HTAP (Hybrid Transactional/Analytical Processing)
HTAP(Hybrid Transactional/Analytical Processing)는 하나의 데이터베이스 시스템에서
트랜잭션 처리(OLTP)와 데이터 분석(OLAP)을 동시에 수행하는 아키텍처를 의미한다.
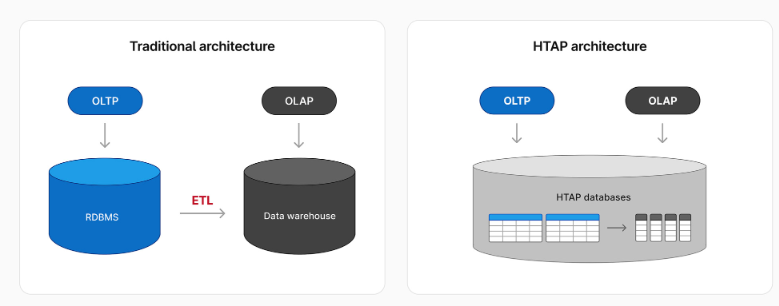
기존에는 OLTP 와 OLAP 를 나누어 사용했었다.
OLTP 와 OLAP 를 나눔으로써 OLTP 는 일상적인 트랜잭션(쓰기 기능)에 집중하고 OLAP 는 쓴 데이터를 ETL 파이프라인을 통해 가공하여 읽기 기능을 향상시키고
기능 분리를 하여 단일 책임을 만다는데 목적이 있었다.
OLTP 돌아보기
OLTP는 일반적으로 운영 애플리케이션에서 사용되는 데이터베이스다. 애플리케이션의 사용자 또는 비즈니스 일 수 있다. 가장 중요한 것은 비즈니스에 수익을 창출하는 애플리케이션이라는 점이다.
데이터베이스에서 발생하는 작업(또는 트랜잭션)은 CRUD다. 예를 들어, 주문 생성, 메뉴 탐색, 주문 변경, 주문 취소 등이 있다. 이러한 트랜잭션은 데이터베이스가 ACID 속성을 가져야 하는 기록 수준에서 작동한다. 이러한 속성은 예기치 않은 오류가 발생하려하는 시점에 데이터베이스에 적용된 일련의 변경 사항이 유효한 상태로 유지되도록 다양한 수준의 Isolation을 통해 보장한다.
OLAP 돌아보기
OLAP는 일반적으로 분석을 위한 데이터를 집계(Aggregate)하는 데 사용되는 데이터베이스다. 예를 들어 합, 최소, 최대 등. OLAP 데이터베이스는 일반적으로 열 지향 데이터 저장소로, 분석 쿼리를 수행하는 데 더 나은 최적화를 제공한다. 이러한 최적화는 OLAP 데이터베이스의 목표가 최적의 쓰기가 아니라 최적의 분석 쿼리(읽기)를 갖는 것이기 때문에 ACID 속성을 갖지 못한다. 이 데이터베이스들은 그래프와 보고서, 데이터 마이닝, 그리고 인공지능을 위한 데이터를 제공하는 데 사용된다.
그렇지만 OLTP 와 OLAP 를 분리하는 것까진 좋았는데 OLTP 에서 OLAP 로 데이터 교환이 이뤄지는 부분에서 생기는 문제점이 있다.
-
데이터 지연(Latency): ETL 과정이 몇 시간에서 며칠까지 걸리므로, "지금 당장" 발생하는 데이터를 분석에 즉시 반영하기 어렵다.
-
비용 및 복잡성: 두 종류의 DB를 운영해야 하므로 인프라 비용이 이중으로 들고 관리가 복잡하다.
-
데이터 중복: 동일한 데이터를 운영용과 분석용으로 중복 저장해야 한다.
HTAP의 주요 특징
Real-time Insights: 데이터가 생성되는 즉시 분석이 가능하여 실시간 의사결정이 가능해진다.
단일 소스(Single Source of Truth): 데이터를 복사하거나 이동할 필요 없이 하나의 시스템에서 관리한다.
메모리 중심 아키텍처: 최근의 HTAP 솔루션들은 In-Memory 기술을 사용하여 디스크 I/O 병목을 줄이고 속도를 극대화한다.
HTAP
하이브리드 트랜잭션 분석 처리(HTAP) 데이터베이스는 OLTP와 OLAP 작업 를 동시에 수행할 수 있는 데이터베이스이다.
예를 들어 쓰기를 수행하는 "비행 중" 거래에 대한 분석 쿼리를 실행할 수 있다. HTAP 데이터베이스는 ACID 트랜잭션을 지원하는 속성을 가지고 있을 뿐만 아니라 컬럼형 OLAP 데이터베이스와 같은 데이터를 제공할 수 있는 방법을 제공한다.
