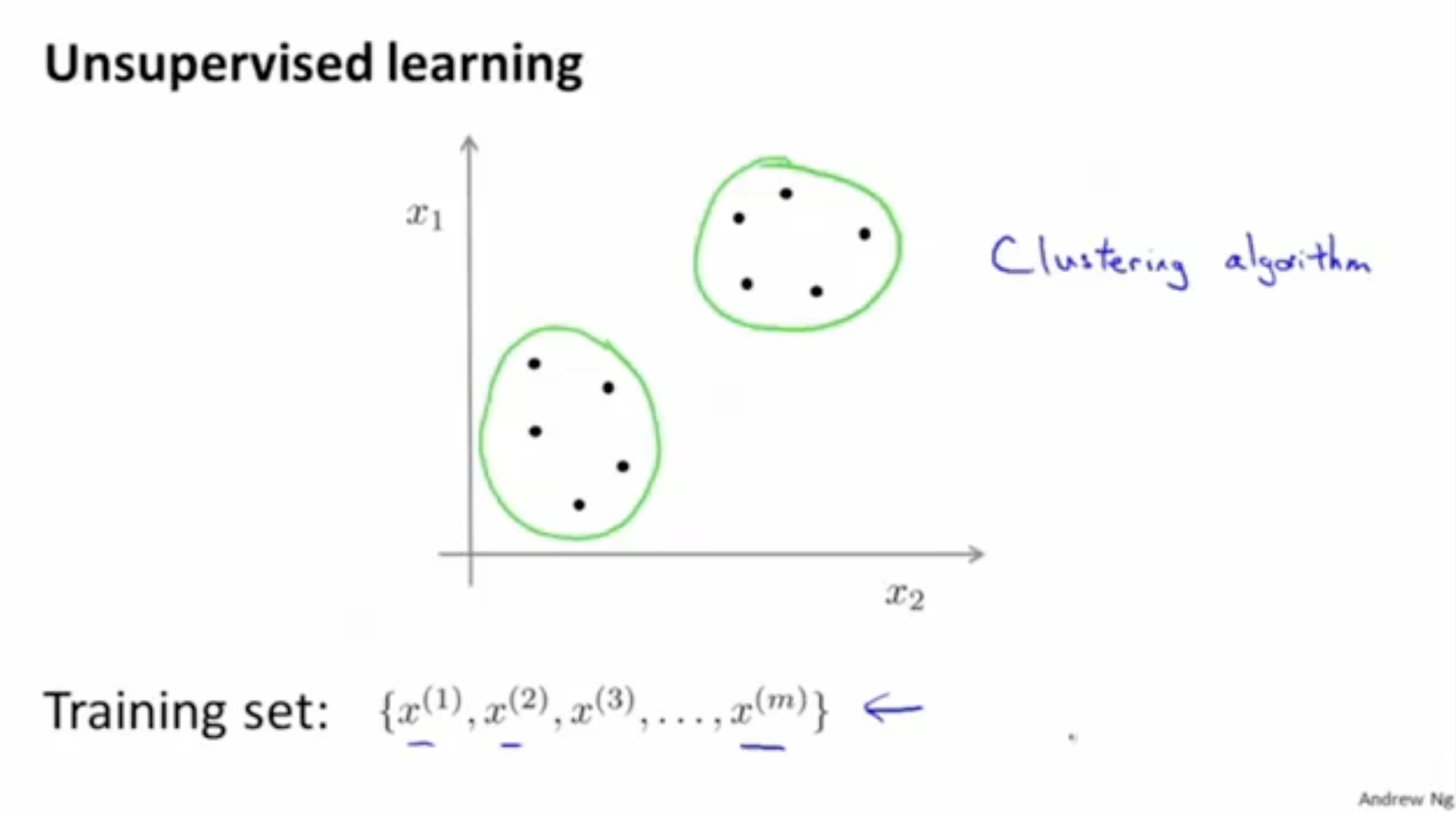
반면에 unsupervied learning은 입력 데이터 만 주어지고, 레이블은 주어지지 않는다.
training set : {}
이 경우 아래 그림처럼, 유사한 데이터들끼리 묶어주는 clustering algorithm이 필요하다.
clustering alg. 중 대표적인 "K-means" 알고리즘을 알아보자.
먼저 아래 그림과 같이 개의 centroids를 선정한다.
