우리는 일반적으로 DB 구조를 읽기(DB Read)와 쓰기(DB Write)를 단순히 분리하는 수준에서 그친다
Command ( = Transaction )
- 시스템 데이터 변경하는 기능
ex) 주문 취소, 배송완료
쿼리 ( = Query ) ( SQL Query 아님 )
- 시스템 데이터를 조회하는 기능
쿼리는 시스템의 상태를 단지 반환하기만 하고 상태를 변경시키지 않아야 한다.
ex) 주문 목록 조회
명령과 쿼리를 단일 모델에 둔다면?
우선 여러 테이블들이 한 테이블안에서 서로 엮이게 된다.
-> 예를 들어 member 테이블에 member에 대한 기능들 이외에, 회원의 예약 에 대한 정보와 회원의 장바구니 목록과 같은 정보들이 포함된다면 어떻게 될까?
처음 기능을 개발할 때는 편하겠지만, 이런식으로 여러 정보들이 쌓인다면, 복잡성이 증가한다.
-> 테이블의 의미가 명확해지지 않아 어떤 책임을 수행해야 할 때 경계가 모호해진다.
기능에 따라 사용하는 테이블의 필드도 달라진다.
-> 예를 들어 회원의 기본 정보 조회에는 회원의 예약 목록과 장바구니 목록과 같은 정보는 필요 없다.
CQRS (Command Query Responsibility Segregation)
책임 분리 ( Responsibility Segregation )
Responsibility ( 구성 요소 )
- 모델
- 함수 ( 코드 )
- 패키지
- 웹서버
- DB
Command Resposiblity 와 Query Responsibility 의 역할을 분리하는 것이 CQRS 가 되겟다.
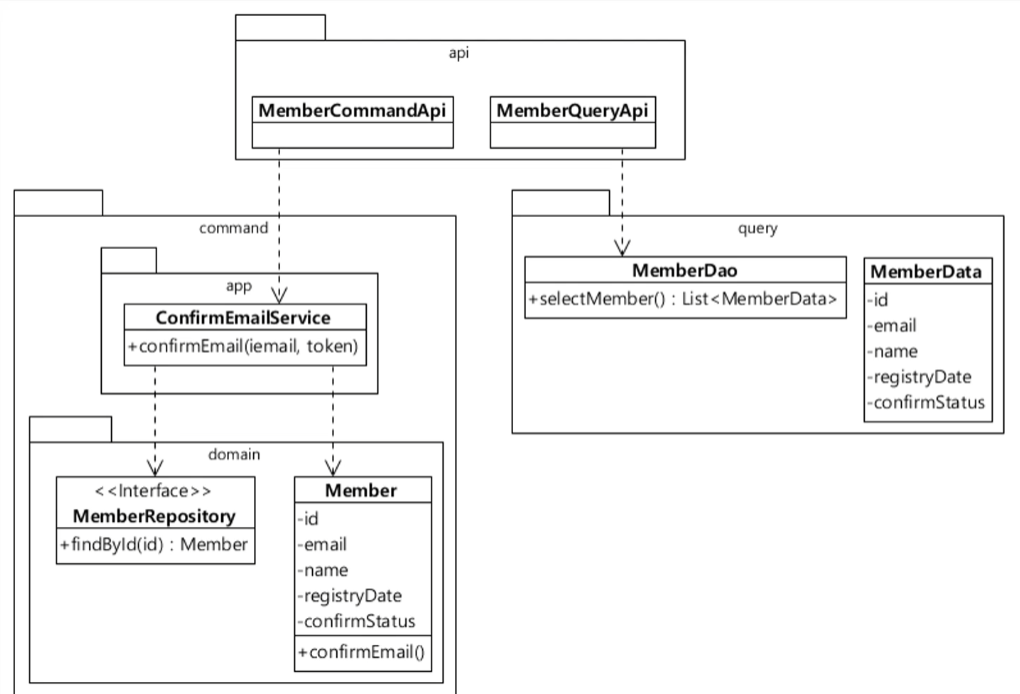
간단한 예로 위 그림에서 Command 와 Query 를 나누어 구현하였다.
