https://www.youtube.com/watch?v=_BYX-oHP0E4&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX&index=14
ML에서는 학습을 위해 대량의 데이터가 필요하다. 이에 따라 많은 저장 공간이 필요하기도 하고, 또한 많은 양의 데이터를 학습하기 위한 시간도 필요하다. 이를 위해 필요한 개념이 data compression이다.
(보통 features의 차원을 줄이는 것을 의미한다.)
데이터의 차원을 다음과 같이 줄여보자.
즉, (파일럿의 스킬, 흥미도)라는 2차원 데이터를 (적성)이라는 1차원 데이터로 압축하는 것이다.
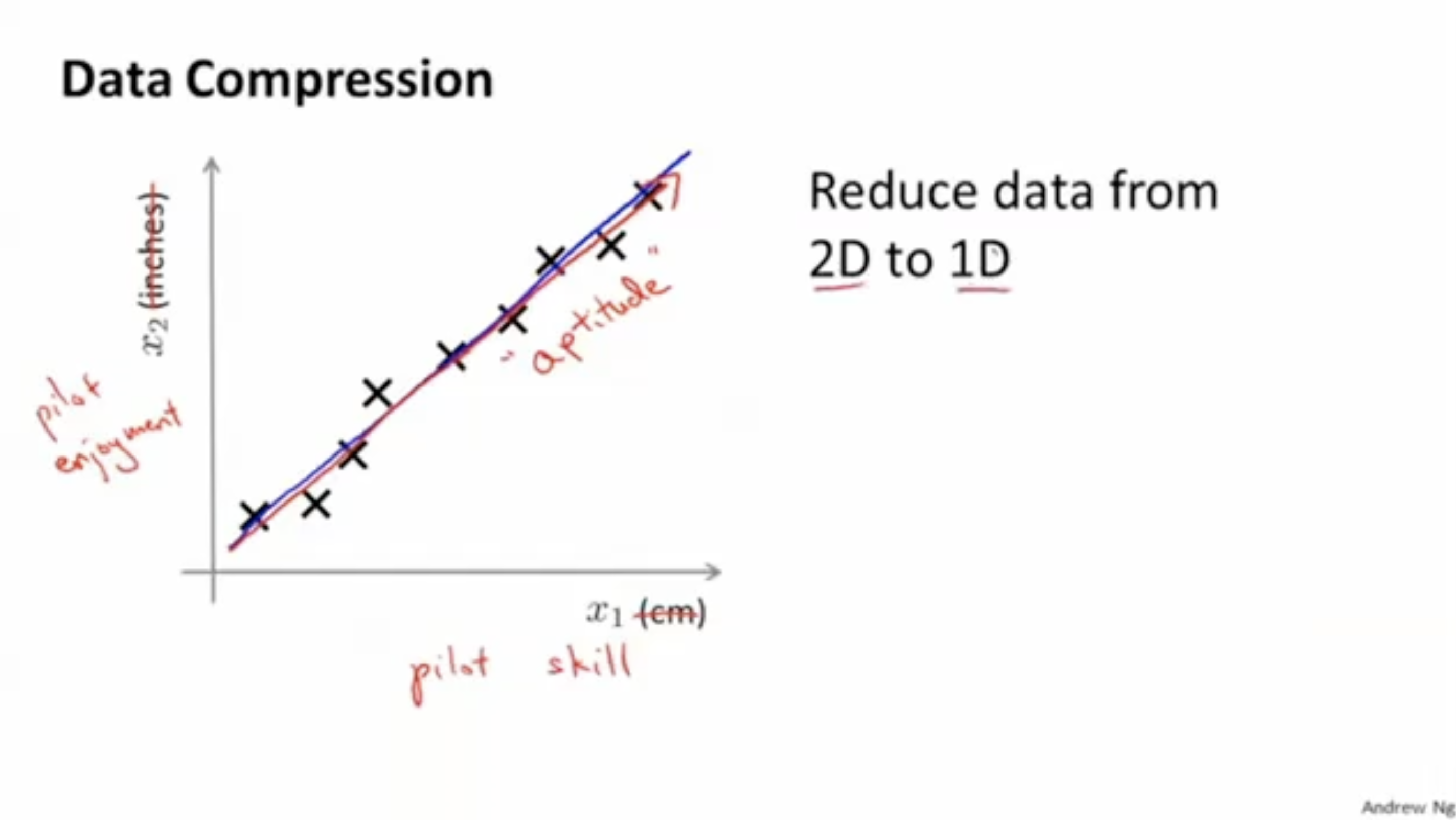
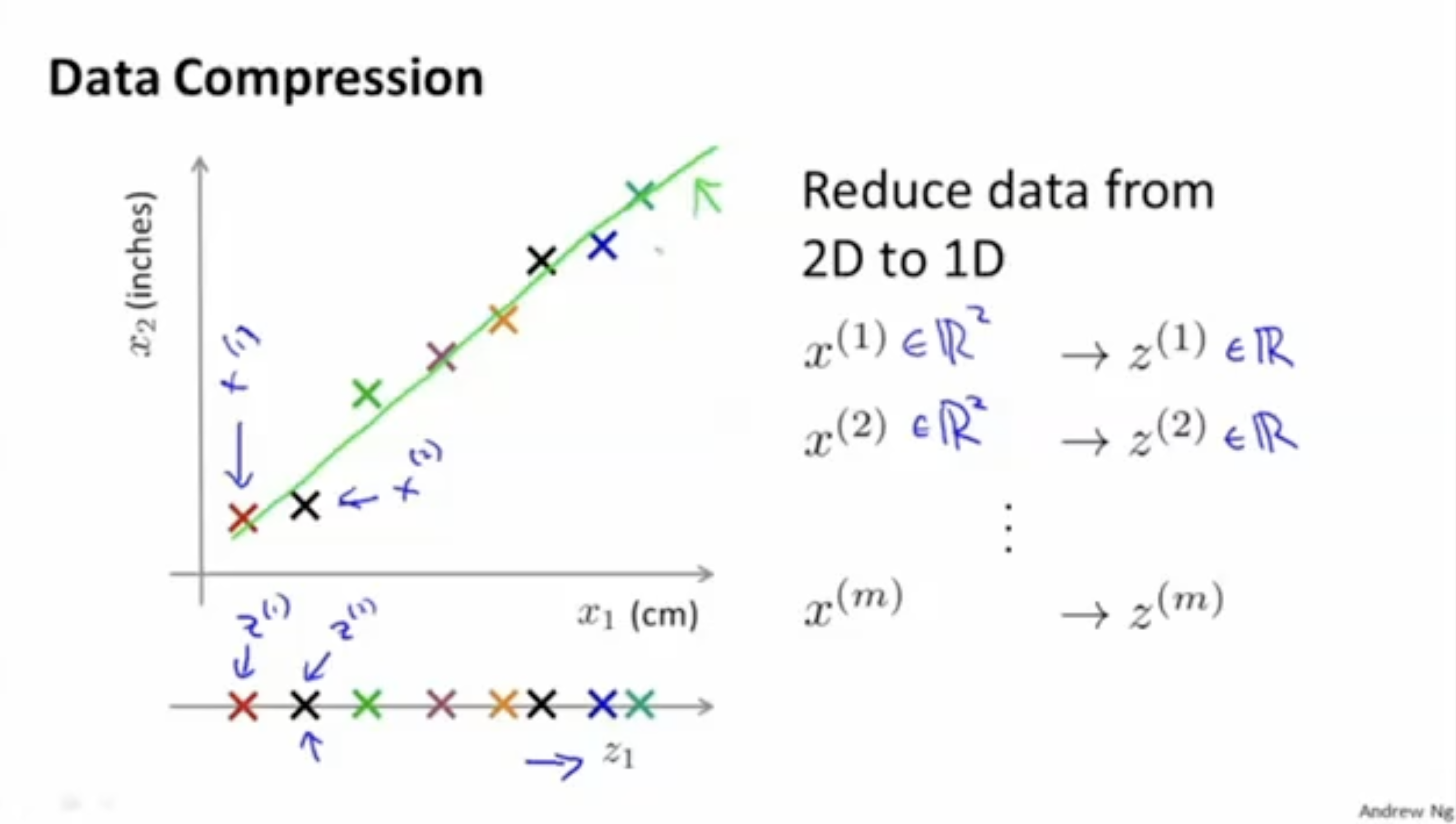
더 구체적으로 표시하면 아래와 같다. 데이터를 어떤 한 1차원 벡터로 projection한다.
