
글 작성 - 23.3.15
업데이트 - 23.4.5
OpenAI의 ChatGPT는 정말 훌륭한 서비스이지만, 운영 및 보안적인 측면에서 컨트롤하기 어렵고 비용적인 문제도 발생한다. 만약 ChatGPT에 못지않은 성능을 내면서 자신만의 안전한 서버에서 실행할 수 있다면 어떨까?
최근 한달 사이에 ChatGPT를 겨냥한 오픈소스 프로젝트들이 많이 공개되었다.
물론 이러한 오픈소스 프로젝트들이 아직까지 ChatGPT, GPT-4와 동등한 성능이라 말하기 어렵다. 하지만, 꽤 준수한 성능을 보이고 있고, 최근 양자화 기술이 접목되어 개인 랩탑에서도 ChatGPT와 같은 LLM 모델을 실행할 수 있는 수준에 이르렀다.
이에 일부 주목받고 있는 오픈소스 LLM 프로젝트들에 대해 정리해보았다.
- OpenChatKit
- Vicuna
- GPT4ALL
- ColossalChat
OpenChatKit (by TOGETHER)

- EleutherAI의 GPT-NeoX-20B 모델에 채팅에 적합한 4천3백만개의 instruction 데이터로 finetuning
📌 blog : https://www.together.xyz/blog/openchatkit
📌 github : https://github.com/togethercomputer/OpenChatKit
📌 demo : https://huggingface.co/spaces/togethercomputer/OpenChatKit
