Stream Processing
-
Batch Processing 은 고정된 (큰) Dataset에 대해 한 번 연산을 하는 거 였다면, Stream Processing 은 끝 없이 들어오는 데이터의 흐름을 연속적, 준 실시간으로 처리하는 것
-
IOT센서, 웹 사이트/앱 과의 상호 작용, 신용 카드 트랜잭션, 실시간 대시 보드, 온라인 머신 러닝 등 다양한 분야에서 사용
-
Batch Processing과 같이 사용하여, 서로의 약점을 보완하고 강점을 취하는 방식으로도 많이 사용(lambda 아키텍처)
Stream Processing 방법
record-at-a-time processing model
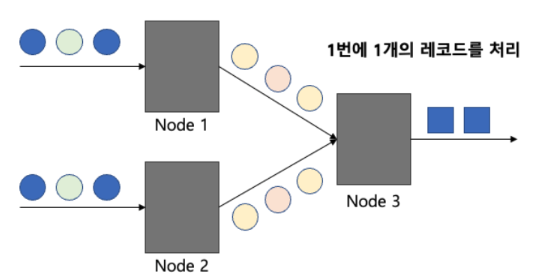
- 각 노드는 지속적으로 한 번에 한 개의 레코드를 받게 됨. 그 레코드를 처리하여 생성된 다른 레코드는 그래프상의 다음 노드로 보냄
- 장점 : 응답 시간(latency)이 매우 짧음 (ms 단위로 가능)
- 단점 : 높은 처리량(throughput)을 달성하기 어렵고, 특정 노드에 장애 발생 시 복구가 어려움
- 예시
- 실시간 fraud detection, 온라인 alert, 게임 이벤트 반응
micro-batch stream processing model

- Spark Streaming에서 기본적으로 취하는 방법. 아주 작은 Batch processing을 처리하는 방식
- 장점 : 높은 처리량
- 단점 : 느린 반응 속도(ms 단위로 처리하기 어려움, 몇 초 단위로는 가능)
- 채택 배경 : 대부분의 데이터 파이프라인에서는 ms 단위의 반응 속도를 필요로 하지 않고, 이 단계에서 빠른 반응 속도를 갖춘다 하더라도, 다른 곳에서 지연이 발생할 가능성이 높음
DStream
Discreatized Stream 불연속적 스트림. RDD의 개념을 바탕으로 구축되어 있음. 카프카 등의 소스로부터 발생되는 데이터를 스파크에서 사용할 수 있도록 데이터의 형태를 재구성한 것
생성
- 카프카 등의 외부의 입력 소스로부터 만들어지거나 다른 DStream에 transformation 연산을 적용하여 생성
- 시간별로 도착한 데이터들의 연속적인 모음으로 이해할 수 있음. 내부적으로 각각의 DStream은 각 시간별로 도착한 RDD들의 연속적인 모음
연산
- RDD 와 마찬가지로 transformation(변환)과 action(액션) 연산이 존재
- 변환으로부터 새로운 DStream 생성
- stateless(무상태) 와 stateful(상태유지)로 나뉨
- stateless 에는 일반적 RDD 트랜스포지면
사용
- 주 시작점인 StreamingContext를 생성하여 데이터를 처리하는 데 사용하게 됨
- 이는 별도의 스레드에서 실행되므로 사용자 애플리케이션 종료 시 작업을 유지하기 위해 스트리밍 연산 완료를 기다리게 하는 메서드인 awaitTermination()을 호출 필요
전체 수행 흐름 요약
- API 스타일 : 저수준 RDD
- 실행 엔진 : RDD DAG 엔진
- 트리거/옵션 설정 : 적음
- 상태 저장 지원 : 약함
- SparkContext 생성
- StreamingContext 생성 (배치 간격과 SparkContext로 초기화)
- DStream 정의 (Transformation 정의)
- start() 호출 (StreamingContext가 실시간 스트리밍 처리 시작)
- 주기적으로 입력 수집 -> RDD 생성 (설정한 배치 주기마다 새로운 RDD 생성)
- DStream에서 정의된 연산 적용 (Transformation 이 각 RDD에 순차 적용됨)
- Action 수행 및 결과 출력 (print, save 등 action이 실행되어
- awaitTermination() (종료되지 않고 계속 대기, 스트리밍 지속)
한계
- RDD API 와 마찬가지로 개발자들이 작성한 코드와 동일한 순서로 연산을 수행(Optimizer 에 의한 자동 최적화 발생 x)
- Event time window 지원 부족(Processing time window만 지원)
Structured Streaming
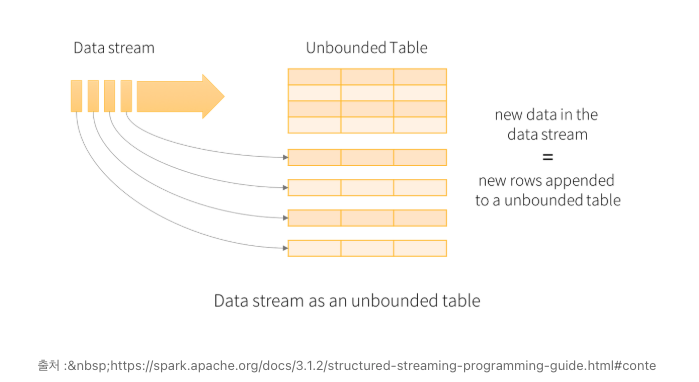
Spark Session 으로부터 생성되는 API. Spark Session 사용 시 스트리밍 데이터 소스에서 DataFrame, DataSet 생성 가능. 데이터의 Stream을 무한하게 연속적으로 추가되는 데이터의 테이블 개념으로 간주