하이브리드 데이터베이스의 가장 큰 장점은 여러 개의 지속적인 데이터 복사본을 제거하고 ETL을 수행할 필요가 없다는 점 ( ZERO - ETL )이다. 이것은 비용적인 면에서 큰 절감이 된다.
HTAP 는 기본 구조 자체가 다중 노드, 분산형이다. 다중 노드 중 일부는 OLTP 를 , 일부는 OLAP 를 다루는데 이것이 하나의 데이터를 하나의 엔진 안에서 관리함으로써 유용한 기능을 수행할 수 있게 한다. OLTP 와 OLAP 분리시 이 둘의 일관성을 유지하는 것은 매우 어렵다.
Spicy Graph
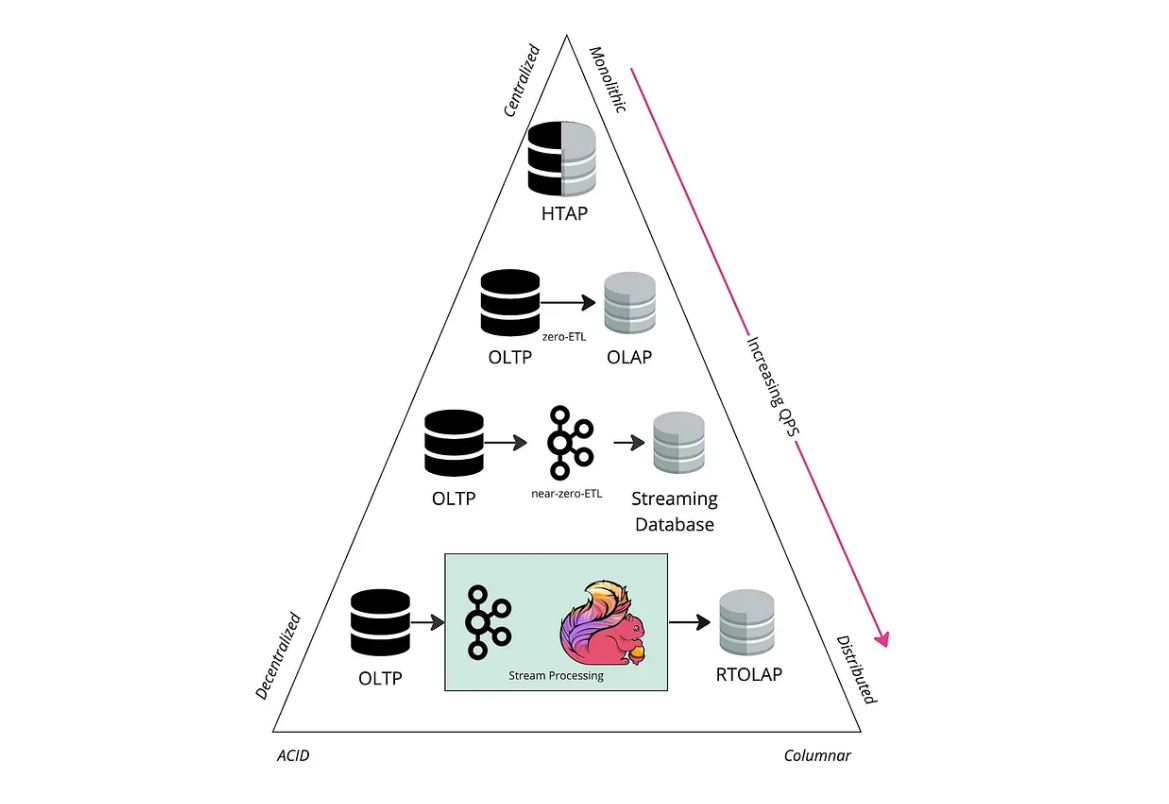
위 그림은 스파이스 그래프 라는 사진인데 이해를 돕기 위해 첨부해보았다.
아래로 올수록 하나의 노드가 받는 QPS ( Query Per Second ) 는 많아진다. 위로 갈수록 하나의 노드가 받는 QPS 는 적어진다.
왼쪽으로 갈수록 행 지행 ( Row ) , 오른쪽으로 갈 수록 열 지향 ( Column ) 데이터베이스를 의미한다.
그림에서 Centralized 와 위에서 말한 분산형이 갈리는 이유는 설명적으로 분산형 인것뿐이고 물리적으로는 두 가지 포맷(Row/Column)으로 저장되지만, 논리적으로는 하나의 데이터로 관리되는 것이라고 이해하면 될 것 같다.
