
- 📝 대규모 서비스를 지탱하는 기술, 서버/인프라를 지탱하는 기술 을 읽으며, 리소스 모니터링에 관련하여 정리한 글입니다.
- 대용량 데이터 서비스를 운영하기 위해서는 서버 부하의 원인을 파악하고, 이를 해결할 수 있어야 합니다. 이는 제가 주로 하는 대용량 데이터를 처리할 수 있는 ML 모델링 및 최적화 시뮬레이션에서도 중요한 이슈이기 때문에 이번 기회에 정리하게 되었습니다.
- 작성 일자: 2020-08-16
1. 성능, 부하란 무엇인가
- 웹 어플리케이션에서 부하분산의 많은 경우는 '디스크 I/O를 분산하고 경감시키는' 작업 이다.
- I/O가 OS에 의해 어떻게 처리되는지 이해해야한다.
- OS는 I/O를 경감시키기 위해 캐시 구조를 사용하게 된다. 캐시가 가장 효율적으로 동작할 수 있도록, 시스템을 구성하는 것이 I/O 분산의 핵심이다.
2. 추측하지말라, 계측하라
- 병목을 규명하기 위한 작업은 크게 나누면 다음과 같다.
1. Load Average 확인
2. CPU, I/O 중 병목 원인 조사
- Load Average가 높은 경우, 다음으로 CPU와 I/O 어느 쪽에 원인이 있는지를 조사해야한다.
참고) sar, vmstat으로 시간 경과에 따라 CPU 사용률이나 I/O 대기율의 추이를 확인할 수 있다.
CPU 부하가 높은 경우:
- 사용자의 프로그램의 처리가 병목인지, 시스템의 프로그램이 원인인지 확인한다. top, sar과 같은 명령어 이용
- ps 명령어로 볼수 있는 프로세스 상태나 CPU 사용시간 등을 보면서 원인이 되고 있는 프로세스를 찾는다.
- 프로세스를 찾은 후, 보다 상세하게 조사할 경우는 strace 명령어로 추적하거나 oprofile로 프로파일링해서 병목지점을 좁혀나간다.
I/O 부하가 높은 경우:
- 일반적으로 프로그램으로부터 입출력이 많아서 부하가 높거나, 스왑이 발생해서 디스크 액세스가 발생하고 있는 상황인 경우가 많다. sar, vmstat을 이용해 문제를 파악한다.
ex1. 스왑이 발생하고 있는 경우:
1. 특정 프로세스가 극단적으로 메모리를 소비하고 있지 않는 지 ps명령어로 확인할 수 있다.
2. 프로그램 오류로 메모리를 지나치게 사용하는 경우, 프로그램을 개선한다.
3. 탑재된 메모리가 부족한 경우에는 메모리를 증설한다. 메모리를 증설할 수 없는 경우에는 분산을 검토한다.
ex2. 스왑이 발생하지 않고, 디스크로의 입출력이 빈번하게 발생하고 있는 상황:
- 캐시에 필요한 메모리가 부족한 경우로 생각해볼 수 있다. 해당 서버가 저장하고 있는 데이터 용량과 증설 가능한 메모리량을 비교해서 다음과 같이 나눠서 검토한다.
1) 메모리 증설로 캐시영역을 확대시킬 수 있는 경우는 메모리를 증설한다.
2) 메모리 증설로 대응할 수 없는 경우는 데이터 분산이나 캐시서버 도입등을 검토한다. 물론, 프로그램을 개선해서 I/O빈도를 줄이는것도 검토가능하다.
CPU Bound 프로그램: CPU 자원을 많이 필요로 하는 프로그램
I/O Bound 프로그램: I/O 자원을 많이 필요로 하는 프로그램
3. Load Average란 무엇인가
-
Load Average:
running 상태의 (CPU 자원이 많이 필요하는) 프로세스의 수와 uninterruptible 상태의 (I/O 자원이 많이 필요하는) 프로세스의 수를 합한 값.
