RDD
특징
- Java, Scala의 객체를 처리하는 방식
- immutable. 즉, 수정할 수 없다
- lineage를 통해 fault tolerent를 보장함으로써 속도가 빠름
- 쿼리 최적화 등을 지원하지 않음(카탈리스트 옵티마이저 x)
- PySpark에서 UDF 선언시 인터프리터와 JVM 사이 커뮤니케이션으로 속도가 저하됨
- RDD 생성은 외부로 부터 데이터를 로딩하거나 또는 코드에서 생성된 데이터를 저장함으로써 생성할 수 있음
- 분산 데이터 세트에 대한 작업 측면에서 프로그램을 작성
- 클러스터를 통해 분산 된 개체의 분할 된 컬렉션으로, 메모리 또는 디스크에 저장
- Transformation(map,filter,join) 과 Action(count, collect, save) 을 통해 구축되고 조작됨
- Transformation
- 기존의 RDD 데이터를 변경하여 새로운 RDD 데이터를 생성해 내는 것. 데이터를 처리함
- filter() 와 같이 특정 데이터만 뽑아 내거나(행 추출) map() 함수처럼, key&value를 뽑아 데이터를 분산 배치 하는 것 들
- Action
- RDD 값을 기반으로 RDD에서 RDD가 아닌 타입의 data 로 변환하는 함수
- action 이 실행될 때, 비로소 transformation 함수가 memory에 비로소 올라오게 됨
- count(), collect() 와 같은 operation 들
- Transformation
- RDDs 생성은
- 기존 python 리스트를 병렬 처리해서. list 등 데이터 소스로부터 RDD 만듦
- 기존 RDD 변환(filter(), map())
- HDFS 또는 기타 스토리지 시스템의 파일
SparkContext를 통해 만들어지며 보통 sc.spark.SparkContext를 통해 객체를 생성
SparkSession을 import해도 SparkContext가 포함되어 있는 내용이라 SparkSession만 import해도 사용가능
list -> (parallelize) -> RDD -> (filter) -> filtered RDD -> (map) -> mapped RDD -> (collect) -> Result
UDF 사용자 정의 함수
- 개발자가 직접 만든 함수로, DBMS에 저장되어 SQL문 안에서 쓸 수 잇는 하나의 함수를 정의하는 것. SELECT, INSERT, UPDATE, DELETE 등 여러 SQL 문에서 사용 가능
- DataFrame, SparkSQL 열에 있는 데이터에 적용할 수 있음
- 스파크 UDF는 내장된 스파크 기능으로 달성할 수 없는 복잡한 데이터 연산을 수행
- 데이터 처리를 위한 좋은 도구지만, 스파크가 JVM과 UDF간에 데이터를 직렬화 및 역직렬화해야 하기 때문에, 성능 오버헤드 발생
예시 상황
- 높은 레벨의 API에서 찾을 수 없는 어떠한 기능이 필요할 때 사용(mysql의 upsert와 같은 기능, map 함수 내지 특정 기능 사용)
- RDD를 기반으로 짠 기존 코드를 유지해야 할 때
- shared variable 조작을 설정해야 될 때
예시 코드
spark = SparkSession.builder\
.appName("APP_NAME")\
.master("local")\
.getOrCreate()
lines = sc.textfile("주소".파일형식) # lines는 RDD타입으로 만들어지게 됨RDD API의 문제점
RDD API 연산(Operations) 이란?