1. 하이브리드 스토리지 엔진
전통적인 DB는 데이터를 가로(Row)로 저장하거나 세로(Column)로 저장하는 방식 중 하나만 선택해야 했다. 하지만 HTAP는 이를 동시에 관리하는 전략을 취한다. 이들이 분리되어 있기 때문에, 분석 쿼리가 아무리 무거워도 실제 서비스 중인 트랜잭션 성능을 갉아먹지 않는 자원 격리가 가능해진다.
-
이중 저장 방식: 하나의 데이터가 입력되면, 시스템은 내부적으로 이 데이터가 트랜잭션인지 쿼리인지 적절히 분석하여 '행 기반 저장소'와 '열 기반 저장소'로 라우팅하고 동시에 업데이트한다. 이것이 ETL 과 다른 이유는 ETL은 데이터가 이미 저장된 후 별도의 파이프라인을 거쳐 주기적으로 복사하는 사후 처리(Post-processing) 방식인 반면, HTAP는 데이터가 들어오는 순간 엔진 내부에서 실시간으로 두 저장소에 반영하는 동시 처리 방식이기 때문이다.
-
Log-Structured 방식 활용: 쓰기 작업(LSM-Tree 등)은 빠르게 행 단위로 기록하고, 백그라운드에서 이 데이터를 분석에 최적화된 열 단위 포맷으로 자동 변환하여 저장한다.
-
메모리 최적화: 실시간 데이터(Hot Data)는 행 기반 메모리에 두고, 분석용 대량 데이터(Cold Data)는 열 기반 디스크나 메모리에 배치하여 효율을 높인다.
2. 가상화 및 스냅샷 격리 (Isolation)
분석 쿼리가 실행되는 동안 서비스(트랜잭션)가 느려지면 안 된다. 트랜잭션이 느려지는 이유는 동시성과 일관성을 맞추다 보면 속도를 늦출 수 밖에 없다. 이를 위해 HTAP는 MVCC(Multi-Version Concurrency Control) 기술을 극대화한다.
-
Snapshot 활용: 분석 쿼리가 시작되는 시점의 데이터 상태(Snapshot)를 고정하여 읽는다. 이 덕분에 운영용 DB에서 계속해서 쓰기 작업이 일어나도 분석 쿼리는 영향을 받지 않고 일관된 데이터를 읽을 수 있다.
-
복제본 활용 (Raft/Paxos 기반): 분산처리 알고리즘 중 Raft, Paxos 라는 알고리즘이 존재하는데, 분산 HTAP DB의 경우, 우선 데이터를 여러 노드에 알고리즘 기법을 적용하여 복제한다. 이때 일부 노드는 트랜잭션 전용(Leader)으로, 다른 노드는 분석 전용(Learner/Follower)으로 역할을 분담시켜 자원에 대한 간섭을 원천 차단하여 추가적인 작업을 사전에 방지한다.
3. 지능형 쿼리 옵티마이저 (Smart Routing)
기존 OLTP , OLAP 에도 Optimizer 가 존재하지만 , HTAP DB 엔진에는 들어오는 쿼리가 단순 조회/수정인지 복잡한 집계 분석인지 스스로 판단하는 Optimizer가 존재한다.
-
비용 기반 선택: 옵티마이저는 쿼리의 성격에 따라 행 기반 저장소에서 데이터를 가져올지, 아니면 열 기반 저장소를 스캔할지 실시간으로 결정한다.
-
실시간 정합성 보장: 분석 저장소가 최신 트랜잭션을 반영하지 못했다면, 옵티마이저가 부족한 부분만 행 기반 저장소에서 보충하여 결과를 합쳐서 내놓습니다. 덕분에 사용자는 ETL 없이도 항상 '최신 상태의 분석 결과'를 얻게 된다.
결론
ETL 이라는 중간 과정이 사라짐으로써 HTAP 는 속도 부문에 있어서 엄청난 강점을 지닌다. 물론 그에 따른 리스크가 존재한다. In-Memory 기반이기에 데이터를 처리하려면 고용량 RAM 이 있어야 하는데 최근 좋은 RAM 값은 거의 보통 PC 한대 값과 맞먹는다. 당연히 속도를 올리기 위한 비용이 존재할 수 밖에 없다. 디스크 기반 HDFS 부터 In-memory Spark 에 고속 In-memory Flink , HTAP 까지 In - Memory를 통해 극한까지 데이터 속도를 끌어올리려고 여러 아키텍쳐가 나오고 성장하는 과정이 존재하고 우리는 그 중간에 있다.