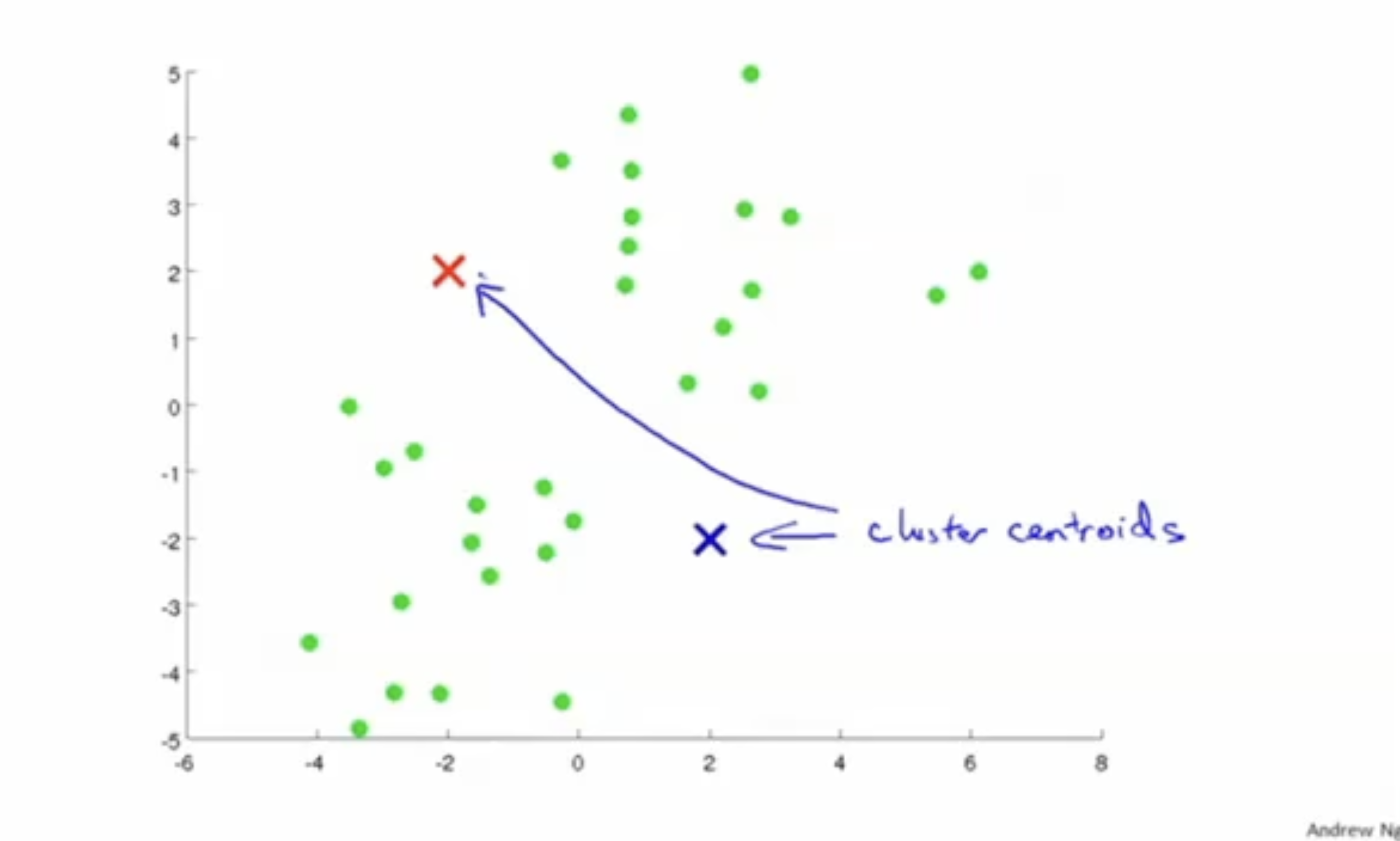
그리고 각 입력 데이터에 대해서 가까운 centroid에 할당되도록 한다.
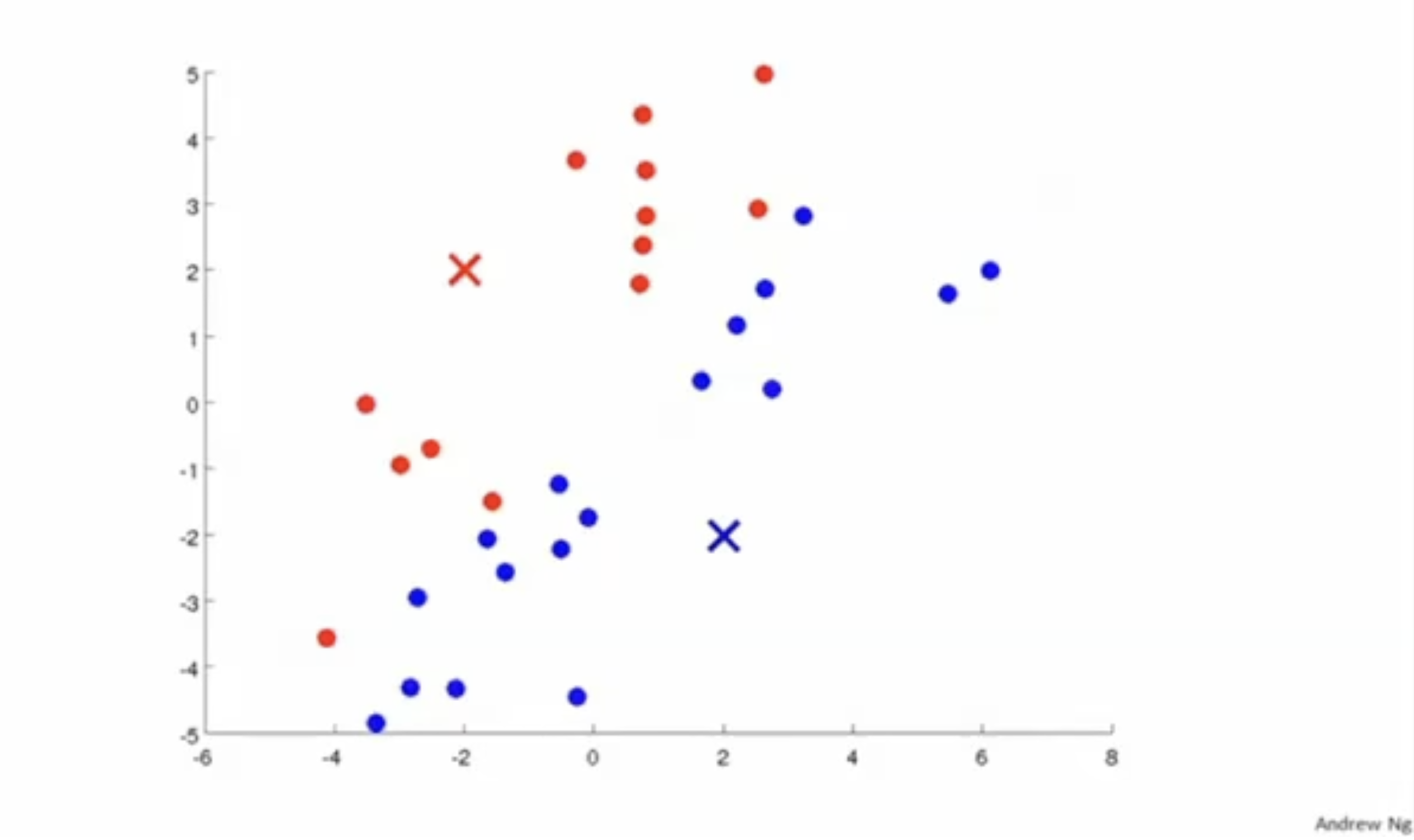
centroid를 clustering이 잘되는 쪽으로 이동한다.
