
기본미션
K평균 알고리즘 동작방식 설명하기
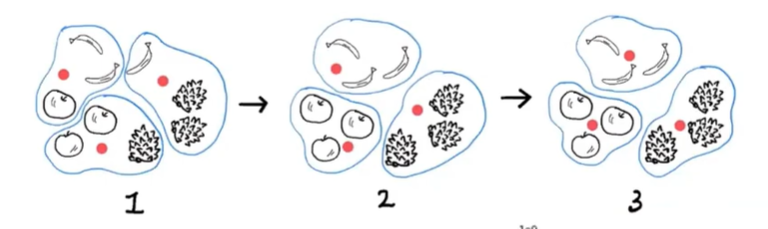
(출처-저자 직강 유튜브 https://www.youtube.com/watch?v=ePqKgBnpcw4&list=PLVsNizTWUw7HpqmdphX9hgyWl15nobgQX&index=16)
-
무작위 K개의 클러스터 중심을 정한다.
클러스터는 군집을 클러스터 기본적으로 K Means 3개 이고 이것을 결정하는 것이 어려워 책 후반에 최적의 군집 갯수를 정하는 방법을 설명한다.
클러스터 중심선택은 무작위라고 했지만 실제는 K++ 라는 알고리즘이 사용된다고 한다.(https://velog.io/@jhlee508/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-K-%ED%8F%89%EA%B7%A0K-Means-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98 참조) -
선택된 중심을 기준으로 클러스터 샘플을 한다.
-
클러스터 샘플내에서 평균값으로 클러스터 중심을 변경한다. 변경된 클러스터 중심을 기준으로 다시 클러스터 샘플을 지정한다.
-
2,3 단계를 클러스터 중심 값이 변화가 없을때 까지 수행한다.
추가. 최적의 군집(K) 갯수는 내부 inertia 밸류 값의 변화를 통해서 유추 할수 있다. 각 군집 갯수 별로 inertia 값을 확인 후 값의 변화가 완만해 지는 지점을 최적의 군집 갯수라고 판단한다.
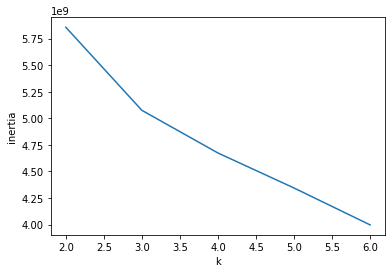
위의 경우 3.0의 부분이다.
선택미션
Ch.06(06-3) 확인 문제 풀고, 풀이 과정 정리하기
- 2번 문제에서 설명된 분산이 가장 큰 주성 분은 몇 번째 인가요?
✔1) 첫번째 주성분
2) 다섯번째 주성분
3) 열번째 주성분
4) 알 수 없음
2번 문제는 1000개의 샘플에 각 샘플의 100개의 특성을 가지고 있을 때 PCA를 이용하여 10개로 특성을 줄이면 데이터 셋의 크기는? 이다. 직관적으로 특성만 줄었기 때문에 (1000, 10)이다.
그럼 분산이 가장 큰 주성분은 몇 번째 인가?

(출처-https://datascienceschool.net/02%20mathematics/03.05%20PCA.html)
첫번째로 가장 분산도가 큰 주성분을 찾고 그것과 최대한 겹치지 않는 성분을 2번째 그리고 그다음의 성분을 찾는 방식으로 최소한의 특징으로 해당 샘플을 정의 하는 것이 차원 축소이다. 따라서 분산도가 가장 큰것을 첫번째 성분으로 사용한다.