그런데 이렇게만 보면 Member , MemberData 는 매우 비슷한 구조를 가지고 있는데 이는 불필요한 코드 중복처럼 보일 수 있다. 그런데 왜 CQRS 를 쓰는 걸까?
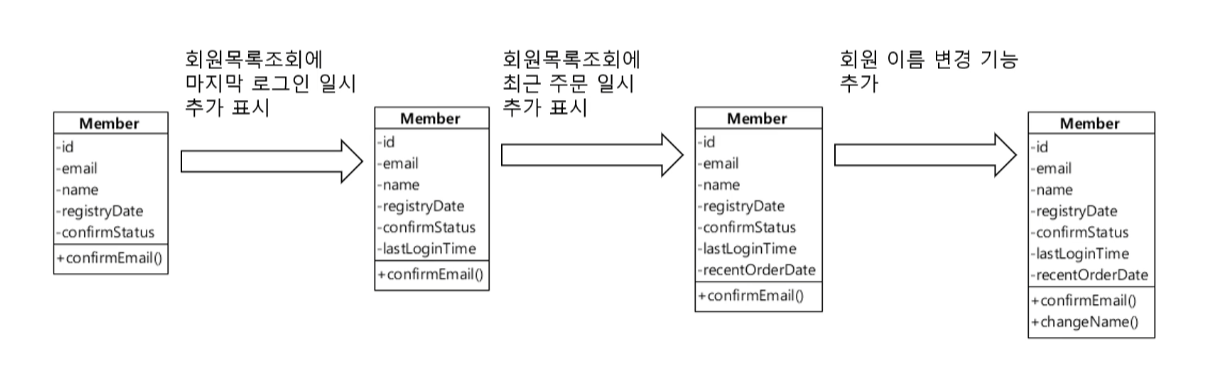
한 Member 를 사용하다 보면 Member 자체가 가지는 역할은 다양할 수 있지만 ,
정작 중요한 단일 책임 원칙을 벗어나게 된다.
Member 의 id email 정도만 확인하면 되는데 LoginHistory 나 RecentOrder 같은 불필요한 필드까지 조회하게 된다는 얘기다. 이는 곧 전체의 성능과 직접적으로 연관된다.

CQRS의 본질
