https://www.youtube.com/watch?v=UqqPm-Q4aMo&list=PLoR5VjrKytrCv-Vxnhp5UyS1UjZsXP0Kj&index=15
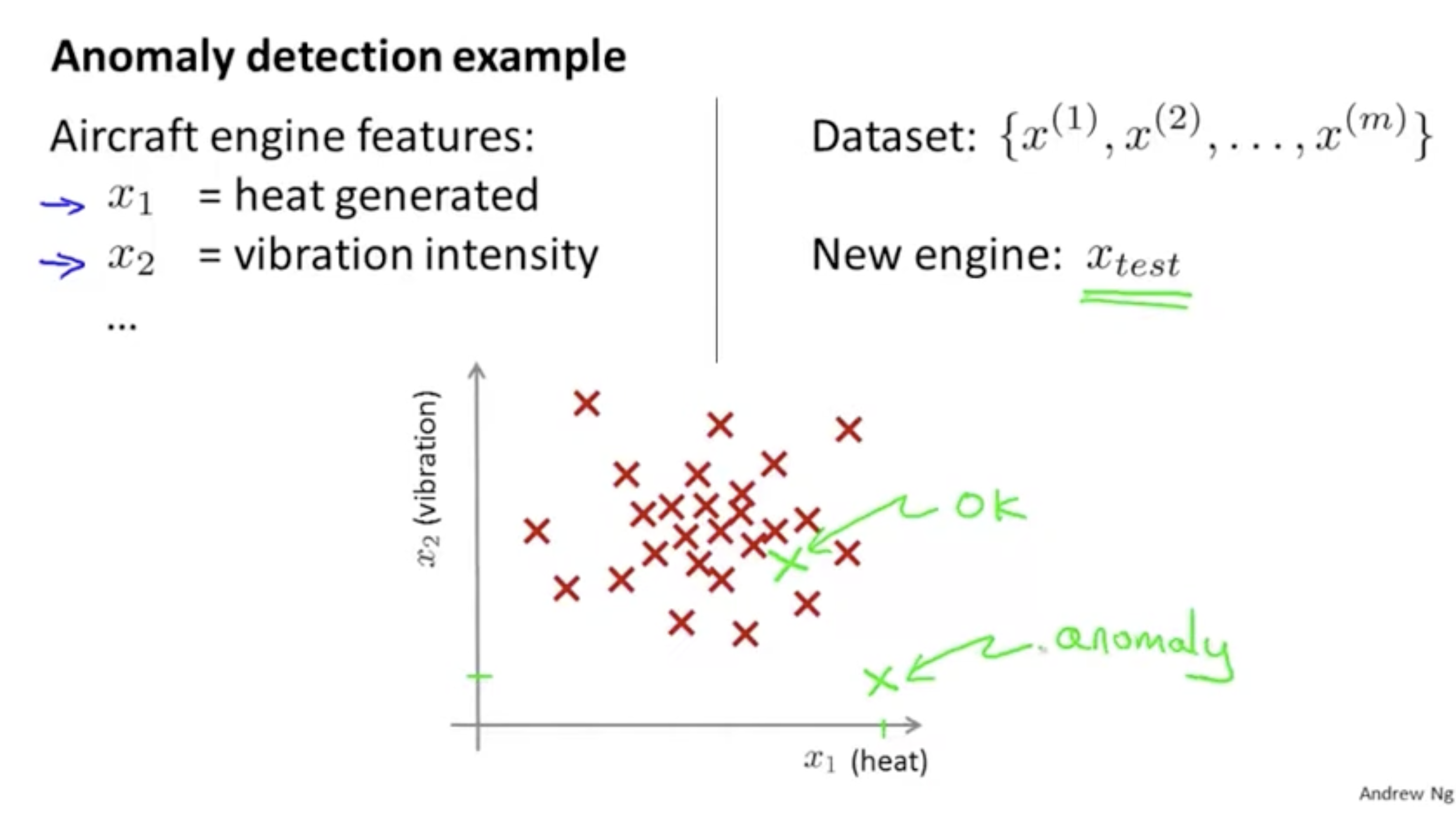
이번 강의에서는 Anomaly Detection(이상 탐지)에 대해서 배운다. 아래 그림을 보자.
항공기 엔진에 대한 features 가 있다.
그리고 이러한 features를 갖는 n개의 데이터셋 을 가지고 있다.
그리고 여기에 새로운 데이터 가 주어졌다. 아래 점들의 분포와 같이,
- 가 다른 데이터들과 유사하게 되어 있다면 이는 정상적인 데이터로,
- 가 다른 데이터들과 멀리 떨어져 있다면 이는 이상 데이터로 판단한다.
- 이러한 과정을 anomaly detection이라고 한다.
그리고 이를 판단하는 기준으로 다음과 같은 수식을 쓴다.
모델 는 입력 데이터 에 대한 probability를 리턴한다.
은 아주 작은 수를 의미한다.
- 만약 에 대한 probability가 매우 낮게 나온다면, 이는 anomaly(이상)으로 판단한다.
- 반면에 에 대한 probability가 기준값을 넘는다면, 이는 정상으로 판단한다.

anomaly detection의 예시를 더 살펴보면 다음과 같다.
- 이상 거래 탐지 : 유저의 행동 features 를 가지고, 이면 이는 이상 거래로 판단한다.
- 제조 공정 이상 탐지 : 기계들의 features 를 가지고, 이면 제조 공정에서 어떤 이상이 있다고 판단한다.

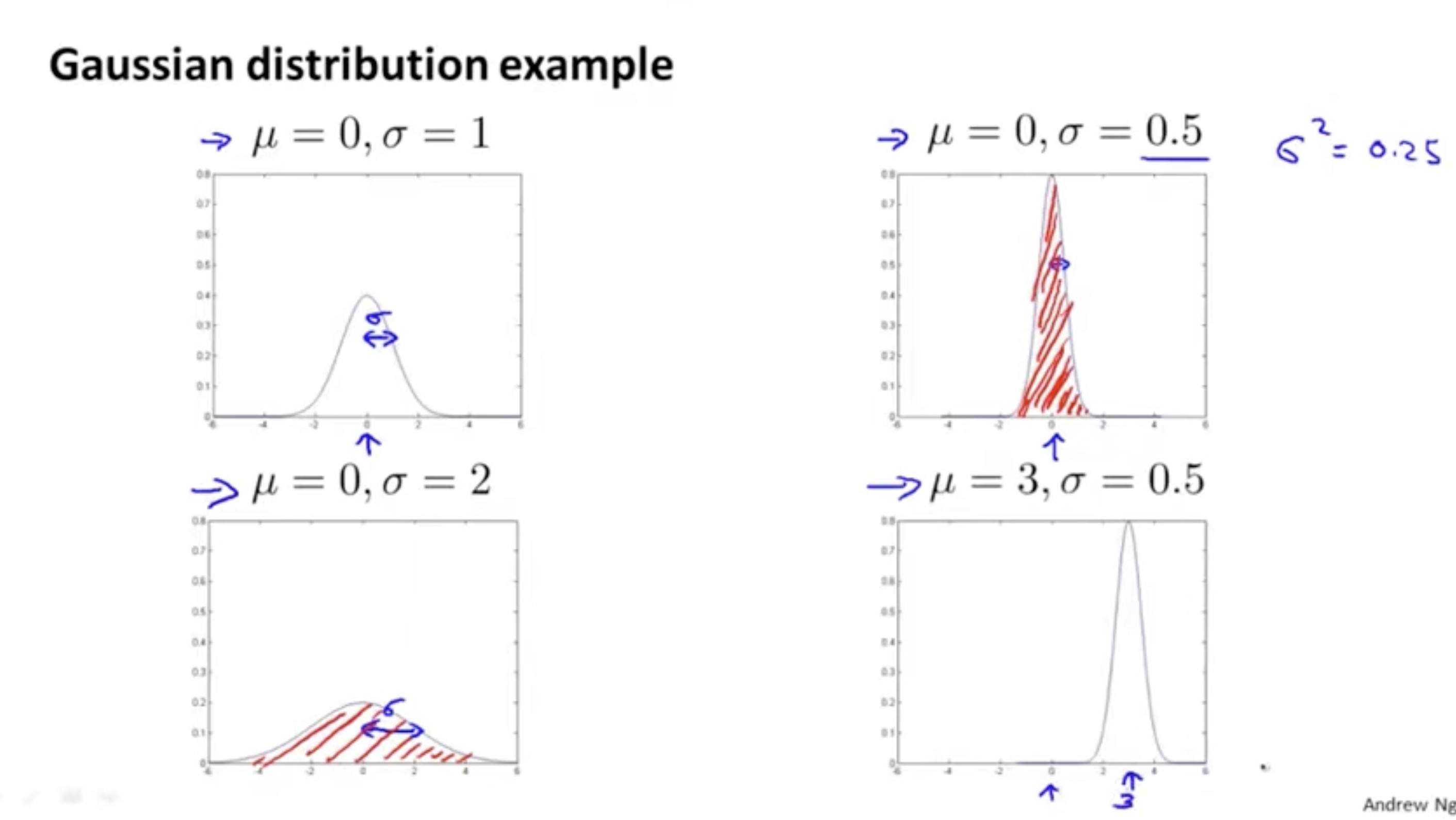
anomaly detection의 원리를 알아보기 전에 먼저 "Gaussian (Normal) Distribution"에 대해서 알아보자. 가우시안 분포(정규 분포)는 아래 그림과 같이 종 모양의 분포를 의미한다.