이렇게 되면 처럼 2차원( and )에서 1차원()으로 데이터의 차원을 축소할 수 있다.
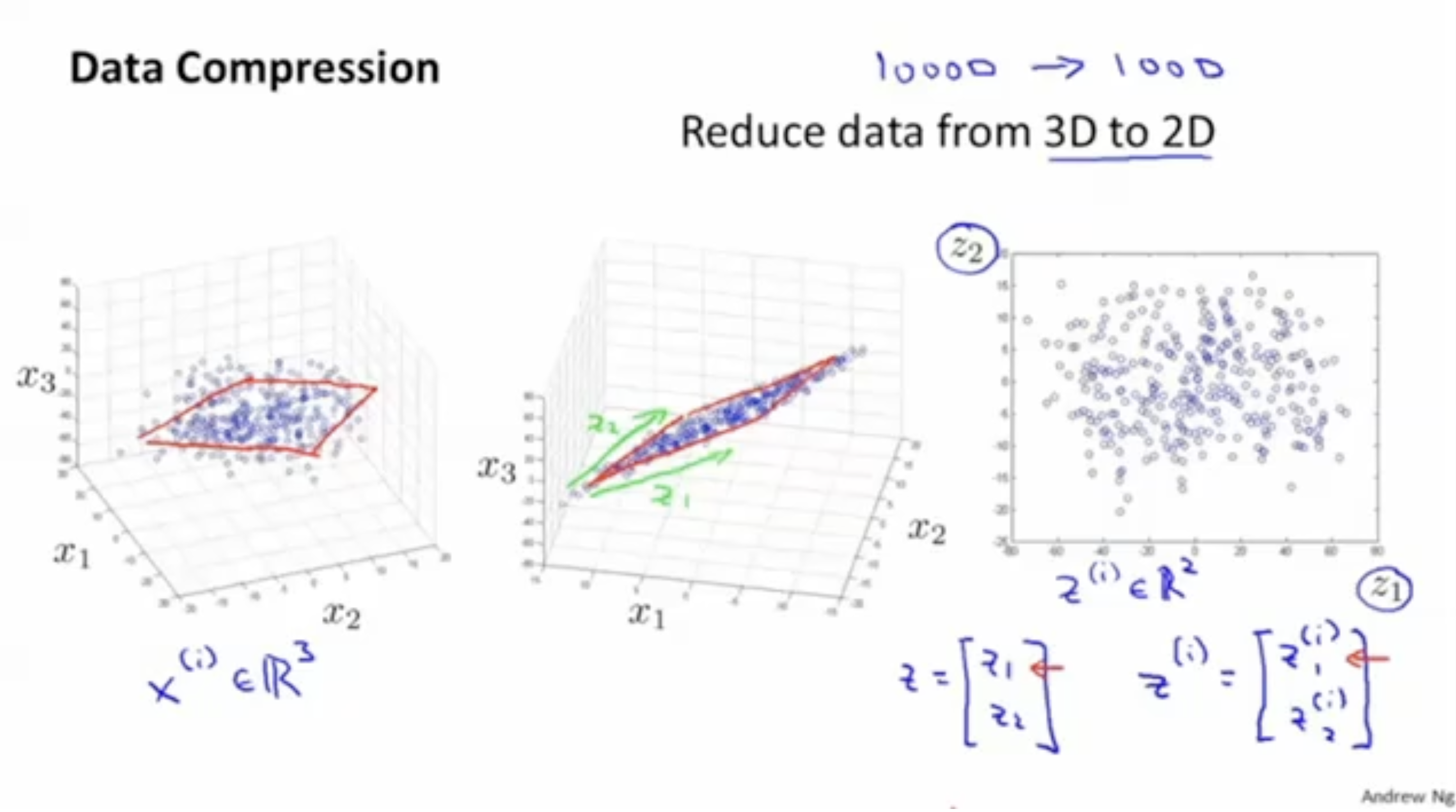
이제 3차원에서 2차원으로 축소를 해보자.
아래 왼쪽 그림과 같이 3차원으로 존재하는 데이터가 있다.
이 3차원 공간에서 2차원 공간을 하나 선정한다. (plane을 하나 선정한다.)
그리고 이 plane에 데이터를 project한다.
그러면, 처럼 3차원에서 2차원으로 데이터를 축소할 수 있다.