CQRS의 본질 : 명령과 쿼리는 다루는 애초부터 다루는 데이터가 다르다.
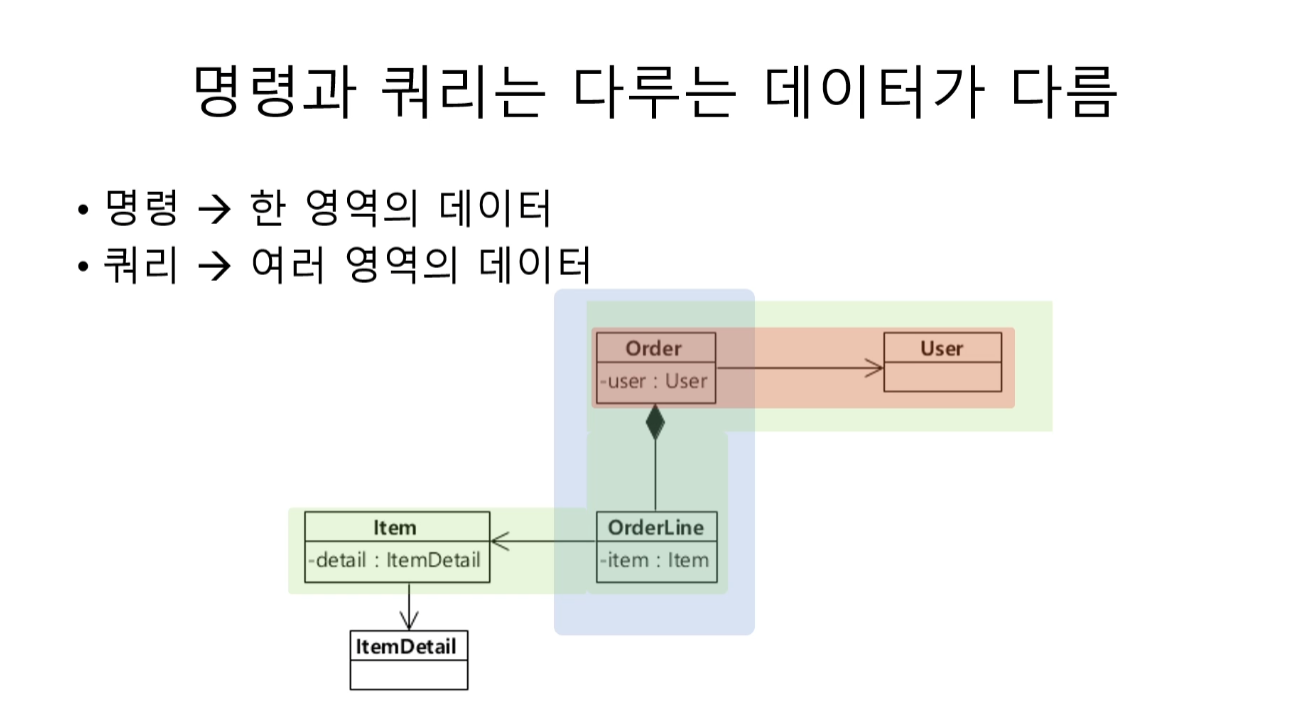
- 명령과 쿼리는 코드 변경 빈도 , 사용자도 다르다
서로 다른 이유로 다른 시점에 코드가 바뀐다.
변경 빈도가 다른 기능이 한 코드에 있으면 , 서로 다른 이유로 코드가 바뀌고 ,
이는 곧 책임의 크기가 적당하지 않다는 것이다.
- 기능마다 성능 요구가 다르다
기능마다 서로 다른 알맞은 성능 향상 방법이 필요한데, 단일 모델로는 다양한 성능 향상 기법의 적용이 어려울 수 있다.
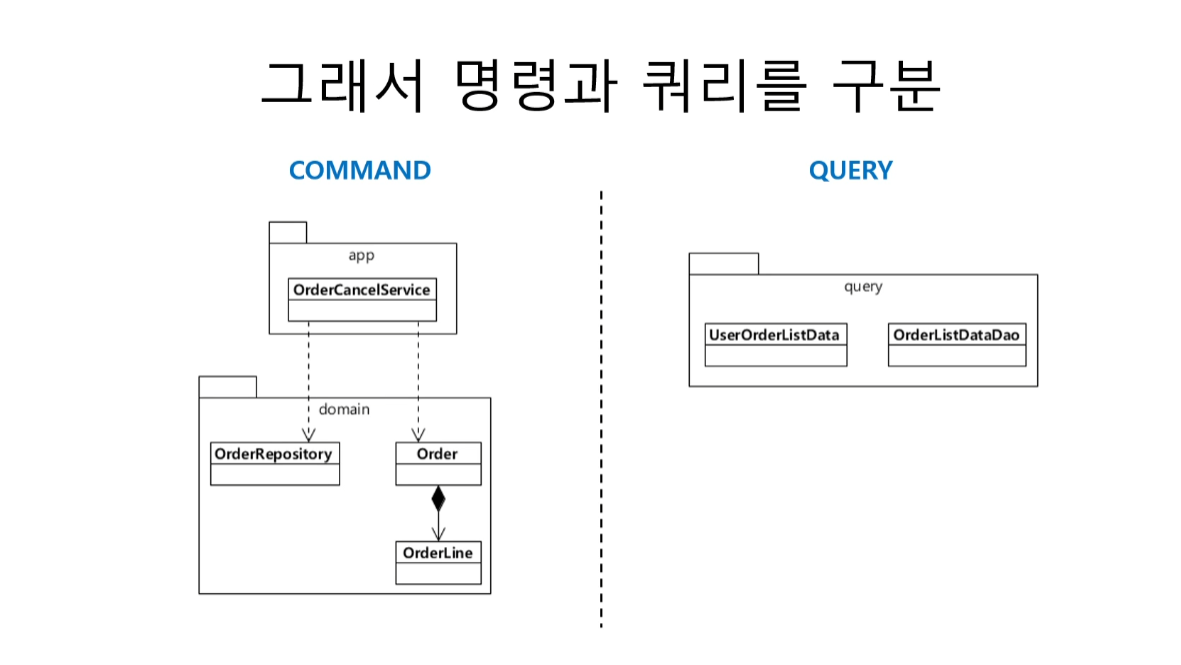
그래서 명령과 쿼리를 구분한다.
