Spark Engine
Spark 엔진은 다음을 담당:
-
DAG 생성 및 최적화
-
Executor 할당
-
RDD/DataFrame Transformation 실행
-
인메모리 처리
-
Shuffle 관리
-
Fault tolerance
사용자의 DataFrame/SQL 코드를 → 클러스터에서 병렬 실행하는 엔진
Spark Core = Execution Engine (완성형)
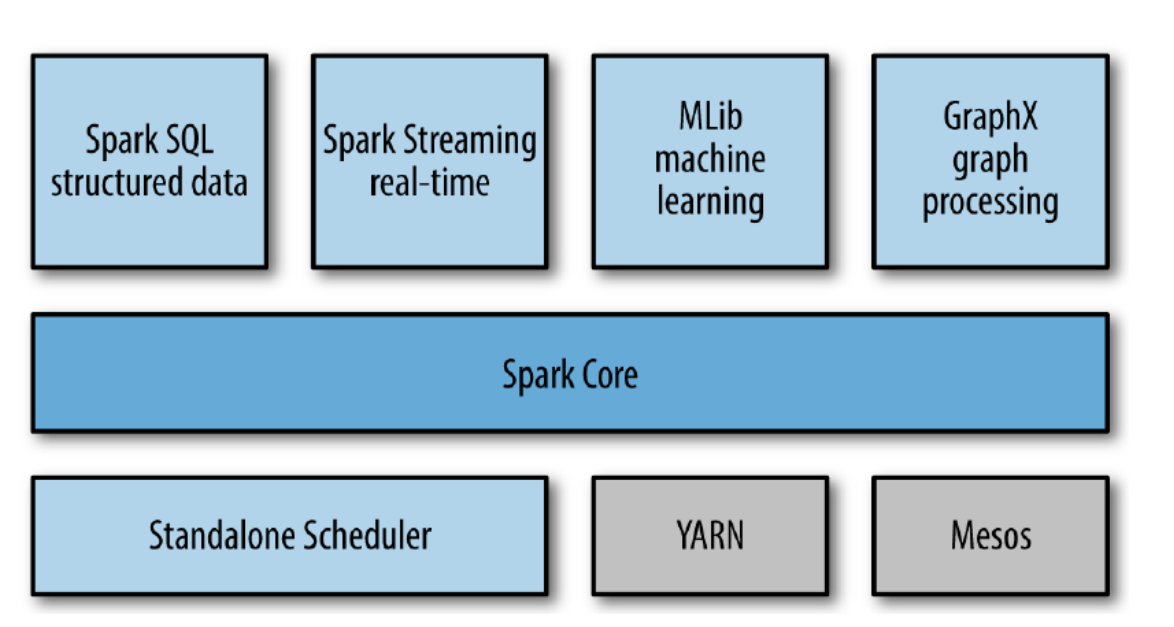
Spark Core = Execution Engine
상위 Spark 라이브러리 = 그 엔진을 사용하는 프레임워크
1) RDD API 제공
Spark의 원래 데이터 모델
변환(transformation) / 액션(action) 수행
불변성, lineage(연산 의존성) 기반 복구
→ Spark가 분산 처리 가능하게 만든 기본 개념
2) Task 스케줄링
Driver → Executors에게 task 분배
DAG Scheduler, Task Scheduler 모두 Core에서 제공
3) 클러스터 자원 관리와 통합
Spark Core는 다음 클러스터에서 동작 가능하게 해주는 추상화 계층:
YARN, Kubernetes, Mesos, Standalone cluster
클러스터 종류와 관계없이 Spark job이 같은 방식으로 실행되도록 해준다.
4) Fault Tolerance (장애 복구)
RDD lineage 기반 복구 시스템 제공:
Executor가 죽으면 task 재실행, Shuffle 파일 복구, 데이터 파티션 재계산
→ Spark의 안정성 핵심 기능.
5) 메모리 및 스토리지 관리
Tungsten 엔진 기반:메모리 최적화, 오프힙 메모리 관리, 캐싱(Persist/Cache), Spill to disk 처리
Spark SQL/ML/Streaming도 모두 이 메모리 시스템을 사용함.