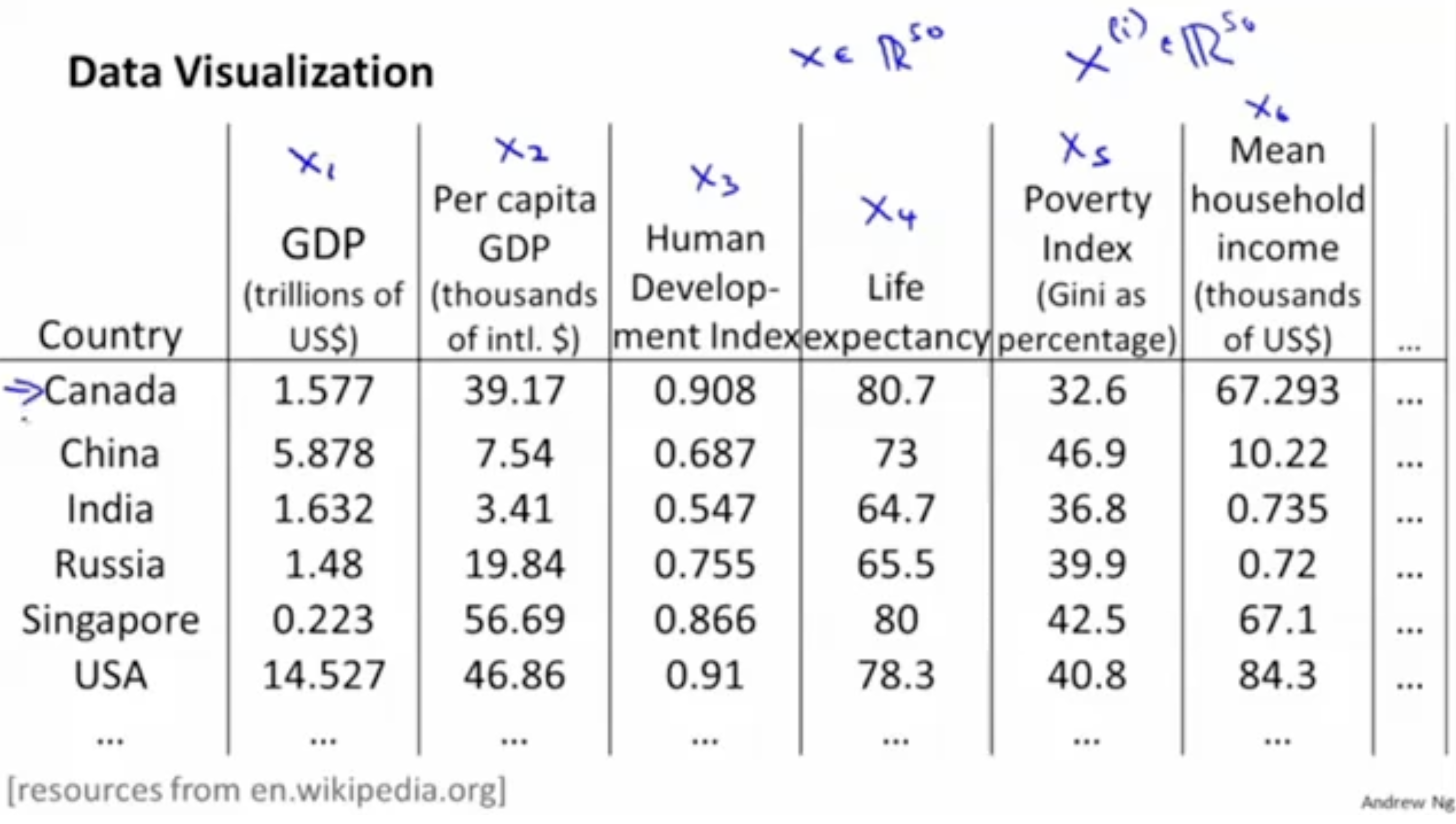
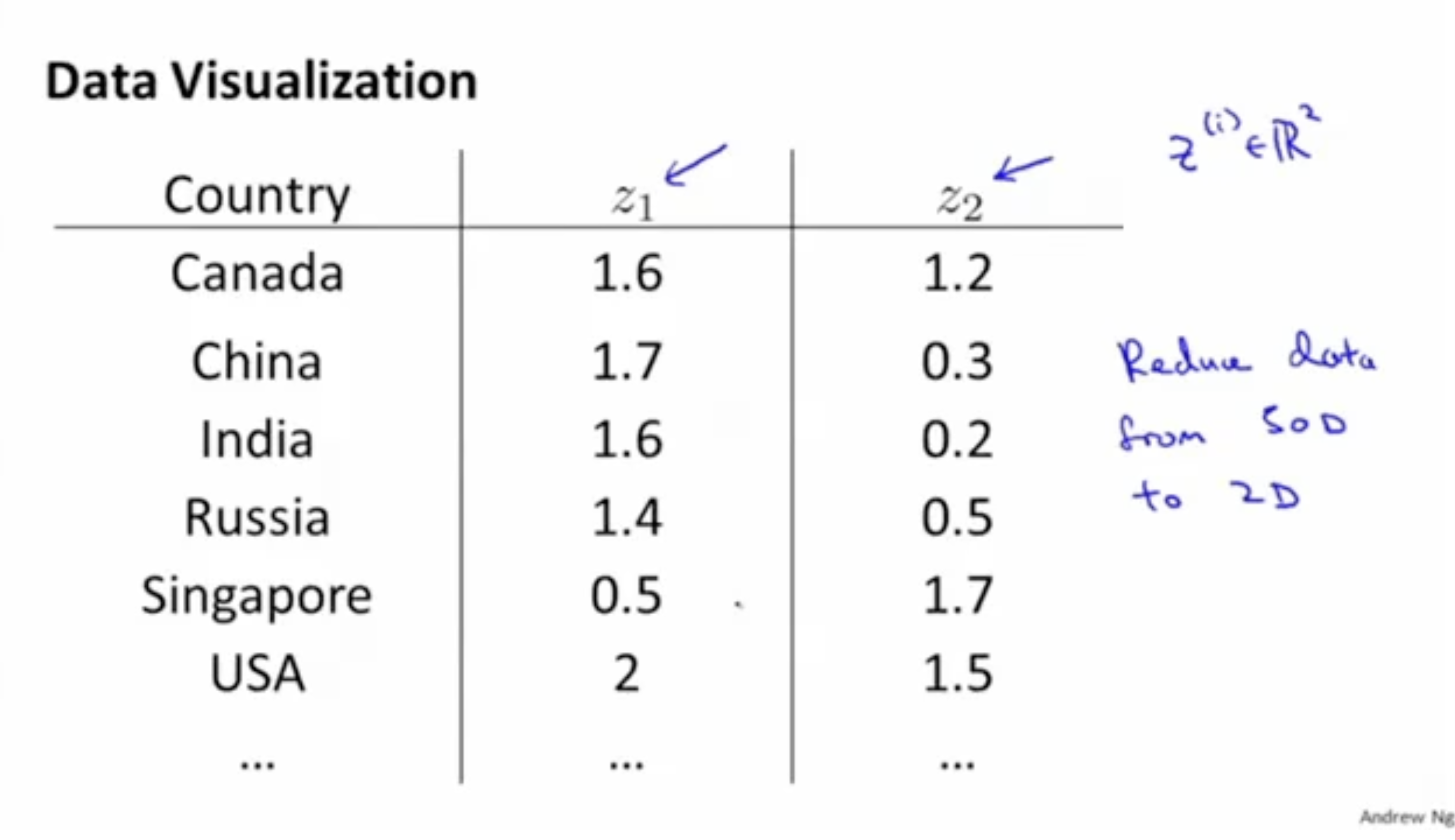
예시와 함께 보자. 아래와 같이 각 나라의 GDP, 1인당 GDP 등의 feature들이 있다고 해보자.
이 경우, 총 features 종류의 수는 50으로, 이다.
그리고 위와 같은 50차원의 features를 ()라는 2차원 데이터로 축소한다.