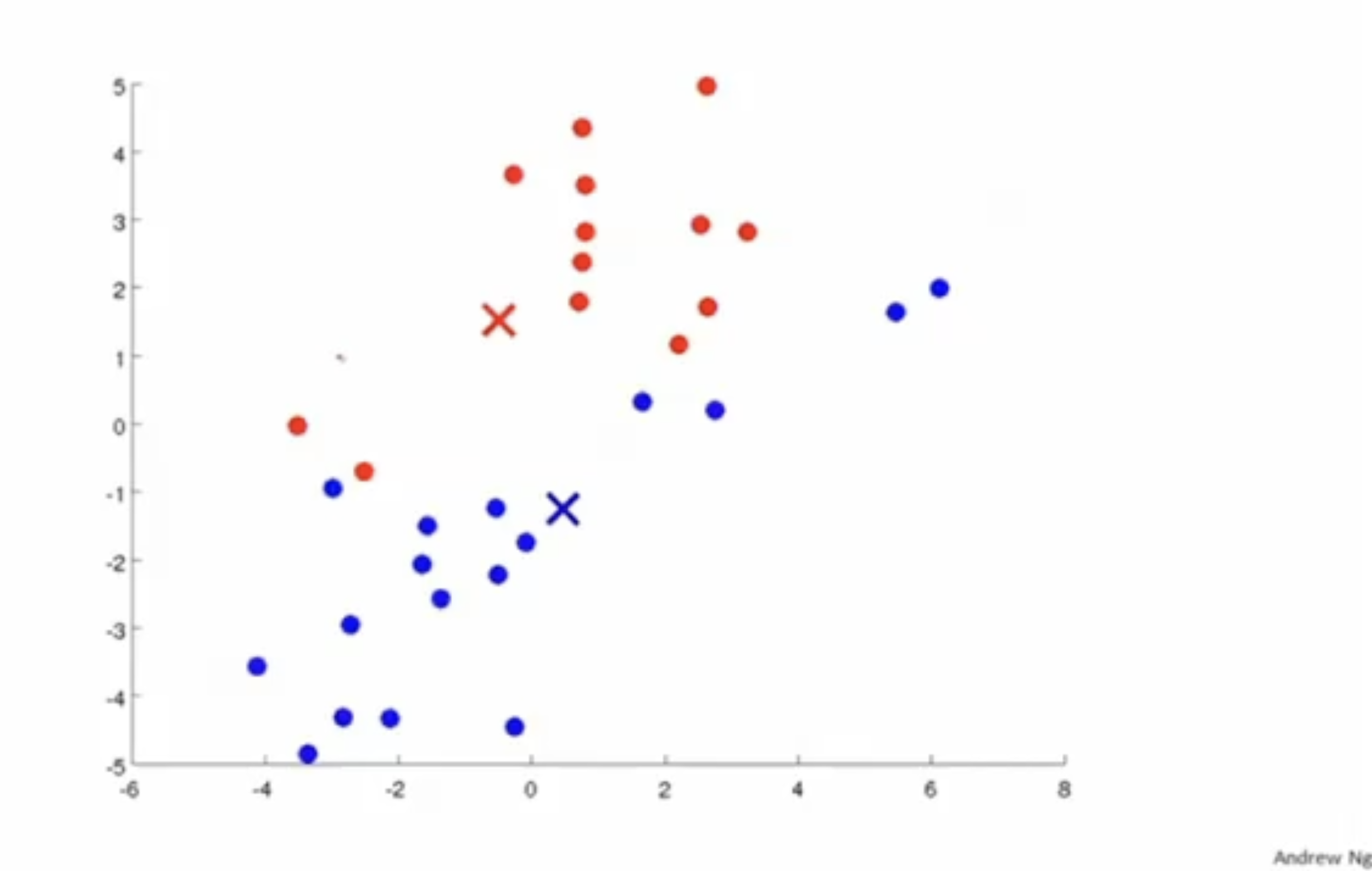
이 과정을 반복하면 아래와 같이 최종 결과를 얻을 수 있다.
