우선 reocommender system이 무엇인지 살펴보자. 아래 그림을 보자.
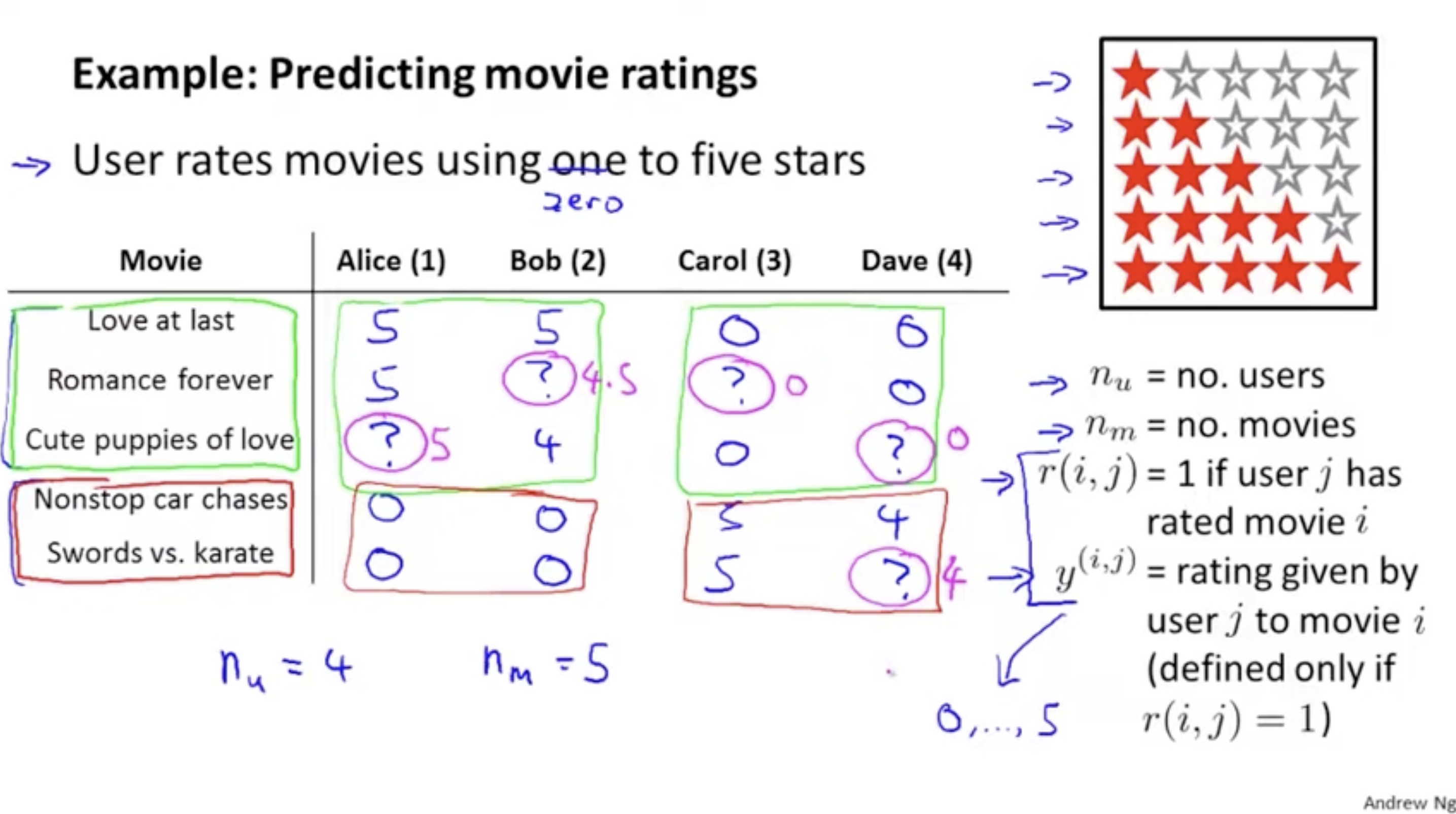
유저들은 관람한 영화에 대한 0~5점의 평점을 매겼고, 그 데이터는 아래와 같다.