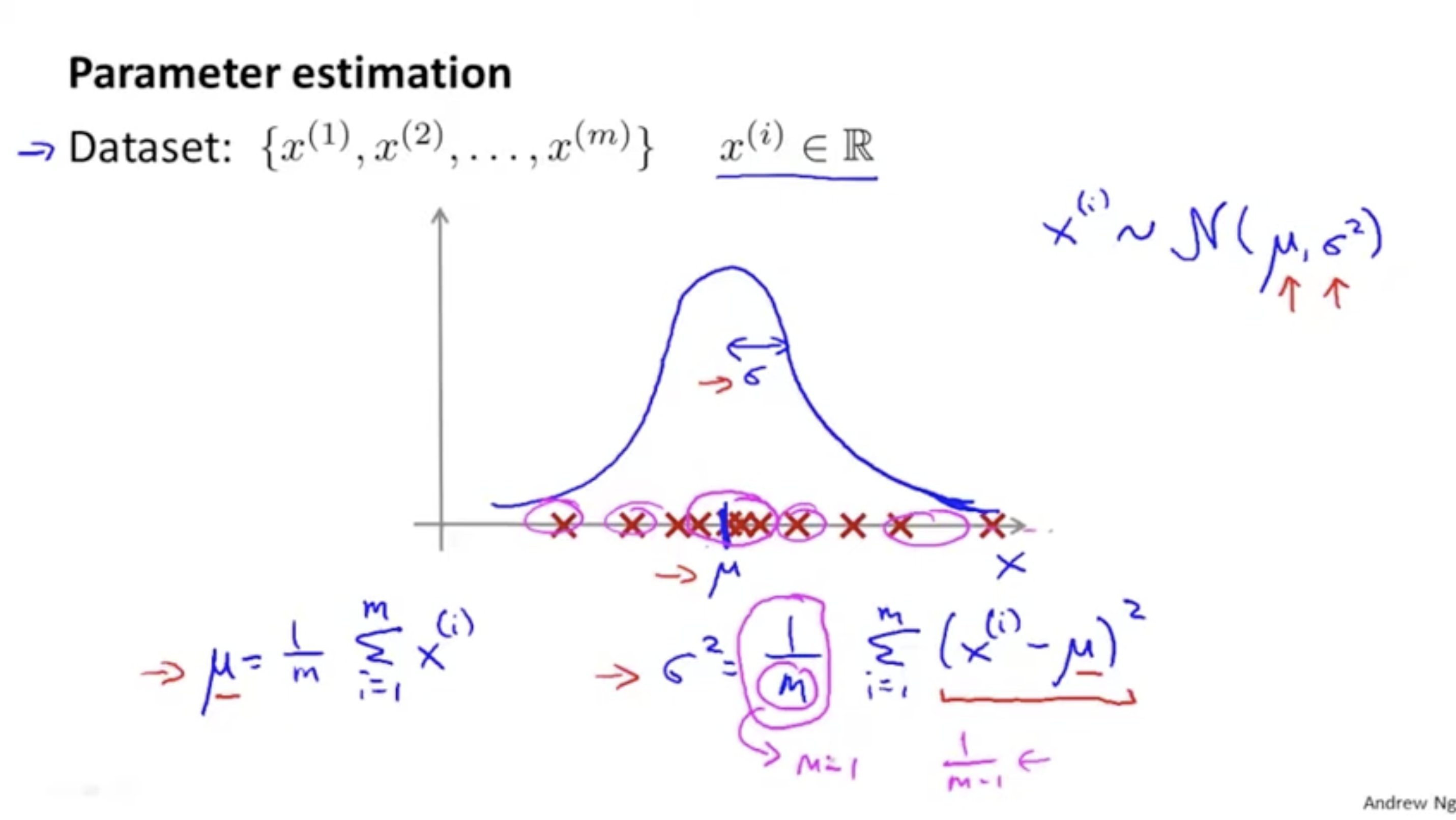
가우시안 분포를 만들기 위해서는 데이터 를 와 로 distribute하면 된다.
수식은 다음과 같다.
- : 데이터셋 를 가우시안(정규) 분포 과 유사하게 만든다.
그리고 이를 위한 평균값과 표준 편차 값은 각각 이다.- : 데이터 에 대해서 평균값 와 분산 에 대해서 가우시안 분포로 적용하는 식.
그리고 공식은 다음과 같다. (외울 필요 x)
- 따라서 데이터셋 를 가우시안 분포로 만들면 아래 그래프와 같을 것이다.

가우시안 분포의 예시는 다음과 같다.
- 평균값 를 중심으로 두고, 표준 편차에 따라 분포가 중심으로 편향되었는지 아니면 넓게 펼쳐져 있는지를 알 수 있다.
- 표준 편차 값이 크다 -> 데이터가 넓은 범위로 분포되어 있다.
- 표준 편차 값이 작다 -> 데이터가 평균값(중심) 위주로 분포되어 있다.
- 그리고 분포의 전체 값을 더하면 1이 나온다. (빨간색 칠한 부분)
그렇다면 (평균값), (분산= 표준편차^2)과 같은 파라미터들은 어떻게 구할 수 있을까? 아래 그림을 보자.
(분산을 구할 때 원래 모집단에 대해서만 을 적용하고 그 외에는 로 적용하는 것이 맞지만,
머신러닝에서는 보통 로 적용하며 로 적용해도 결과에 큰 차이는 없다.
데이터 의 feature 의 가우시안 분포값을 구하면 다음과 같다. (Density estimation)
- 입력 데이터셋 : (총 m개의 데이터셋)
- 데이터 features(columns) (총 n개의 features(columns))
- 데이터 에 대해서 각각의 features 의 가우시안 분포를 구한다.
- 그리고 의 probability 값 를 구한다.
그리고 모든 데이터에 대해서 벡터로 표현하면 아래와 같이 나온다.
- 이렇게 하여 밀도값()을 구할 수 있다.

Anomaly detection의 alg.의 개략적인 내용은 다음과 같다.
1. x의 features 중 anomaly를 잘 나타내는 feature 를 선택한다.
2. parameter 을 fit한다.
3. 새롭게 들어온 데이터 에 대해서 를 계산하여 이면 anomaly로 판단한다.