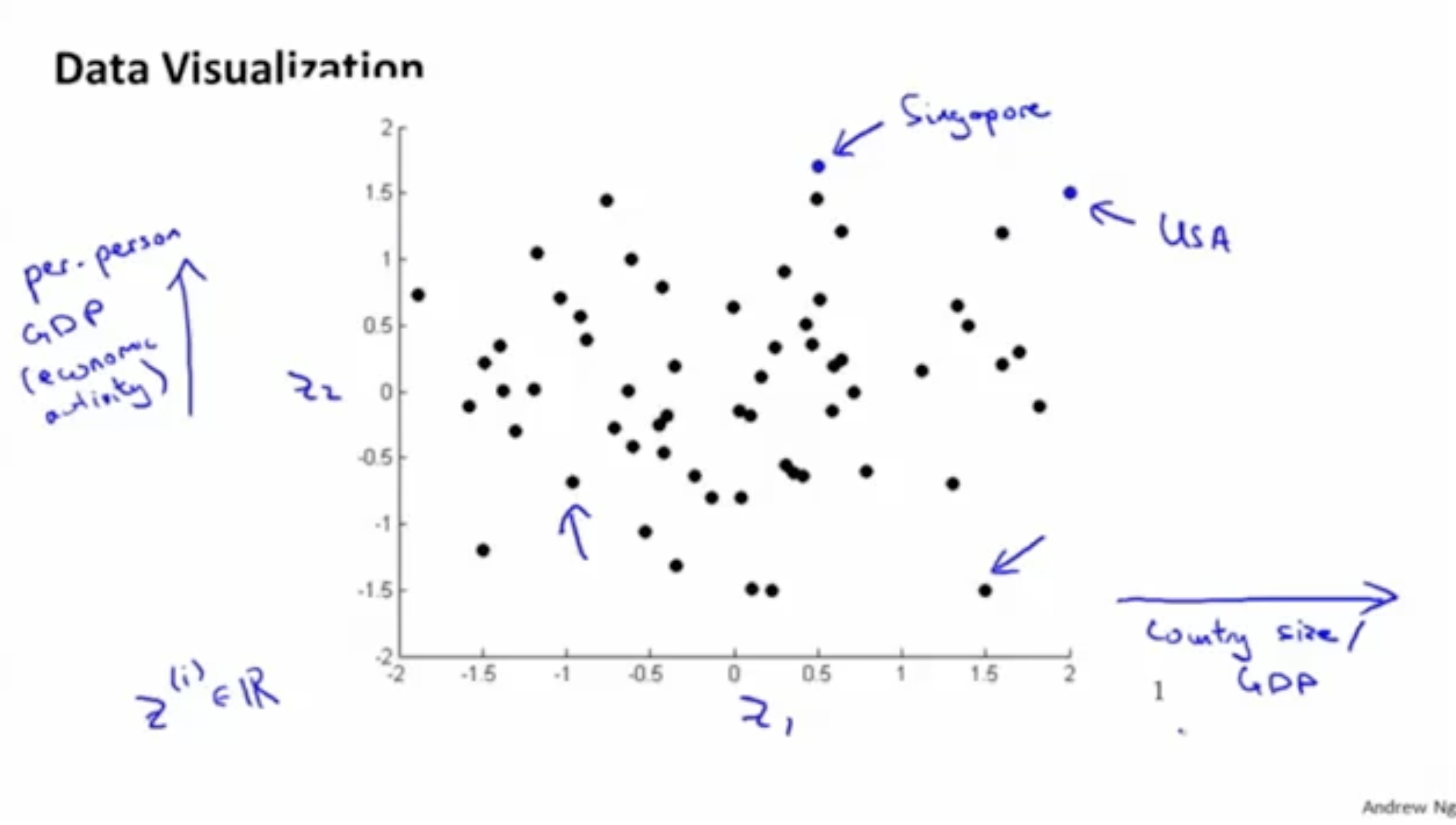
그리고 각 국가를 그래프 위에 그려보면 아래처럼 표시할 수 있다.
- 우선 은 GDP, country size 등의 feature들을 내포하며, 는 1인당 GDP, 경제 활동 등의 feature들을 내포한다.
- 그리고 아래 그림과 같이 USA는 모두 높은 값으로 나타날 것이다. (1인당 GDP도 높고, 총 GDP도 높고, 땅도 크고, ...)
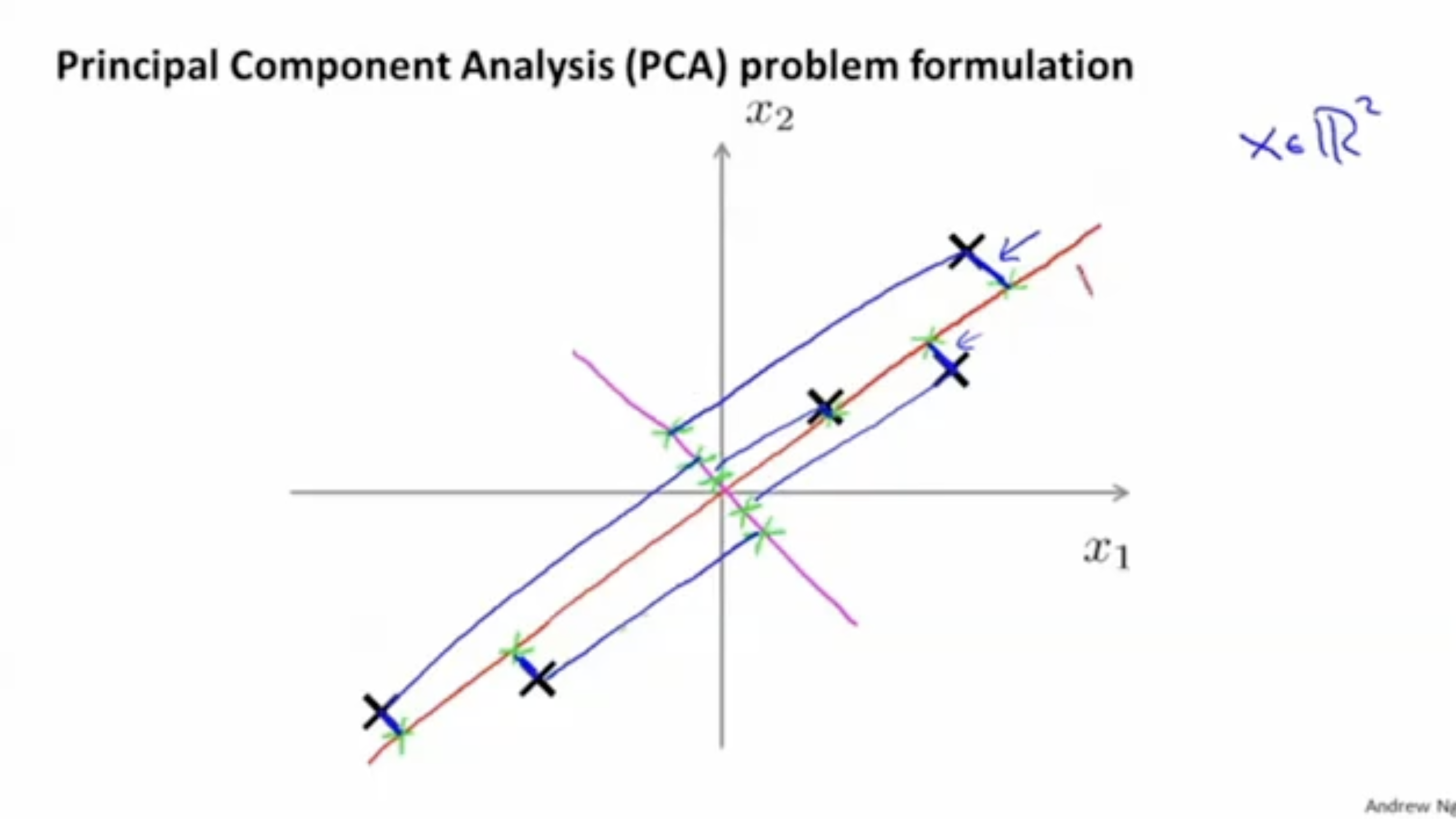
그리고 이처럼 데이터를 vector로 project하여 차원을 축소하는 방법이 "Principal Component Analysis (PCA)" 방법이다.
아래 그림과 같이 빨간색 벡터와 핑크색 벡터가 있을 때, PCA는 데이터들의 projection error가 최소화되는 빨간색 벡터를 선택할 것이다.