총 유저 수는 4이고, 영화 종류 수는 5이다.
그리고 각 유저의 평가한 영화 평점을 기반으로, 각 유저가 아직 보지 않은 영화에 대한 평점을 예측할 수 있다.
예를 들어, Alice는 Love at last와 Romnace forever에 높은 평점을 주었지만, Nonstop car caseses와 Swords vs. karate에는 낮은 평점을 주었다. 그리고 다른 유저들의 영화 평점을 살펴 보니, Love at last와 Romance forever 그리고 Cute puppies of love에 높은 평점을 준 유저들은 Nonstop car chases와 Swords vs. karate에는 낮은 평점을 준다는 것을 알 수가 있다.
따라서 이러한 유저들의 평점을 가지고 모델을 학습하여, 어떤 유저가 아직 보지않은 영화에 대한 유저의 평점을 예측할 수 있다.
그리고 이러한 추천 시스템을 "Content-based recommender system"이라고 한다.
먼저 notation을 정리해보자.
nu : # of users. =4
nm : # of movies. =5
x(i) : movie i's features. x(i)=⎣⎢⎢⎡x0(i)x1(i)x2(i)⎦⎥⎥⎤ (x0(i)=1)
θ(j) user j's parameter vectors. θ(j)=⎣⎢⎢⎡θ0(j)θ1(j)θ2(j)⎦⎥⎥⎤
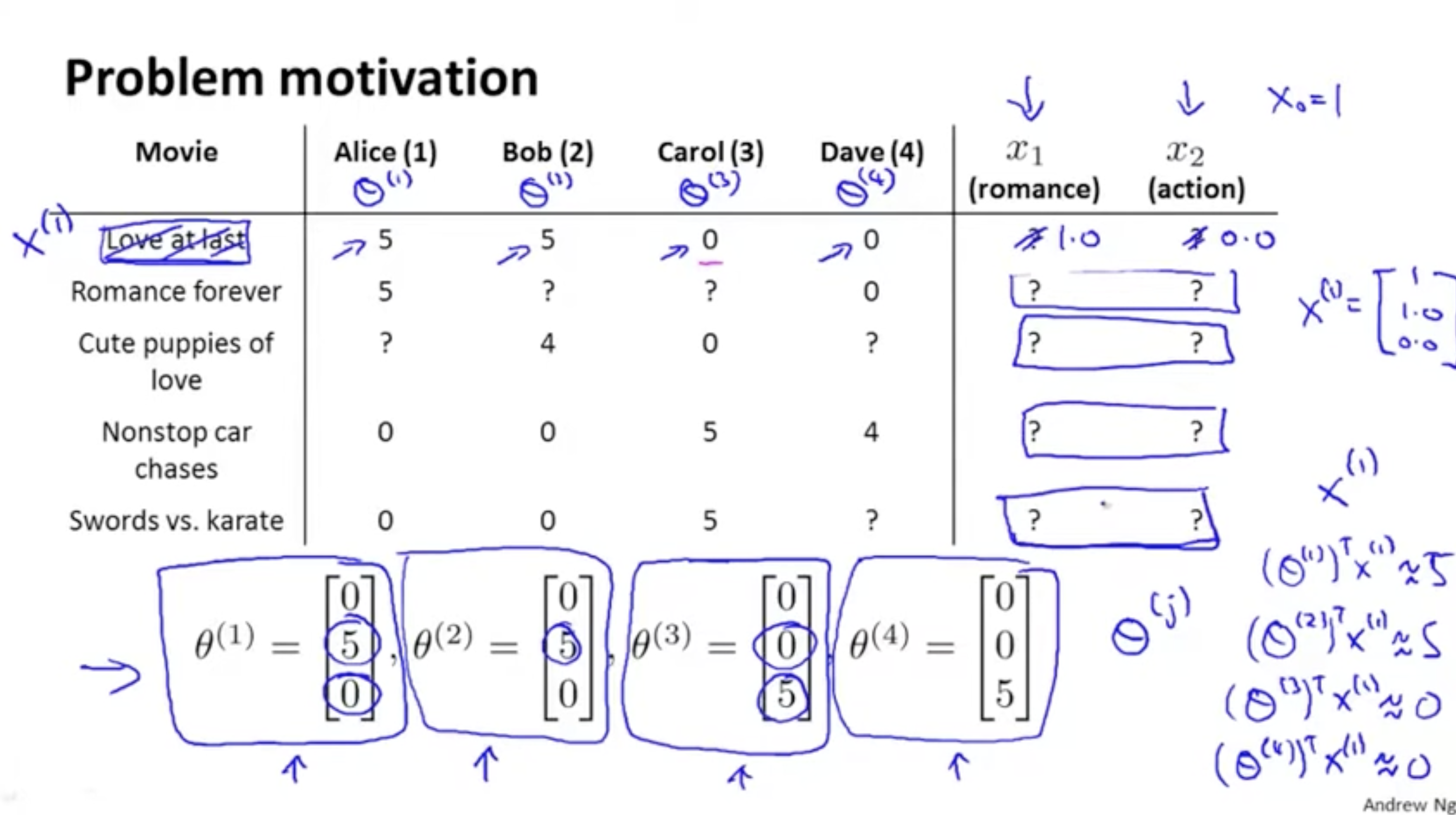
따라서 아래에서 Alice의 Cute puppies of love 영화에 대한 평점을 예측하려면 아래와 같이 계산할 수 있다.
Cute puppies of love의 feature vector : x(3)=⎣⎢⎡10.990⎦⎥⎤
Alice의 영화에 대한 parameter vector : θ(1)=⎣⎢⎡050⎦⎥⎤
(θ(1))Tx(3)=0.99×5=4.95