Apache Spark에서 RDD라고 하는 분산된 데이터 컬렉션에 대해 수행할 수 있는 모든 작업. RDD는 스파크의 가장 기본적인 데이터 추상화 단위이며, 이 RDD에 적용되는 연산들을 통해 데이터를 변환하고 분석
1. 변환(Transformation)
- RDD에 적용되어 새로운 RDD를 생성하는 연산
- 지연 실행(Lazy Evaluation) 의 특성. 변환 연산 자체는 즉시 계산을 수행하지 않고, 계산을 위한 실행 계획(DAG)만 생성
- map(), filter(), flatemap(), union(), groupByKey(), reduceByKey(), soryByKey()
2. 액션(Actions)
- RDD에 대한 실제 계산을 트리거하고 결과를 드라이버 프로그램으로 반환하거나, 외부 저장소에 저장하는 연산
- 액션이 호출될 때 이전의 변환 연산들이 실행
- 액션 연산의 결과는 RDD가 아닌, list, 숫자, 또는 외부에 저장된 파일 등이 될 수 있음
- collect(), count(), first(), reduce()
최적화 방법 X
- RDD API 기반 코드에서 어떤 일이 일어나는지 스파크는 알 수 없음
- Join, filter, group by 등 여러 연산을 하더라도 스파크에서는 람다 표현식으로만 보임
- PySpark 경우, 연산 함수 Iterator[T] 데이터 타입을 제대로 인식하지 못함. 스파크에서는 단지 파이썬 기본 객체로만 인식
데이터 압축 테크닉 X
- 스파크는 위에 제네릭 형태로 표현한 타입 T에 대한 정보를 전혀 얻을 수 없음
- 그 타입의 객체 안에서 어떤 타입의 컬럼에 접근한다 해도, 스파크는 알 수 없음
- 결국 바이트 뭉치로 직렬화 해 사용할 수 밖에 없음
✅ 결국, 스파크가 연산 순서를 재정렬 해 효과적인 질의 계획으로 바꿀 수 없음
DataFrame
특징
- RDD는 없는데, dataframe 에서는 미리 정의해둔 스키마를 파일을 읽어올 때 혹은 인메모리에 있는 리스트로부터 dataframe 만들 때 지정 가능
- 내부 데이터가 Row라는 것만 명시, 실제 데이터 타입은 알 수 없음
- Python Wrapper 코드로 Python에서의 성능 향상
- Dataset 제네릭 객체 집합에 대한 별칭
- RDD 와 마찬가지로 Pyspark에서 함수를 선언해서 사용할 경우(UDF), 속도 저하의 원인이 됨
- lineage를 통해 lazy하게 작동(계산 혹은 기능에 계보를 저장하고 바로 실행되지 않음. 즉 결과를 바로 돌려주지 않음) -> transformation 과 action 의 분할
예시 코드
spark = SparkSession.builder\
.appName("APP_NAME")\
.master("local")\
.getOrCreate()
df = spark.read.format(FORMAT).option(OPTION, 'true').load("주소.파일형식")
# df는 dataframe 타입으로 만들어지게 됨
Dataset
특징
- 데이터 타입이 명시되어야 함
- Scala/Java에서 정의한 클래스에 의해 타입을 명시해야하는 JVM 객체. 따라서 python은 지원하지 않음
- 카탈리스트 옵티마이저 지원
- Type-safe
- RDD와 DataFrame의 장점을 갖는다.
예시 상황
- 데이터 프레임 조작을 통해 원하는 수행을 할 수 없을 때
- type-safety를 원할 때, 대가로 그만한 비용을 감당 가능할 때 *dataframe은 dataset의 row 타입
예시 코드
SparkSQL
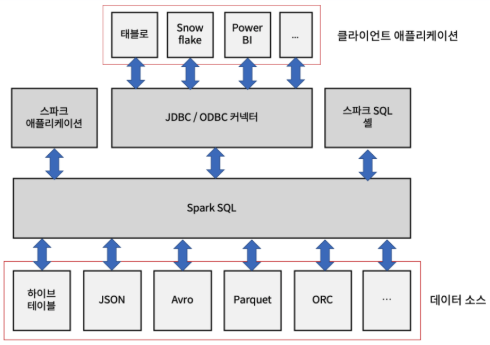
특징
- 구조화된 데이터를 처리하기 위한 스파크 모듈
- DataFrame, Dataset이라 불리는 추상화를 제공하고, 분산 SQL 쿼리 엔진의 역할도 수행
- RDD의 문제를 해결함
- SQL 같은 질의 수행
- 스파크 컴포넌트들을 통합하고, DataFrame, Dataset 이 java, scala, python, R 등 여러 프로그래밍 언어로 정형화 데이터 관련 작업을 단순화 할 수 있도록 추상화 해줌
- 정형화된 파일 포맷(Json, CSV, avro, parquey, orc 등)에서 스키마와 정형화 데이터를 읽고 쓰며, 데이터를 임시 테이블로 변환
- 빠른 데이터 탐색을 할 수 있도록 대화형 스파크 SQL 쉘 제공
- 표준 DB JDBC/ODBC 커넥터를 통해, 외부의 도구들과 연결할 수 있는 중간 역할 제공. 커넥터를 통해 클라이언트 애플리케이션과 쉽게 연동이 가능해짐.