6) 네트워크 통신 / Shuffle 시스템 제공
Executor 사이 데이터 이동, Shuffle block 관리, Netty 기반 통신
7) 고수준 라이브러리의 기초가 됨
Spark Core가 있어야 다음이 동작한다:
Spark SQL, DataFrame & Dataset, MLlib, GraphX, Structured Streaming
Spark RDD
Resilient Distributed Dataset
Spark 의 가장 근본적인 Data 처리 방식이다.
RDD API
Spark의 계산 엔진은 RDD API로 정의된 연산을 내부 DAG로 변환해 실행한다.
RDD 객체은 아래 정보를 가진다:
| 속성 | 의미 |
|---|---|
| dependencies | 상위 RDD와 어떤 연산(map/filter)이 연결됐는지 |
| compute() 함수 | 해당 RDD를 계산해야 할 때 실행할 실제 연산 코드 |
| partitioner | 데이터 분할자(예: HashPartitioner) |
| partitions | 각 RDD가 몇 개의 파티션을 가졌는지 |
개발자는 RDD API(map, filter, reduceByKey…) 를 호출
Spark는 그 API 호출을 이용해 “계산 DAG(계산 그래프)”를 만들고
Action에서 그 그래프를 Executor 에서 실행한다.
RDD 의 현재 용도
Spark 가 4.X 버전까지 나오면서 Data 접근도 Dataset , DataFrame 등 다양하면서 현재는
- 저수준 API 를 통한 세밀한 제어 또는 함수형 프로그래밍을 선호할 때
- 스키마 적용이 어려운 비정형 데이터
- 데이터 처리에 대한 안전한 방식이 중요할 때 사용한다
Immutable (불변성)
Spark RDD 는 불변성을 가진다. 그 이유는 RDD 자체가 Read-Only 인 데이터셋이기 때문이다.
rdd2 = rdd1.map(lambda x: x + 1)
여기서 rdd1 이 변경되지 않고 rdd2만 새로 생성된다.
이는 Spark Transformation 의 특성때문에 기존 RDD를 수정하지 않는다.
왜 RDD 는 Read-Only인가?
만약 수백 개의 노드가 하나의 RDD 값을 동시에 수정한다면 ? -> Lock 관리가 말도안될 것이고, 성능은 급락한다.
Read-only 구조라면 누가 수정을 하든 원본은 그대로 유지된다. 또한 Lock 을 쓸 필요도 없다
Fault-Tolerance
RDD는 자체 Lineage (계보) 를 가지는데 이는 변환 과정을 저장해놓는 곳이다.
rdd0 → map → rdd1 → filter → rdd2
어떤 노드가 이런식으로 계보를 저장해두었는데, 어떤 노드의 rdd2 일부 파티션이 다운되면 Spark 는 그냥 rdd0부터 필요한 연산만 다시 계산해서 복구한다. 원본이 수정되면 복구가 불가능해진다.
Lazy Evaluation
rdd0 → rdd1 → rdd2 → rdd3
이렇게 Transformation이 여러 개 이어져 있어도 Spark는 Action이 호출될 때까지 아무것도 실행하지 않는다.
Spark 내부 구조는 이렇게 저장됨: 어떤 연산을 어떤 순서로 해야 하는지만 DAG 형태로 기록
rdd0 --map--> rdd1 --filter--> rdd2 --map--> rdd3
Action 시점에
- 필요 없는 연산은 건너뛰고
- 최적화된 실행 계획(DAG)만 만들어 실행한다.
rdd0 = sc.textFile("file")
rdd1 = rdd0.map(...)
rdd2 = rdd1.filter(...)
rdd3 = rdd2.map(...)
rdd4 = rdd2.count() # Action 1
이런 코드가 있으면 여기서 Spark는 rdd3을 절대 계산하지 않는다.
왜냐하면 Action은 rdd4(count)이며 count는 rdd2까지만 필요하기 때문이다.
Spark 내부 동작
(1) Transformation 호출 단계
Spark는 아래 DAG만 저장:
textFile → map → filter(2) Action(count) 호출
Spark Scheduler가 DAG를 Stage로 나눔:
Stage 1: textFile → map → filter
(3) Executor 실행
Executor가 Stage를 task 단위로 실행할 때:
-
HDFS에서 해당 블록 읽기
-
map 함수 실행
-
filter 실행
-
count 수행
이 모든 것이 RDD의 compute() 호출 재귀 체인으로 이루어진다.