즉, CPU를 사용하자고 해도 다른 프로세스가 CPU를 사용하고 있어서 기다리고 있는 프로세스 와 디스크 입출력이 끝날때 까지 기다려야만 하는 프로세스 두가지로 나타내어지는 값이다. -
Load Average는 CPU 갯수에 따라 해석을 달리 할 수 있다. ex) cpu갯수로 Load Average값을 나누어, CPU 사용율을 측정할 수 있다.
-
Process State Codes
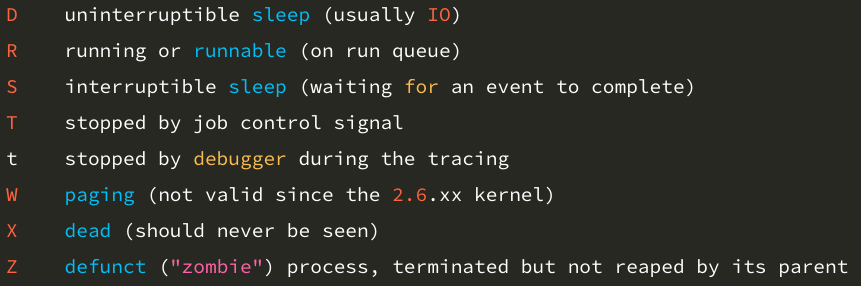
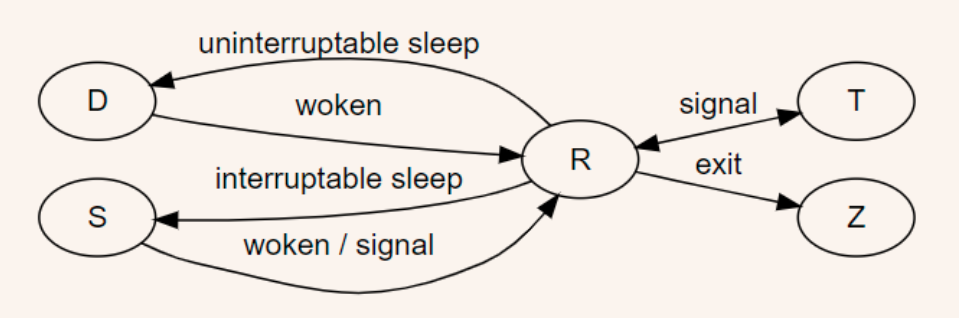
4. Vmstat 명령어로 부하의 정체 파악하기
- Load Average만으로는 CPU 작업에 부하가 많은 지, I/O 작업에 부하가 많은 지 파악하기 힘듬으로 vmstat명령어로 간단하게 확인할 수 있다.
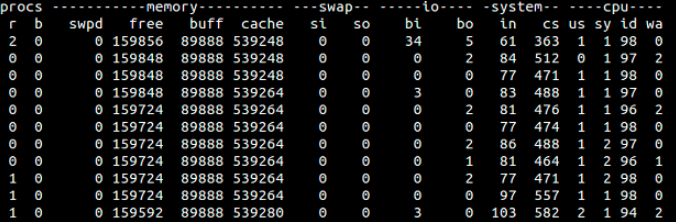
1) 프로세스:
r: 실행시간을 기다리고 있는 프로세스 수 (CPU 부하 프로세스 수)
b: 인터럽트 안되는 sleep 프로세스 수 (I/O 부하 프로세스 수)
2) 메모리:
swpd: 가상메모리 사용량
free: 유휴메모리 양
buff: 버퍼메모리 양
cache: 캐시메모리 양
inact/active: 비활성화/활성화 메모리 양
3) 스왑메모리:
si/so: 디스크→메모리 / 메모리→디스크 스왑량 (/s)
4) 입출력 IO:
bi / bo: 장치에서 받아오는 블록, 장치로 보내는 블록 (blocks/s).
5) 시스템:
in: 초당 인터럽트 수
cs: 초당 문맥교환 수
6) CPU 사용률(%):
us: 비커널 코드 소비 시간 (사용자 시간)
sy: 커널 코드 소비 시간 (시스템 시간)
id: 유휴 시간
wa: 입출력 대기 시간
st: 가상머신으로부터 뺏은 시간
- r,b 를 통해 CPU 부하가 많은 지, I/O 부하가 많은 지 파악할 수 있다.
