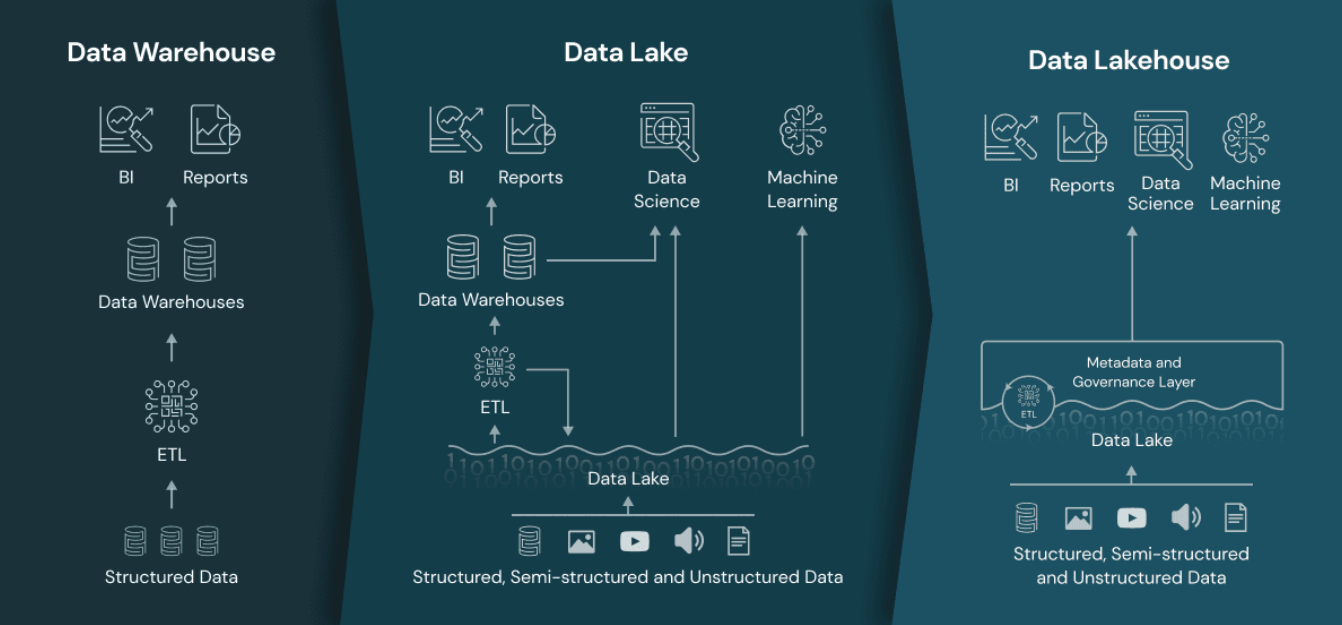
Data 플랫폼의 진화 과정
Data WareHouse (DW)
Data Warehouse란?
기업에서 운영되는 여러 시스템(DB)에서 데이터를 모아
분석 전용 저장소에 넣고 BI/리포트/결정 지원을 위해 사용하는 플랫폼.
초기 1세대 데이터 분석 플랫폼은 데이터 웨어하우스다.
OLTP 시스템에서 데이터를 모아 DW 에 저장했다.
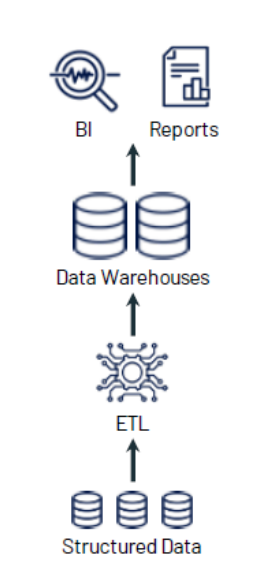
이렇게 모아진 데이터는 의사결정 지원 시스템(DSS)이나 비즈니스 인텔리전스(BI) 분석에 사용.
DW 의 데이터 특징
Schema on Write 사용 → 데이터를 넣을 때 엄격한 스키마(컬럼 구조)를 미리 정의해야 한다.