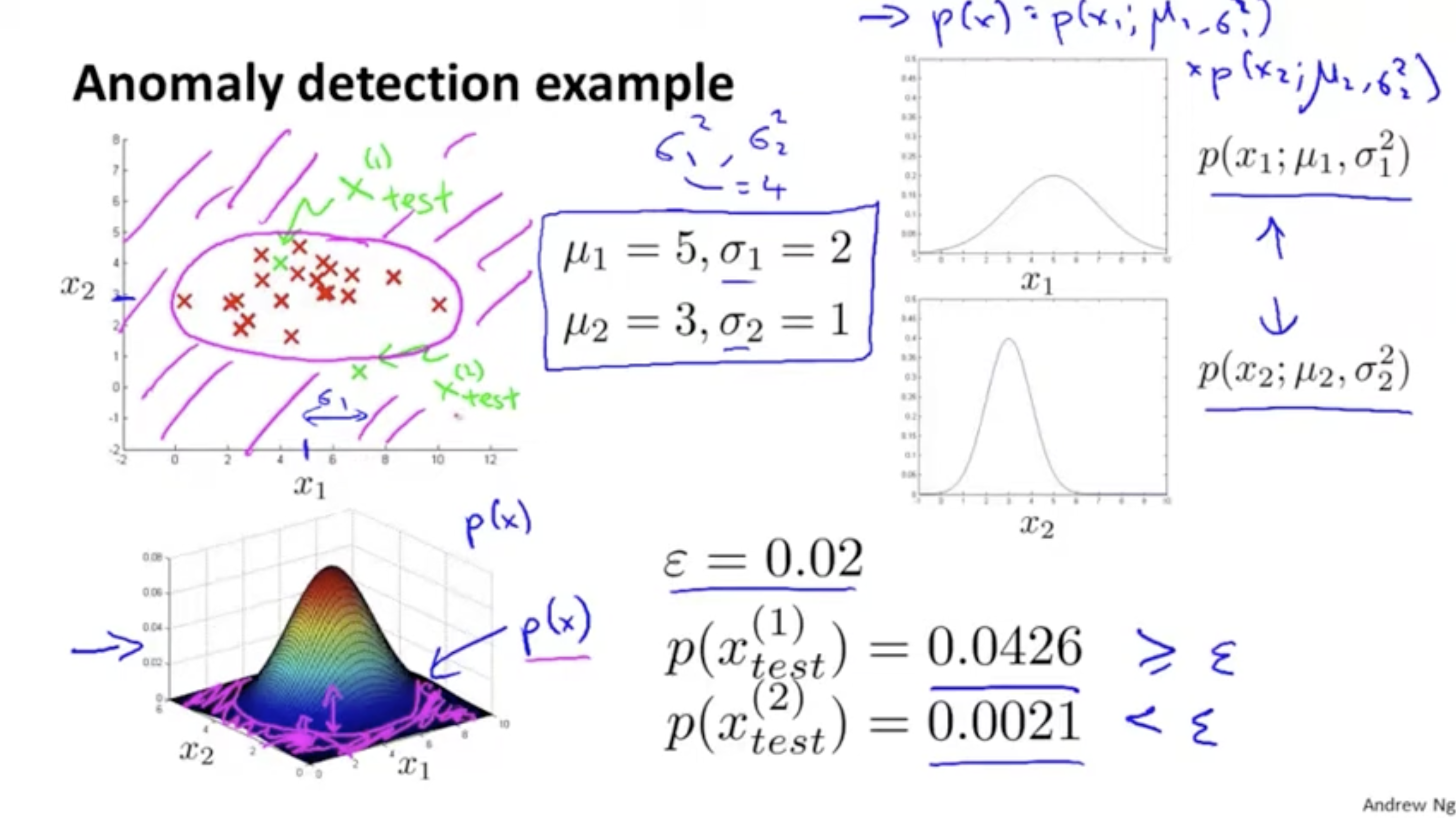
그림을 통한 예시를 보자.
- 좌측 상단 그래프에서 데이터의 분포를 가우시안 분포로 바꿨을 때, feature 에 대한 분포 정보는 이고, feature 에 대한 분포 정보는 이다.
- 그리고 각 feature의 가우시안 분포를 그려보면 우측 그래프와 같이 나온다.
- 위에서 구한 각 feature들의 가우시안 분포에서의 밀도값을 통해 전체 밀도값을 구할 수 있다.
- 예시로 인 상황에서 좌측 상단 그래프처럼 , 데이터가 들어왔다고 해보자.
- 각각 계산한 결과, 으로 은 정상으로, 으로 은 비정상으로 판별된다.
- 정상/비정상 범위를 그래프에 표시해보면 좌측 하단의 그래프처럼 0.02보다 작은 밀도값을 갖는 데이터들은 anomaly로 그 외에는 정상으로 판별될 것이다. (좌측 상단 그래프에서 핑크색으로 칠해진 부분은 anomaly로 내부는 정상으로 판별된다.)
일반적으로 labeled된 데이터 등 학습 모델을 평가할 수 있는 방법이 있는 경우, 더 쉽게 학습 모델을 구축할 수 있다.
- 예를 들어, anomaly에 해당하는 labeled된 데이터가 있다고 가정해보자. ( : normal / : anomaly)
- 그리고 training / cross-validation / test set이 있다. (normal / anomaly로 labeled된)

비행기 엔진에 대한 anomaly detection을 예로 들어보자.
- 10,000개의 정상 데이터와 20개의 비정상 데이터를 가지고 있다.
- 그리고 이 데이터를 training / cross-validation / test set으로 나눈다.
- training set : 6,000개의 정상 데이터.
- cross-validation set : 2,000개의 정상 데이터, 10개의 비정상 데이터.
- test set : 2,000개의 정상 데이터, 10개의 비정상 데이터.
- 가끔씩 CV와 Test에 같은 정상 데이터를 적용하는 경우도 있지만, 그렇게 추천되지는 않는다.

그렇다면 anomaly detection 모델은 어떻게 평가할 수 있을까?
- 우선 학습 데이터셋으로 학습한 모델 가 있다.
- 그리고 cross-validation set과 test set을 이 모델에 적용하여 예측값( or )을 구한다.
- 하지만 단순히 error 값을 기준으로 모델을 평가하기에는 data skew 문제가 존재한다. (일반적으로 anomaly 데이터를 매우 적다.)
- 따라서 위에서 구한 예측값을 기반으로 precision / recall / f1-score 등의 지표를 통해 모델의 정확도를 평가한다.
- 또한, cross validation set을 정상/비정상의 기준값이 되는 parameter 을 선택하는 데 사용할 수 있다.

그런데 이상 데이터를 분류할 때, logistic regression과 같은 supervised learning을 적용하지 않고 왜 Anomaly detection 모델을 적용할까?
이유는 다음과 같다.
- anomaly detection의 경우 (에 해당하는) 이상 데이터의 수가 매우 적고, 에 해당하는 negative 데이터는 많다.
- 반면에, supervised learning의 경우 에 해당하는 positive data와 에 해당하는 negative data 모두 매우 많다.
- 또한, 이상 탐지의 경우 이상의 기준이 데이터의 종류마다 매우 다르다. (예를 들어, 값이 큰 경우가 이상일 수 있거나 혹은 값이 중간이 경우가 이상, 혹은 값이 작은 경우가 이상 등등)
- 그리고 이상 데이터의 경우, 아직 발견되지 않았을 가능성이 높다. (따라서 이게 이상인지 아닌지를 나타내는 label 정보는 모른다.)
- 반면에 supervised learning은 positive/negative의 기준이 명확하다. (값을 기준으로 판단) 따라서 학습 데이터셋만으로도 충분히 positive/negative를 예측하는 모델을 만들 수가 있다. (ex. 스팸 분류)

Anomaly detection과 Supervised learning의 예시를 보면 다음과 같다.