- 특히 vmstat에서 중요하게 볼 지표는 bi, bo지표인데 이를 통해 실제로 얼마나 I/O 발생하고 있는지 그 절대치를 알수 있다. (top이나 sar같은 다른 명령어들 I/O 대기율까지만 확인 가능)
5. Top 명령어로 프로세스 정보확인하기
- top 명령어를 통해 Load Average, CPU 사용율, 메모리 사용량 등을 파악할 수 있다.
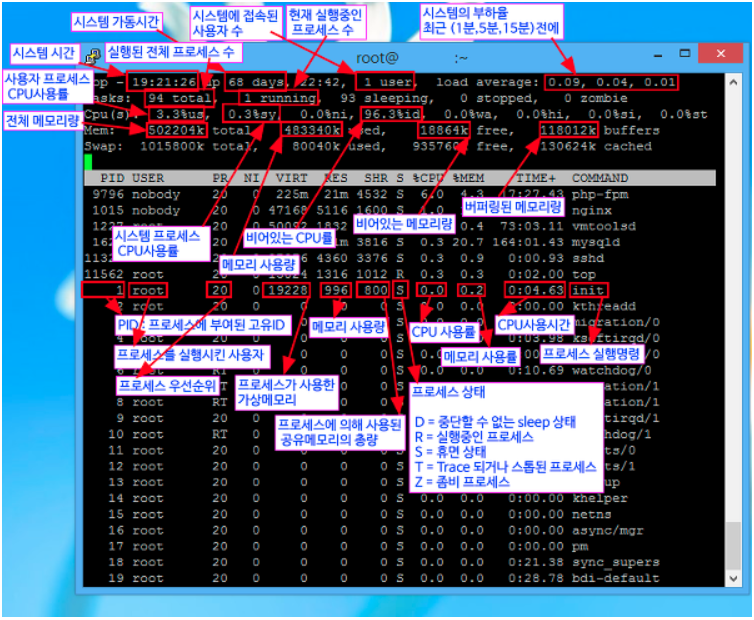
- swap 메모리의 사용 여부가 시스템의 상태에 중요한 영향을 끼친다
- VIRT: 해당 프로세스가 확보하고 있는 가상 메모리 영역의 크기
- RES: 해당 프로세스가 확보하고 있는 물리메모리 영역의 크기
- SHR: 다른 프로세스와 공유 하고 있는 Shared Memory의 양
- S: 프로세스 상태
- 실 가용 메모리 = free + buffers + cached Mem
- 실 사용 메모리 = used - (buffers + cached Mem)
- VIRT는 실제로는 할당되지 않은 가상의 공간이기 때문에 해당 값이 크다고 해도 문제가 되진 않는다. 실제 사용하고 있는 메모리는 RES 영역이기때문에 메모리 점유율이 높은 프로세스를 찾기 위해서는 RES 영역이 높은 프로세스를 찾아야 한다.
- swap이 발생하고 있을 경우는 물리 메모리가 부족하다는 증거이므로, RES의 크기가 몹시 큰 프로세스가 없는 지를 파악한다.
- 좀비 프로세스가 사용한 PID가 정리되지 않고 쌓이면 새로운 프로세스에 할당할 PID가 모자라게 되고, 이는 결국 더이상 PID를 할당하지 못하는 PID 고갈을 일으킬 수 있다.
1) 가상 메모리와 물리 메모리
메모리 할당 과정:
1. 사용자 프로세스는 멀티 태스킹 시스템을 보호하기 위해, 직접 하드웨어에 접근할 수 없으므로, 일단 처리를 중지하고 커널에 메모를 확보를 의뢰한다.
2. 커널은 이때 실제 메모리의 영역의 주소를 넘기는 것이 아니라, 가상적인 메모리 주소를 넘긴다.
3. 프로세스는 커널에서 반환된 가상 메모리 주소를 실제 주소인 것으로 간주하고 처리를 재개한다.
