경사 하강법이란?
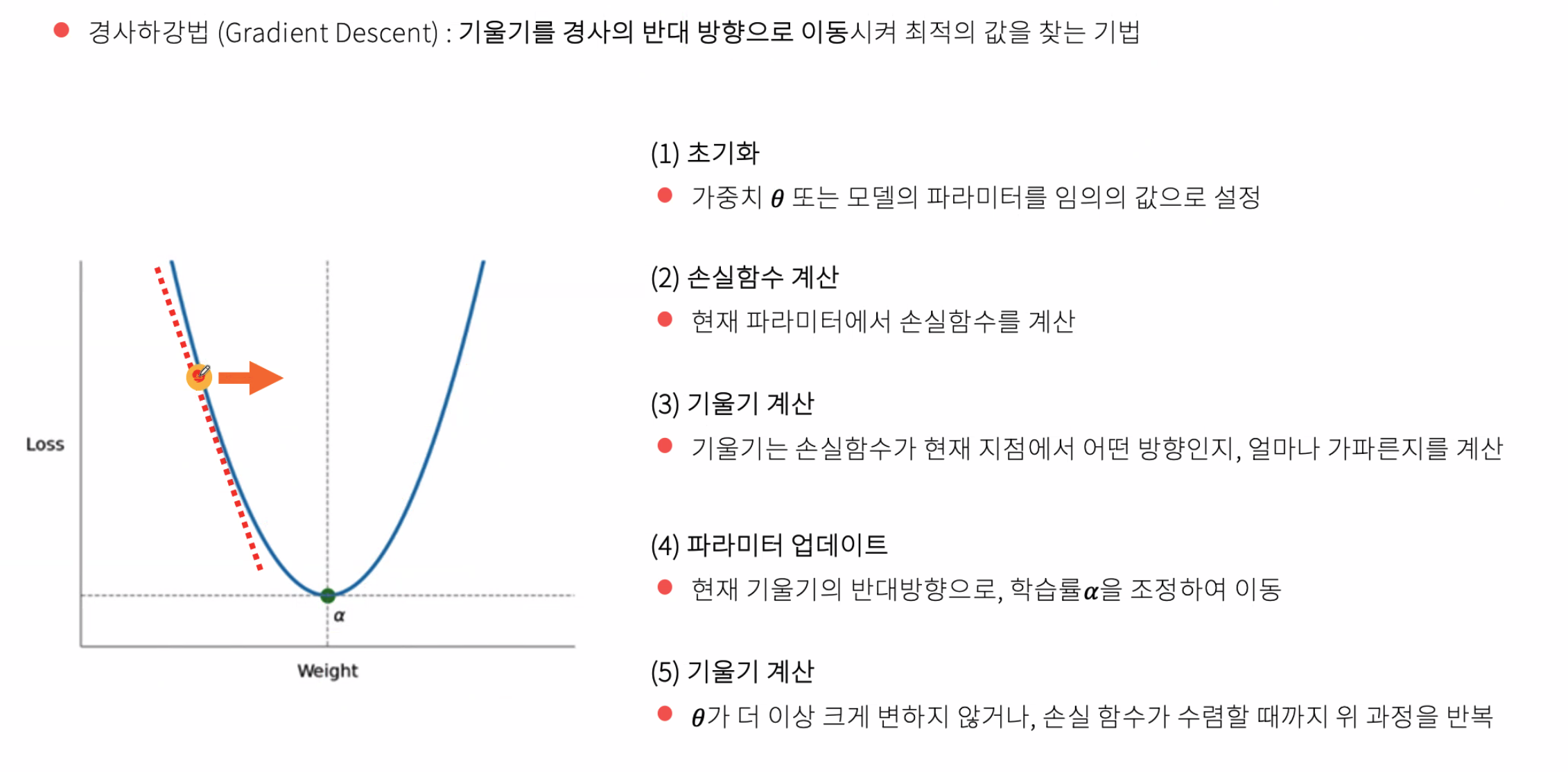
📌 기계학습 모델 및 신경망을 훈련하는 데 일반적으로 사용되는 최적화 알고리즘. 예측 결과와 실제 결과 간의 오류를 최소화하여 기계 학습 모델을 학습한다. 학습 데이터는 이러한 모델이 시간이 지남에 따라 학습하는 데 도움이 되며, 특히 경사 하강 내의 비용 함수는 매개변수 업데이트가 반복될 때미다 정확도를 측정하는 바로미터 역할
📌 예측 결과와 실제 결과 간의 오류를 최소화하여 기계 학습 모델을 학습한다. 오차가 최소가 되는 값을 찾는데 이 때 미분 기울기를 이용해 오차가 가장 작은 방향으로 이동하는 것을 경사 하강법(Gradiant Descent)라고 함
작동 방법
📌 선형 회귀에서 최적선을 찾는 것과 마찬가지로, 경사하강법의 목표는 비용 함수 또는 예측된 y와 실제 y사이의 오차를 최소화 하는 것.