- Anomaly detection : 사기 탐지, 제조 공정, 기계 모니터링
- Supervised learning : 이메일 스팸 분류, 날씨 예측, 암 진단

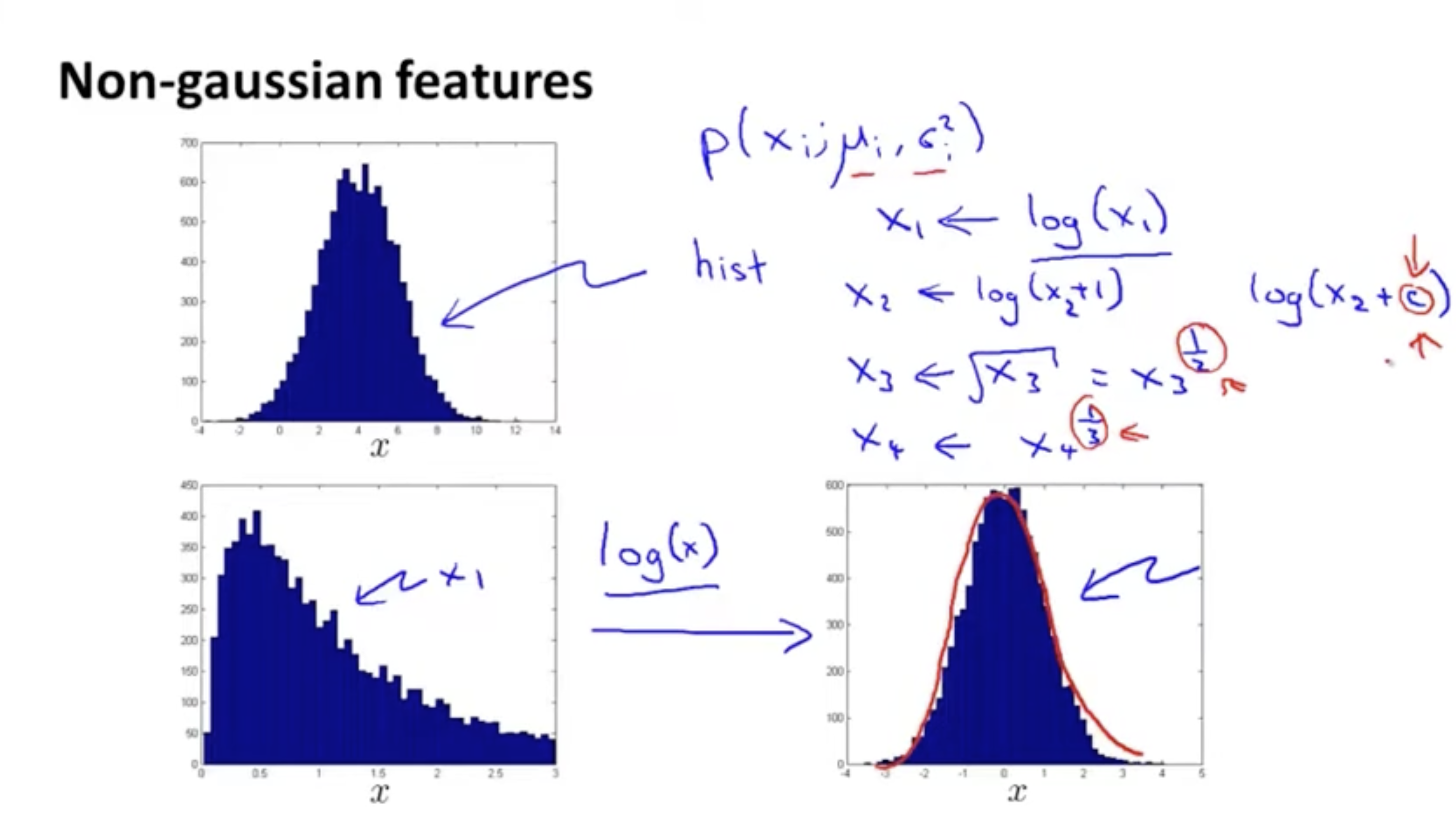
만약 데이터의 분포를 확인했을 때, 좌측 하단과 같이 가우시안 분포와 많이 다르다면 와 같은 함수를 통해서 이를 우측 하단과 같이 가우시안 분포에 유사한 분포로 만들어 주면 된다.
- 이러한 함수는 종류가 매우 다양하다.
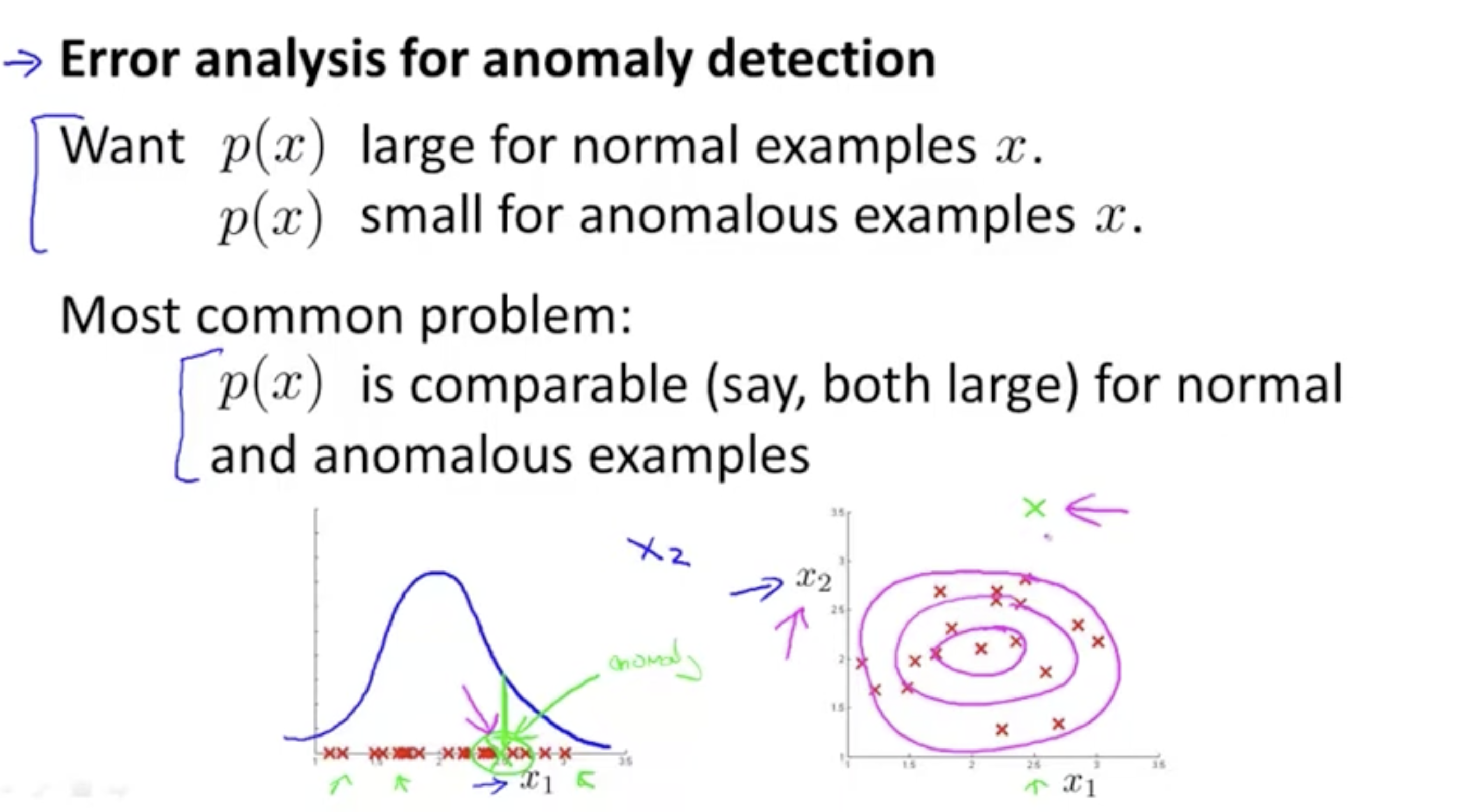
anomaly detection에서 모델은 다음과 같은 방향으로 학습할 것이다.
- 정상 데이터 에 대해서는 값이 높게 나오도록,
- 비정상 데이터 에 대해서는 값이 낮게 나오도록 학습한다.
- 그리고 하단 그림과 같이 feature 에서는 anomaly detect가 안 되는 데이터에 대해서 feature 를 추가하여 anomaly를 판별할 수 있는 방법이 있다.
- 이처럼 anomaly를 detect할 수 있는 feature를 찾는다.