4. 그 후 프로세스가 할당받은 메모리 영역에 실제로 쓰기 작업을 하면 Page fault가 발생하며 그제서야 커널은 실제 물리 메모리에 프로세스의 가상 메모리 공간을 매핑한다. 그리고 이렇게 물리 메모리에 바인딩된 영역이 RES로 계산된다.
-
할당받고 사용된 메모리는 RES 영역으로 계산이 되고, 이것은 물리 메모리와 관련이 있기 때문에 더이상 줄 수 있는 메모리 영역이 없다면 swap을 사용하거나 OOM으로 프로세스를 죽이는 등의 방법으로 메모리를 확보하게 될 것이다.
-
가상 메모리 구조를 통해 얻을 수 있는 이점:
1. 물리 메모리 그 이상의 용량의 메모리를 다룰 수 있을 것처럼 프로세스에 꾸며 보일 수 있다.
2. 물리 메모리 상에 뿔뿔히 흩어져 있는 영역을 연속된 하나의 메모리 영역으로 프로세스에게 보일 수 있다.
3. 물리 메모리가 부족한 경우는 장시간 사용되지 않는 영역의 가상메모리와 물리 메모리 영역 맵핑을 해제한다. 해제된 데이터는 2차 기억장치(디스크 등)에 저장해두고 다시 필요해지면 원래로 돌린다.(swap)
2) Linux의 페이지 캐시 원리
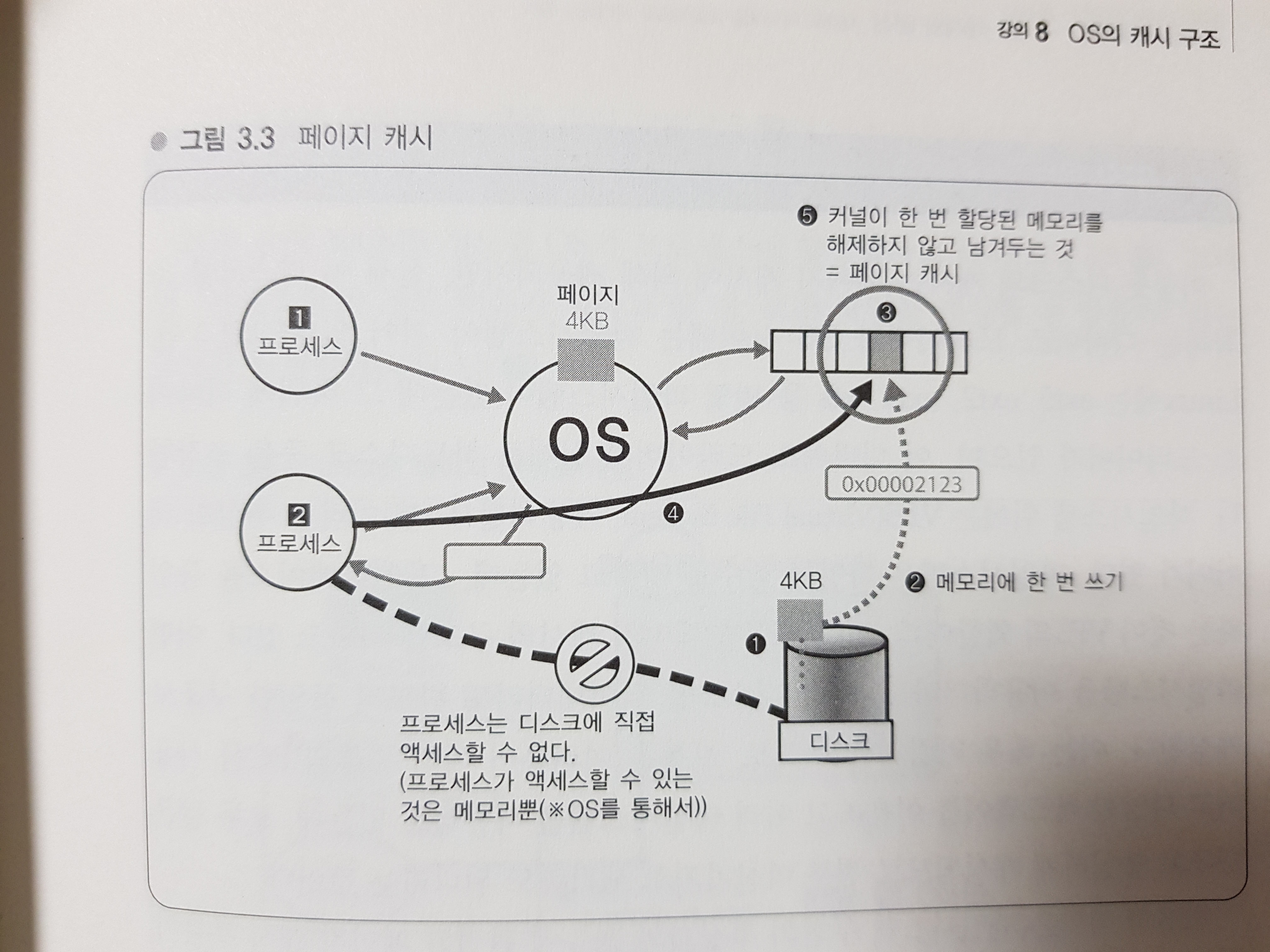
- 페이지 캐시: 작정된 페이지는 파기되지 않고 남긴다.
- 리눅스는 페이지 단위로 디스크를 캐싱한다.
- DB도 계속 구동시키면, 캐시가 점점 최적화되어감으로써, 점점 시간이 지날수록 I/O부하가 내려가는 특성을 보인다.
- 리눅스는 사용되지 않는 메모리가 있으면, 전부 캐싱 메모리로 사용한다.
- 메모리를 늘리면, 캐시를 사용할 수 있는 용량이 늘어나고, 캐시에 사용할 수 있는 용량이 늘어나면, 보다 많은 데이터를 캐싱할 수 있고, 많이 캐싱되면 디스크를 읽는 횟수가 줄어든다.