CQRS 의 구현
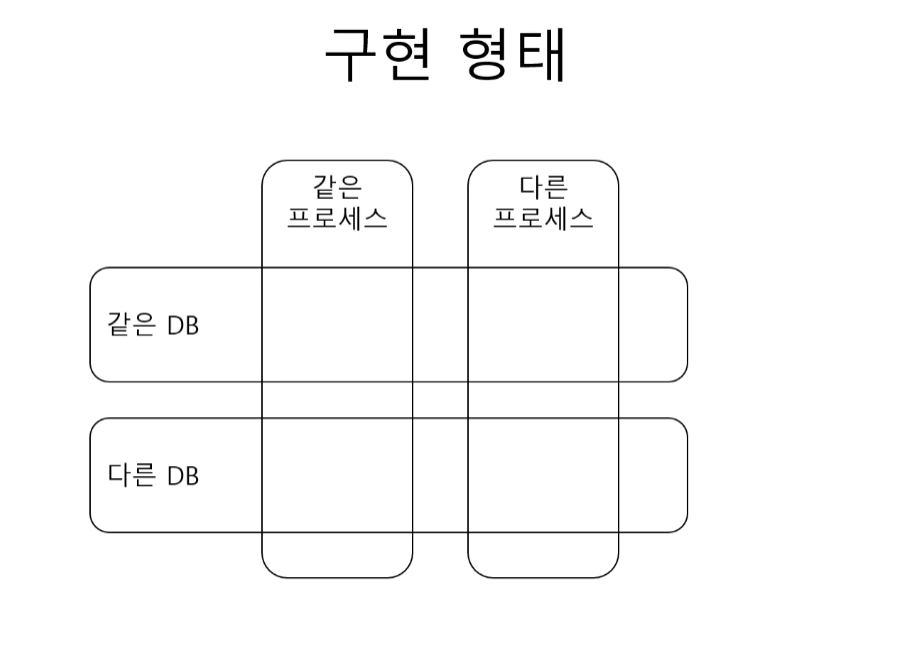
CQRS 관점에서 “DB가 한 프로세스에 있다”는 말은 보통 읽기/쓰기(커맨드/쿼리)가 같은 애플리케이션 프로세스(=같은 서비스) 안에 있다는 뜻이다.
하나의 서비스(프로세스) 안에
-
Command 핸들러(주문취소/배송완료 등)
-
Query 핸들러(주문목록조회 등)
그리고 같은 DB(또는 같은 DB 커넥션/스키마)를 붙여서 처리
이 경우 CQRS는 코드/책임 분리는 했지만, 배포/운영 관점에서는 단일 프로세스 + 단일 DB라서
트랜잭션은 보통 Command에서만 강하게 쓰고, Query는 같은 DB에서 읽기만 하되,
성능/스케일 이슈는 여전히 같은 DB가 병목이 될 수 있다.