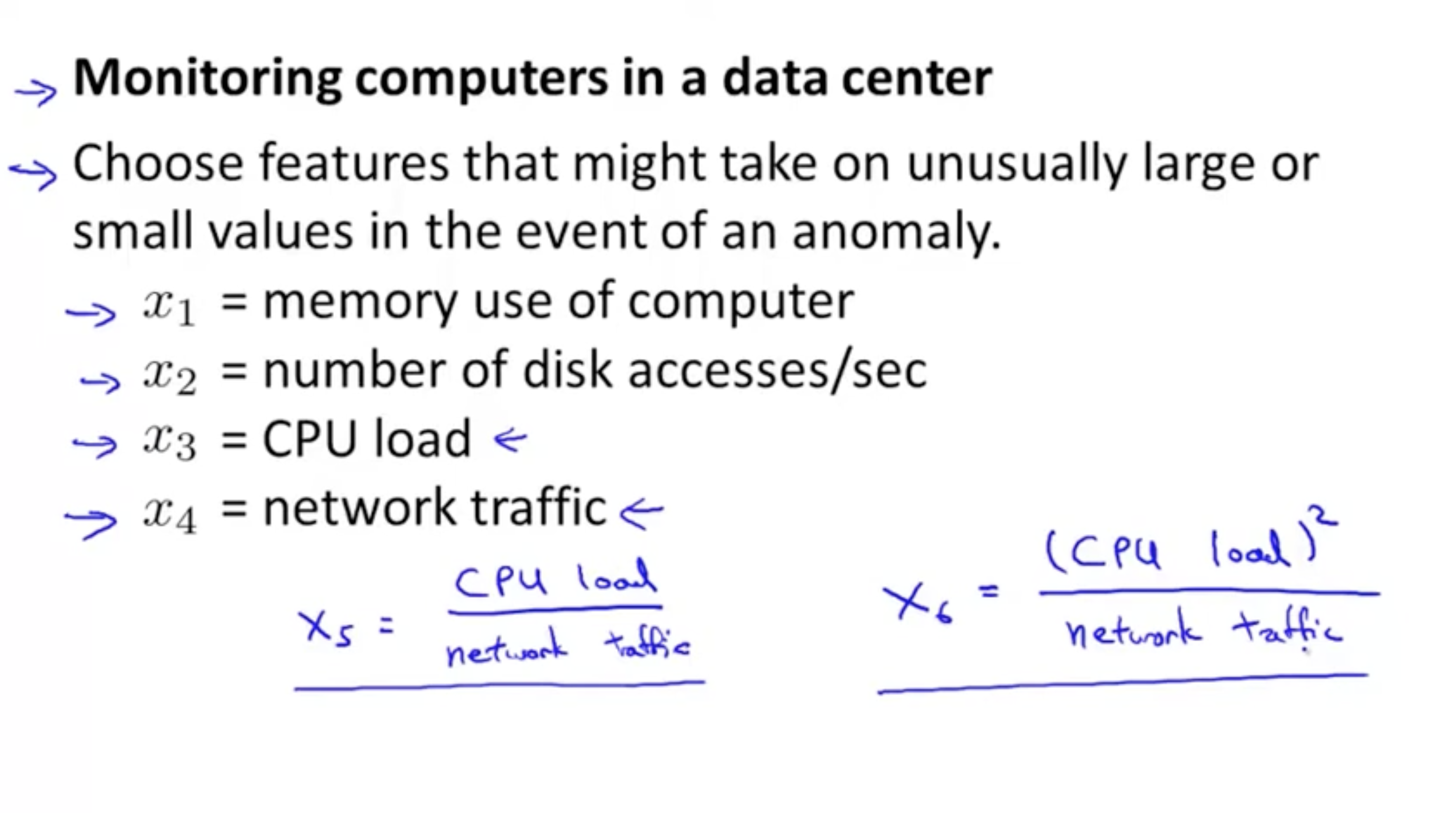
데이터 센터에서 컴퓨터 모니터링을 하는 예시를 보자.
- 비정상 데이터에서 값이 너무 작거나 너무 큰 데이터를 갖는 feature를 선택한다.
- 그리고 feature들의 종류는 아래와 같이 다양하게 존재한다.
- feature들을 조합하여 새로운 feature를 정의할 수도 있다. (ex. )
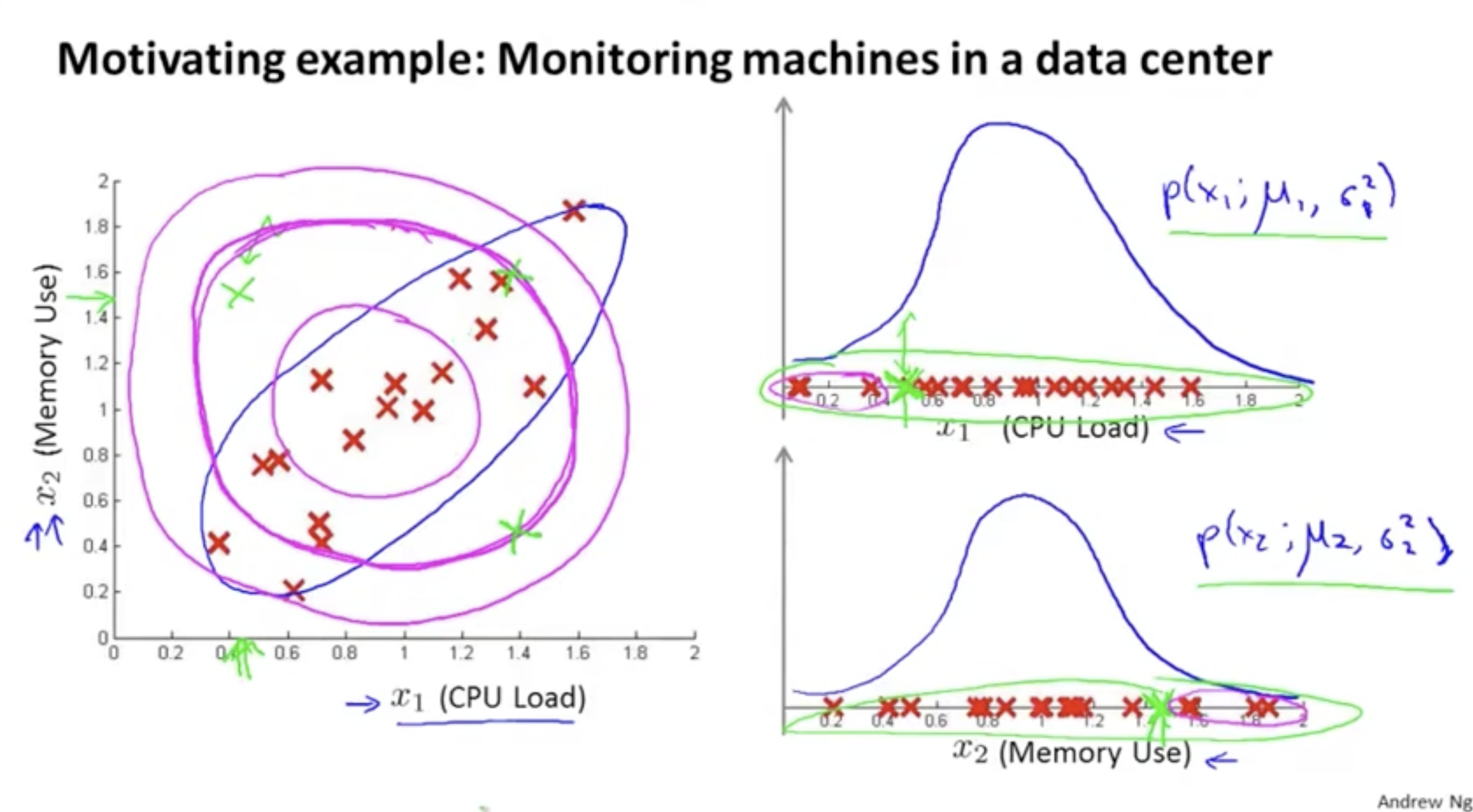
하지만 특정 feature들을 선택해도 anomaly가 제대로 나타지 않는 경우가 있을 수 있다.
- 좌측 그림처럼 여러 개의 feature를 조합한 분포에서 초록색에 해당하는 anomaly 데이터는 적절한 분포 내에 존재하고 있다. 따라서 anomaly로 판단하기 힘들다.
- 또한, 우측 그림처럼 각각의 feature를 기준으로 봤을 때도 초록색 데이터는 적절한 분포 내에 존재하고 있음을 알 수 있다.
- 그렇다면 이러한 경우 어떻게 anomaly detection을 해야할까?