프로세스가 디스크로부터 데이터를 읽어내는 과정 속 페이지 캐시:
1. OS는 우선 디스크로부터 4KB 크기의 블록을 읽어낸다.
2. 프로세스는 디스크에 직접 액세스 할 수 없기 때문에, 프로세스가 액세스 할 수 있는 가상 메모리 공간에 읽어낸 블록을 쓴다.
3. 그러면 프로세스는 해당 메모리에 액세스 한다.
4. 데이터 읽기를 마친 프로세스는 '이번 디스크 읽기가 끝나고 데이터 전부를 처리했으므로 더 이상 불필요'하게 되었어도 메모리를 해제하지 않고 남겨둔다.
5. 그럼 다른 프로세스가 같은 디스크에 접근했을때 남겨두었던 페이지를 사용할 수 있음으로 디스크를 읽으러 갈필요가 없게 된것이다. 이것이 페이지 캐시이다.
6. Free 명령어로 Swap 확인하기
- swap: swap 영역은 물리 메모리가 부족할 경우를 대비해서 만들어 놓은 영역이다
- swap 영역은 물리 메모리가 아니라 디스크의 일부분을 메모리처럼 사용하기 위해 만들어놓은 공간이기 때문에, 메모리가 부족할때 사용한다고는 하지만 메모리에 비해 접근과 처리 속도가 현저하게 떨어진다. 그래서 swap 영역을 사용하게 되면 시스템의 성능 저하가 일어난다.
free 명령어

total: 전체 swap 영역의 크기
used: 현재 사용중인 swap 영역의 크기
free: 현재 남아있는 swap 영역의 크기
- 22MB 정도의 swap 영역을 사용하고 있다. 전체 영역에 비해서는 적은 양이지만 swap 영역을 사용했다는 것 자체가 시스템에 메모리와 관련해 문제가 있을 수 있다는 의미이다. 아주 적은양이라도 swap 영역을 쓰기 시작했다면 반드시 살펴봐야 한다.
- swap의 사용여부를 판단하는 것도 중요하지만 누가 swap을 사용하느냐도 매우 중요한 판단 기준이 된다.
