CHAPTER 2: MP, MRP, MDP
1. 마르코프 프로세스 (MP)
마르코프 프로세스는 현재 상태만으로 다음 상태 전이 확률이 결정되는 순차적 모델이다. 즉, 과거 이력은 전이 확률에 영향을 주지 않는다는 특징을 가지고 있다.
예시) 아이가 잠드는 과정
- 상태: 누움 → 일어남 → 눈 감음 → 졸림 → 잠듦(종료)
- 각 상태는 정해진 확률에 따라 다음 상태로 전이된다.
- 예: “누움 → 눈 감음” 전이 확률 0.6, “일어남 → 일어남” 전이 확률 0.9
- 각 상태에서의 전이 확률의 합은 항상 1
구성 요소
- 상태 집합 S
- 전이 확률 행렬 P
- 각 행의 합이 1 (↔ 다음 상태의 확률 분포)
=> MP = (S, P)
2. 마르코프 리워드 프로세스 (MRP)
MRP는 마르코프 프로세스에 보상 개념이 추가된 모델이며, R(보상함수)과 γ(감마)를 추가로 포함하는 모델이다.
구성 요소
=> MRP = (S, P, R, γ)
- MP의 S, P 그대로 유지 (S : 상태의 집합, P : 전이 확률 행렬)
- R(s): 상태 도달 시 받는 기대 보상
- γ (0≤γ≤1): 미래 보상 할인 계수
(미래 얻을 보상에 비해 당장 얻는 보상을 얼마나 더 중요하게 여길 것인지를 나타내는 파라미터)
핵심 개념
- 리턴(Return): 현재부터 미래까지 할인된(감쇠된) 보상의 합
- 가치(Value): 상태에서 시작할 때 기대할 수 있는 리턴의 평균
γ 도입 이유
- 이론적 수렴 보장 (리턴 Gt가 무한의 값을 가지는 것을 방지)
- 당장 보상 선호 반영 (사람의 선호 반영)
- 미래 불확실성 반영
에피소드의 샘플링
- 에피소드: 시작 상태에서 종료 상태까지 한 번의 상태 전이 여정
- 샘플링: MRP의 확률 규칙에 따라 여러 번 돌려보는 것
과정
- 시작 상태에서 시작
- 매 단계마다 전이 확률에 따라 다음 상태를 랜덤 선택
- 종료 상태에 도달할 때까지 반복
- 그 과정에서 받은 보상들을 감쇠해서 더한 것 → 리턴(G) 계산
- 이렇게 여러 번 실행 = 여러 에피소드 샘플링
+) 여러 번 샘플링하는 이유 : 전이 확률 때문에 리턴 값이 매번 달라지기 때문, 그래서 평균을 내야 그 상태의 기대값(Value)가 나온다!
💡 상태 가치 함수 (State Value Function)
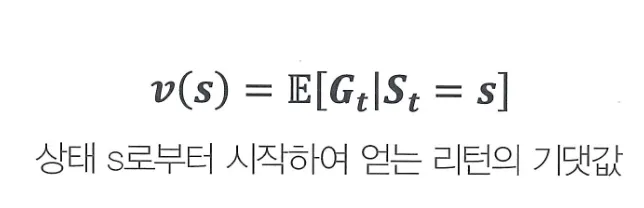
- v(s): 상태 s의 가치 (value)
- E[⋅] : 기대값, 즉 평균
- Gt: 시점 t부터 받는 감쇠된 보상의 총합 (리턴)
- 조건 (St=s): 지금이 상태 s일 때
→ 이 식은 지금 상태가 s일 때 앞으로 받을 보상 총합의 평균 → 상태의 미래 기대 이익을 의미
예시)
- 아이가 눈을 감은 상태(s₂)에 있을 때,
앞으로 졸려하고 → 잠들면 → +10 보상을 받을 수도 있지만
운 나쁘게 다시 일어나면 → −1 보상만 받고 종료될 수도 있다.
따라서,
- 어떤 에피소드에서는 리턴이 8일 수 있고
- 또 다른 에피소드에서는 4일 수 있다.
- 이들을 평균 내면 그 상태의 기대 리턴 = v(s2)
3. 마르코프 결정 프로세스 (MDP)
MDP는 앞서 설명한 MRP에 에이전트의 행동(Action) 요소를 추가한 모델이다.
에이전트가 행동을 선택하면, 그에 맞춰 확률적 전이와 보상이 결정된다.
구성 요소
=> MDP = (S, A, P, R, γ)
- S, γ는 MRP와 동일
- A: 에이전트가 취할 수 있는 행동 집합
- P(s’|s,a): 상태 s에서 행동 a 후 다음 상태가 s’일 확률
- R(s,a): 상태 s에서 행동 a를 취했을 때의 기대 보상
MDP 동작 순서
상태 s → 에이전트 행동 a 선택 → 확률적 전이 → 보상 R → 다음 상태 s’예시)
- 에이전트(어머니)의 행동: 자장가 부르기 vs 놀아주기
- 같은 상태에서도 선택한 행동에 따라 전이 결과와 보상이 달라진다.
4. Prediction vs. Control
| 구분 | 목표 | 예시 (Grid World) |
|---|---|---|
| Prediction | 고정된 정책 하에서 상태 가치 계산 | 랜덤 이동 시 각 칸에서 기대 리턴 예측 |
| Control | 최적 정책을 찾아 리턴 최대화 | 최단 경로로 종료점까지 빠르게 이동 |
Prediction
- 주어진 정책 π에 대해 상태 가치 Vπ(s) 또는 행동 가치 Qπ(s,a) 산출
Control
- 최적 정책 π를 학습해 V(s), Q*(s,a) 도출
출처 - 바닥부터 배우는 강화 학습