따라서 Alice의 Cute puppies of love에 대한 평점은 4.95점일 것이다.
그렇다면 이를 공식으로 작성해보자.
r(i,j)=1 : 유저 j가 영화 i에 평을 남긴 경우. (평이 없을 경우 r(i,j)=0)
y(i,j) : 유저 j가 영화 i에 매긴 평점.
θ(j) : 유저 j의 prameter vector. ∈Rn
x(i) : 영화 i의 feature vector. ∈Rn
(θ(j))T(x(i)) : 유저 j의 영화 i에 대한 예측 평점.
m(j) : 유저 j가 평을 남긴 영화 수.
위 notation을 가지고 linear regression의 optimzie function을 다음과 같이 작성할 수 있다.
θkj:=θkj−α(∑i:r(i,j)=1((θ(j))Tx(i)−y(i,j))xk(i)+λθk(j)) (for k=1)
이처럼 각 영화의 feature 정보(romatinc, action)가 주어지고, 이를 기반으로 평점을 예측하고 추천하는 것을 content-based recommender system이라고 한다. 하지만 모든 영화에 대해서 이러한 feature를 갖고 있기는 쉽지 않다. 따라서 이를 위해 not content-based인 "collaborative filtering" 기술이 필요하다.
영화 평점 데이터 중, 영화의 feature x(i)는 주어지지 않고 유저의 parameter vecotr θ(j)만 주어졌다고 해보자.
x(1)의 x1, x2 값은 모르는 상태로 시작한다.
그리고 각 유저의 x(1)에 대한 평점과 각 유저의 parameter θ(1),θ(2),θ(3),θ(4)를 가지고 x(1)의 값을 예측해보자.
(θ(1))Tx(1)≈5
(θ(2))Tx(1)≈5
(θ(3))Tx(1)≈0
(θ(4))Tx(1)≈0
예측 결과, 아마도 x(1)=[1.00]과 같이 나올 것이다.