- 특정 프로세스가 사용하는 전체 swap 영역에 대한 정보가 필요한 경우에는 /proc/< pid >/status 파일을 통해서도 확인할 수 있다.
- 커널에서의 메모리 재할당 과정에 대한 이해
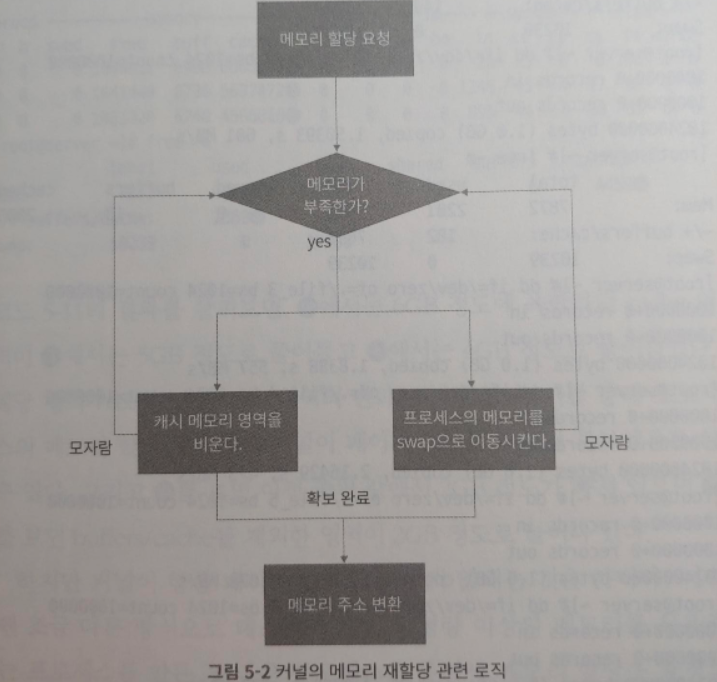
- 커널에서의 메모리 재할당은 주로 두가지 로직으로 처리된다.
1. 커널이 사용하는 캐시 메모리 영역으로부터의 재할당:
Page Cache, Buffer Cache, inode cache, dentry cache 등의 메모리를 캐시 용도로 사용하면 시스템의 성능이 전반적으로 향상된다. 이 경우 정작 사용자 프로세스가 메모리를 필요로 할때 사용할 메모리가 부족해질 수 있다. 이럴때 메모리 재할당이 일어난다. 커널은 캐시 용도로 사용하던 메모리를 사용 해제하고 가용 메모리 영역으로 돌린 후 프로세스가 사용할 수 있도록 재할당한다. 이는 시스템 운영 중에 자연스럽게 발생하는 과정이다.
2. swap을 사용한 메모리 재할당:
캐시 용도의 메모리를 해제할 만큼 해제하고도 더 이상 프로세스에 할당해줄 메모리가 없다면, 바로 이때 swap을 사용하게 된다. 해당 메모리 영역이 물리 메모리에서는 해제되었지만 swap 영역으로 이동했기 때문에 프로세스가 해당 메모리 영역을 참조하려고 하면 다시 swap 영역에서 불러들어야 한다. 메모리를 swap 영역으로 쓰거나 읽는 작업이 디스크에서 일어나기 때문에 I/O를 일으키고 이 과정에서 시스템의 성능이 저하된다.