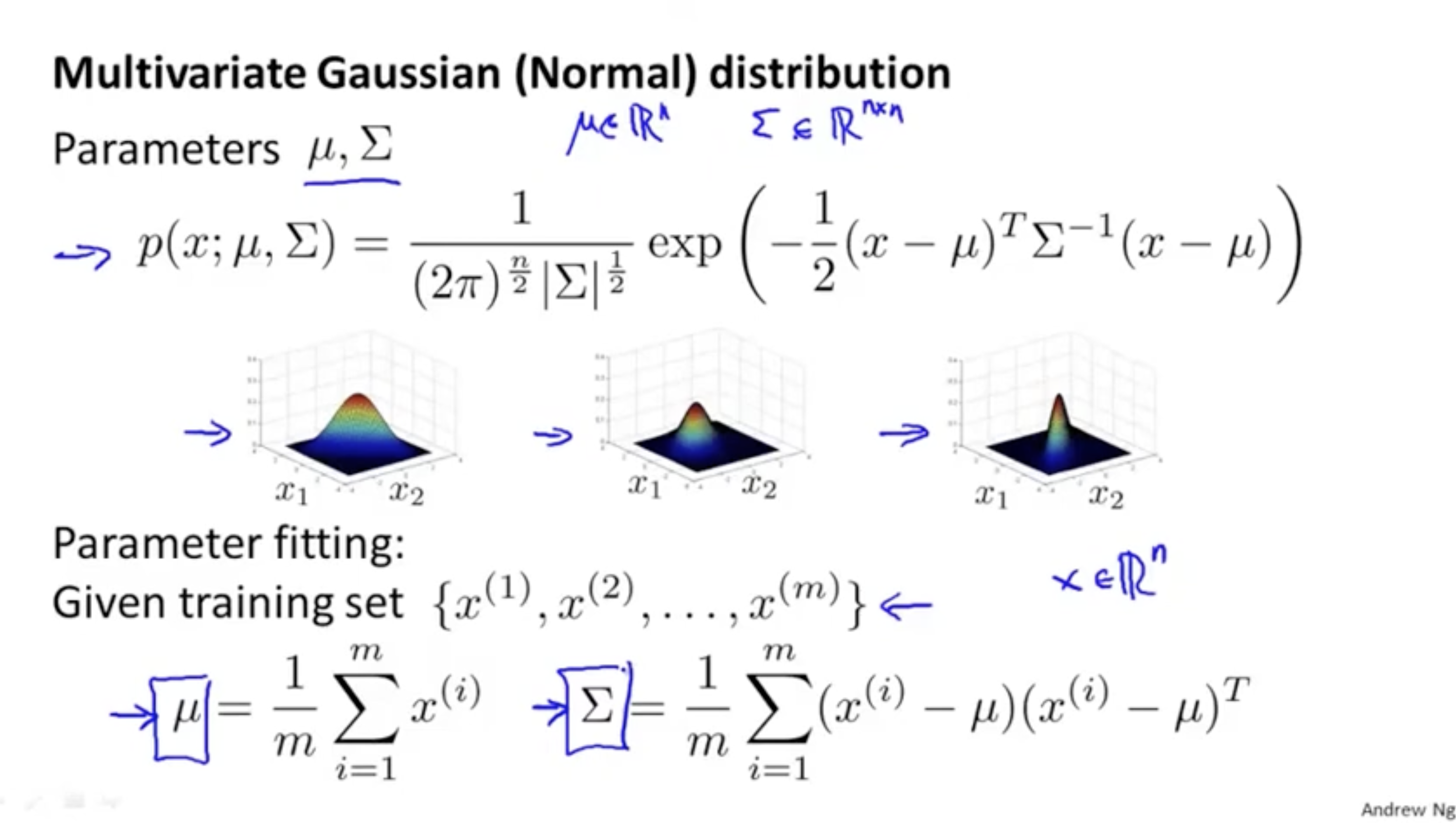
이를 위해 필요한 방법이 "Multivariate Gaussian (Normal) distribution"이다.
- 기존의 가우시안 분포는 각각의 feature(column)에 대해서 각 가우시안 분포를 구했지만,
- multivariate gaussian distribution은 전체 features에 대한 가우시안 분포를 구한다.
(이를 위해 전체 평균값 벡터 와 공분산 matrix 를 구한다.)

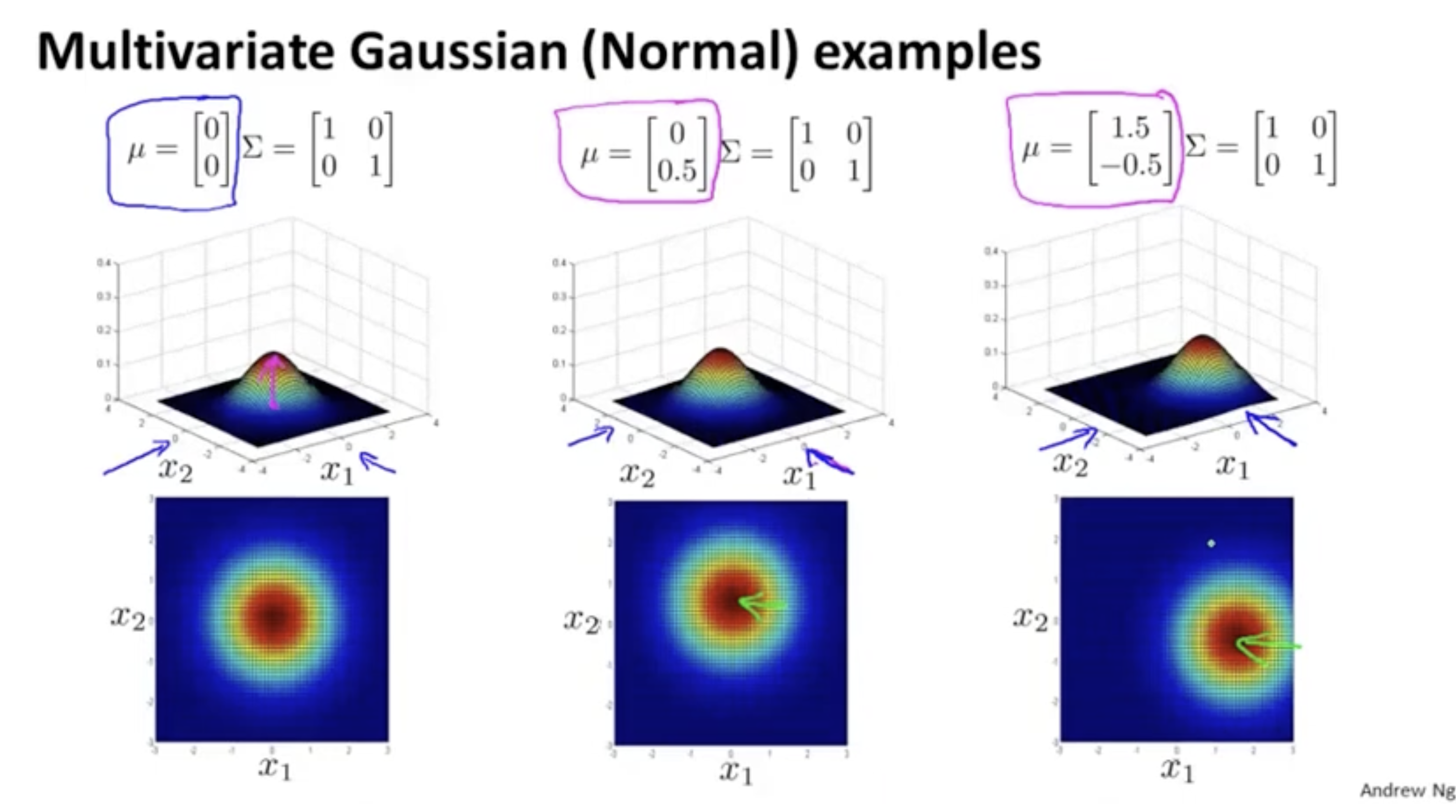
multivariate gaussian distribution을 그리면 아래와 같다.