DW 의 문제점
0) 전통적인 RDBMS 구조를 그대로 확장
-
데이터는 디스크에 저장
-
쿼리는 해당 디스크를 가진 서버(노드)의 CPU가 직접 처리
-> 스토리지를 분리하면 CPU가 가져올 데이터가 없어짐 → 설계 불가능
...
[노드1] CPU + RAM + Local Disk
[노드2] CPU + RAM + Local Disk
...
0-1) MPP (Massively Parallel Processing) 방식은 데이터를 노드 로컬로 분할 저장
MPP DW는 데이터를 노드별로 파티션하여 저장(Distributed Storage)하고
각 노드가 로컬 디스크를 읽어 병렬로 쿼리를 수행해 속도를 냄.
→ 로컬 디스크가 없으면 성능이 죽음.
→ 디스크만 늘리거나 CPU만 늘리는 방식 자체가 존재하지 않았음.
1) 비용 문제
-
컴퓨팅 자원(CPU/RAM)과 저장소(Storage)가 묶여 있는 구조라, 피크 시간대(사용량이 폭증할 때) 확장하려면 비용이 매우 많이 들었다.
-
컴퓨트와 스토리지가 묶여 있어서 스토리지만 늘리고 싶은데도 컴퓨트 리소스까지 같이 늘어나 비용 폭증
-> 성능을 올리려면 서버 자체를 크게 업그레이드해야 하는 구조
2) 비정형 데이터 처리 불가
- 전통적 RDB 구조 기반 → 숫자/문자 데이터는 OK
But 영상/음성/텍스트 등은 스키마에 맞지 않아 저장·분석 어려움
Data Lake
모든 형태의 데이터(정형, 비정형 , 반정형 데이터) 를 원래 그대로저비용 스토리지에 저장해두는 대규모 저장소
-
주로 범용적이고 오픈된 파일 포맷(Parquet, ORC, JSON 등)을 저장
-
싼 비용으로 대용량 데이터를 저장하기 위해 HDFS(Hadoop Distributed File System)를 사용.
-
최근에는 AWS S3, Azure ADLS, GCP GCS 같은
클라우드 오브젝트 스토리지가 HDFS를 대체하고 있다 -
Schema-on-Read 구조이다
-> 싸고, 유연하고, 정형+비정형 모든 데이터 저장 가능
DW VS DL
❌ DW 한계
-
스토리지와 컴퓨트 결합 → 비용 ↑
-
비정형 데이터 저장 불가
-
스키마 강제 → 유연성 낮음 (Schema-on-write)
✔ Data Lake의 해결
-
스토리지(S3/GCS/ADLS)가 매우 저렴함
-
어느 형태의 데이터든 저장 가능
-
스키마는 분석 시점에 적용(Schema-on-Read)
-
컴퓨트(예: Spark, Presto)는 필요할 때만 사용
Data Lake의 문제점
ACID 트랜잭션 없음
파일 기반으로 Update , Delete 등이 어렵다
Table Version 관리 없음
어떤 시점의 데이터인지 추적이 힘들다
데이터 퀄리티 (DQ)
아무 데이터나 저장할 수 있는 것이 단점이 된다. 이를 Data Swamp (데이터 늪)이라고 한다.
Data LakeHouse
DW 와 DL 의 동시사용
BI를 위한 Data Warehouse와 AI/ML을 위한 Data Lake를 함께
사용하는 2계층 아키텍처는 현대 데이터 환경에서 여러가지 심각한 문제점들을 야기한다.
Data Lake
모든 종류의 원시 데이터(정형, 비정형 등)를 먼저 저비용 데이터 레이크(Amazon S3 등)에 저장
BUT → ACID 부족, 업데이트/삭제 어려움,
Data Warehouse
ACID, 품질 좋음, 비정형 데이터 저장 어려움, 비쌈, ML 워크로드에 부적합
AI/ML 작업은 데이터 레이크의 데이터에 직접 접근하거나, 웨어하우스의 데이터를 다시 파일로 추출하여 사용
DW + DL 의 한계
Reliability
두 시스템 간의 데이터를 다시 일치시키기 위한 복잡한 ETL 파이프라인은 잦은 오류와 데이터 품질 저하의 원인이 된다.
