Spark 란?
✔ Spark는 Hadoop MapReduce의 단점을 해결하기 위해 등장한 새로운 일반화된 분산 처리 엔진이다.
MapReduce는 다음과 같은 치명적 구조를 가지고 있었다:
❌ Map 단계 → 디스크에 출력
❌ Reduce 단계 → 디스크에 출력
❌ 다음 Job 실행 → 또 디스크 읽기
❌ 상태가 항상 디스크에 있기 때문에 반복 연산(ML, 그래프 알고리즘)에 매우 느림
✔ 재사용(Reuse)되는 데이터를 디스크에 안 쓰고, RAM에 저장
✔ 여러 Stage를 연속으로 메모리에서 처리 가능
✔ Iterative Job (ML, Graph, SQL)이 10~100배 빨라짐
✔ Hadoop + Hive 엔진으로는 불가능했던 Interactive Query
-> Spark 는 MapReduce 를 대체할 수 있는 새로운 엔진
Apache Spark 는 데이터 센터나 클라우드에서 대규모 분산 데이터 처리를 하기 위해 설계된 통합형 엔진
✔ MapReduce = 분산 Batch 실행 엔진
✔ Spark = 분산 In-Memory 실행 엔진
✔ Hive = SQL Layer(쿼리 엔진)이며 실제 실행 엔진은 MR/Tez/Spark 등
Hive는 직접 실행 엔진이 아니라 “엔진 위에서 동작하는 SQL 인터페이스 + 컴파일러
즉, Hive는 SQL을 해석하는 레이어고,
실제 실행은 다음 엔진 중 하나가 담당한다:
Hive on MapReduce
Hive on Tez
Hive on Spark
Hive + LLAP
Spark 의 장점
단일 엔진 위에서의 다양한 작업 - 범용성
Spark는 특정 용도만 처리하는 엔진이 아니라, 모든 형태의 데이터 처리를 하나의 플랫폼에서 할 수 있게 만든 범용 엔진이다.
Hadoop에서는
-
Batch = MapReduce
-
SQL = Hive(MR 기반)
-
ML = Mahout(MR 기반)
-
Streaming = Storm
이렇게 엔진이 모두 서로 달라서 통합이 복잡했다.
Spark는 반대로:
-
Spark Core
-
Spark SQL
-
Spark MLlib
-
Spark Streaming
-
GraphX
ex) 배치 처리, 반복 작업(머신 러닝), Interactive Query, Streaming
모두 단일 실행 엔진(Spark Engine) 위에서 동작함
데이터 포맷/메모리 구조(DataFrame/RDD)를 공유
클러스터 리소스도 공동 사용
Spark 하나로 Batch + ML + SQL + Streaming을 모두 처리/ 결합 가능
- 속도
스파크는 질의 연산을 DAG로 구성 , 각각의 태스크로 분해 , 클러스터의 워커 노드위에서 병렬 수행된다.
+모든 중간 결과는 메모리에 유지되며, 디스크 I/O 에 제한적으로 사용하므로 성능이 크게 향상 된다.
다양한 API, 라이브러리 지원 - 사용 편리성
-
Python(Pyspark)
-
Scala(Spark의 원래 언어)
-
Java
-
SQL(Spark SQL)
-
R (SparkR)
→ 누구나 쉽게 Spark를 사용할 수 있음.
내장 라이브러리:
-
MLlib (머신러닝)
-
GraphX (그래프 연산)
-
Spark Streaming
-
Catalyst Optimizer
-
Tungsten Execution Engine
이런 풍부한 기능들을 별도 설치 없이 바로 제공.
다른 빅데이터 도구 와 통합 편리 - 확장성
Spark는 Hadoop 클러스터에서 실행될 수 있고,
HDFS뿐 아니라 Hadoop 에코시스템의 어떤 데이터 소스도 접근할 수 있다.
Spark는 Hadoop의 YARN 위에서 실행 가능:
-
HDFS 파일
-
Hive 테이블
-
HBase
-
Parquet
-
ORC
-
Kafka
-
S3
-
Azure Blob
전부 읽고 쓸 수 있다.
Spark는 Hadoop을 대체하는 것이 아니라, Hadoop을 더 강력하게 만드는 실행 엔진이다.
저장과 연산을 모두 하는 Hadoop 과 달리 Spark 는 이 둘을 분리하여 많은 저장소로 부터 연결될수 있게 하였고 이를 통해 확장성을 확보할 수 있게 되었다.