7. Sar 명령어로 각종 OS 지표파악하기
- cpu 사용률(오늘)
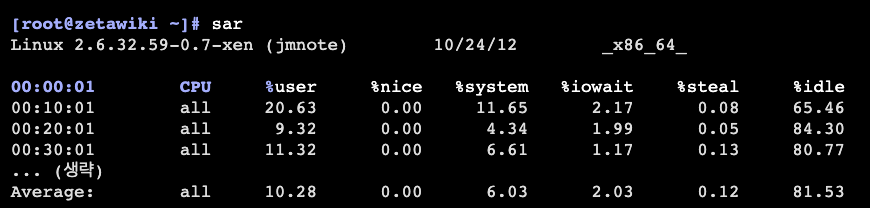
user: 사용자 모드에서 CPU가 소비한 시간의 비율
nice: nice로 스케줄링의 우선도를 변경한 프로세스가 사용자 모드에서 CPU를 소비한 시간의 비율
system: 시스템 모드에서 CPU가 소비한 시간의 비율
iowait: CPU가 디스크 I/O 대기를 위해 idle상태로 소비한 시간의 비율
steal: Xen등 OS의 가상화를 이용하고 있을 경우, 다른 가상 CPU의 계산으로 대기된 시간의 비율
idle: CPU가 디스크 I/O 등으로 대기되지 않고, idle상태로 소비한 시간의 비율
-
cpu 사용률(날짜별)
sar -f /var/log/sa/sa날짜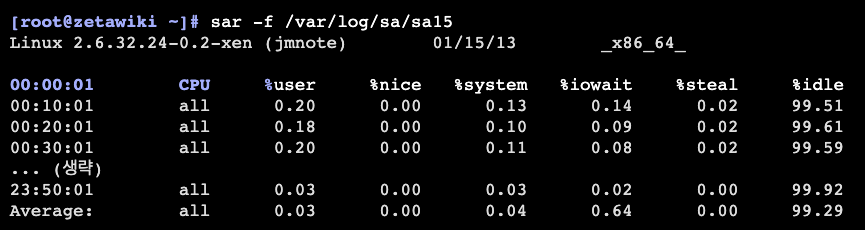
-
시간 추이별 Load Average 확인
sar - q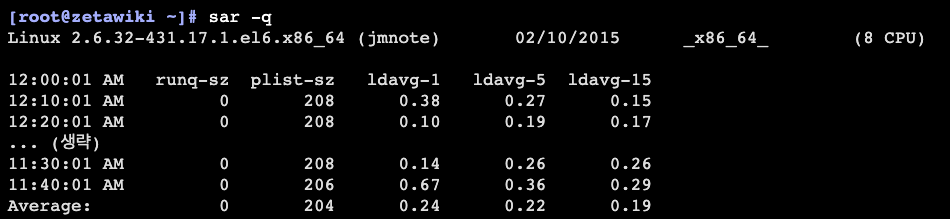
-
물리 메모리 사용 현황 확인(오늘)
sar -r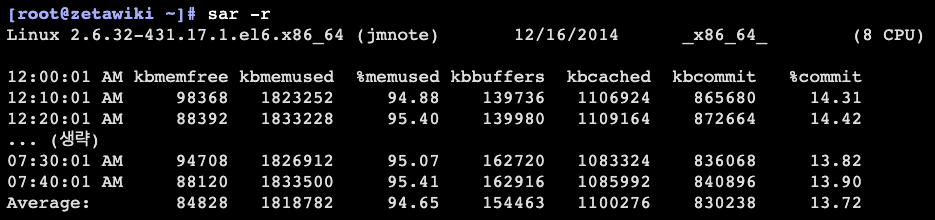
kbmemfree : 물리 메모리의 남은 용량(kbytes)
kbmemused : 사용중인 물리 메모리 양(kbytes)
%memused : 물리 메모리 사용률
kbbuffers : 커널에서 buffer 메모리로 총 사용된 물리 메모리의 양 (kbytes)
kbcached : 커널에서 cache data 로 사용된 총 물리 메모리의 양(kbytes)
kbcommit : 현재 작업을 위해 필요한 메모리의 총량(kbytes),메모리 부족이 발생하지 않기 위한 RAM/swap 사용량의 추정치
%commit : 현재 작업을 위해 필요한 메모리 총량의 %, kernel은 보통 메모리를 overcommits하므로 일반적으로 100%를 넘을 것이다.
8. 그이외 자주 쓰이는 시스템 모니터링 리눅스 명령어
- 다음 참고 자료들을 통하여 자주 사용되는 리눅스 명령어를 소개한다.
참고자료:
리눅스 쿡북
[Tip] Linux 메모리 확인 방법들
리눅스 명령어를 이용한 시스템 모니터링하기
리눅스 서버 60초안에 상황 파악하기
🏝이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)
참고 자료