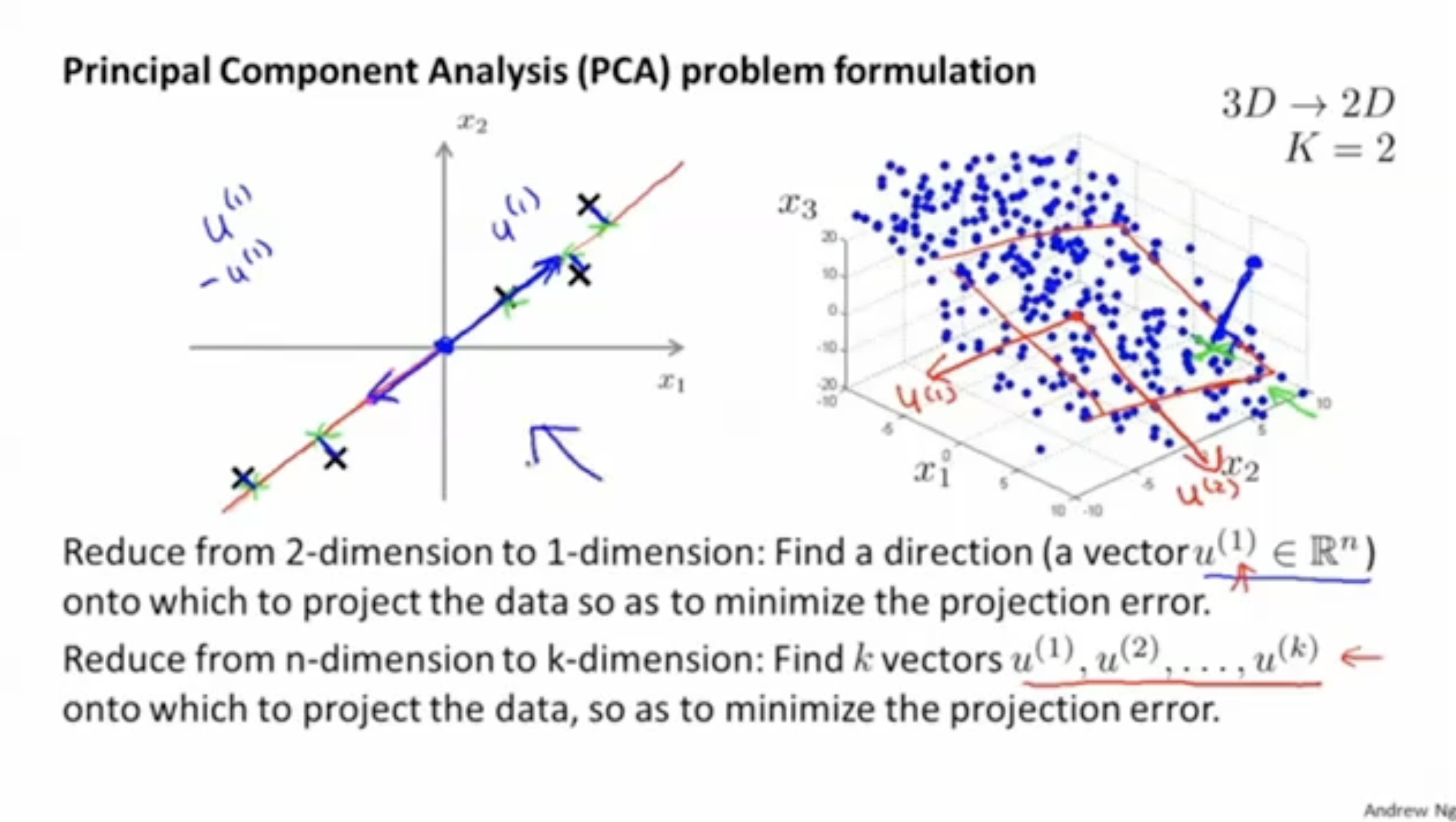
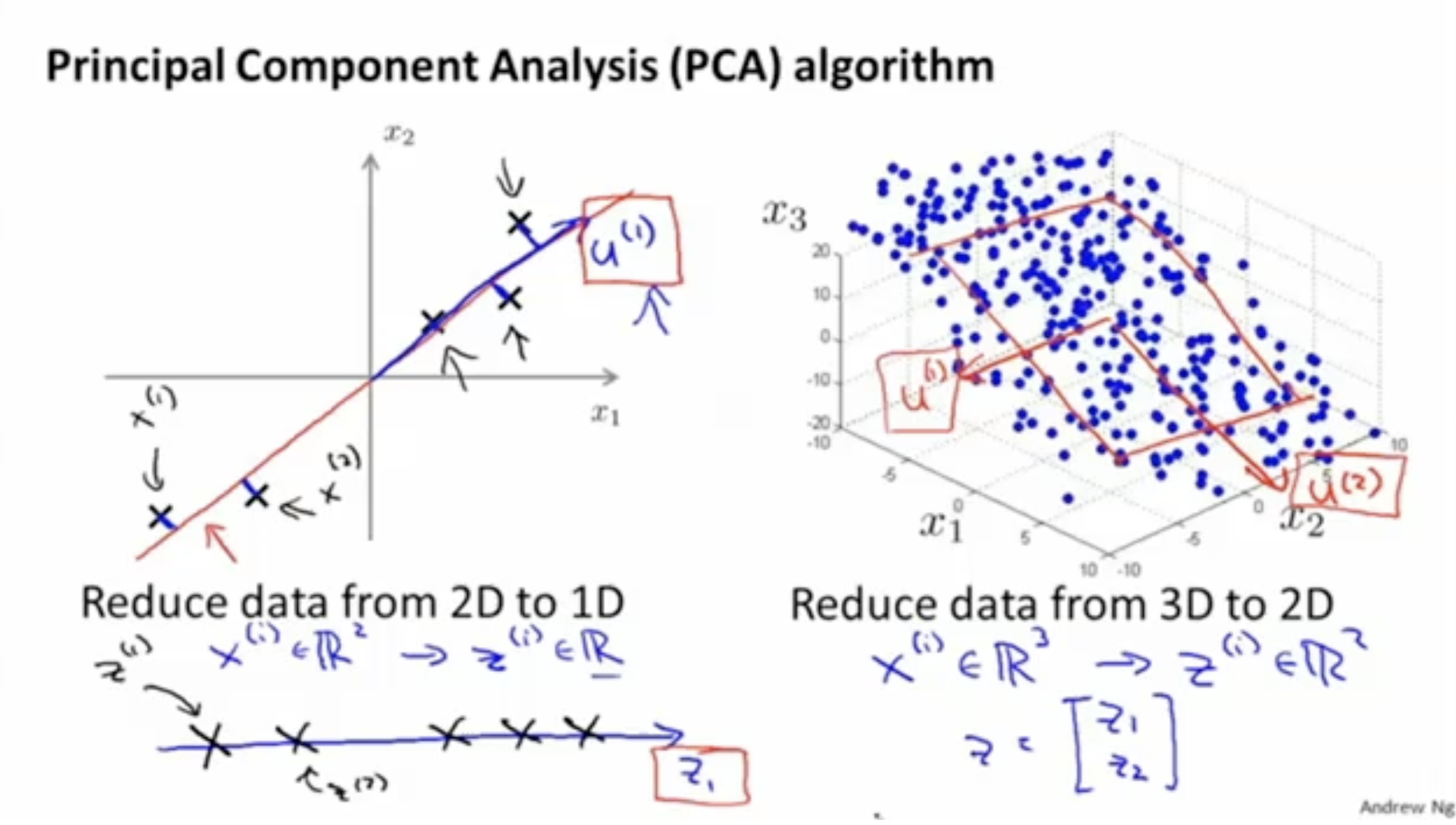
먼저, 2차원 데이터를 1차원으로 축소하는 PCA를 예시로 살펴보자.