Data Staleness
데이터가 레이크에서 웨어하우스로 복제되는 데 시간이 걸려 분석가들은 오래된(Stale) 데이터를 보게 된다 (실시간성 떨어짐)
Limited Support for Advanced Analytics
AI/ML 프레임워크는 데이터 웨어하우스로는 독점적인 데이터 포맷에 직접 접근하기 어려워, 비효율적인 ODBC/JDBC를 사용하거나, 데이터를 다시 파일로 추출해야 하는 번거로움이 발생한다.
Total Cost of Ownership
동일한 데이터가 두 곳에 중복 저장되고, 복잡한 ETL 파이프라인을 유지보수하기 위해 많은 비용과 엔지니어링 자원이 소모된다.
그래서 두 개의 장점만 합쳐서 만든 것이 Lakehouse이다.
Data LakeHouse 의 특징
Data Warehouse의 안정성과 성능 + Data Lake의 유연성과 저비용을 결합한 아키텍처
트랜잭션 로그(Commit Log)를 추가하여 ACID 제공
기존 파일은 절대 수정하지 않고, 새로운 파일 + 트랜잭션 로그만 추가하는 방식
Delta Lake, Iceberg, Hudi 같은 Lakehouse 테이블 포맷은 Data Lake 위에 트랜잭션 레이어를 씌운 구조이다.
스키마 관리 및 적용 (Schema-on-Read)
Transcation MetaData Layer 를 추가해 다음 기능을 제공함:
- 스키마 추적
- 스키마 강제(Enforcement)
- 스키마 진화(Evolution)
- 스키마 감사(Log & History)
- Time travel 기반 스키마 버전 관리
Transaction Metadata Layer : 데이터 레이크의 파일들(Parquet 등) 위에, 어떤 파일들이 특정 테이블의 어떤 버전을 구성하는지를 기록하는 “트랜잭션로그(Transaction Log)”를 추가하는 기술
엔진(Spark, SQL 엔진 등)이 직접 파일을 읽음
→ Vendor lock-in이 없음
→ Cloud-native 구조
→ 자유로운 컴퓨트 연결 가능 -> 스토리지 - 컴퓨팅 분리
- Parquet, ORC 같은 오픈 포맷(컬럼 기반 파일 포맷)을 직접 접근할 수 있는(open direct-access) 구조를 기반으로 한다.
성능 최적화 기법
• Caching: 자주 사용하는 데이터를 빠른 SSD나 메모리에 캐싱
• Auxiliary Data: 파일의 통계 정보(최소/최대값 등)를 활용하여 불필
요한 데이터 읽기를 건너뛰는 데이터 스키핑(Data Skipping)
• Data Layout Optimization: Z-Ordering과 같은 기법을 사용하여
관련 데이터를 물리적으로 가깝게 배치하여 조회 성능 향상
ML/AI Workload를 위한 First-Class 지원
-
대규모 데이터 기반 Feature Engineering 용이
-
Parquet/ORC 기반 → 고성능 vectorized I/O
-
Delta Lake / Iceberg / Hudi 같은 테이블 형식 → 버저닝, snapshot, rollback
-
Python/Spark/MLflow/ML Framework 와 자연스럽게 통합
-> TensorFlow, PyTorch와 같은 주요 ML 프레임워크는 Parquet와
같은 오픈 포맷을 직접 읽는 데 최적화되어 있음
- 머신러닝과 데이터 사이언스 작업을 일급 시민처럼(first-class)
완벽하게 지원하도록 설계되었다.
최신 고성능 제공
✔ 컬럼 포맷 (Parquet/ORC)
필요한 컬럼만 읽어 I/O 대폭 절감 -> 쿼리 속도 향상
✔ 효율적 캐싱 레이어
Delta Lake는 intelligent caching 제공
✔ 고급 인덱싱
Z-ordering
Bloom filter, Data skipping → 불필요한 파일 읽기 제거 → 성능 급상승
✔ 분산 컴퓨트 엔진과 자연스러운 결합
Spark , Trino/Presto , Databricks 엔진