이처럼 유저의 파라미터 θ를 가지고 각 영화의 feature x를 구할 수가 있다.
optimization 방법도 앞서 봤던 θ를 학습하는 방법과 유사하다. 이전에서는 x가 주어지고 θ를 예측해야 했다면, 이번에는 θ가 주어지고 x를 예측하면 된다. 따라서 다음과 같이 수식을 정리할 수 있다.
영화 feature vector x 정보가 있다면 이 정보를 가지고 유저 parameter vector θ를 학습하고,
유저 parameter vector θ가 있다면 영화 feature vector x를 학습한다.
그리고 닭이 먼저냐 달걀이 먼저냐 처럼, 만약 둘 중 아무것도 주어지지 않는다면 아래와 같이 수행한다.
처음에 θ를 랜덤하게 선택한다. (유저들이 어떤 영화를 좋아하는지 모름.)
다음으로 θ에 대해서 영화 feature x를 예측한다.
영화 feature x를 가지고 유저 parameter θ를 예측한다.
유저 parameter θ를 가지고 영화 feature x를 예측한다.
영화 feature x를 가지고 유저 parameter θ를 예측한다.
유저 parameter θ를 가지고 영화 feature x를 예측한다.
...
아마 유저가 영화를 보고 평을 남기거나 본인의 선호도를 입력하면, 데이터가 쌓이면서 위 과정이 더 효과적으로 학습될 것이다.
그리고 각각의 optimization function을 다음과 같이 하나로 통합할 수 있다.
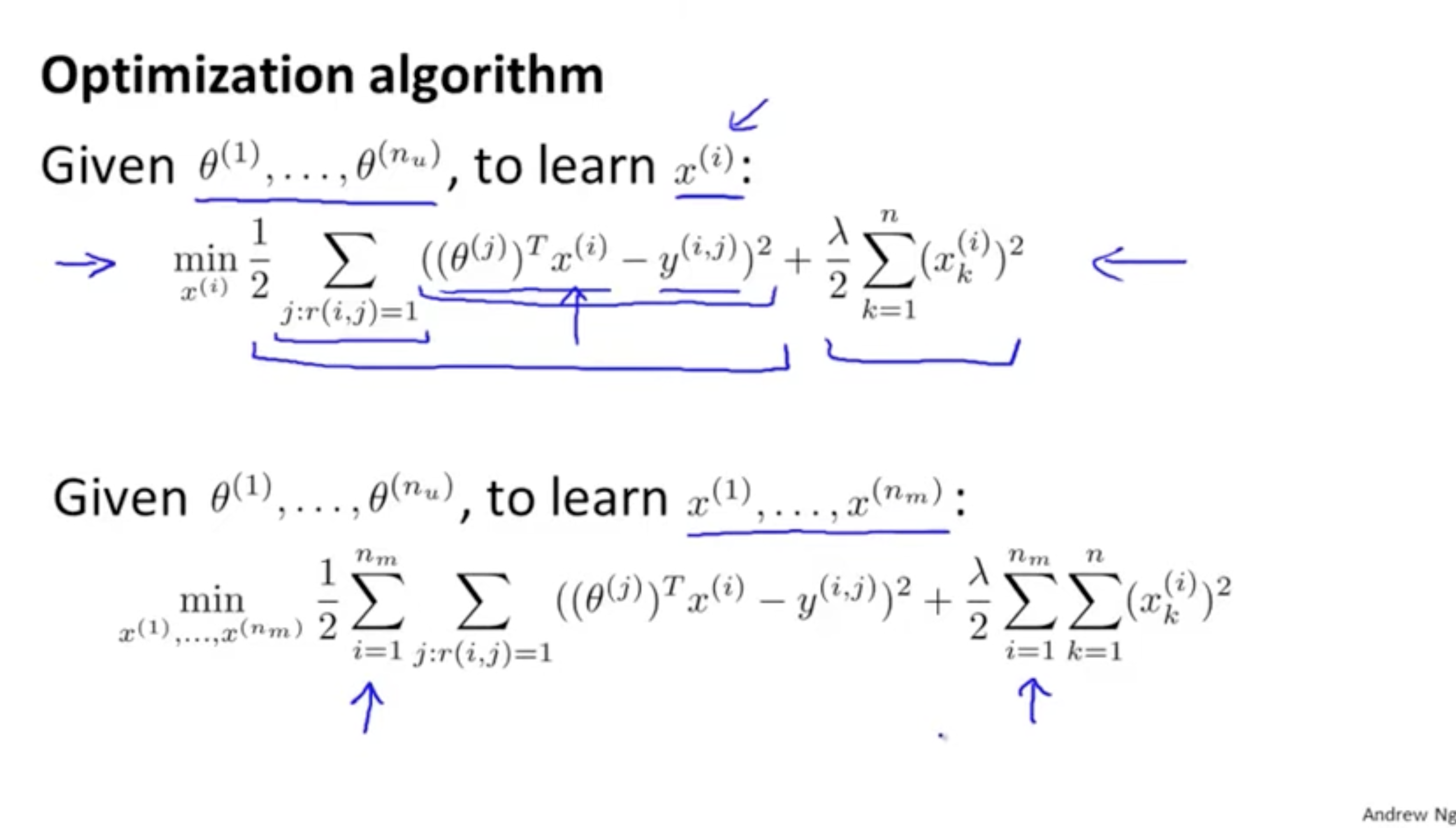
θ가 주어지고 x를 예측할 때 : x(1),...,x(nm)min21∑i=1nm∑i:r(i,j)=1((θ(j))Tx(i)−y(i,j))2+2λ∑i=1nm∑k=1n(xk(i))2