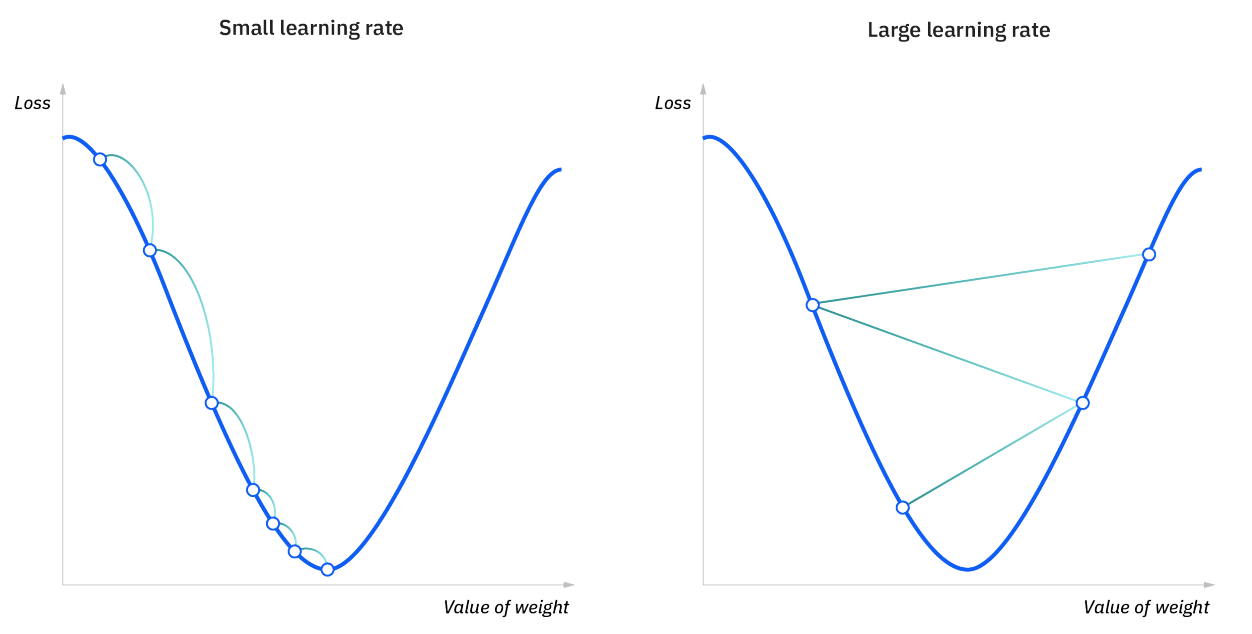
1. 학습 속도(Learning rate)
- 단계 크기(알파) = 최소 단계에 도달하기 위해 취하는 단계의 크기. 이 값은 일반적으로 작은 값이며 비용 함수의 조작에 따라 평가 및 업데이트
- 학습률이 높으면 더 큰 단계가 발생,but 최소 단계를 초과할 위험
- 학습률이 낮으면 단계 크기가 작아짐. 정밀도가 높다는 장점이 있지만 반복 횟수는 최소값에 도달하는 데 더 많은 시간과 계산이 필요하기 때문에 전반적인 효율성 떨어짐
2. 비용(손실) 함수
- 현재 위치에서 실제 y와 예측된 y 간의 차이 또는 오차를 측정. why? 모델에 피드백을 제공하여 기계 학습 모델의 효율성이 향상되어 매개 변수를 조정하여 오류를 최소화하고 로컬/글로벌 최솟값을 찾을 수 있음
- 비용 함수가 0에 가깝거나 0이 될 때까지 가장 가파른 하강법(기울기<0)을 따라 반복. 이 시점에 모델은 학습을 중지함
Loss Function vs Cost Function
모델을 학습시키기 위해서는 모델의 성능을 측정하고, 그 성능을 개선해야하는데 이 두 함수는 모델의 오차나 성능을 수치화하는데 사용된다.- 손실함수(Loss function)
- 모델의 단일 데이터 포인트에 대한 예측이 얼마나 잘못되었는지 측정
- 회귀 모델에서 평균제곱오차(Mean Squared Error)가 손실함수
- 모델이 얼마나 잘못되었는지??
