확장 가능 비즈니스를 위한 Web Scalability for Startup Engineers - 2편


- 📝 Web Scalability for Startup Engineers 을 읽고 정리한 글입니다.
- 이 책은 HTTP-based systems (websites, REST APIs, SaaS, and mobile application backends)에 관련된 Scalability를 다루고 있습니다. 특히, 스타트업이 겪을 수 있는 다양한 challenges와 issues들에 대해서 깊이 있고 실용적인 방법을 소개합니다.
- 본 포스팅은 확장 가능 비즈니스를 위한 Web Scalability for Startup Engineers 의 후속편으로 Front-End Layer, Web Services, Data layer 각각의 영역에서의 Scalibilty에 대해 다루고, 더 나아가 Caching, Asynchronous Processing, Searching for Data에 대해서 심도있게 다루고 있습니다.
- 작성 일자: 2020-05-26
Principles of Good Software Design
Design for Scale
1. Adding More Clones
- 제일 쉽게 Scaling 할 수 있는 전략으로 추가적으로 clone(복제) 하는 방법을 뜻한다.
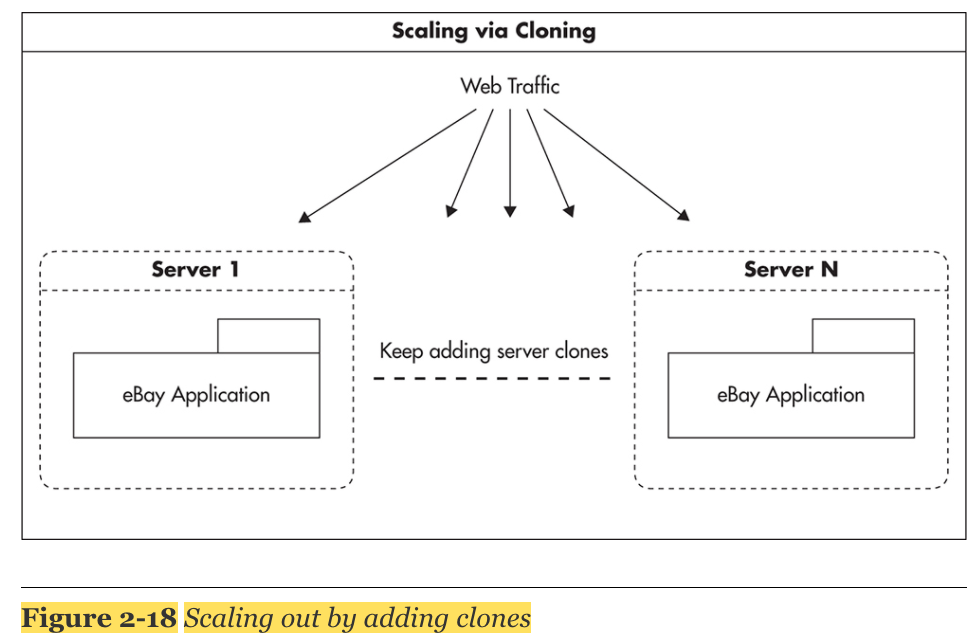
- 만약에 web services가 stateless 하다면 load balancer pool에 서버를 계속적으로 추가함으로써 쉽게 scaling이 가능해진다.
2. Functional Partitioning
- 기능에 따라 분리함으로써 Scaling 하는 전략을 뜻한다
- ex) object cache servers, message queue servers, queue workers, web servers, data store engines, and load balancers 으로 나누어서 각각의 서버를 운영한다.
3. Data Partitioning
- data 전체를 여러 머신에 복제시켜서 나누는 것이 아니라, data의 subset(일부분)을 각각의 machine에 분배함으로써 scaling하는 전략을 뜻한다.