x가 주어지고 θ를 예측할 때 : θ(1),...,θ(nu)min21∑j=1nu∑i:r(i,j)=1((θ(j))Tx(i)−y(i,j))2+2λ∑j=1nu∑k=1n(θk(j))2
그리고 자세히 보니 두 cost function이 동일함을 알 수가 있다. (((θ(j))Tx(i)−y(i,j))2)
따라서 두 케이스를 모두 고려한 다음과 같이 cost function을 정리할 수 있다. J(x(1),...,x(nm),θ(1),...,θ(nu))=21∑i:r(i,j)=1((θ(j))Tx(i)−y(i,j))2+2λ∑i=1nm∑k=1n(xk(i))2+2λ∑j=1nu∑k=1n(θk(j))2
∴x(1),...,x(nm),θ(1),...,θ(nu)minJ(x(1),...,x(nm),θ(1),...,θ(nu))
(한가지 주의점이 있다면, x,θ∈Rn이라는 점이다. 기존에는 θ0=1때문에 1차원이 더 많았지만, x0은 1이라는 보장이 없기 때문에 이 부분을 제외하여 n차원이 된다.)
따라서 Collaborative filtering alg.을 정리하면 아래와 같다.
1. 영화 feature vector x와 유저 parameter vector θ를 랜덤하게 초기화한다.
2. gradient descent alg.을 이용하여 cost function J(x(1),...,x(nm),θ(1),...,θ(nu))을 최소화하는 x(1),...,x(nm),θ(1),...,θ(nu)을 찾는다.
3. 위 과정으로 학습한 parameter θ와 feature x를 가지고 평점 θTx를 계산하여 예측한다.