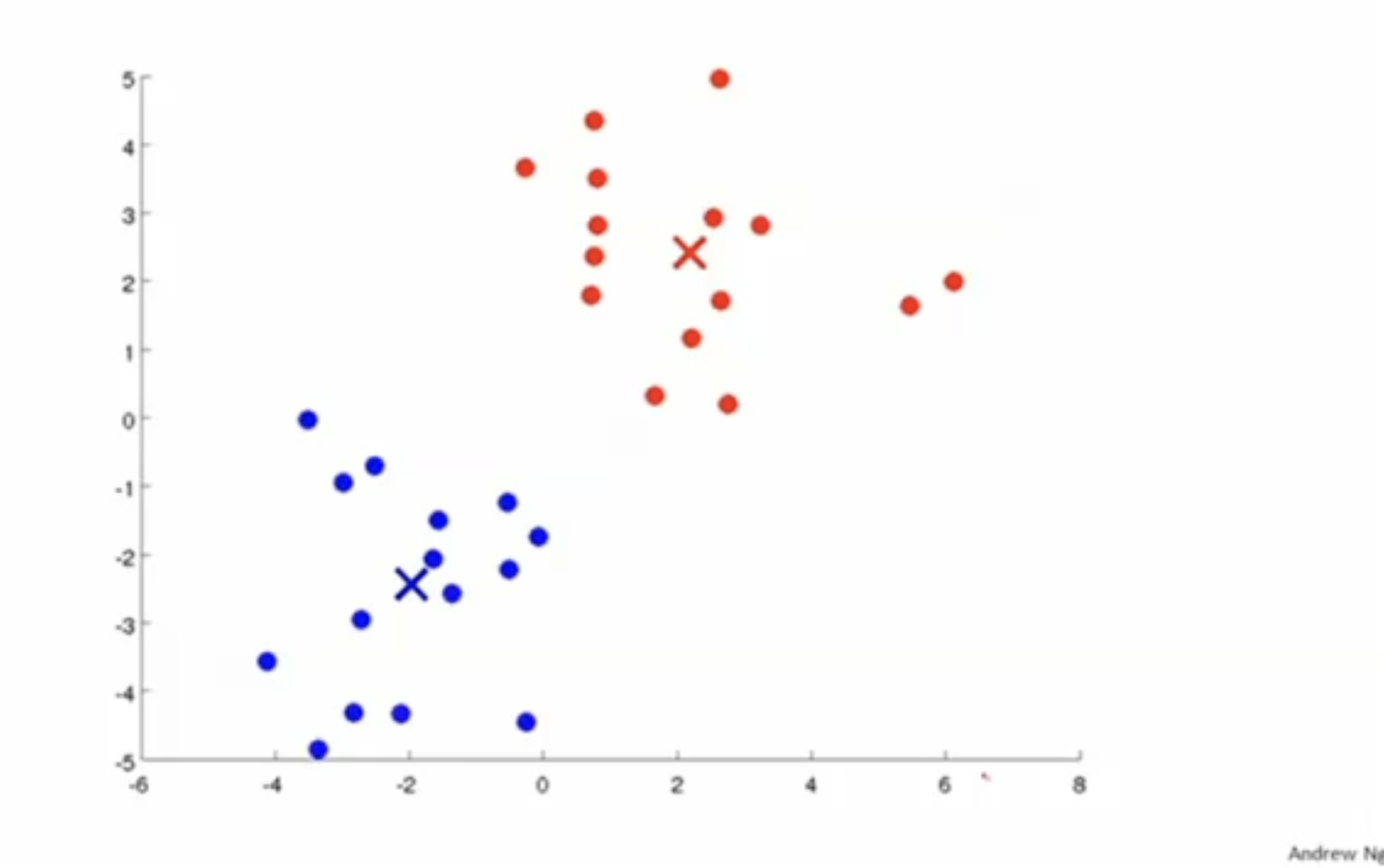
K-means algorithm에서 입력값은 다음과 같다.
- : number of clusters
- Training set : {} (이때 각 의 차원은 이 아니라 이다. 항을 버리기 때문.)

K-means algorithm의 절차를 표현하면 아래 그림과 같다.
1. 랜덤하게 개의 centroids 를 선정한다.
2. 각각의 입력 데이터 에 대해서 가까운 centroid의 인덱스를 구한다. 그리고 이 값을 에 저장한다.
3. 개의 centroids에 대해서, 각 centroid 의 값을 로 할당된 데이터 포인트들의 평균값으로 설정한다.
예를 들어, 이 centroid 와 가깝다고 할당된 경우,
가 되고,
이 된다.
4. 그리고 위 과정을 반복하여 각 데이터 (인) 가 각 centroid 와 가까워지도록 하는 최적의 를 찾는다.