Spark 의 분산 실행
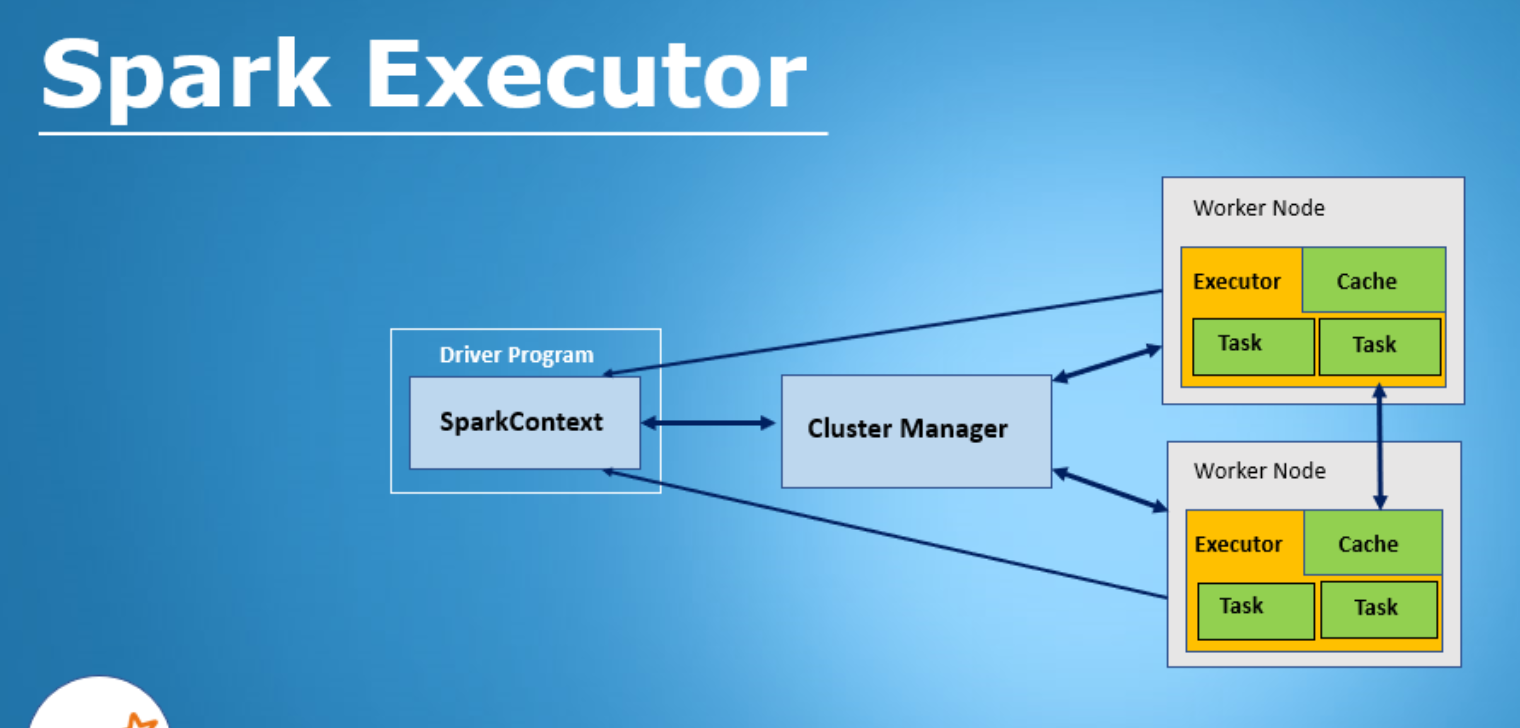
하나의 스파크 App 은 Spark 클러스터의 병렬 작업들을 조율하는 하나의 드라이버 프로그램으로 이루어진다. 드라이버는 SparkSession 객체를 통해 클러스터의 분산 컴포넌트들(Spark Executor)에 접근한다.
Spark Driver
SparkSession 객체를 초기화하는 책임을 가진 스파크 애플리케이션의 일부로서, 스파크 드라이버는 여러 가지 역할을 한다.