import org.apache.spark.sql.SparkSession
val Saprk = SparkSession.builder("local")\
.master("local")
.appName("StructuredNetworkWordCount")\
.getOrCreate()- Structured Streaming은 꾸준히 생성되는 데이터를 무한히 증가하는 하나의 커다란 데이터 셋으로 간주. 데이터가 연속적으로 추가되는 테이블처럼 다룸
- 새로운 데이터를 row 단위로 계속해서 쌓으며 새로운 행 추가 시 데이터 테이블을 업데이트하고 결과 행을 외부 싱크(외부 저장장치)에 기록
- 싱크 : 데이터를 쓰는 장소
- 소스 : 데이터를 읽는 장소(ex.카프카)
생성
- DataStreamReader를 사용.SparkSession의 readStream()을 통해 생성이 가능
사용
- DataStreamWriter를 이용한 쿼리 작업 필요
- DataStreamWriter는 데이터 셋의 writeStream 메서드를 사용하며 저장 모드, 쿼리명, 트리거 주기, 체크포인트 설정 가능.
- awaitTermination을 통한 실행 동작 제어 가능
저장
- 결과를 언제 output 할지는 trigger를 통해 정의 가능. 시간 단위 뿐만 아니라 메가바이트 단위 등의 주기에 따라서도 아웃풋이 가능
- 정의하지 않으면 가능한 빠르게 트리거가 배치 처리를 수행
- 엔진은 모든 스트리밍 소스
trigger
- 기본값은, 고정간격 마이크로 배치, 일회성 마이크로 배치, 연속형 처리
- 기본값 : 이전 작업 종료 시 (마이크로 배치) 바로 다음 작업에 들어감
- 고정 간격 마이크로 배치 : 고정된 인터벌을 주고 작업
- 일회성 마이크로 배치 : 사용 가능한 모든 데이터를 처리하고 자체적으로 중지하기 위해 단 한 번의 마이크로 배치를 실행
- 연속형 처리 : 마이크로 배치 방식은 데이터가 쌓이길 기다려 한꺼번에 효율적으로 작업이 가능하지만 지연 시간이 발생. 반면 연속형 처리는 레코드가 오면 하나씩 바로 작업하는 방식으로 빠른 응답 속도
output
- DataStreamWriter 의 저장 모드에는 아래와 같이 세 가지 존재
- Append : 마지막 트리거 이후 업데이트 된 행만 출력. 새롭게 추가된 데이터만 출력하기 때문에 결과 테이블의 기존 Row를 변경하지 않은 쿼리에만 적용 가능
- Update : 마지막 트리거 이후 업데이트 된 행만 출력. 마지막 출력 시점부터 다음 출력 발생하는 시점 동안 변경된 데이터만 출력
- Complete : 지금까지 처리된 모든 행을 출력. 데이터 프레임이 가지고 있는 전체 데이터를 모두 출력하는 방법
****
전체 수행 흐름 요약
- API 스타일 : 고수준 SQL / DataFrame
- 실행 엔진 : Catalyst + Tungsten
- 트리거/옵션 설정 : 풍부함
- 상태 저장 지원 : 강함(stateful join)
- SparkSession 생성 (SparkContext가 아닌 SparkSession을 통해 시작)
- Streaming Source 지정, readStream (Kafka, socket, file 등 외부 스트리밍 소스)
- Transformation 수행 (RDD가 아닌 DataFrame API / SQL API 로 연산)
- Sink(출력 타겟) 설정, writeStream (Kafka, console, S3 등으로 출력)
- Trigger(실행 주기) 지정 (기본값은 micro-batch 모드이며, 몇 초 단위로 연산됨)
- Query 실행 및 종료 대기 (query.awaitTermination())
Structured Streaming에서 watermark와 window 연산을 함께 사용할 때 주의할 점
- Window : 데이터를 시간 기준으로 구간별로 나눠 처리(예: 1분 간격)
- Watermark : 늦게 도착한 데이터 처리 기준선(lateness 허용)
⚠️ 주의할 점
-
watermark는 상태 유지 기간을 결정함. 예를 들어 withWatermark("timestamp", "10 minutes") -> 10분 이상 늦은 데이터는 집계 대상에서 제외됨
-
window 처리와 결합 시, 상태(state)가 자동 제거됨
-> 설정된 watermark 기준보다 오래된 상태는 자동 GC 대상