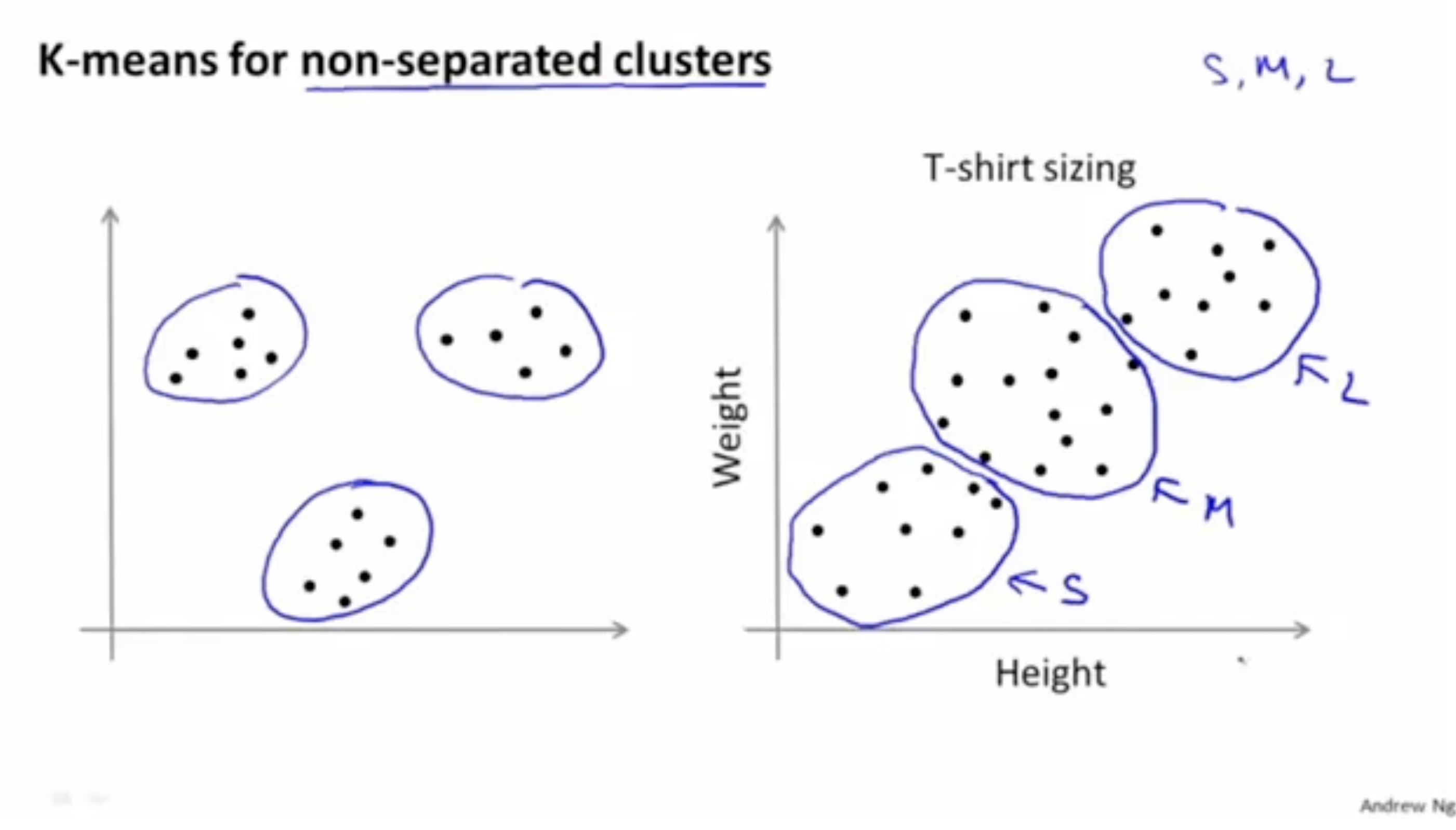
K-means alg.은 왼쪽처럼 분리된 데이터에 대해서 뿐만 아니라, 오른쪽처럼 비교적 연속적인 데이터에 대해서도 clustering이 가능하다.
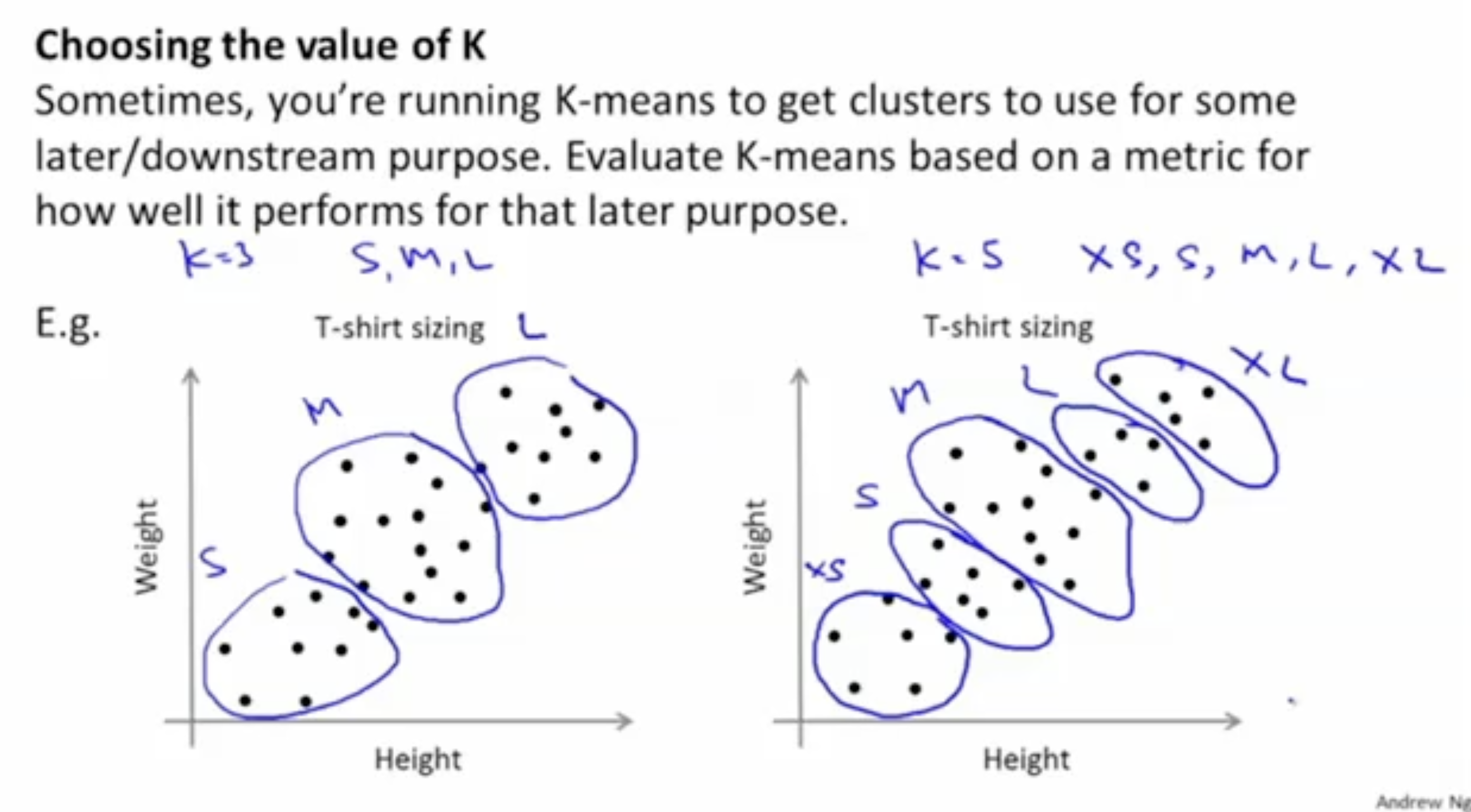
예를 들어, 키-몸무게에 따른 의류 사이즈는 사람마다 다양하게 나오는데 이걸 가지고 어떻게 S/M/L를 구분할 수 있을까? 이 경우 clustering이 필요하며 K-means alg.을 활용하여 clustering을 할 수 있다.
k-means의 최적화를 위한 cost function을 알아보자.
- : 의 가장 가까운 centroid 값.
- : centroid .
- : 의 centroid.
- ex. :
- 그리고 k-means의 cost function은 아래와 같다.
: 각 데이터 x와 x의 centroid 간의 평균 거리값을 의미한다.- 그리고 최적화 방법은 다음과 같다.
: cost function(=Distortion Function)을 최소화하는 최적의 와 를 찾는다.

k-means alg.의 절차를 다시 살펴보자.