- 손실 함수 값이 낮을수록 모델의 예측이 실제 값에 가까워짐
- 비용 함수(Cost Function)
- 전체 훈련 데이더셋에 대한 모델의 평균적인 성능 평가
- 손실 함수의 결과값들을 평균내어 계산. 예를 들어, MSE는 여러 데이터 포인트에 대한 MSE의 평균을 취한 것
- 모델의 전반적인 성능
- 모델을 최적화 하는것이 목적이고, 이 값이 최소화될 때 모델의 성능이 최적화 된다.
- 차이
- 손실 함수는 개별 데이터 포인트에 대한 모델의 오류, 비용 함수는 전체 데이터셋에 대한 모델의 평균적인 성능 측정
유형
📌 학습 알고리즘에는 배치 경사하강법, 확률적 경사하강법, 미니 배치 경사하강법의 세 가지 유형이 있다.
1. 배치 경사하강법
- 훈련 세트의 각 점에 대한 오차의 합을 구하며, 모든 훈련 예제가 평가된 후에만 모델을 업데이트. 이 프로세스를 학습 에포크라고 한다.
- 이 방법은 계산 효율성을 제공하지만 모든 데이터를 메모리에 저장해야 하므로 대규모 학습 데이터 세트의 경우 처리 시간이 여전히 길어질 수 있다. 배치 경사하강법은 일반적으로 안정적인 오차 기울기와 수렴을 생성하지만, 때로는 해당 수렴 지점이 가장 이상적이지 않아 국소 최소값(local minimum)과 전역 최소값(global minimum) 을 찾음
2. 확률적 경사 하강법
- SGD(Stochastic Gradient Descent) 는 데이터 세트 내의 각 예제에 대해 학습 Epoch 를 실행하고 각 학습 예제의 매개 변수를 한 번에 하나씩 업데이트
- 예제를 하나만 보유하면 되므로 메모리 저장 용이
- 잦은 업데이트는 더 많은 세부 정보와 속도를 제공할 수 있지만 배치 경사하강법
3. 미니 배치 경사 하강법
- 위 두 개념을 결합한 것. 학습 데이터 셋을 작은 배치로 분활하고 각 배치에 대해 업데이트 수행.
문제점
- 최적화 방법에 가장 일반적인 접근 방식이지만 자체적인 문제가 있다.
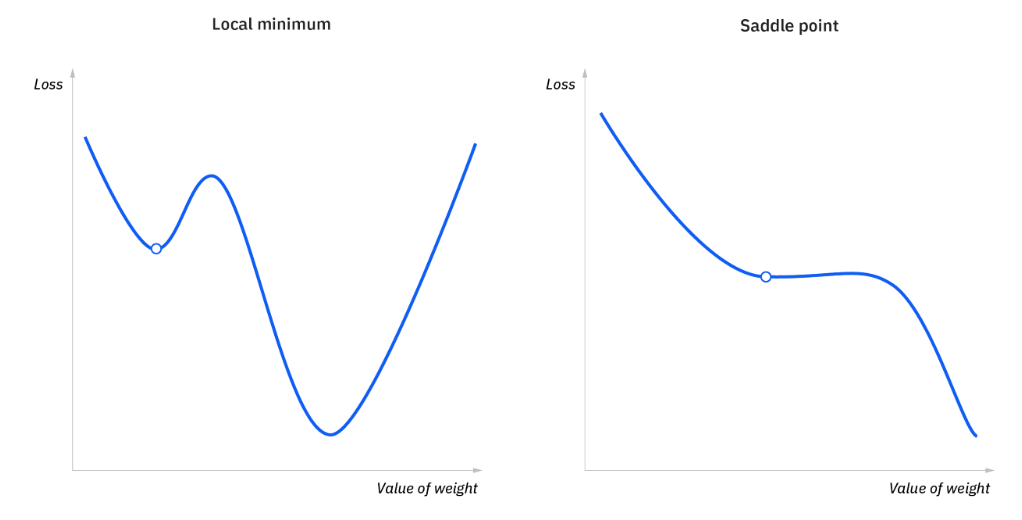
1. Local minimum & Saddle point
- 볼록 문제의 경우 경사하강법은 local minimum 을 쉽게 구할 수 있지만, 비볼록 문제가 발생하면 local minimum 찾는데 어려움
- 비용 함수의 기울기가 0이거나 0에 가까우면 모형이 학습을 중지. Local minimum을 초과하는 몇 가지 시나리오에서도 이 기울기가 생성될 수 있으며, 이는 local minimum과 saddle point
- Global
2. 기울기 소실(Vanishing Gradient)