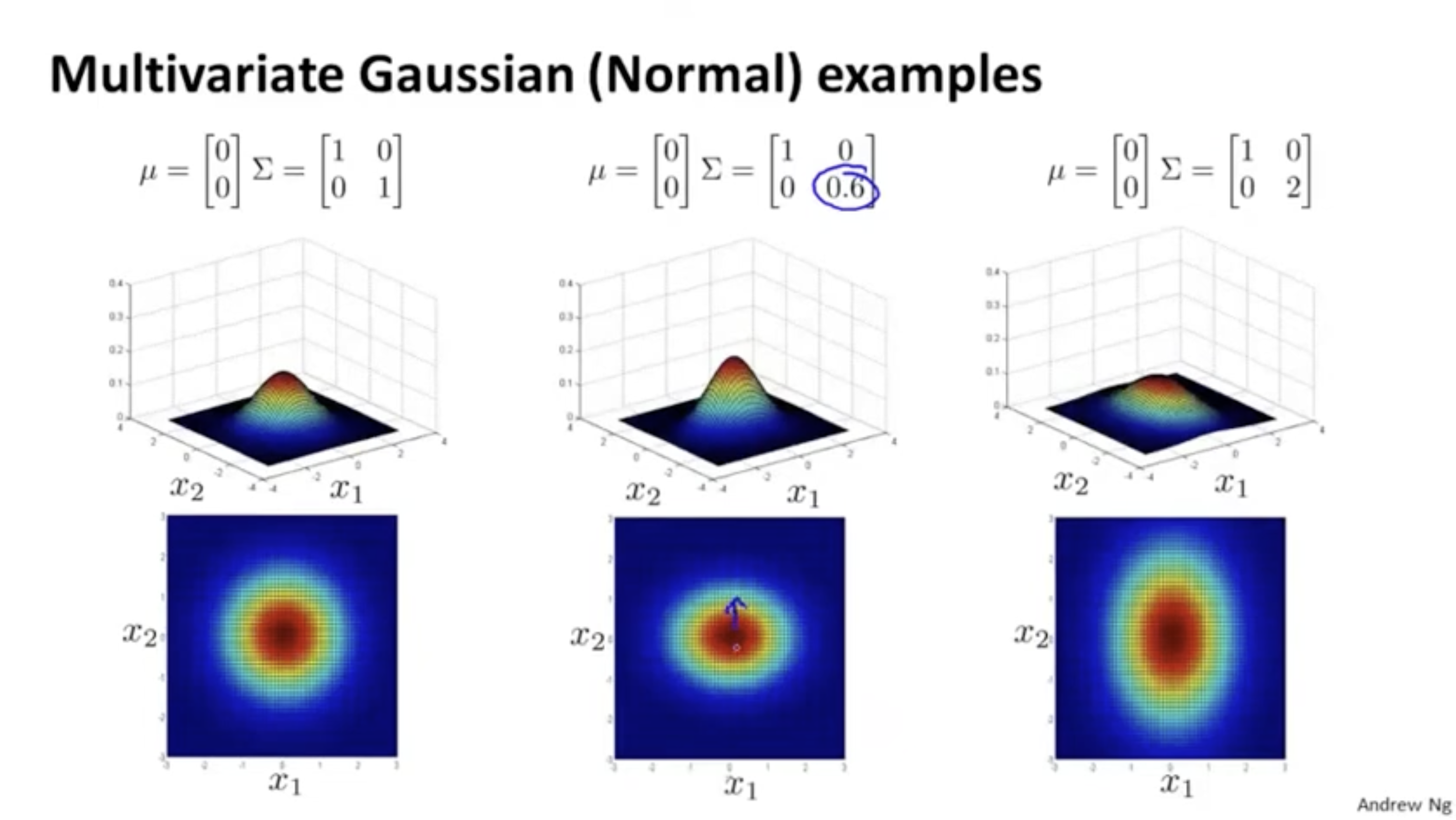
- covariance matrix 의 대각 성분 값에 따라 각 feature의 표준 편차가 정해진다.
- 표준편차 값이 작을수록 가파르고, 클수록 완만한 모양을 띈다.
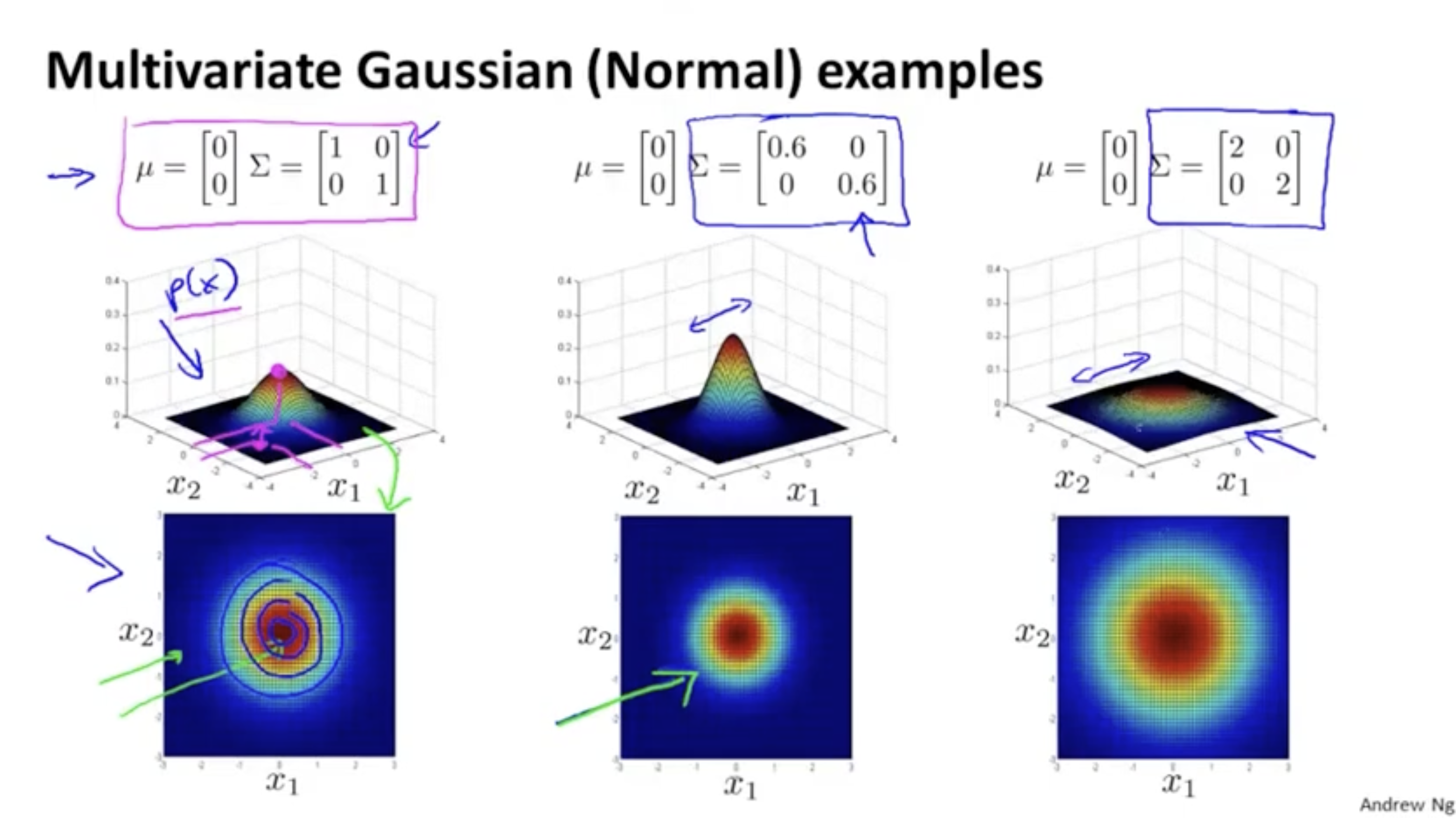
특정 feature의 표준편차에 따라 다양한 모양이 존재한다.