✅ SparkSQL 사용 없이, RDD만 사용시 다양한 데이터 소스 사용 불가. 텍스트 파일 혹은 하둡의 시퀀스 파일만 사용 가능
장점
1. 성능
- RDD와 달리 스파크는 연산, 표현식, 데이터 타입 정보를 모두 알 수 있음 -> 스파크는 연산 순서를 재정렬하여, 더 효과적인 질의 계획으로 변경 가능. RDD는 연산 함수 Iterlator[T] 데이터 타입을 제대로 인식 못함
- 위의 성능을 Catalyst Optimizer 로 가능하게 해줌
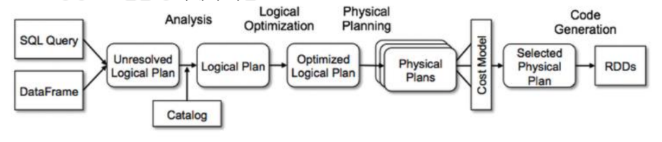
Catalyst Optimizer
연산 쿼리를 받아 실행 계획으로 변환. 아래의 그래프에서, 크게 네 단계의 변환 과정을 거쳐 RDD 생성
1. 분석
2. 논리적 최적화 - 컴파일러 레벨에서 실행되는 최적화(null 체크)
3. 물리 계획 수립 - 일부 데이터를 샘플링해서 돌려보고 가장 빠르게 실행되는 플랜을 가져감
4. 코드 생성
2. 표현성
이름별 나이의 평균 구하기
# rdd example
dataRDD = sc.parallelize([("영희", 20), ("철수", 30), ("민수", 22), ("재원", 28)])
agesRDD = (dataRDD.map(lambda x: (x[0], (x[1], 1)))\
.reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1])) \
.map(lambda x: (x[0], x[1][0] / x[1][1]))) - RDD 예시의 경우, 람다 표현식이 어떻게 키를 집계하고 평균 계산을 하는지 직관적으로 알기 쉬움
# dataframe example
data_df = ss.createDataFrame([("영희", 20), ("철수", 30), ("민수", 22),
("재원", 28)], ["name", "age"])
avg_df = data_df.groupBy("name").agg(avg("age"))- DataFrame API 예시의 경우는 스파크가 무엇을 하는지가 명확하게 보임
3. 일관성
- 프로그래밍 언어들을 통틀어 일관성을 가지고 있음
- python, scala, java로 작성한 스파크 코드의 형태가 거의 비슷
4. Dataframe API - 개요
- 구조, 포맷 등 몇몇 특정 연산 등에 있어, 판다스 데이터 프레임에 영향을 많이 받음
- 이름 있는 컬럼과 스키파를 가진 분산 인메모리 테이블처럼 동작
- 기본 타입
- Byte, Short, Integer, Long, Float, Double, String
- 정형화 타입
- Binary, Timestamp, Date, Array, Map, Struct, StructField
- 실제 데이터를 위한 스키마를 정의할 때 어떻게 이런 타입들이 연계되는지를 아는 것이 중요
- 스파크에서 스키마는 Dataframe을 위해 컬럼 이름과 연관된 데이터 타입을 정의한 것
- 외부 데이터 소스에서 구조화된 데이터를 읽어 들일 때 사용
- 읽을 때 스키마를 가져오는 방식과 달리, 미리 스키마를 정의하는 것은 여러 장점이 존재
- 스파크가 데이터 타입을 추측해야 되는 책임을 덜어줌
- 스파크가 스키마를 확정하기 위해, 파일의 많은 부분을 읽어 들이려고 별도의 잡을 만드는 것을 방지
- 데이터가 스키마와 맞지 않는 경우, 조기에 문제 발견 가능
- 스키마 정의 방법
# programming
schema_programming = StructType([
StructField("author", StringType(), True),
StructField("title", StringType(), True),
StructField("pages", StringType(), True),
])
# DDL
schema_ddl = "author STRING, title STRING, pages INT"