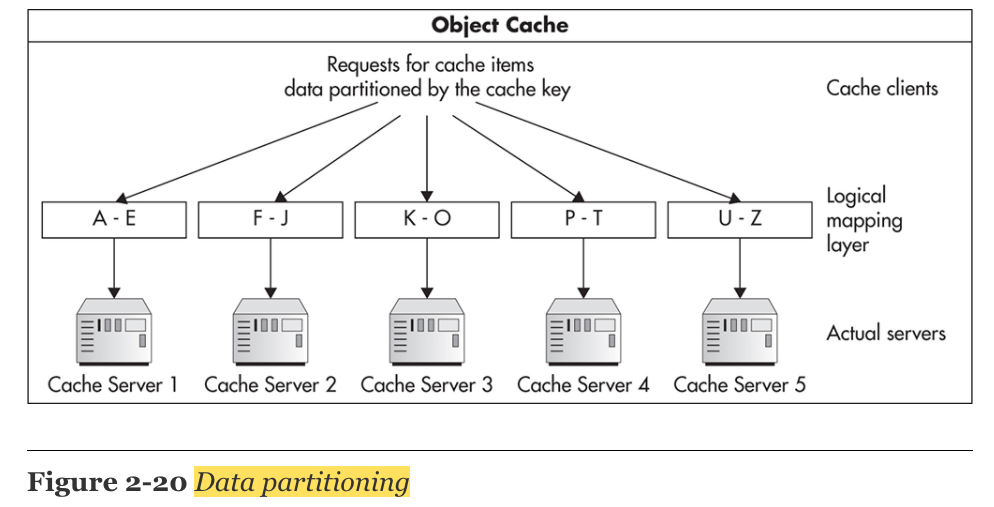
- ex) Object Cache를 scaling하기 위해서 Cached Object의 cache key와 Cache Server를 맵핑시킨 후, Data의 부분 집합을 Cache Server에 분배시켜 저장한다. 각각의 server가 적은 데이터를 가지게 됨으로써 더 빠르게 처리할 수 있고, 메모리에 더 많이 저장할 수 있게 된다. Cache Server를 계속 늘림으로써 Scaling이 가능해진다.
4. Self-Healing
특정 부분이 중단되더라도 다시 회복할 수 있는 능력을 뜻한다.
Building the Front-End Layer
- Front-End는 상대적으로 Scale하는 것이 쉽다. 핵심은 Stateless이다. 특히, Caching을 통해 많은 Scaling이 가능하다.
Managing State
- stateless가 핵심으로써 stateless란, 어떠한 data나 state를 지니고 있지 않은 것을 뜻한다. stateless services는 외부에 state를 전가함으로써 stateless 지위를 획득한다.
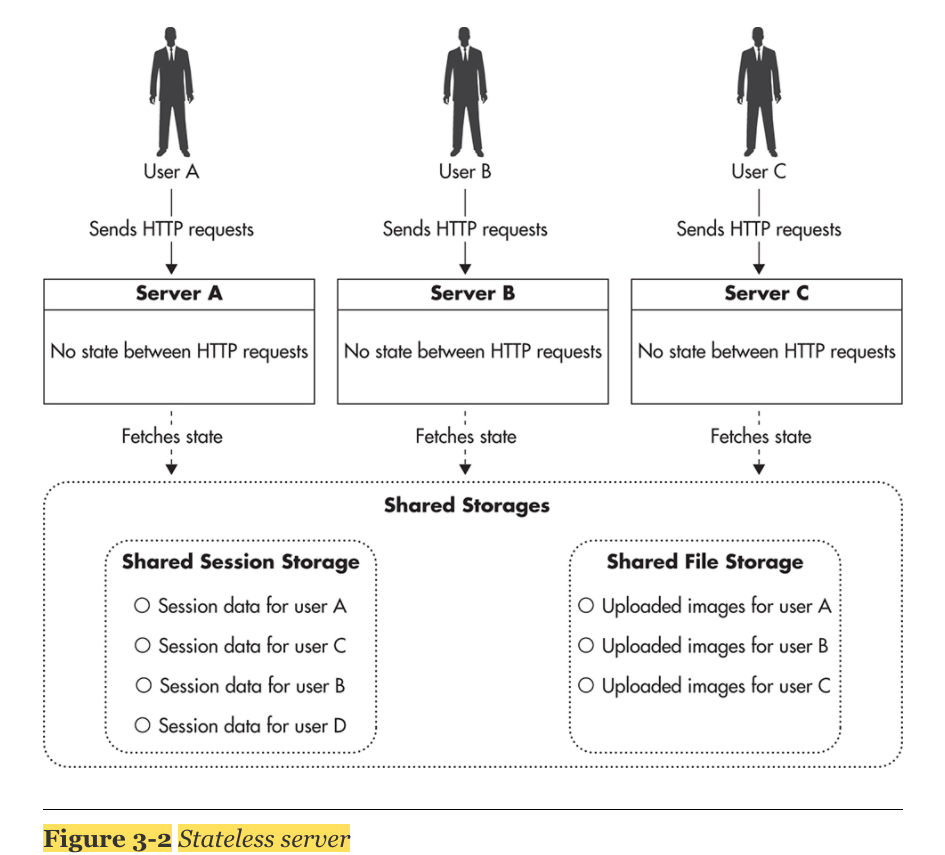
- server는 stateless 상태를 유지하고, shared storage에 state를 저장시킴.