- 심층 신경망, 특히 순환 신경망에서는 모델이 경사하강법과 역전파로 훈련될 때 두 가지 다른 문제가 발생
- Vanishing Gradients
- 그라데이션이 너무 작을 때 발생. 역전파 중에 뒤로 이동함에 따라 기울기는 계속 작아지므로 네트워크의 초기 계층이 이후 계층보다 더 느리게 학습함. 이 경우 가중치 매개변수는 중요하지 않게 될 때까지 업데이트 된다. 더 이상 학습하지 않는 알고리즘이 생성된다.
- Gradient Exploding
- 그라데이션이 너무 클 때 발생(=불안정한 모델) 이 경우 모델 가중치가 너무 커져 결국 NaN으로 표현된다.
- 해결책은 모델 내의 복잡성을 최소화하는 데 도움이 될 수 있는 차원 축소 기술 활용
지수의 역할
- MSE를 언제 사용해야 데이터적으로 좋을까? -
정규분포일 떄 좋다. why? 평균은 이상치에 민감하잖아. 그러니까 안정적으로 평균을 다룰 때(설득력을 다룰 떄) 정규분포를 따르면 좋다.
이상치가 잇으면 데이터를 대변하지 못하잖아. - 큰 오차를 줄이는 것이 중요한 상황에서도 유용하게 쓰임(절대적 손실 규모가 중요할 떄)
- 비용함수의 관점에서
- MSE에서는 제곱을 햇기 때문에 절대적인 오차가 더 중요한 의미를 볼 수 있따.
- MSE을 보면 MAE, RMSE를 보자
- MAE : 평균을 보기 위함
- RMSE : 큰 값을 보기 힘들 때 값을 줄임.
- 제곱은 양수화 해서 더 큰 오차에 더 큰 가중치를 봐서
RMSLE
- 예측 값과 실제 값의 상대적 차이를 계산하고 로그 변환
- 큰 값보다 작은 값의 오차를 더 중요하게 반영하는 특징(상대적 오차에 집중)
로그의 역할(작은 걸 더 크게)
- 로그변환은 정규분포화 하기 위함
회귀는 연속형 데이터
0,1은 로지스틱
❓
Q.좋은 학습을 위해 기울기를 줄여 나가야하는데, 기울기가 줄여 나가면 학습속도가 느려진대요. 이해했습니다.
학습속도 느리다 = 모델이 너무 복잡하고 매개변수가 많은 경우가 되어 필요햔 계산량이 많다는 소리 아닌가요?
A.별개의 관점인 것 같아요. 일단 좋은 학습을 위해 기울기를 줄인다기보다 학습을 진행하다보면 기울기가 줄어드는 경향을 보이는거구요 (극소점으로 수렴해야 하니까요), 기울기가 줄어들면 학습 속도가 느려집니다. 이건 모델이 학습을 해나가는 방향에 맞춰 이야기를 하는거구요. 전체적인 관점에서 모델이 복잡하고 매개변수가 많아서 학습속도가 느리다는 것은 말 그대로 계산량이 많아져서이지 기울기가 작아져서 학습속도가 느려지는 건 아니에요. 학습속도는 기울기가 작아지면서 (내부적 관점)도 느려지지만 모델 자체가 복잡하고 매개변수가 많으면 (외부적 관점) 연산량때문에 느려집니다