그럼에도 RDD 를 나눠서 쓰는 이유
중간 RDD (rdd1, rdd2) 를 정의할 필요는 없다.
하지만 개발자가 보기 편해서 이름을 붙이는 것일 뿐
Spark 입장에서는 rdd0 → rdd3를 하나의 Stage로 최적화해서 실행하기 때문에 중간 rdd1, rdd2는 실제로 계산되거나 저장되지 않는다.
- 가독성 목적
- 디버깅 쉬움 , 어디서 오류 났는지 명확, 변환 단계가 눈에 보임
- Lineage(계산 단계 기록)와 Fault-tolerance
-
Spark는 모든 변환을 “그래프 형태(계산 레시피)”로 저장
-
어떤 파티션이 날아가면 Spark는 lineage를 통해 rdd0부터 필요한 부분만 다시 계산해서 복구할 수 있음
중간 RDD는 실행 결과가 아니라 계산 그래프를 구성하는 노드 역할
Partitioned (분산된)
RDD는 여러 개의 Partition(파티션)으로 나뉘어 저장·계산되는 분산 컬렉션이다.
각 파티션은 독립적으로 병렬 처리되며, 각 파티션은 다른 노드(Executor)에서 독립적으로 계산될 수 있다.
RDD
├─ Partition 0
├─ Partition 1
├─ Partition 2
└─ Partition 3
| 개념 | 의미 |
|---|---|
| Partition | RDD의 데이터 조각 |
| Task | 파티션을 처리하는 실행 단위 |
| Executor | Task를 실행하는 JVM 프로세스 |
Task 1개 = Partition 1개 , 파티션 수 = 병렬 처리 수준(parallelism)
Task 1개는 한 Executor 코어 1개에서만 실행 가능
ex)
Executor 수: 4개
각 Executor에 CPU 코어 4개
전체 사용 가능한 코어: 4 × 4 = 16 cores
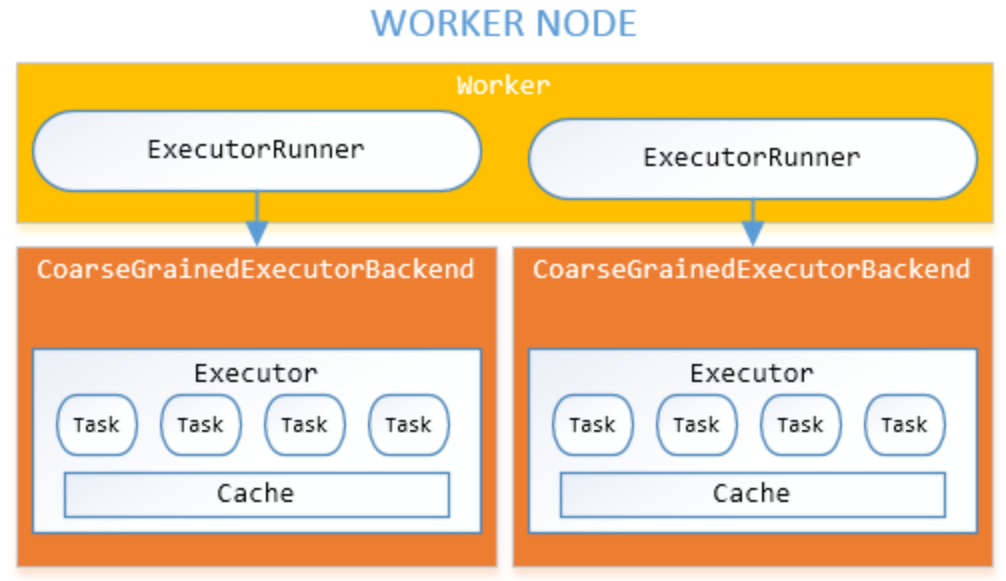
즉, 파티션 수가 적으면 실행할 Task가 너무 적어져서 Executor들이 일을 못 한다.
공식적인 권장 파티션 수는?