Alpaca (by Stanford)

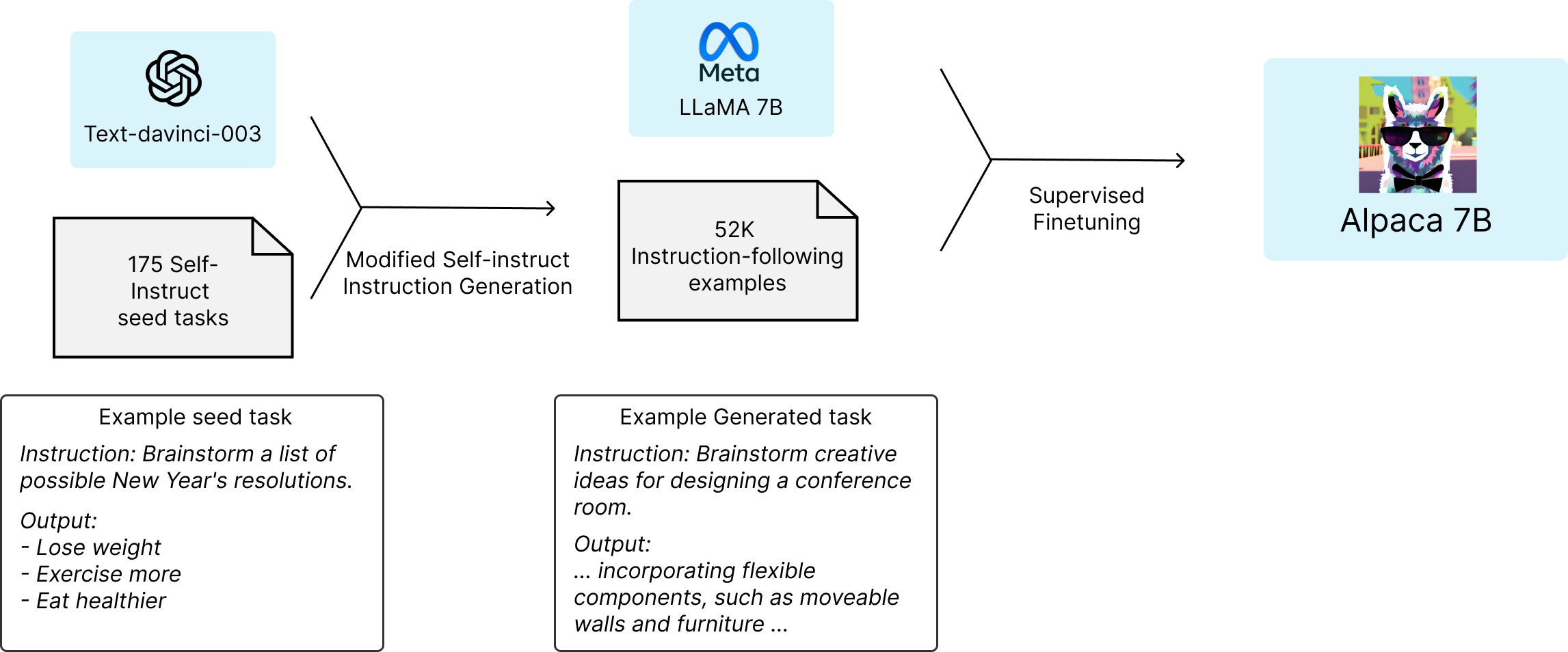
- 175개의 샘플 instruct 데이터를 통해 OpenAI의 text-davinci-003모델로 부터 5만2천개의 instruction 데이터를 자동생성 ($500 정도 소모)
- 자동생성된 instruction 데이터를 얼마전 meta에서 공개한 LLaMa 7B모델에 finetuning하였고 (80GB A100 8개로 finetuning하는데 3시간 정도 들었고, 클라우드 비용이 $100 안들었다고 함)
- 벤치마크결과 text-davinci-003과 유사한 성능을 발휘 🤯 (참고로 text-davinci-003은 175B)
📌 blog : https://crfm.stanford.edu/2023/03/13/alpaca.html
📌 github : https://github.com/tatsu-lab/stanford_alpaca
📌 demo : https://alpaca-ai-custom3.ngrok.io/
Vicuna (by FastChat)

- Meta LLaMA, Standford Alpaca 프로젝트에 영감을 받아 진행
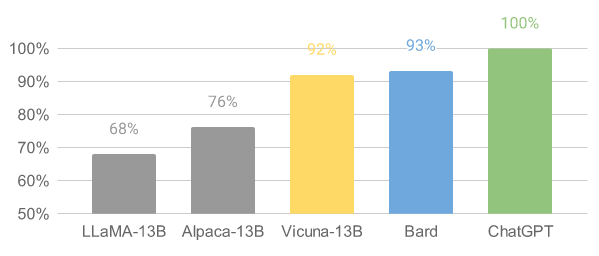
- Bard/ChatGPT의 성능에 약 90%에 달하는 능력을 보유