같은 프로세스 , 같은 DB
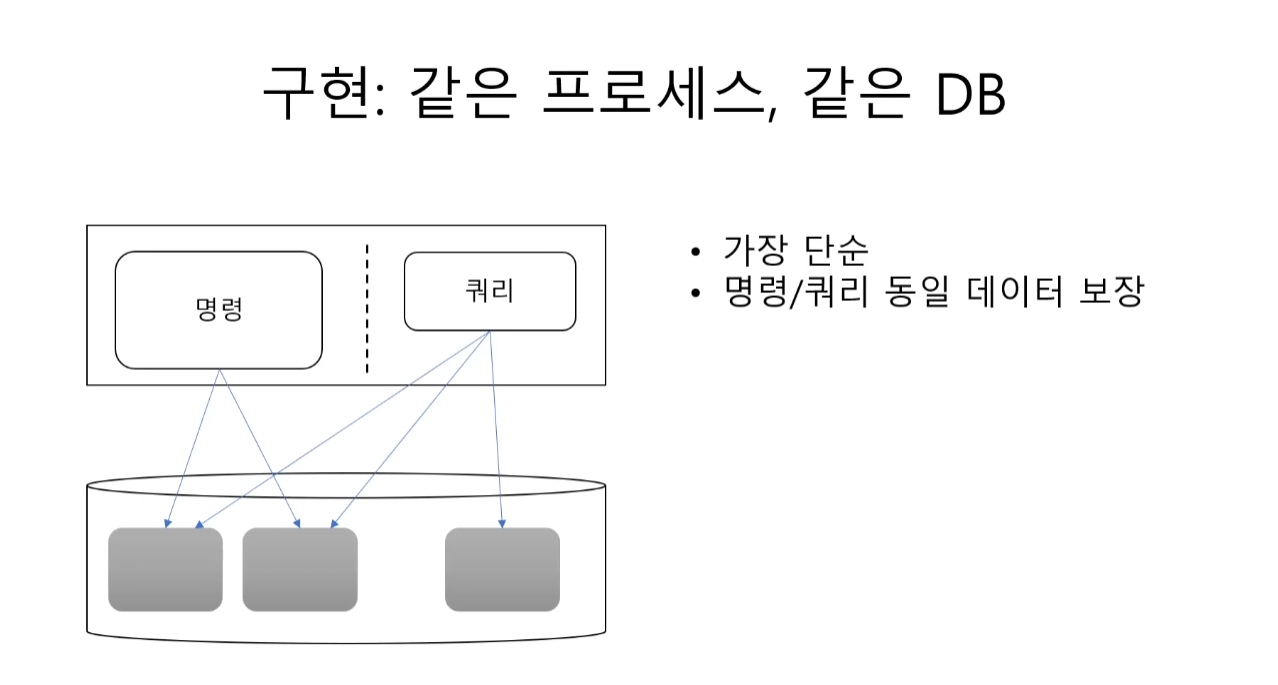
앱 수준에서도 DB 수준에서도 분리가 없는 상태.
구현은 가장 단순하고 , 명령/쿼리가 동일한 데이터를 보장한다
같은 프로세스 , 같은 DB , 다른 테이블
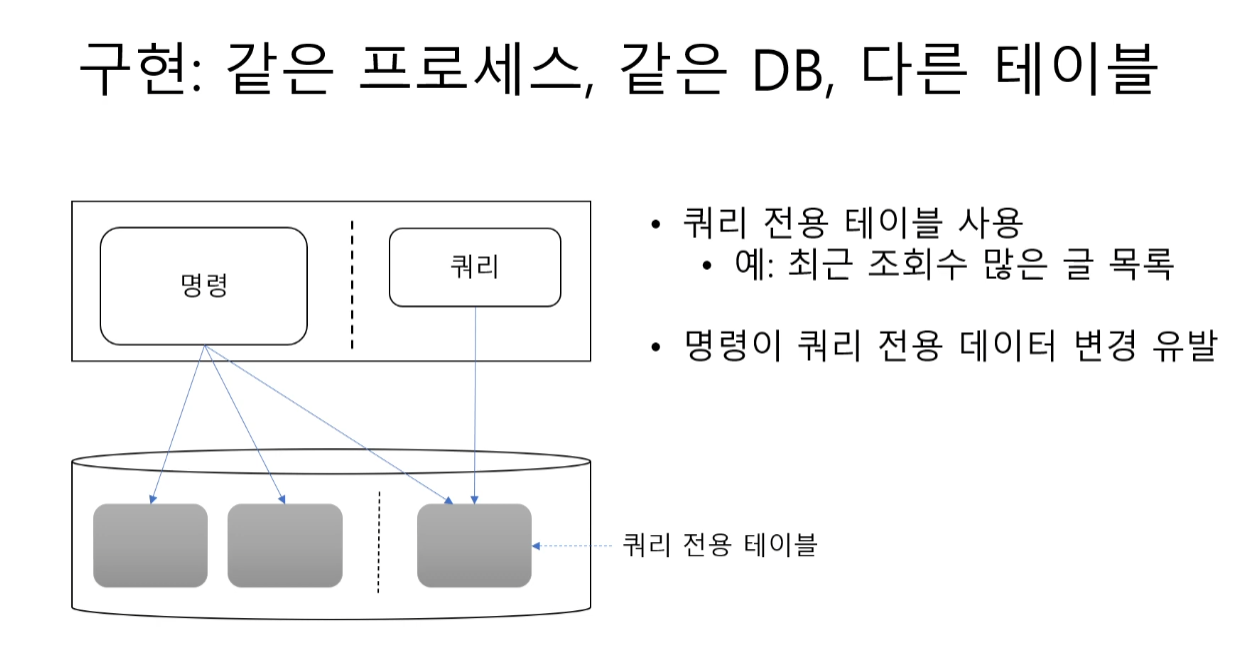
위와 앱 수준에서는 비슷하고 DB 수준에서 테이블만 논리적 분리 (쿼리 전용 테이블) 하였다.