1. 랜덤하게 centroid를 선택한다.
2-1. 입력 데이터의 centroid 할당 파트에서, cost function 를 최소화하는 를 구한다.
(여기서 는 고정되어 있다는 점을 주의한다.)
2-2. centroid의 이동 파트에서, cost function 를 최소화하는 를 구한다.
- 정리 : centroid initialization -> cluster assignment -> move cetroid -> cluster assignment -> move centroid (going to avg. of x's) -> ... -> no difference between previous -> done !

그러면 초기 centroid를 random하게 초기화하는 부분을 알아보자.
- 우선 centroid(cluster) 개수 는 무조건 데이터 수 보다 작을 것이다.
- 개의 학습 데이터에서 랜덤하게 개를 뽑는다.
- 그리고 이 데이터들을 centroid로 설정한다.
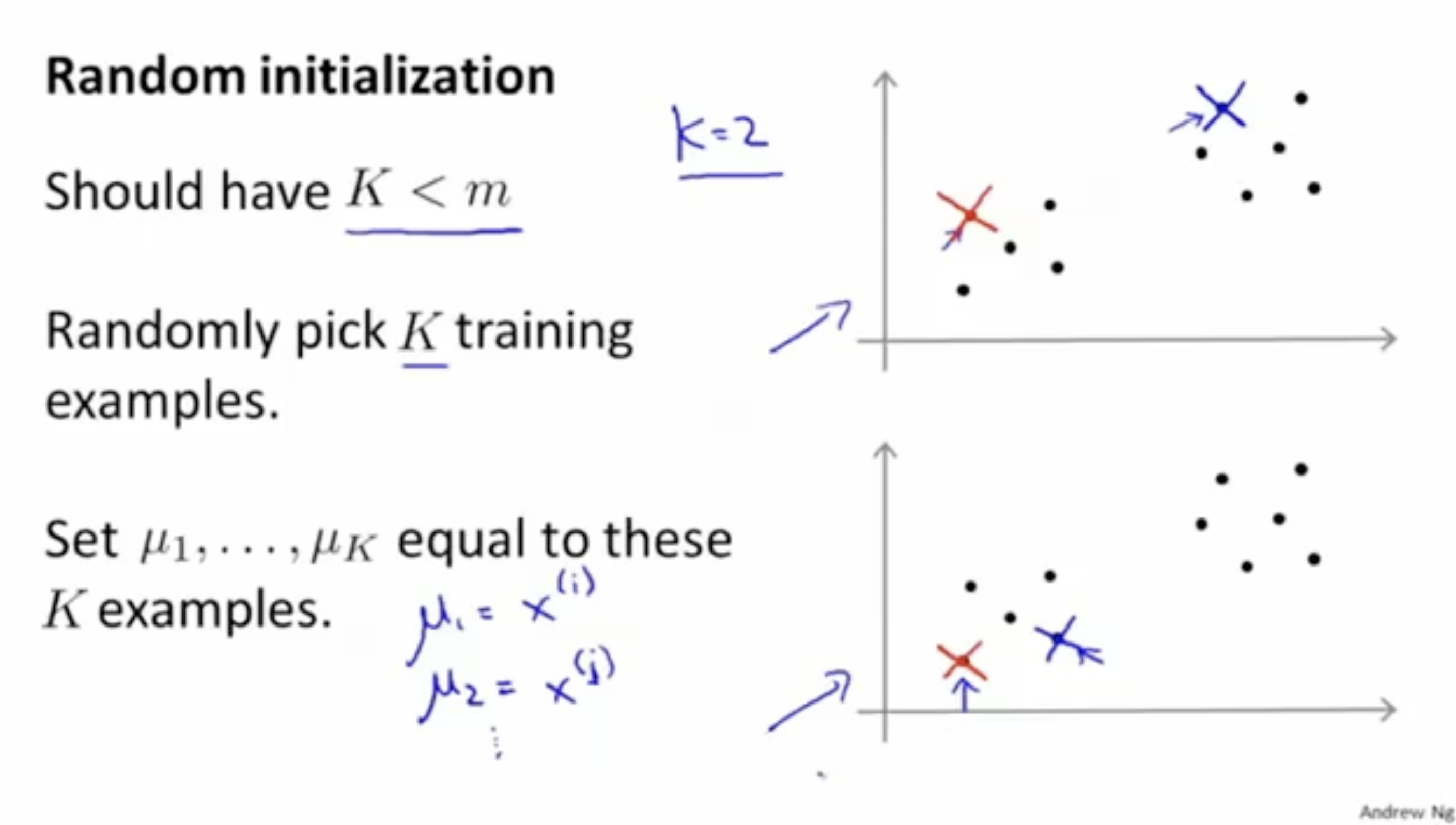
하지만, centroid가 어디서 시작하느냐에 따라 결과가 매우 달라질 수 있다.
