
이번 포스팅에서는 합성곱 신경망(Convolutional Neural Network, CNN)을 이용하여, 여러가지 그림들을 분류해보겠습니다.
먼저 합성곱 신경망에 대해서는 여기를 참고해 주세요!
▶사용할 데이터 집합
이번 합성곱 신경망을 이용한 분류에서 사용할 데이터 집합은 앞에서도 사용했던 Fashion MNIST입니다.
▶라이브러리 임포트
사용할 라이브러리는 아래와 같습니다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import transforms, datasets
from torch.utils import data▶GPU, Parameter 설정
앞서 설명했던 것과 같습니다.
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
epoch = 20
batch_size = 64▶데이터셋 준비
이는 심층 심경망과 같습니다.
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
trainset = datasets.FashionMNIST(root = './.data/', train = True, download = True, transform = transform)
testset= datasets.FashionMNIST(root = './.data/', train = False, download = True, transform = transform)
train_loader = data.DataLoader(dataset = trainset, batch_size = batch_size)
test_loader = data.DataLoader(dataset = testset, batch_size = batch_size)▶모델 설계
이제 CNN의 설계 부분입니다.
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.pool = nn.MaxPool2d(2)
self.drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(self.pool(self.conv1(x)))
x = F.relu(self.pool(self.conv2(x)))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = self.drop(x)
x = self.fc2(x)
return F.log_softmax(x, dim = 1)먼저 입력을 받는 conv1의 첫번째, 두번째 파라미터는 입력 채널수와 출력 채널 수를 의미합니다. FashionMNIST 데이터셋은 흑백이미지이기 때문에 색상 채널이 1개입니다. 또한 첫 번째 컨볼루션 계층에서는 10개의 특징맵을 생성합니다. 다음으로 두 번째 컨볼루션 계층인 conv2는 conv1의 결과인 10개의 특징맵을 입력으로 받아 20개의 특징맵을 생성합니다. 각 컨볼루션 계층의 커널(필터)의 크기인 kernel_size는 5로 설정하였습니다.(숫자를 (4,3)과같이 적어줄 경우 직사각형의 커널을, 하나의 숫자만 적어줄 경우 정사각형으로 간주합니다.) 컨볼루션 계층 사이에 풀링 계층이 존재하는데, 풀링을 사용하여 이미지의 크기를 줄입니다. 여기서는 풀링 계층의 커널 크기를(2x2)로 설정하였습니다.다음으로는 드롭아웃을 설정해 둡니다. 이는 컨볼루션 계층을 모두 나온 특징맵을 드롭아웃 시키기 위해 정의해 주었습니다. 컨볼루션, 드롭아웃을 모두 거친 특징맵은 일반 신경망을 거칩니다. 첫 번째 신경망 계층인 fc1에서는 앞 계층의 출력 크기인 320을 입력 크기로 하고, 출력 크기를 50으로 설정하였습니다. 두 번째 신경망 계층인 fc2는 입력 50, 출력 10으로 설정하였습니다.(클래스가 10개이기 때문에, 출력 크기는 10입니다)
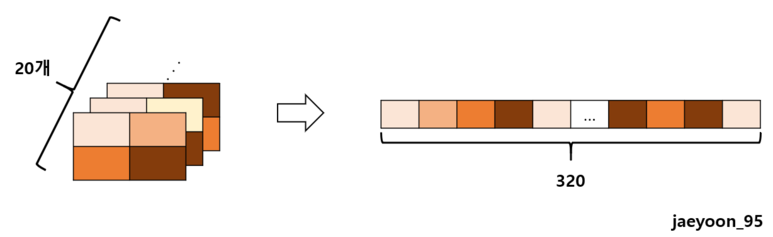
※fc1입력 전 왜 크기가 320이 되는지?초기 입력 데이터 크기(1, 28, 28) : 채널 1개(이미지 1개), 이미지의 크기 28x28
conv1를 거친 뒤 데이터 크기 (10, 12, 12) : 10개의 피쳐, 이미지의 크기 12x12
conv2를 거친 뒤 데이터 크기 (20, 4, 4) : 20개의 피쳐, 이미지의 크기 4x4
※드롭아웃에 대한 설명은 여기를 참고해주세요!
▶학습 및 평가
학습 및 평가는 아래와 같습니다.
model = CNN().to(DEVICE)
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum = 0.5)
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train epoch : {} [{}/{} {:.0f}%]\tLoss:{:.6f}'.format(epoch, batch_idx*len(data),len(train_loader.dataset),100.*batch_idx/len(train_loader),loss.item()))
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100 * correct / len(test_loader.dataset)
return test_loss, test_accuracy
for epoch in range(1, epoch + 1):
train(model, train_loader, optimizer, epoch)
test_loss, test_accuracy = evaluate(model, test_loader)
print('[{}] Test Loss : {:4f}, Accuracy : {:.2f}%'.format(epoch, test_loss, test_accuracy))