테이블은 분리되었어도 같은 DB에 저장 ( 물리적 분리 X ) 되어있다.
-> 리소스(CPU/IO/락/커넥션 풀/스토리지)를 공유, 조회가 무거워지면 쓰기 성능에도 영향, 반대도 영향
같은 프로세스 , 다른 DB
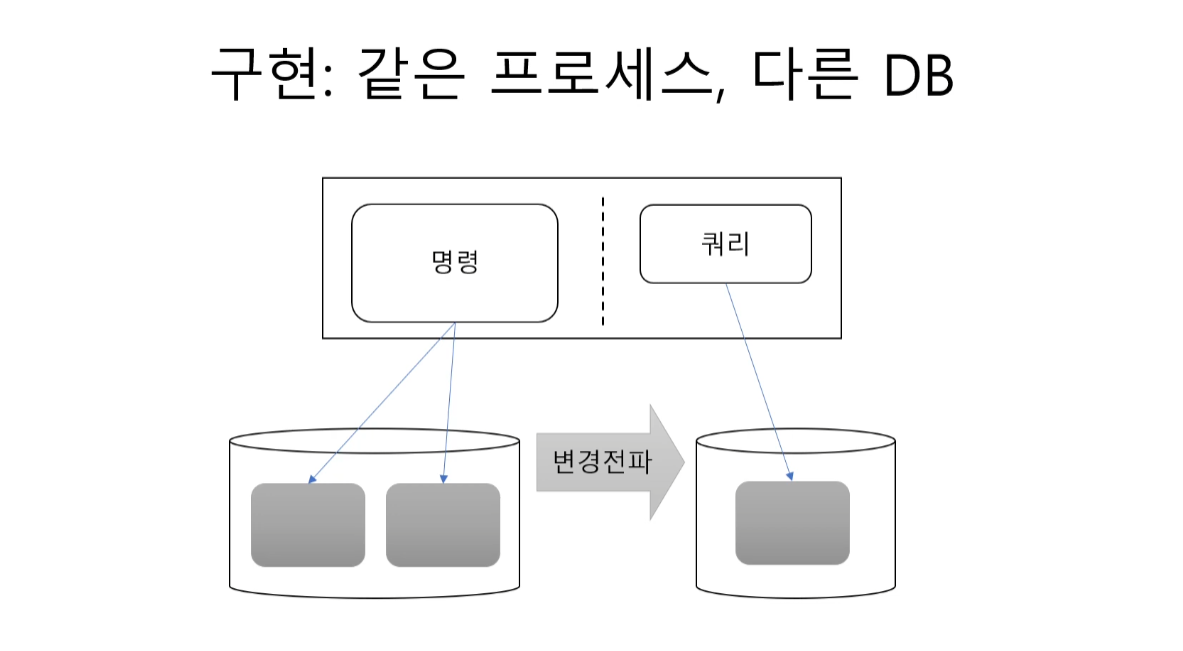
예를 들어 NoSQL을 사용하여 분리한 두 DB 저장소가 존재하고 명령으로 바뀐 데이터를 쿼리쪽으로 변경전파를 하여 쿼리를 통해 데이터를 읽는 방식이 존재한다.