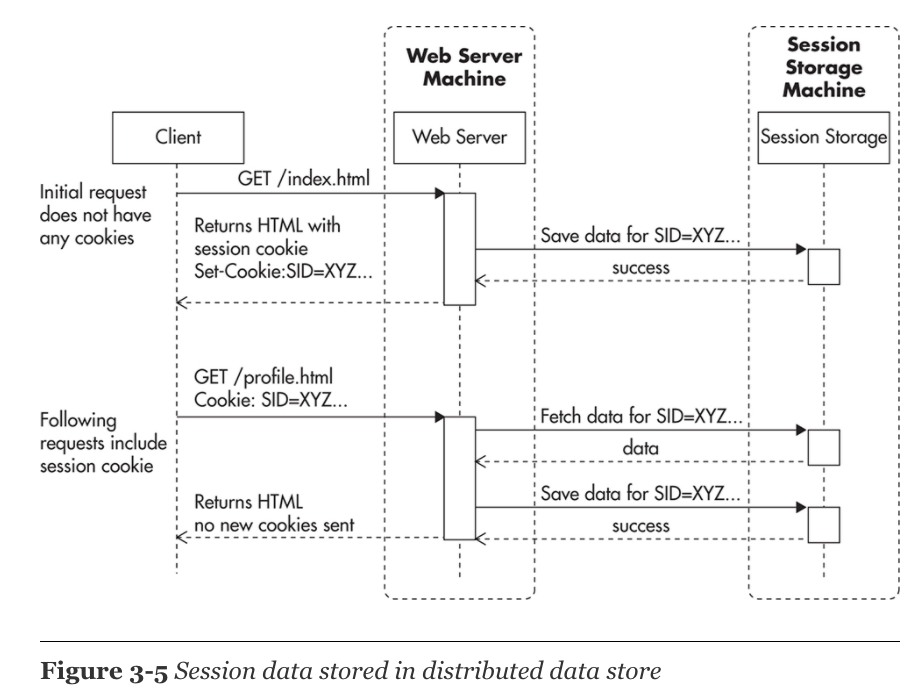
Managing HTTP Sessions
- HTTP protocol은 statelss특징을 가진다. session을 web server가 아닌 외부에 저장하기 위한 3가지 전략.
1. Store session state in cookies
- 작은 데이터를 저장할때 사용할 수 있는 방법으로, user ID, security token같은 것들을 cookie에 저장함으로써, 속도를 향상 시킬 수 있다. 다만 많은 데이터를 넣으면 web request 속도가 느려지기 때문에, 적은 데이터를 저장하는 데에만 사용한다.