- ShareGPT에 공유된 conversation 데이터셋을 바탕으로 LLaMA-13B 모델을 finetuning
- 70K의 ShareGPT 데이터셋을 바탕으로 InstructGPT/ChatGPT와 유사하게 Supervised Instruction tuning을 진행, reward 모델을 위한 강화학습은 별도로 진행되지 않았음
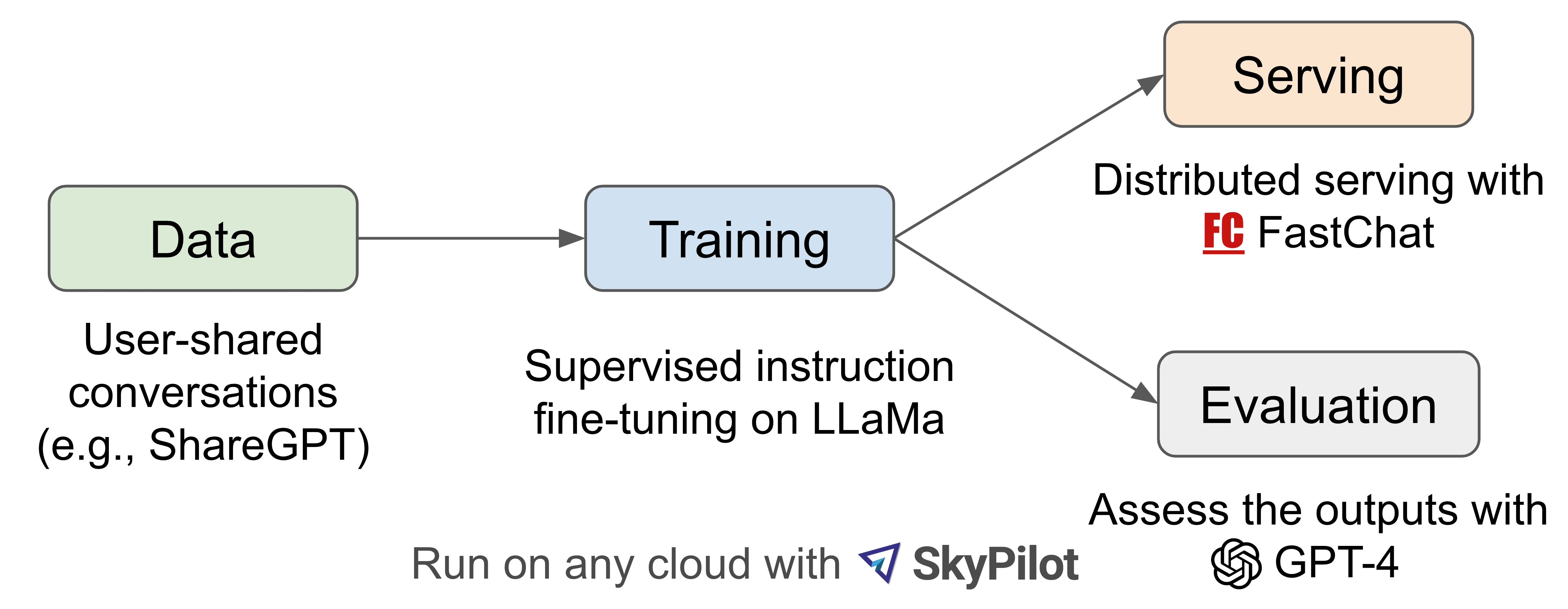
- Vicuna-13B의 context length를 2048까지 확장 (Alpaca는 512)
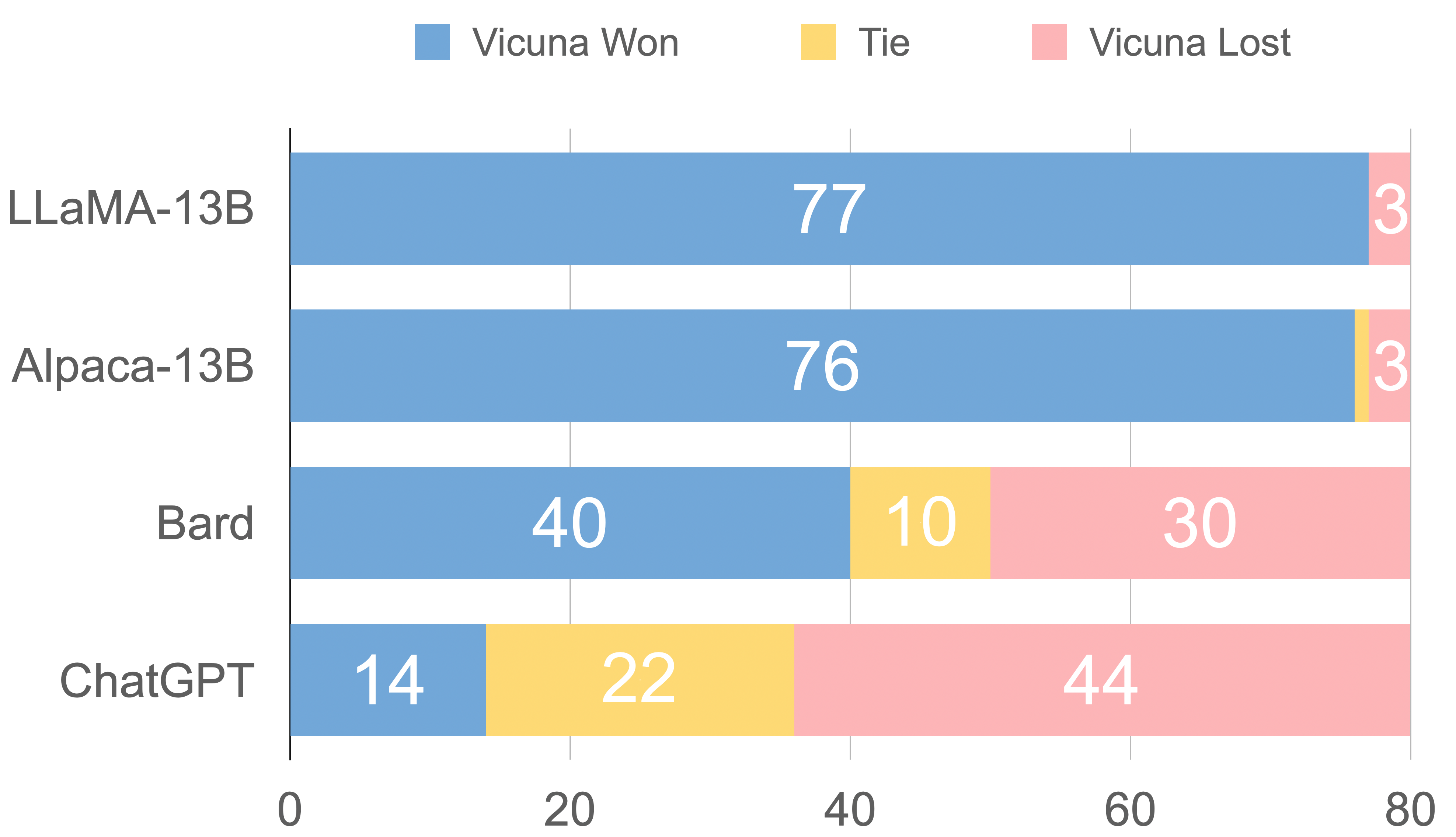
- LLaMA-13B, Alpaca-13B, Bard, ChatGPT와 성능 비교 진행 (평가는 GPT-4에 의해 진행됨)
- 90%이상의 평가에서 Vicuna가 오픈소스의 SOTA모델들(LLaMA, Alpaca)에 비해 90%에 비해 더 좋은 평가를 받음
- 45%의 평가에서 Vicuna의 응답이 ChatGPT보다 우수하거나 동일하다고 평가 받음
📌 blog : https://vicuna.lmsys.org/
📌 github : https://github.com/lm-sys/FastChat
📌 demo : https://chat.lmsys.org/
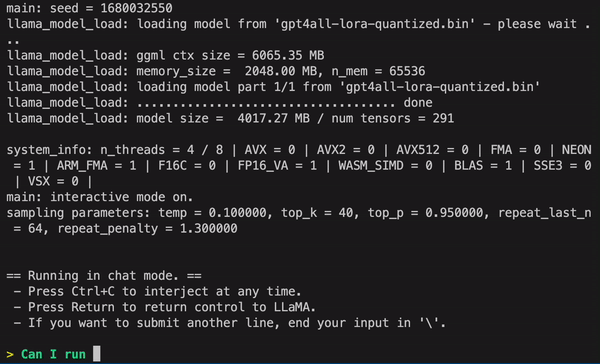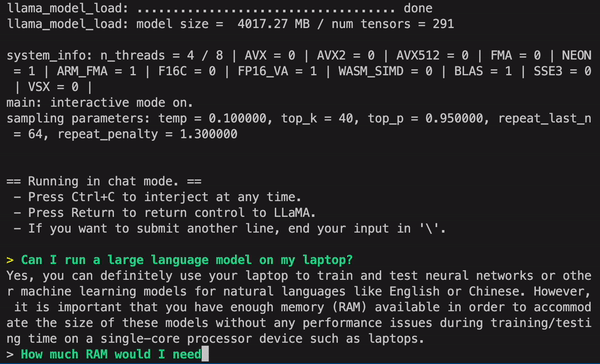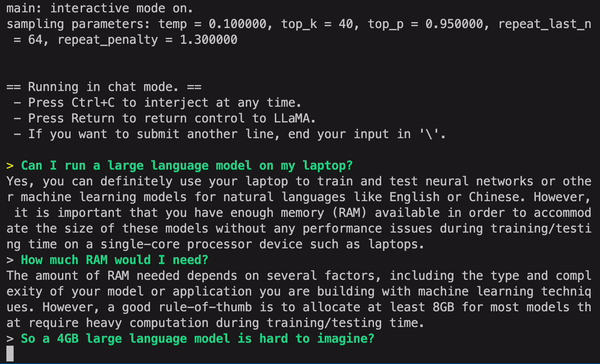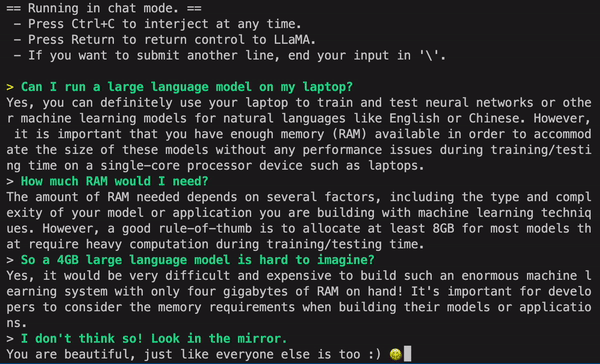