Spark 공식 가이드 / 업계 모범 사례:
총 CPU 코어 × 2 ~ 4
예: 코어 16개 → 최소 32~64 파티션
동시에 16개 실행 (풀 가동)
END → 다음 16개 실행
END → 다음 16개 실행
...Task 하나가 비정상적일 때도 병렬성을 유지하기 위해
네트워크·디스크 I/O variability를 흡수하기 위해
성능 균형이 좋기 때문
① Partition 수 = 병렬 처리 수
파티션이 너무 적으면 Executor가 놀고,
너무 많으면 오버헤드 증가.
② Partition 크기는 적당히 작아야 함
일반적으로 100MB ~ 200MB per partition 권장
너무 크면 느림
너무 작으면 Task 오버헤드 많음
③ 파티션은 Fault tolerance 단위
Task 실패 시 해당 파티션만 lineage로 다시 계산 가능.
④ Executor 메모리 관리의 핵심 단위
cache/persist도 파티션별로 저장됨.
EX) HDFS를 읽을 때
RDD의 파티션 개수 = HDFS 블록 수가 기본이 됨.
예:
HDFS 블록 크기 = 128MB
파일 크기 = 1GB
→ 약 8개의 블록
→ Spark RDD도 기본 8개의 파티션 생성
Partition 개수는 개발자가 조절할 수 있다
두 가지 함수로 제어:
- repartition(n)
완전 셔플 발생 → 파티션 새로 분배
병렬성 증가/감소 조절 가능
느리지만 균등하게 재분배됨
- coalesce(n, shuffle=False)
기존 파티션을 줄임 (보통 shuffle 없음)
병렬도 줄일 때 유용
빠름
RDD Cache
Spark의 핵심은 RDD는 원칙적으로 materialize(메모리/디스크에 실체화) 할 필요가 없지만 (왜? -> Lineage)
특정 상황에서는 실체화하는 것이 필수적으로 또는 선택적으로 필요하다.
이걸 이해하면 Spark 성능 튜닝을 정확하게 할 수 있다.
0. 기본 원칙
✔ RDD는 기본적으로 materialize(저장)되지 않는다.
Transformation은 lazy이며, Action이 호출될 때만 lineage 기반으로 다시 계산된다.
그러나 다음과 같은 상황에서는 materialization이 필요해진다.
1. Action 수행 시
최종 결과는 당연히 materialize됨.
계산 결과가 끝나면 중간 RDD는 다시 메모리에 남아있지 않는다.
lineage만 남고, RDD는 원래처럼 비-materialized 상태로 돌아간다.
2. 여러 번 사용할 RDD
cache/persist를 호출할 때 materialize 된다.
rdd = sc.textFile("file")
rdd2 = rdd.map(...)
rdd2.persist()
rdd2.count() # 첫 실행 → materialize 발생
rdd2.collect() # 두 번째 실행 → 재계산 없이 저장된 데이터 사용
persist()/cache() 를 호출하면 Spark는 해당 RDD를 “저장할 준비”만 하고 Action이 처음 호출될 때 materialize 한다.
persist 레벨에 따라 저장 위치가 달라진다
| Persist Level | 저장 위치 | 설명 |
|---|---|---|
| MEMORY_ONLY | RAM | 가장 빠르지만 메모리 부족 시 재계산 |
| MEMORY_AND_DISK | RAM + Disk | 메모리 부족 시 디스크에 spill |
| DISK_ONLY | Disk | 느리지만 안정적 |
| MEMORY_ONLY_SER | 압축된 메모리 | 공간 절약 |
| OFF_HEAP | JVM 외부 메모리 | GC 부담 없음 |
3. Checkpoint 사용 시
rdd.checkpoint()
rdd.count() # 이때 materialize되고 HDFS에 저장됨
RDD lineage가 너무 길어지면 재계산 비용이 커지므로
Spark는 checkpoint를 제공한다.
Checkpoint의 특징:
HDFS 같은 안정적인 저장소에 저장됨
lineage가 끊김 (fault tolerance가 개선됨)
4. Wide Transformation(Shuffle)이 발생시
이 경우는 뒤에서 Spark 분산환경을 다룰 때 다시 알아보도록 하자.