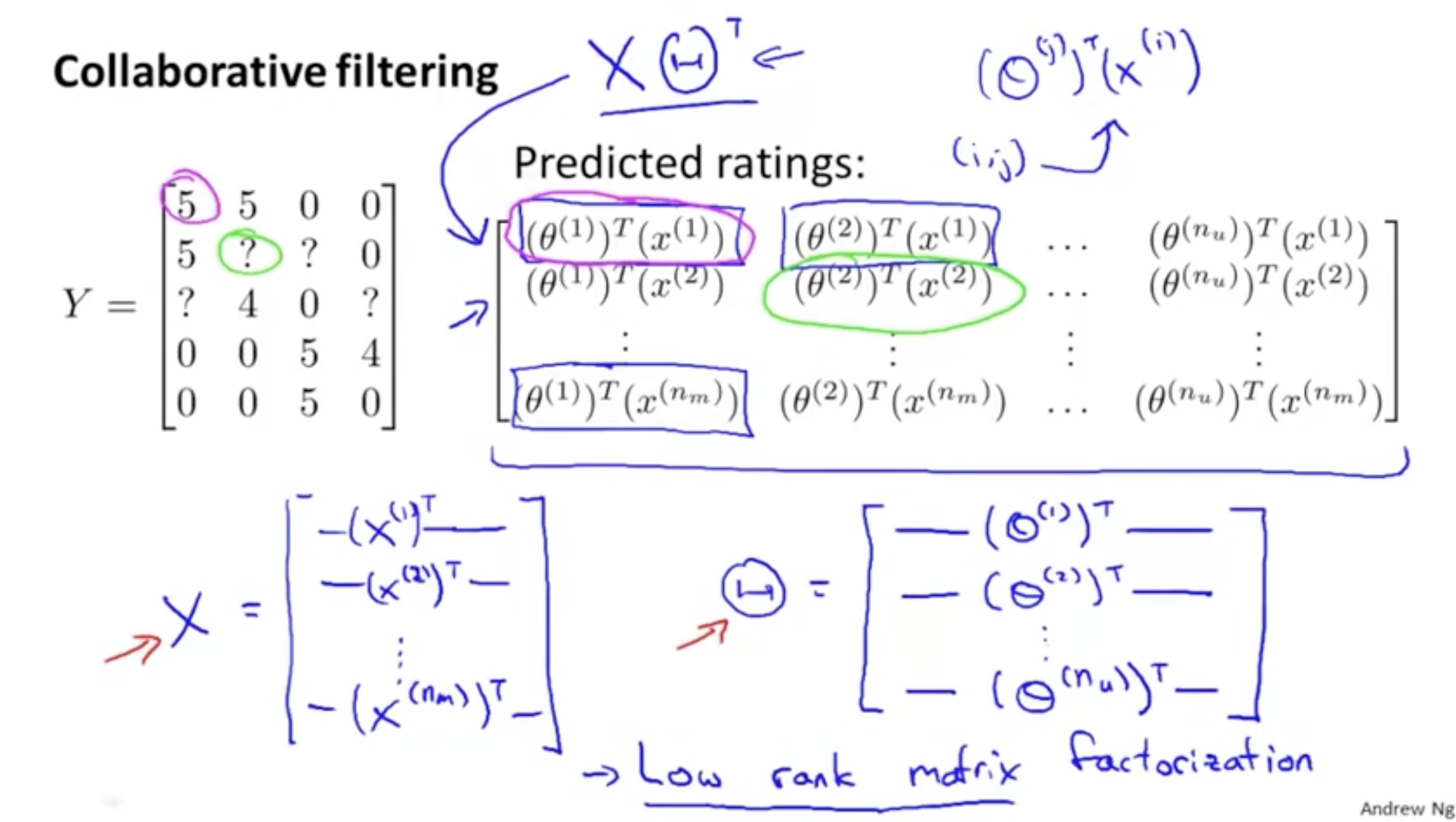
그렇다면 predict하는 과정을 한번에 빠르게 연산할 수 있는 방법을 알아보자.