GPT4ALL (by Nomic.ai)
- OpenAI의 ChatGPT(gpt-3.5-turbo)를 통해 806,199개의 고품질 prompt-generation 데이터셋을 수집
- 이후 수집된 데이터에서 저품질의 응답 데이터를 제거하고, 다양성을 위해 데이터를 큐레이팅하여 최종적으로 437,605개의 데이터셋을 학습데이터로 사용
- LLaMa-lora 모델을 베이스로 학습 후 4bit 양자화를 적용하여 CPU에서도 실행 가능
(직접 테스트해보니 Macbook m1 pro 기준 대답 성능도 준수하고 속도도 꽤나 빠름) - 실행 방법
- Download the gpt4all-lora-quantized.bin file from Direct Link or Torrent-Magnet
- Clone this repository, navigate to chat, and place the downloaded file there.
- Run the appropriate command for your OS:
- M1 Mac/OSX:
cd chat;./gpt4all-lora-quantized-OSX-m1 - Linux:
cd chat;./gpt4all-lora-quantized-linux-x86 - Windows (PowerShell):
cd chat;./gpt4all-lora-quantized-win64.exe - Intel Mac/OSX:
cd chat;./gpt4all-lora-quantized-OSX-intel
- M1 Mac/OSX:
📌 technical report : https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf
📌 github : https://github.com/nomic-ai/gpt4all
ColossalChat(by ColossalAI)
- LLaMA-7B모델을 베이스로 RLHF 진행
- 104K의 영어, 중국어 데이터셋 사용
- Alpaca, Vicuna등 다른 오픈소스 모델들이 Supervised Instruction Tuning까지만 진행하고, 보상모델을 위한 강화학습은 진행하지 않은 것에 비해, ColossalChat은 지도학습 + 보상모델까지 진행하여 ChatGPT의 RLHF와 가장 유사한 학습방법을 진행
- 4bit 양자화 진행 (4GB GPU에서도 실행 가능)
📌 blog : https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b
📌 github : https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat
📌 demo : https://chat.colossalai.org/
.jpeg)