다른 프로세스 , 다른 DB
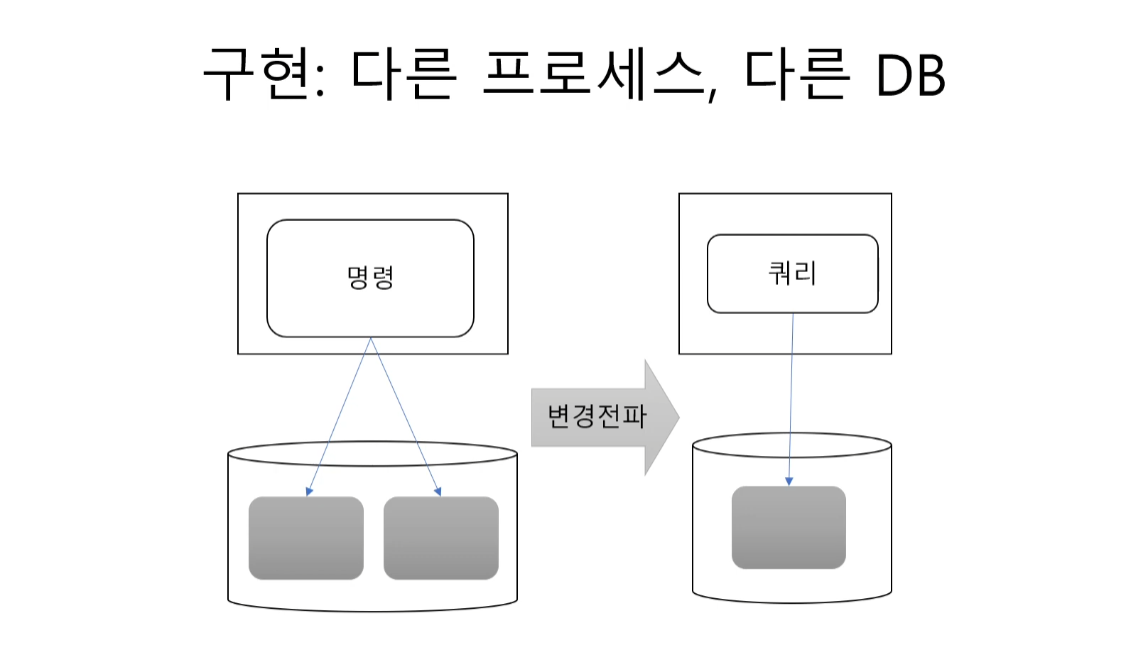
MSA 처럼 앱 수준에서도 분리가 되고 , DB 수준에서도 분리가 된 MSA 식 구현이다.
리소스를 온전히 사용한다. 독립 배포 , 독립 확장 , 장애 격리 , 병렬 개발등 MSA의 장점을 그대로 가져간다.
