Apache Spark✨
1.[Apache Spark] Spark 정리

Spark 는 Hadoop의 빅데이터 처리 방식은 맞지만, 속도가 느린 것을 해결하기 위해 사용한다. Spark는 인메모리 방식의 연산처리를 지향하면서 MR(Map Reduce)의 연산 속도의
2025년 5월 19일
2.[Apache Spark] Spark (RDD vs DataFrame vs Dataset)
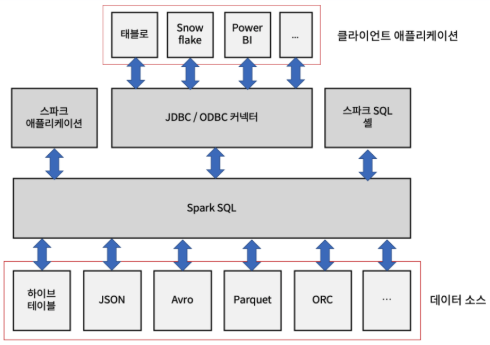
Apache Spark에서 RDD라고 하는 분산된 데이터 컬렉션에 대해 수행할 수 있는 모든 작업. RDD는 스파크의 가장 기본적인 데이터 추상화 단위이며, 이 RDD에 적용되는 연산들을 통해 데이터를 변환하고 분석RDD에 적용되어 새로운 RDD를 생성하는 연산지연 실
2025년 5월 27일
3.[Apache Spark] Streaming Processing (DStream, Structured Streaming)
Stream Processing Batch Processing 은 고정된 (큰) Dataset에 대해 한 번 연산을 하는 거 였다면, Stream Processing 은 끝 없이 들어오는 데이터의 흐름을 연속적, 준 실시간으로 처리하는 것 IOT센서, 웹 사이트/앱
2025년 6월 20일