왼쪽 그림과 같이 2차원 데이터 ()에 대해서 최솟값의 projection error를 갖는 벡터 을 선택한다.
다음으로, 오른쪽 그림과 같이 3차원을 2차원으로 축소하는 경우를 보자. 이 경우, 3차원 데이터 를 2차원으로 축소하는 벡터 를 선택한다.
- 따라서 이를 일반화하면, PCA에서는 차원을 갖는 데이터를 차원으로 축소하기 위해서 개의 벡터 ()를 선택한다.
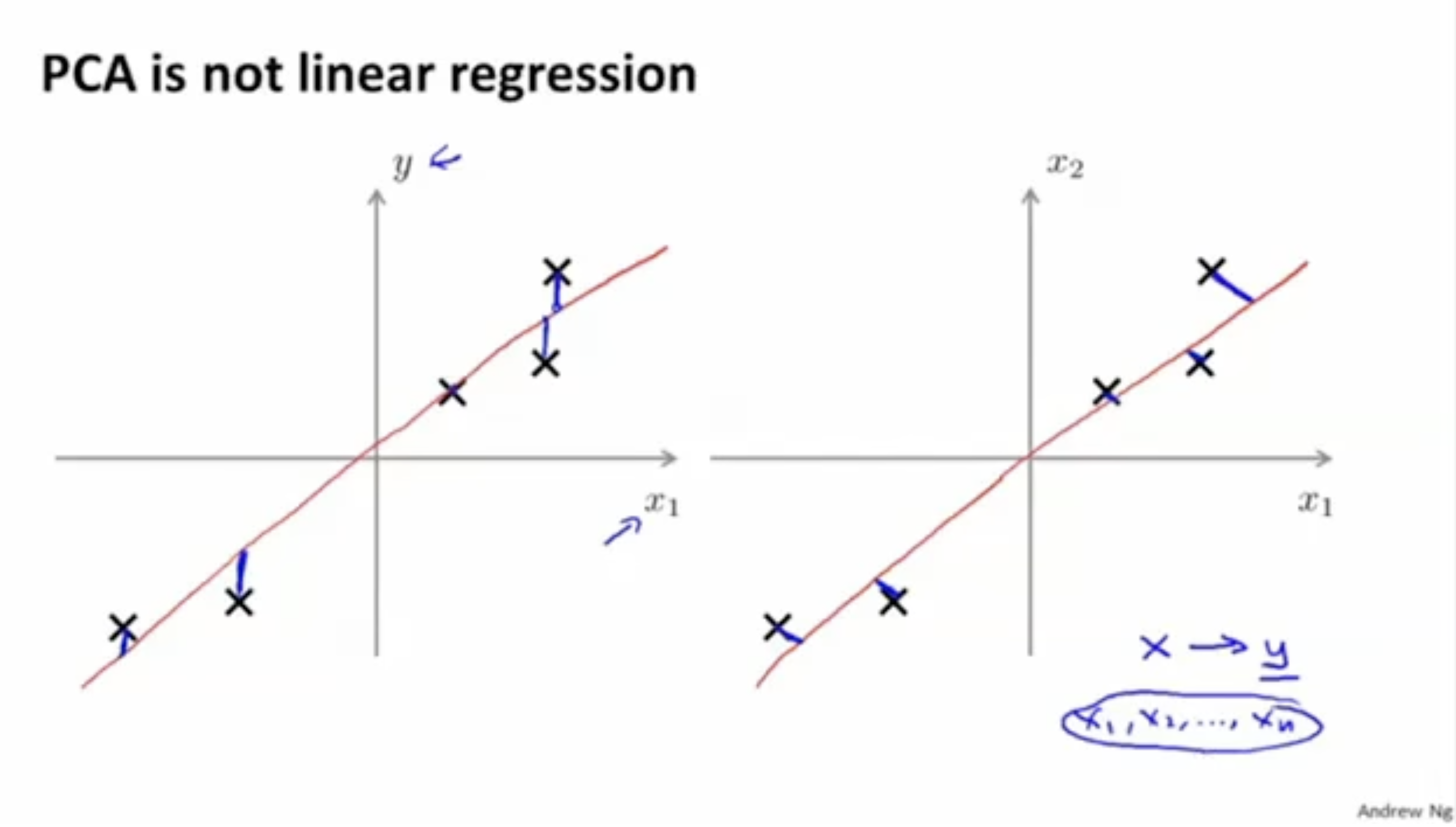
그리고 주의할 점이 PCA는 linear regression( )이 아니라는 것이다.
아래 그림에서 왼쪽과 같이 어떤 벡터(함수)에 대해서 입력값()을 넣어 결과값()를 구하는 게 아니라,
우측과 같이 어떤 벡터와 입력값 와의 거리를 구하는 것이다.
이제 PCA의 구현 과정을 하나씩 살펴본다.
- 먼저, m개의 학습 데이터셋 가 있다.
- 그리고 데이터 전처리 과정을 진행한다. (feature scaling, mean normalization 등)
- 전처리 과정 수식은 다음과 같다.
(여기서 는 , 등이 될 수 있다.)

다음으로는 n차원 데이터를 k차원으로 축소하는 방법이다. 우선 아래 그림처럼 2차원을 1차원으로, 혹은 3차원을 2차원으로 축소한다.
즉, n차원 데이터 를 축소하여 차원 데이터 로 만든다.
PCA를 컴퓨터로 연산하려면 아래와 같다.