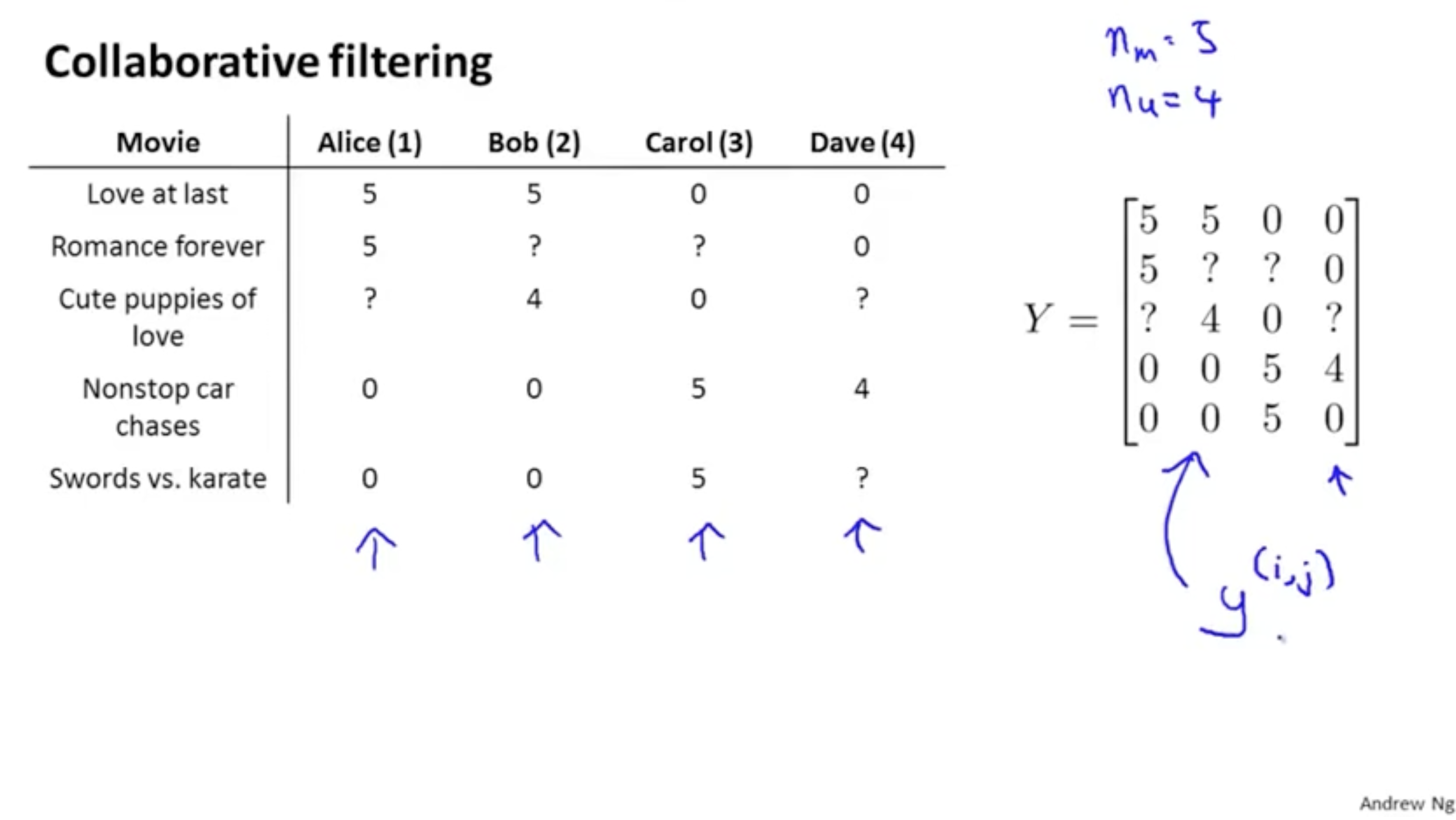
아래 그림과 같이 유저 j의 영화 i에 대한 평점 y(i,j)를 우측 행렬 Y로 표현해보자.
그리고 이 Y의 값을 구하는 방법은 다음과 같다. y(i,j)=(θ(j))Tx(i)
하지만 "Vectorization"을 활용하면 한 번에 Y 행렬을 구할 수가 있다. 그리고 그 과정은 다음과 같다.