데이터 전파
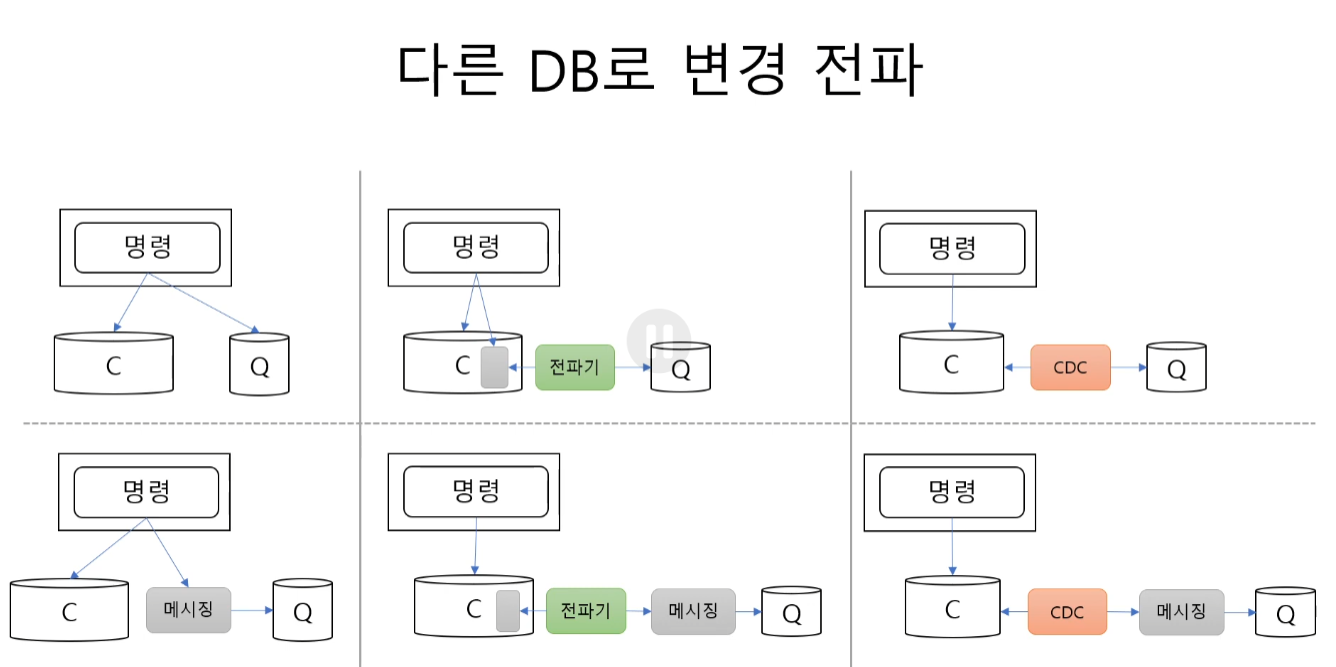
명령으로 인해 변경된 데이터를 쿼리가 올바르게 받으려면 명령쪽 데이터를 쿼리쪽으로 전달해줘야 한다.
그 과정에서 여러가지 전달 방법이 있다.
- 수동 ( + 메시징 )
- 전파기 ( + 메시징 )
- CDC ( + 메시징 )
명령 수준 처리 (동기 수동 전파)
예: 주문 취소 처리하면서 orders 업데이트 + order_list_view도 같이 업데이트)를 할때
구현은 단순하다.
그러나 데이터 유실 가능성이 존재한다.
Query DB 에 일시적인 문제가 발생시 Query DB에 반영해야 할 데이터가 유실 될 수 있다.
또는 메세징 에러 때문에 명령에 에러가 날 수 있다
전파기 (비동기 수동 전파)
변경 내용을 기록하고 별도로 전파기를 통해 변경 내역을 전파하는 것
하나의 트랜잭션 명령 수준에서 처리, 변경 내역을 별도 테이블에 기록 -> 데이터가 유실되지 않는다.
CDC (Change Data Capture)
DB 수준에서 제공하는 바이너리 로그를 읽어 변경된 데이터를 Query 테이블로 전달하는 방식.
명령쪽에서 코드를 전파기로 전달하는 별도의 과정 구현이 필요 없다.