-
클러스터 매니저와 통신하며 Executor 들을 위해 필요한 리소스(CPU,Memory) 등을 요청한다
-
모든 스파크 작업을 DAG 형태로 변환 , 스케줄링, 각 실행단위 별로 Task 를 나누어 Spark Executor 로 분배
SparkSession
SparkSession 은 모든 스파크 연산과 데이터에 대한 통합 연결 채널
Cluster Manager
Cluster Manager 는 Spark App이 실행되는 클러스터에서 자원을 관리 및 할당하는 책임을 지닌다.
Spark Executor
Spark Executor 는 클러스터의 각 워커 노드에서 동작한다. 드라이버 프로그램 과 통신하며 워케에서 Task 실행. 대부분 노드당 하나의 이그제규터만 실행.
Spark RDD
Spark 의 가장 근본적인 Data 구조
Resilient Ditributed Dataset ( 회복력 있는 분산 데이터)
RDD 는 Immutable , Partitioned 성질을 가진다
더 자세한 설명은 다음 글에
Spark DataFrame
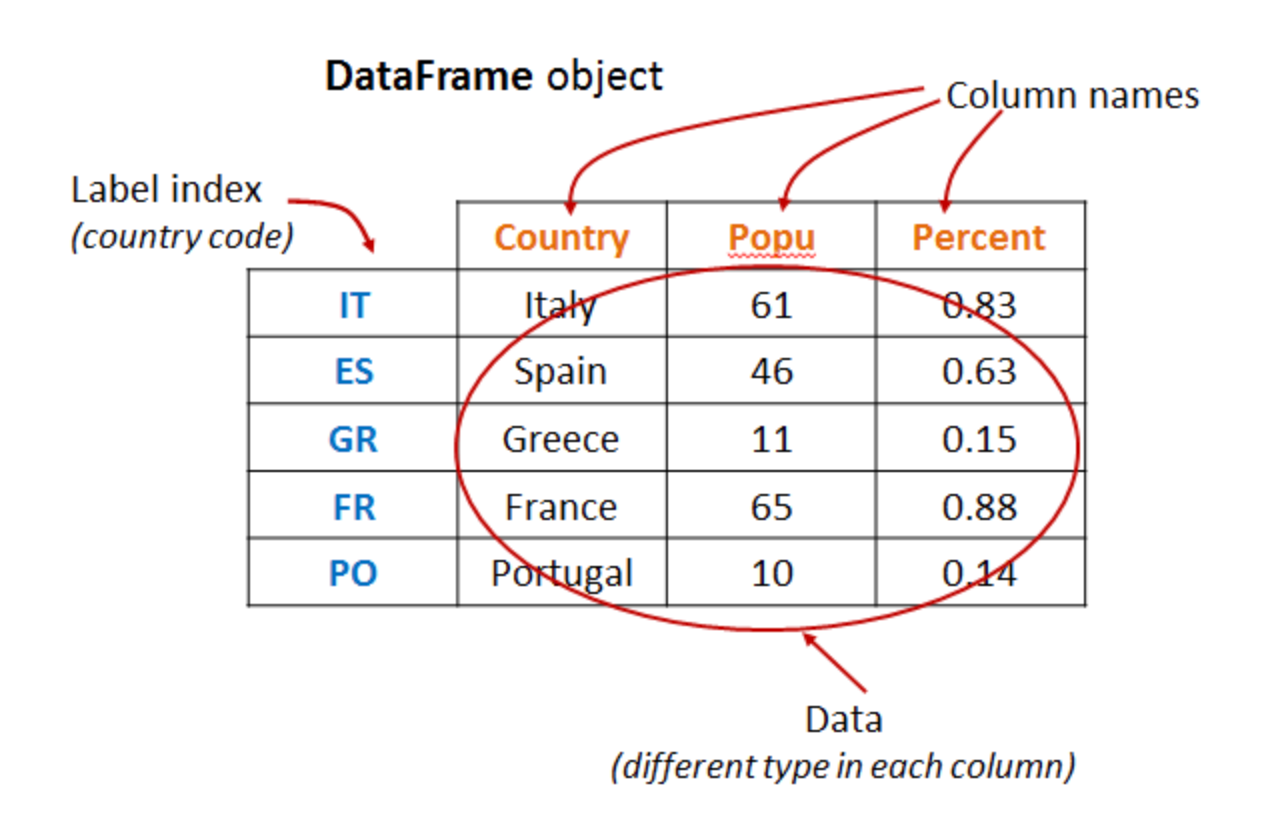
우리가 흔히 아는 RDB 의 테이블과 유사
