Over-fitting 과 Under-fitting 을 이해하기 위해선 Bias 와 Variance trade-off 를 이해 해야한다. ML의 목표는 학습 데이터셋에 없는 데이터, 즉 테스트 셋에 대해서 높은 성능을 보이는 것. 만약 training set과 test set의 성능에 큰 차이가 있다는 것은 일반화 능력이 낮다.
Bias(분산) 이란?
- 학습된 모델의 예측값 평균과 실제 값간의 차이
- 높은 bias 는 training set 을 제대로 학습하지 못하고 모델을 지나치게 단순화시킨다. 학습셋과 테스트셋 사이의 높은 오류율을 보임
- 예를 들어, 고집이 너무 강해 새로운 지식을 학습시켜도 자신의 주관대로 하는 사람
- 선형회귀(Linear regression)
Variance(분산) 이란?
- 예측값의 평균과 실제 값간의 차이
- Variance 가 큰 모델은 데이터셋의 특성을 잘 반영하나 이전에 본 적이 없는 데이터셋에 일반화 되지 않는다. 결과적으로 train set = GOOD!!, test set = BAD!!
- 예를 들어, 귀가 너무 얅아서 옳은것이든 틀린 것이든 학습 시키는 그대로 수용하는 사람
- 고차 다항 회귀(High-degree polynomial regression), 심층 인공신경망(Deep neural network)
Bias & Variance 수학적 관계
- x: 입력값(데이터셋)
- f(x): 학습 데이터을 학습한 모델
- Y: 학습 모델의 예측값
- f’(x): f(x)를 테스트 데이터로 예측한 값
- σ2 : 노이즈의 분산

- 예측값 Y는 train set에 대해 학습한 모델 f(x) + 평균이 0인 분포의 오류(e)의 합으로 정의
- Irreducible error(=σ2) 는 성능이 좋은 모델도 줄일 수 없는 오류로 데이터의 노이즈 양을 측정한 것
- σ2 는 노이즈의 분산으로써 예측 모델 f와 독립적인 어떠한 상수로 존재
- 예측 오차를 최소화하기 위해 bias의 제곱과 variance을 최소화해야한다.
- 만약 bias를 최소화 시키기 위해 f(x) = f*(x) 가 되도록 모델을 학습하면, bias는 0이 되지만 variance 증가.
- 만약 variance를 최소화하기 위해 어떠한 상수만을 출력하도록 학습시키면, variance는 0이 되지만 모델의 출력과 f*(x) 사이의 차이가 커져 bias 증가.
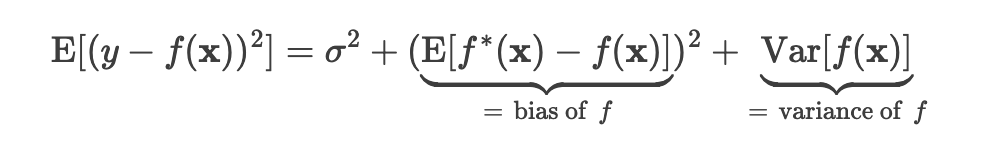
Bias-Variance Trade-off
- 타겟의 중심은 실제 값이고 중심에서 멀어질수록 모델의 예측이 점점 나빠진다.
(1) 에러율이 가장 작은 모델
(2) Over-fitting, train set = GOOD, test set = BAD
(3) Under-fitting
(4) 에러율이 가장 큰 모델

- Train set 에 잘 맞게 학습하면(작은 Bias) capacity 가 큰 모델이 필요하다. 하지만 모델의 capacity 가 너무 높으면 test set에 대한 variance가 커져 전체 에러율이 높아진다.
- 반대로 capacity가 너무 작으면 제대로 학습을 할 수 없어 train set에 대한 variance가 작은 반면, test set에 대한 bias가 커지므로 전체 에러율이 높아진다.
