
이번 포스팅에서는 앞서 설명했던 CNN을 조금더 깊은 신경망으로 구현하고, 색깔이 있는(RGB값이 있는) 데이터를 처리해 보겠습니다. 먼저 합성곱 신경망에 대한 설명은 여기를 참고해주세요!
▶사용할 데이터 집합
이번에 사용할 데이터셋은 CIFAR-10입니다. 이 데이터 셋은 32x32크기의 이미지를 6만개 포함하고 있고, 총 10개의 클래스(자동차, 새, 고양이, 사슴 등)가 존재합니다. 또한 Fashion MNIST와는 다르게, RGB값을 가지는 유색 이미지입니다.(R, G, B에 대한 채널을 각 1개씩, 총 3개의 채널을 가집니다.) 따라서 입력 데이터 크기는 32x32x3(채널 개수)입니다.
아래의 코드로 시각화를 해봅시다.
import torch
import numpy as np
from torchvision import transforms, datasets, utils
from torch.utils import data
##load dataset
transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))
])
trainset = datasets.CIFAR10(root = './.data/', train = True, download = True, transform = transform)
testset= datasets.CIFAR10(root = './.data/', train = False, download = True, transform = transform)
train_loader = data.DataLoader(dataset = trainset, batch_size = batch_size)
test_loader = data.DataLoader(dataset = testset, batch_size = batch_size)
##check dataset
dataiter = iter(train_loader)
images, labels = next(dataiter)
img = utils.make_grid(images, padding=0)
npimg = img.numpy()
plt.figure(figsize = (10,7))
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
▶라이브러리 임포트
사용할 라이브러리는 아래와 같습니다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import transforms, datasets, utils
from torch.utils import data
import matplotlib.pyplot as plt
import numpy as np▶GPU, Parameter 설정
앞서 설명했던 것과 같습니다.
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
epoch = 100
batch_size = 64▶데이터셋 준비
이는 위의 데이터 시각화 앞부분과 동일합니다.
transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))
])
trainset = datasets.CIFAR10(root = './.data/', train = True, download = True, transform = transform)
testset= datasets.CIFAR10(root = './.data/', train = False, download = True, transform = transform)
train_loader = data.DataLoader(dataset = trainset, batch_size = batch_size)
test_loader = data.DataLoader(dataset = testset, batch_size = batch_size)▶모델 설계
이제 CNN의 설계 부분입니다. 이번 CNN은 ResNet의 핵심인 Residual 블록을 사용하여 구현하겠습니다.
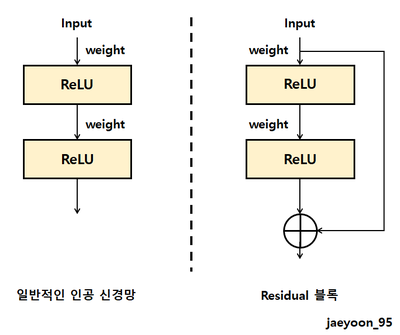
신경망을 깊게 쌓는다면, 최초 입력에 대한 정보가 소실되기 때문에, 좋지만은 않습니다. Residual 블록 같은 경우에는 블룩의 출력에 입력값을 더함으로써 모델을 훨씬 깊계 설계할 수 있도록 하였습니다.(입력 정보에 대한 정보 소실을 막았기 때문이죠.) ResNet은 위의 Residual 블록을 여러 계층 쌓은 모델입니다.
먼저 Residual 블록에 대한 코드입니다.
class ResidualBlock(nn.Module):
def __init__(self, in_planes, planes, stride = 1):
super(ResidualBlock,self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes)
)
def forward(self, x):
output = F.relu(self.bn1(self.conv1(x)))
output = self.bn2(self.conv2(output))
output += self.shortcut(x)
output = F.relu(output)
return output기존 CNN과 비교했을 때, BatchNorm2d가 새로 등장하는데, 이는 배치 정규화(Batch Normalization)을 수행하는 계층입니다. 다음으로는 초기의 입력 데이터를 결과에 더해주는 모듈인 shortcut을 정의합니다. 여기서 사용되는 nn.Sequential은 여러 모듈을 하나의 모듈로 묶어주는 역할을 합니다. 즉, 위의 예로는 Conv2d, BatchNorm2d 모듈이 하나의 모듈로 묶여 shotcut이라는 새로운 모듈이 탄생합니다.
※배치 정규화란?
배치 정규화는 학습률을 너무 높게 잡으면 기울기가 소실되거나 발산하는 증상을 예방하여 학습 과정을 안정화 하는 방법입니다.
class DeepCNN(nn.Module):
def __init__(self, class_num=10):
super(DeepCNN,self).__init__()
self.in_planes = 16
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.layer1 = self._make_layer(16, 2, stride=1)
self.layer2 = self._make_layer(32, 2, stride=2)
self.layer3 = self._make_layer(64, 2, stride=2)
self.fc = nn.Linear(64, class_num)
def _make_layer(self, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(ResidualBlock(self.in_planes, planes, stride))
self.in_planes = planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.max_pool2d(out, 8)
out = out.view(out.size(0), -1)
out = self.fc(out)
return outDeepCNN모델은 이미지를 입력받아 Conv, BatchNorm2d를 거치고, 여러 계층의 ResidualBlock을 거쳐 max_pooling을 통해 예측을 출력합니다. 위에서 정의했던 ResidualBlock은 _make_layer를 통해 정의됩니다. 이는 뒷쪽에서 설명하겠습니다. 각 입력과 출력을 보면 처음 conv1는 3x3크기의 커널을 가지기 때문에 RGB, 3개의 채널을 16개로 만듭니다. layer1을 지나면 16x32x32, layer2를 지나면 32x16x16, layer3을 지나면 64x8x8 크기의 텐서를 얻습니다. 마지막으로 최대 풀링을 통해 텐서에 있는 원소의 개수를 64개로 만들어주고, 이를 fc에 입력받아 레이블 10개의 예측값을 출력합니다.
_make_layer에 대한 설명
이 함수는 self.in_planes 채널 개수로부터 직접 입력받은 인수 planes 채널 개수 만큼을 출력하는 ResidualBlock을 생성합니다.
(1) layer1 : 16채널에서 16채널을 내보내는 ResidualBlock 2개
(2) layer2 : 16채널에서 32채널을 내보내는 ResidualBlock 1개, 32채널에서 32채널을 내보내는 ResidualBlock 1개
(3) layer3 : 32채널에서 64채널을 내보내는 ResidualBlock 1개, 64채널에서 64채널을 내보내는 ResidualBlock 1개
▶학습 및 평가
학습 및 평가는 아래와 같습니다.
model = DeepCNN().to(DEVICE)
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum = 0.5)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1)
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train epoch : {} [{}/{} {:.0f}%]\tLoss:{:.6f}'.format(epoch, batch_idx*len(data),len(train_loader.dataset),100.*batch_idx/len(train_loader),loss.item()))
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100 * correct / len(test_loader.dataset)
return test_loss, test_accuracy
for epoch in range(1, epoch + 1):
scheduler.step()
train(model, train_loader, optimizer, epoch)
test_loss, test_accuracy = evaluate(model, test_loader)
print('[{}] Test Loss : {:4f}, Accuracy : {:.2f}%'.format(epoch, test_loss, test_accuracy))