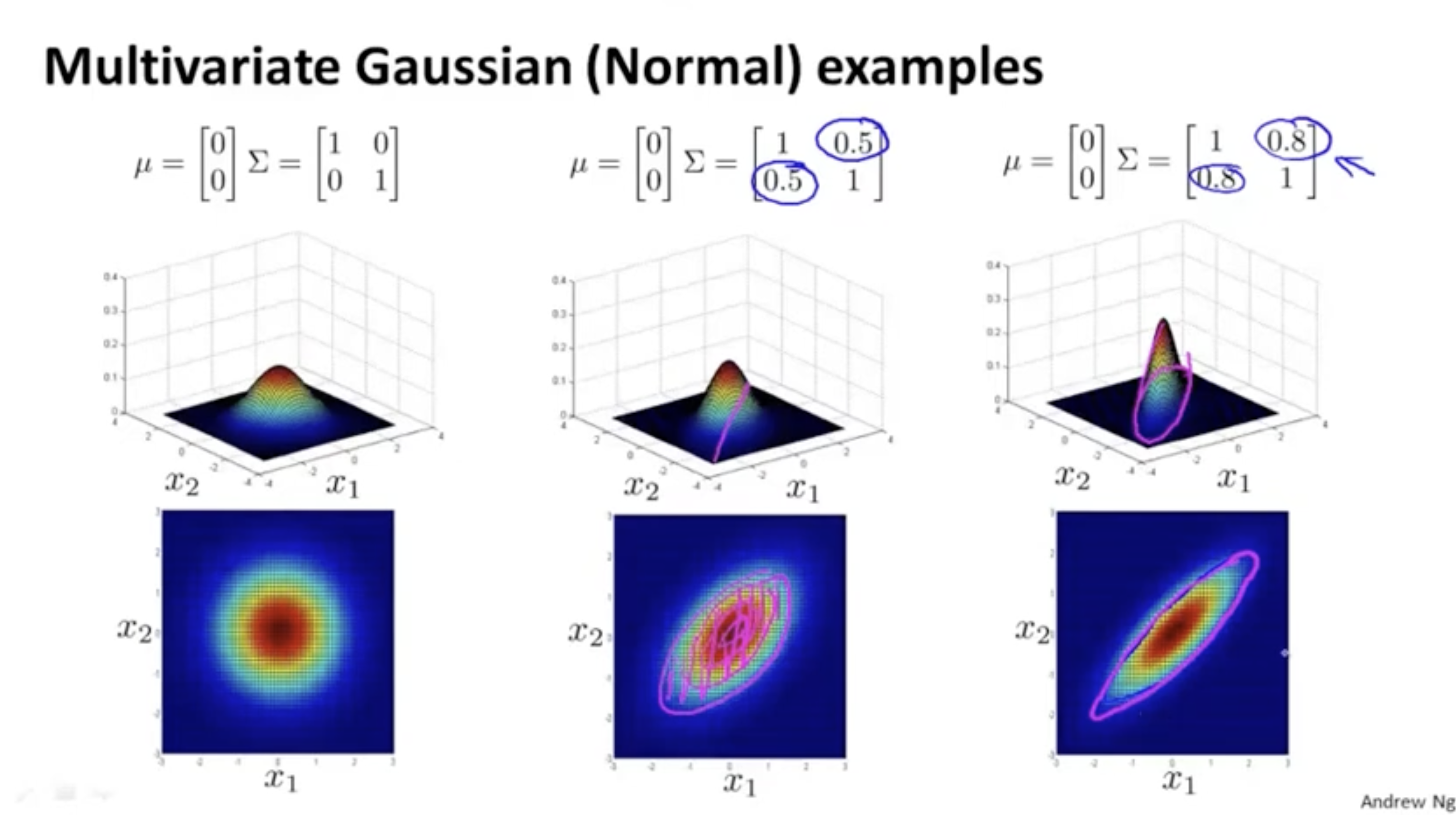
또한, covariance matrix 의 다른 대각 성분 값을 통해 feature 간의 correlation을 표현할 수 있다.
- 아래 두 번째 및 세 번째 그림과 같이 과 가 비례하는 분포를 볼 수 있다.
- 그리고 이 값이 클수록 가파른 모양을 보여 준다.
아래 두 번째 및 세 번째 그림은 두 feature 가 음의 방향으로 비례하는 모습을 보여주는 분포이다.
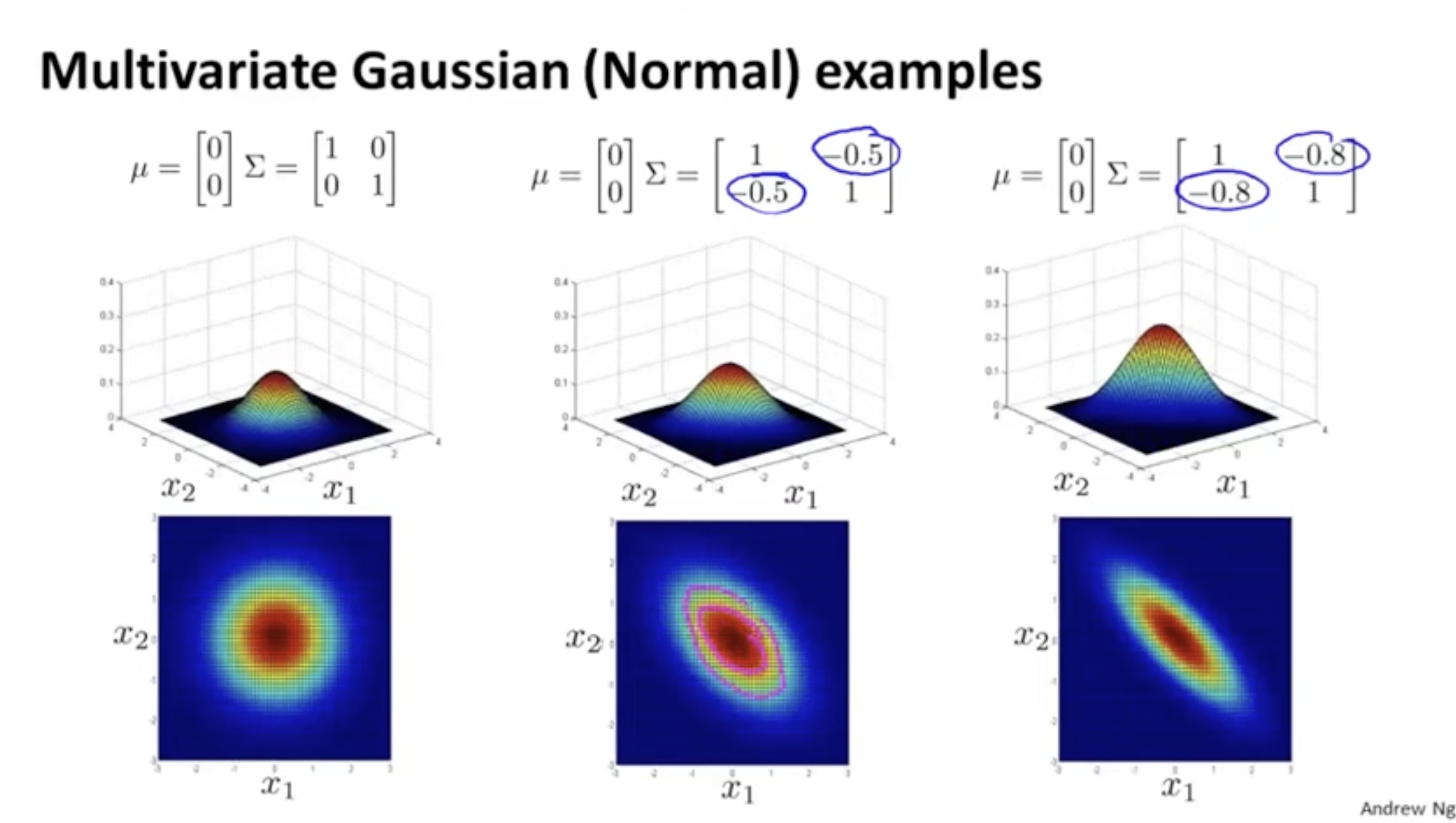
또한, 평균값 에 따라 분포 위치가 바뀔 수 있다.
그러면 mulitivariate gaussian distribution의 방법을 정리해보자.
- 파라미터 와 를 구한다.
- 를 통해 전체 데이터셋 에 대한 가우시안 분포를 구한다.
(구체적인 수식은 아래를 참고)
따라서 최적의 와 를 가지고 모델 를 구한 후, 새로운 데이터 에 대해서 이면 anomaly로 판단한다.
multivariate gaussian distribution의 경우 우측 그래프처럼 분포가 나올 것이고, 초록색 anomaly data에 대해서 이상 데이터로 판별할 것이다.

원래의 gaussian distribution 모델은 각 feature들의 가우시안 분포를 곱한 방식을 택했다. 반면에, multivariate gaussian distribution은 전체 features에 대한 가우시안 분포를 고려한다.
- multivariate gaussian distribution에서 covariance matrix 의 주대각 성분들은 각 feature의 분산을 의미한다.
- 이에 따라 만약 multivariate gaussian distribution에서 주대각 성분을 제외한 나머지 값이 0이라면 이는 기존의 (각 feature를 나눠서 가우시안 분포를 구한 후 곱하는) gaussian distribution과 같은 결과가 나올 것이다.

기존 방법과 multivariate gaussian을 비교 정리하면 아래와 같다.
- 가우시안 분포 함수:
- 기존 방법의 가우시안 분포 :
- multivariate :
- features들의 조합
- 기존 방법 : 수동적으로 feature들을 조합해야 함.
- multivariate : 자동으로 feature 간의 correlations를 설정함.
- 계산 비용
- 기존 방법 : 비교적 저렴함.
- multivariate : 높은 연산 비용.
- 구현 조건
- 기존 방법 : training set의 크기 이 작아도 괜찮음.
- multivariate : 무조건 (학습 데이터셋 크기 feature 차원)을 만족해야 하며 (일반적으로 은 만족해야 함.), covariance matrix 는 invertible해야 함.