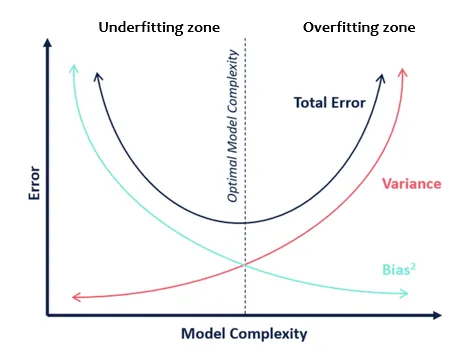
결론
주어진 데이터를 학습하여 새로운 데이터를 잘 예측하는 모델링 기법을 고려하는 것도 중요하지만, 데이터가 모델링에 필요한 정보량을 충분히 보유하고 있는지 확인이 필요하다. 충분하지 않은 정보량의 데이터로는 모델의 복잡도를 조절하더라도 noise의 크기만 조절 되는 과소적합에서 벗어날 수 없다.
데이터 양을 충분히 확보하는데 한계가 있다면, 모델은 데이터양에 따라 비슷한 성능을 보일것이고 예측 성능 차이가 크게 없다면 가장 단순한 모델이 시스템의 효율성 측면에서 좋은 모델이다
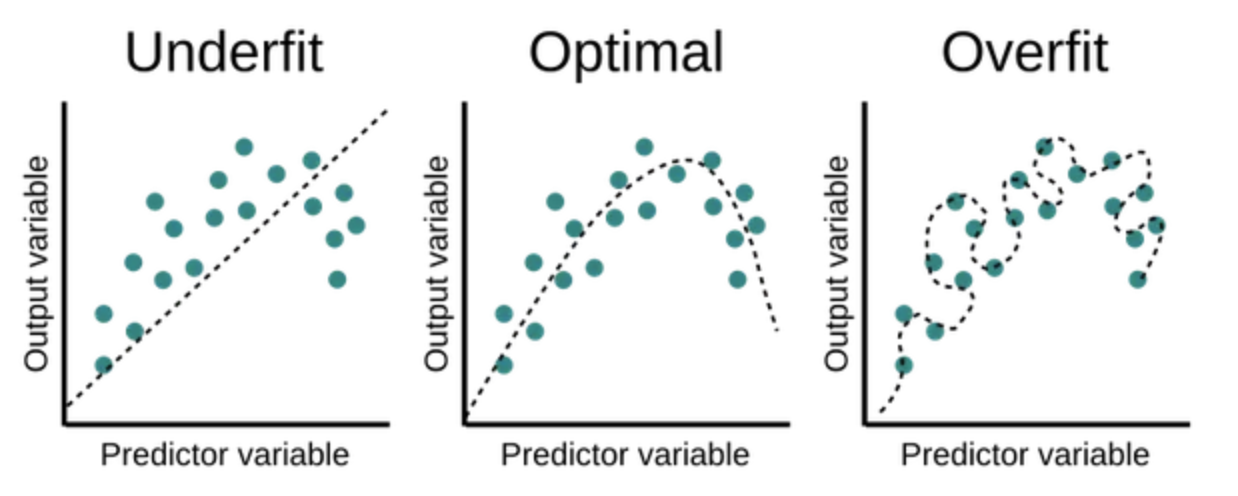
1. Under-fitting
- Bias 크고, Variance 작음
- Train set을 제대로 학습 못하고 모델을 단순화(Test set과 큰 오차율)
- 해결방안
- 모델 파라미터가 많은 복잡한 모델 고려
- 학습 데이터 확보
2. Over-fitting
- Bias 작고, Variance 큼
- Train set만 잘 학습. Test set에 대해서는 큰 오차율
- 해결방안
- 적당한 복잡도 모델 고려
- 불필요한 노이즈 데이터 제거
- 정규화 제약
질문
1. 복잡도는 어떻게 조절할까?
독립변수끼리는 상관성이 낮아야한다
두변수가 똑같은걸 설명하면 하나만 잇어도 되겟네
독립변수와 종속변수가 상관성 낮아도 괜찮다. 대신 독립변수끼리는 상관성이 낮아야함.
2. 좋은 모델이란?
time complexity, space complexity 를 생각해보자