아래 그림에서 맨 위의 그래프는 clustering이 잘된 경우지만, 아래 두 경우는 그렇지 않다.
- 이처럼 K-means alg.은 global optima가 아닌, 많은 local optima가 존재한다는 단점이 있다.
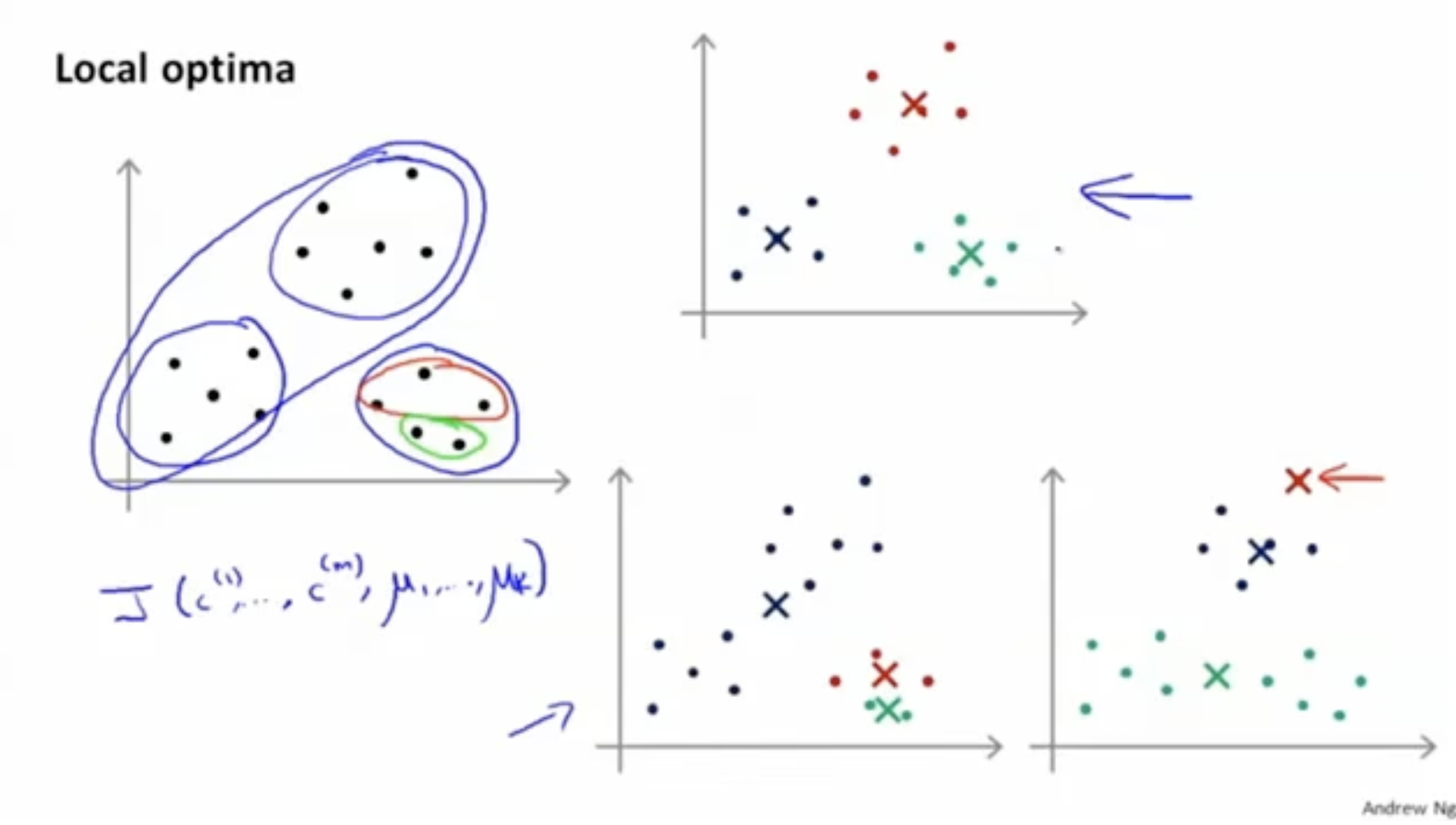
K-means alg.의 random (centroid) initiatlization을 정리하면 다음과 같다.