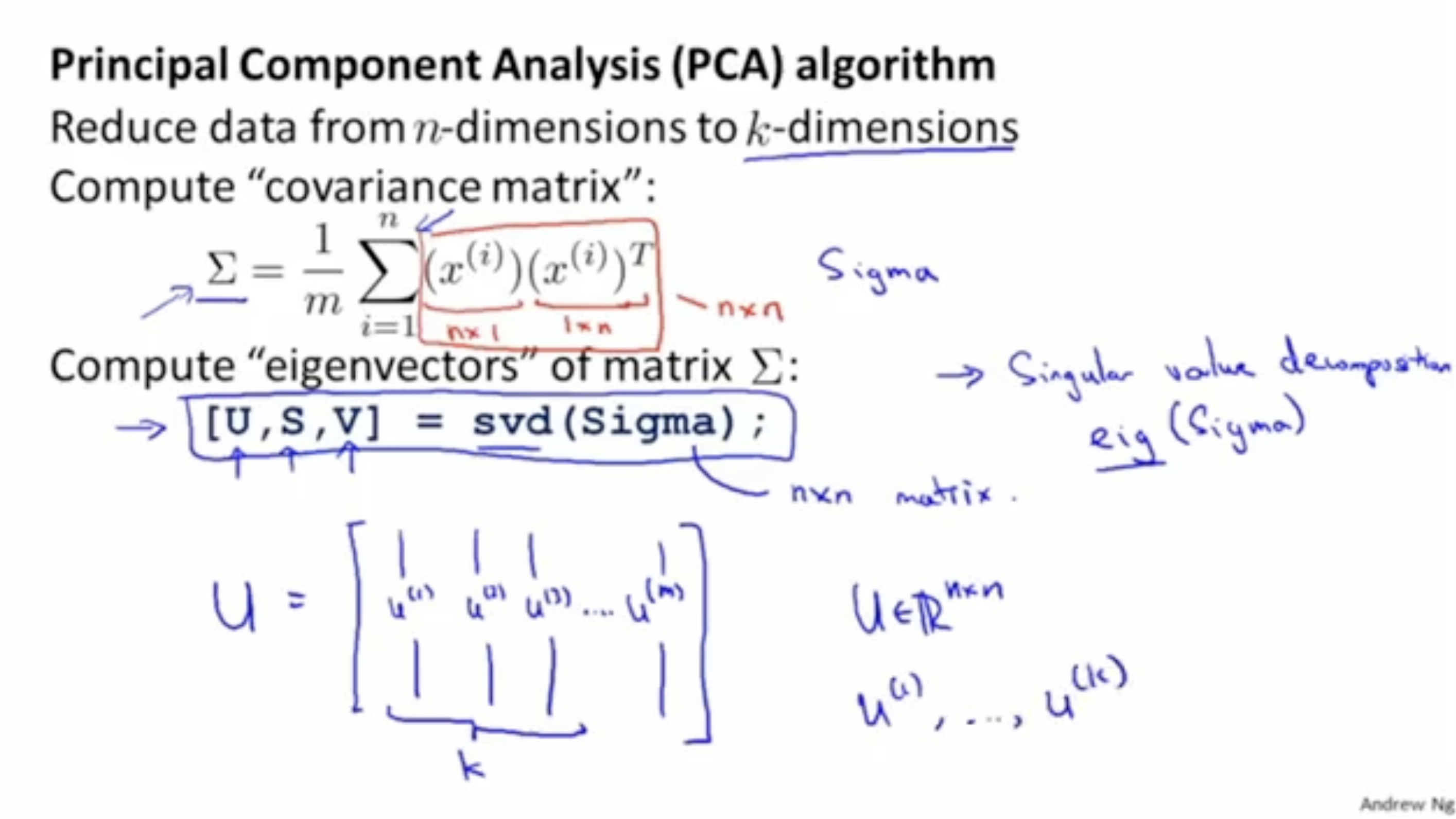
- 먼저 covariance matrix (공분산 행렬)을 계산한다.
: 여기서 는 sum 함수가 아니라 notation으로서의 의미이다.
그리고 이때 covariance matrix 행렬은 크기를 갖는다.
()- 다음으로 를 통해 covariance matrix 에 대한 eigenvalue(고유값)을 구한다.
여기서 는 singular value decomposition 함수이다.- 를 통해 얻은 행렬에서 개 만큼의 벡터를 가져온다.
- 이제 이 벡터로 projection을 하면 된다.
앞서 말한 마지막 부분에 대한 설명을 좀더 설명하면 아래와 같다.
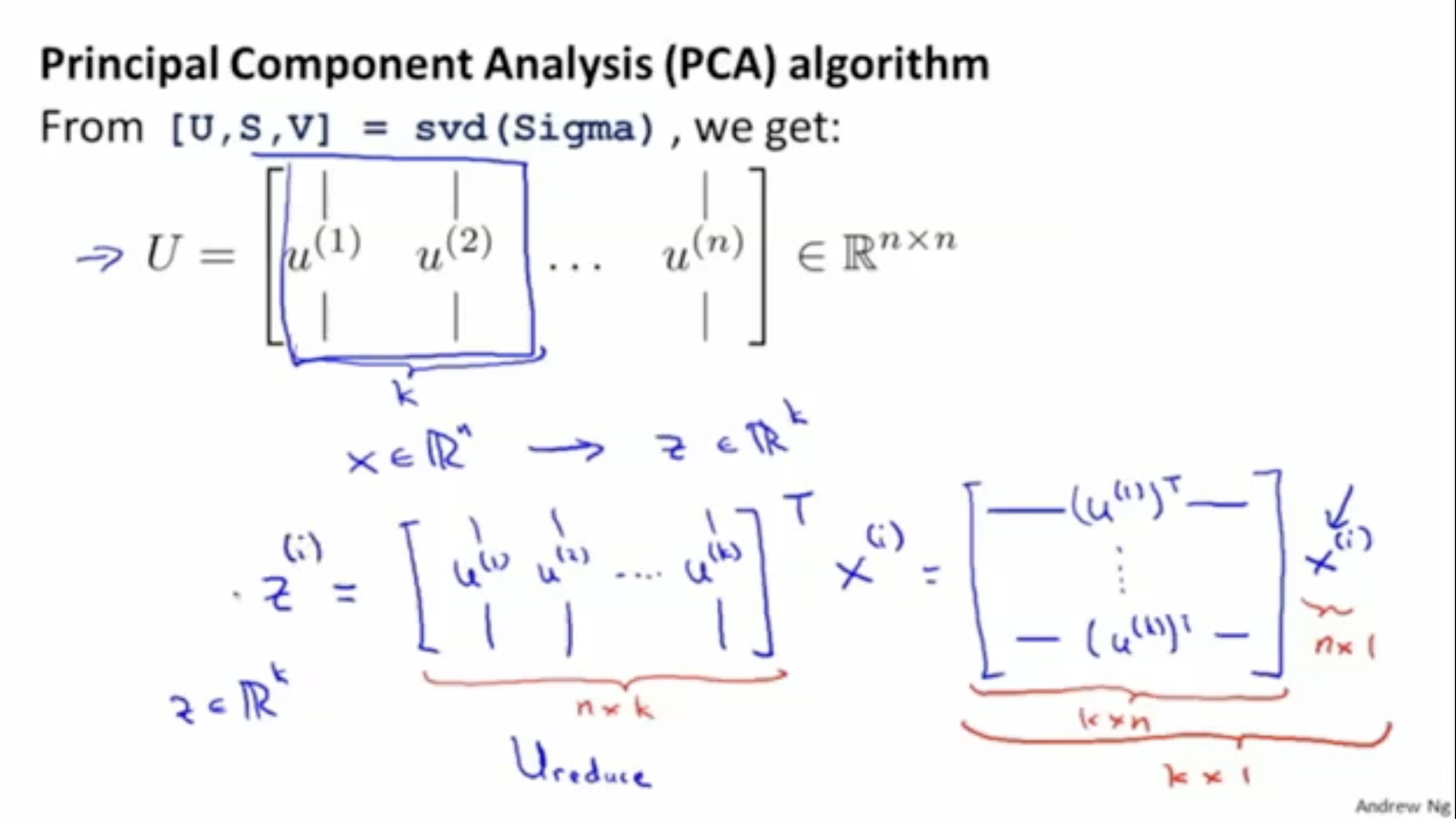
- 앞서 구한 행렬에서 개 만큼의 벡터를 가져와 행렬을 만든다.
- 데이터 를 reduce matrix 에 project하여 축소된 k차원의 데이터 를 구한다.
)
따라서 PCA 방법을 요약하면 아래 그림과 같다.
1. 데이터 전처리.
2. covariance matrix 구하기.
3. 로 행렬 구하기.
4. 에 를 적용하여 데이터로 차원을 축소하기.