- 개의 학습데이터에서 개를 뽑는다.
- K-means alg.을 적용하여 , 값을 구한다.
- cost function(distortion function)을 계산한다.
- cost function의 값이 변화가 없을 때까지 위 과정을 반복한다.
다만, K-means alg.은 적은 수의 에 대해서 잘 동작하지만, 많은 수의 에 대해서는 많은 local optima가 존재하게 되며 잘 동작이 되지 않는다.

그렇다면 어떻게 적절한 값을 찾을 수 있을까?
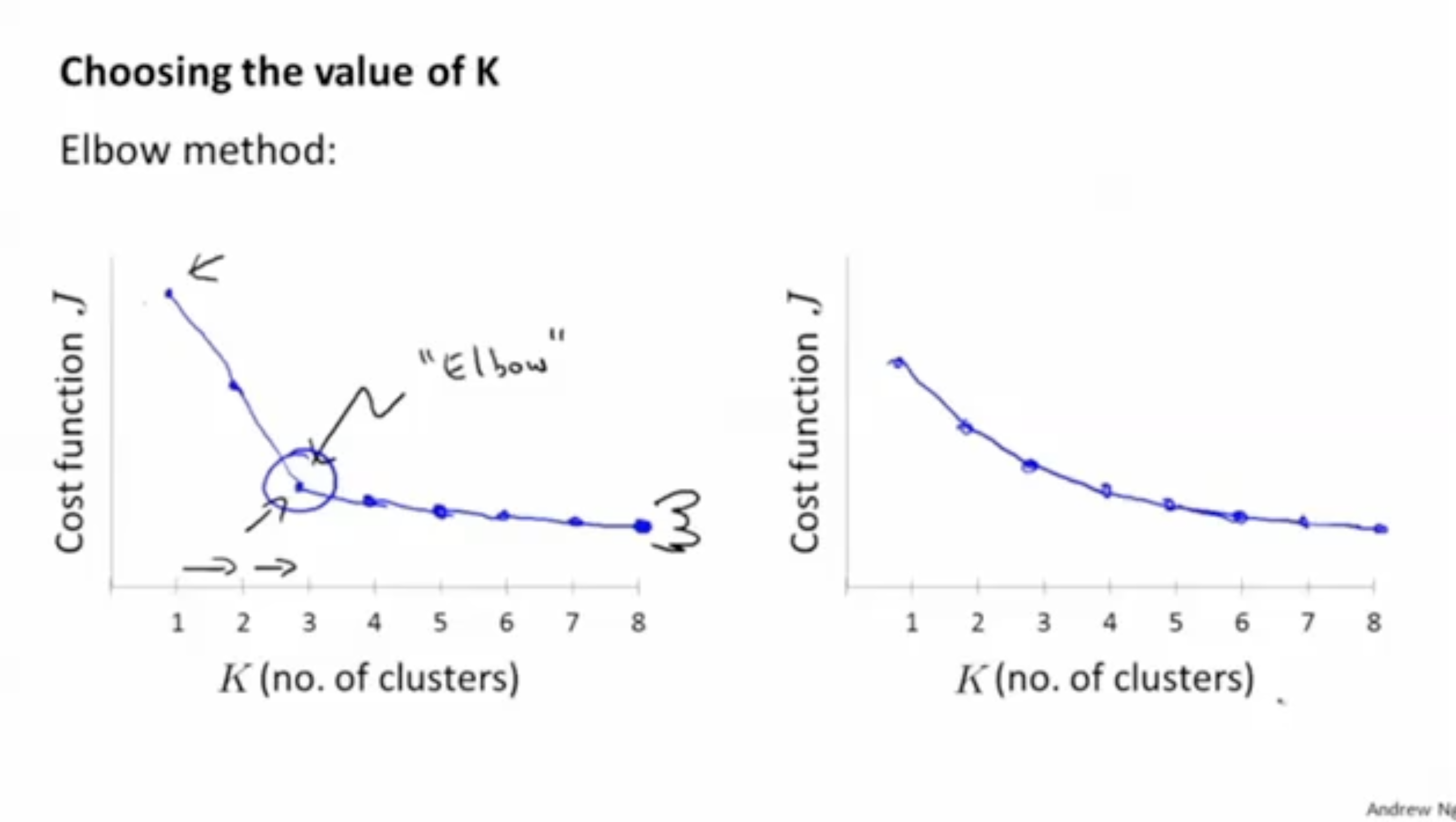
한 가지 방법이 "Elbow method"이다.
- 좌측 그래프처럼 변곡점(Elbow point)을 기준으로 cost function이 크게 줄어들기 때문에, 해당 가 최적의 라고 볼 수 있다.
- 하지만, 우측 그래프처럼 기울기가 완만하게 이어질 경우, 해당 method는 효과가 없다는 단점이 있다. 이를 위해서는 다른 방법을 적용해야 한다.
그리고 때로는, 사용자의 목적에 맞게 를 설정할 수 있다.
- 아래 예시에서 좌측은 S\M\L로 3개의 사이즈로 구분을 원하는 경우고, ()
- 우측은 XS\S\M\L\XL로 5개의 사이즈로 구분을 원하는 경우이다. ()