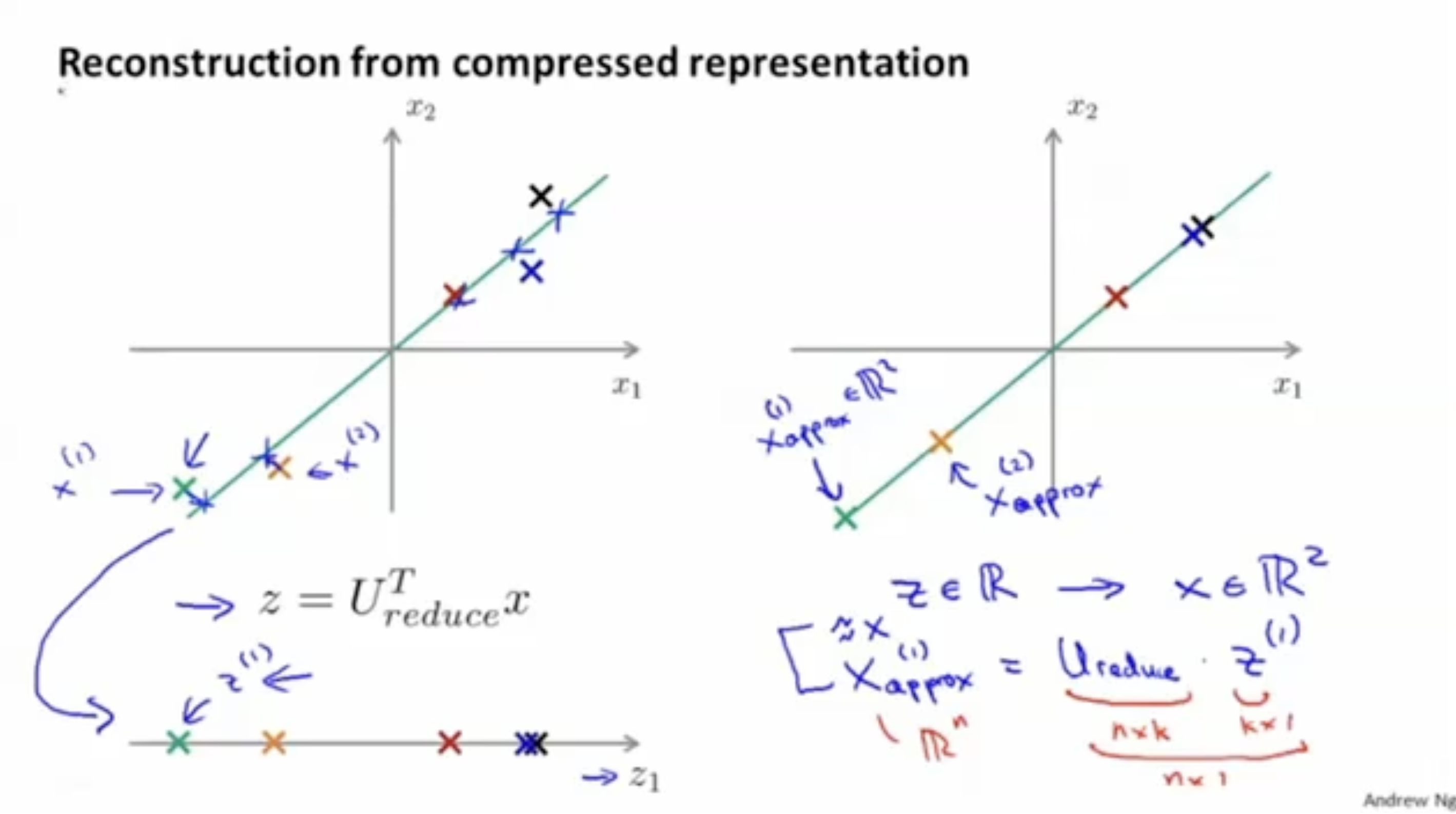
차원으로 축소된 데이터 를 다시 차원 데이터 로 복귀하는 방식은 아래 그림과 같다.
- 에서 양 변에 를 곱하여 를 구한다.
()- 만약 projection error가 작다면, 일 것이다.
그렇다면 어떻게 값을 선택하면 될까. 아래 그림을 보자.
- 우선 평균 projection error 값을 구한다.
- 다음으로 데이터의 전체 variation 값을 구한다.
- 그리고 로 error를 계산하여 차원으로 축소했을 때 데이터가 얼마나 잘 보존되는지를 판단한다.
: 이때 0.01은 0.05, 0.10 등 사용자가 어떻게 정의하느냐에 따라 다르다.- 오차가 0.01보다 작다는 예시에서, 이는 차원으로 축소해도 데이터의 정보가 99%만큼 보존된다는 것을 의미한다.

이를 알고리즘적으로 표현하면 그림의 좌측 부분과 같다.
값은 1부터 시작한다.
1. 위에서 했던 방식으로 차원으로 축소했을 때의 error를 계산한다.
2. 만약 기준값(0.01)보다 크다면 에 1을 더한 후, 위 과정을 반복한다.
3. 만약 기준값(0.01)보다 작거나 같으면 멈춘다. 그리고 해당 값을 최적의 값으로 선택한다.
하지만, 이처럼 연산할 경우 연산 비용도 많이 든다는 단점이 있다.
따라서 우측 그림과 같이 컴퓨터의 함수 를 통해서 계산한다.
1. 를 통해 Diagonal matrix 를 구한다.
2. 연산을 통해 차원으로 축소했을 때의 정확도를 구한다.
3. 를 1부터 시작해서 늘려가며 조건을 만족하는 최솟값 를 찾는다.

최적의 를 찾는 방법을 요약하면 아래와 같다.
- 를 통해 Diagonal matrix 를 구한다.
- 을 만족하는 최솟값 를 찾는다.

이제 PCA를 (un)supervised learning에 적용하는 구체적인 방법을 알아보자.
- m개의 입력 데이터()에 대해서 PCA를 적용하여 차원으로 축소된 데이터 를 구한다.
- 그리고 해당 를 통해 () 데이터셋으로 학습을 한다.
- 여기서 주의할 점이 있는데, PCA를 적용한 데이터로 학습한 모델에 테스트를 진행할 때, 테스트 데이터에도 또한 PCA를 적용하여야 한다는 것이다.

PCA의 활용 예시는 다음과 같다.
- 데이터 압축:
- 메모리 절약, 디스크 절약
- 학습 속도 향상
- 데이터 시각화 (ex. 2차원 데이터 or 3차원 데이터로 시각화)

간혹 PCA를 overfitting을 방지하는 데 사용하는 경우가 있는데, 이는 잘못된 적용이다.
- 보통 overfitting을 방지하기 위해 feature의 차원을 줄이는 것을 생각한다.
- 그리고 PCA는 데이터의 차원을 줄여주기 때문에 PCA를 적용하면 feature의 차원 줄어들어 overfitting을 방지할 수 있다고 생각한다.
- 하지만, 이는 적절하지 않다.
- 그러니 overfitting을 방지하려면 PCA가 아닌 regularization을 적용하면 된다.

그리고 PCA를 바로 적용하지 말고, 우선 raw 데이터로 학습을 해보고 다음과 같은 문제가 발생할 경우 PCA를 적용하는 것을 고려해본다.
- 학습 속도가 너무 느릴 경우 PCA 적용 고려.
- 메모리가 부족할 경우 PCA 적용 고려.