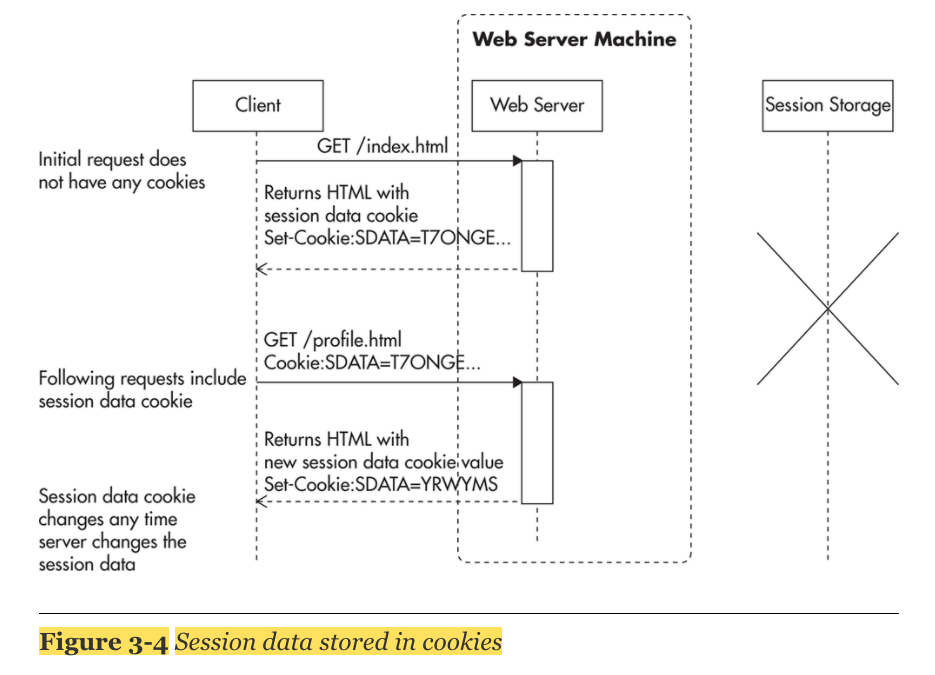
2. Delegate the session storage to an external data store
- Memcached, Redis, DynamoDB, or Cassandra 와 같은 솔루션을 사용해서 외부에 data store을 만드는 방식이다. 이외에 session의 경우, session ID별로 data partition할 수 있는 전략도 있다.
3. Use a load balancer that supports sticky sessions
- 추천하지 않는 방법이다.
Managing Files
- 유저가 컨텐츠를 생산해서 server에 올리는 경우, 우리 시스템에서 생성된 file을 유저가 우리 서버로 부터 download할 수 있게 하는 경우가 있다.
- CDN 과 Amazon S3를 사용함으로써 해결 가능하다.
- 일반적으로 분산 저장 스토리지는 매우 복잡한 문제이므로, 제일 먼저 Amazon S3와 같은 클라우드 서비스 이용을 적극 고려해야한다.
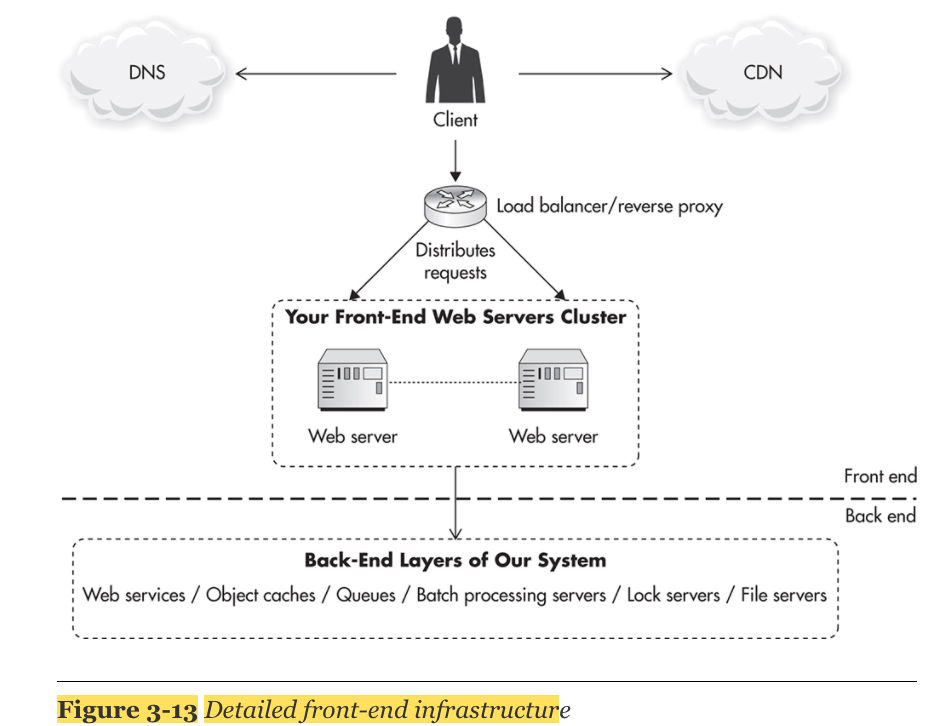
Components of the Scalable Front End
1. DNS
- 3rd party service를 이용할 것을 추천한다. ex) Amazon Route53 service
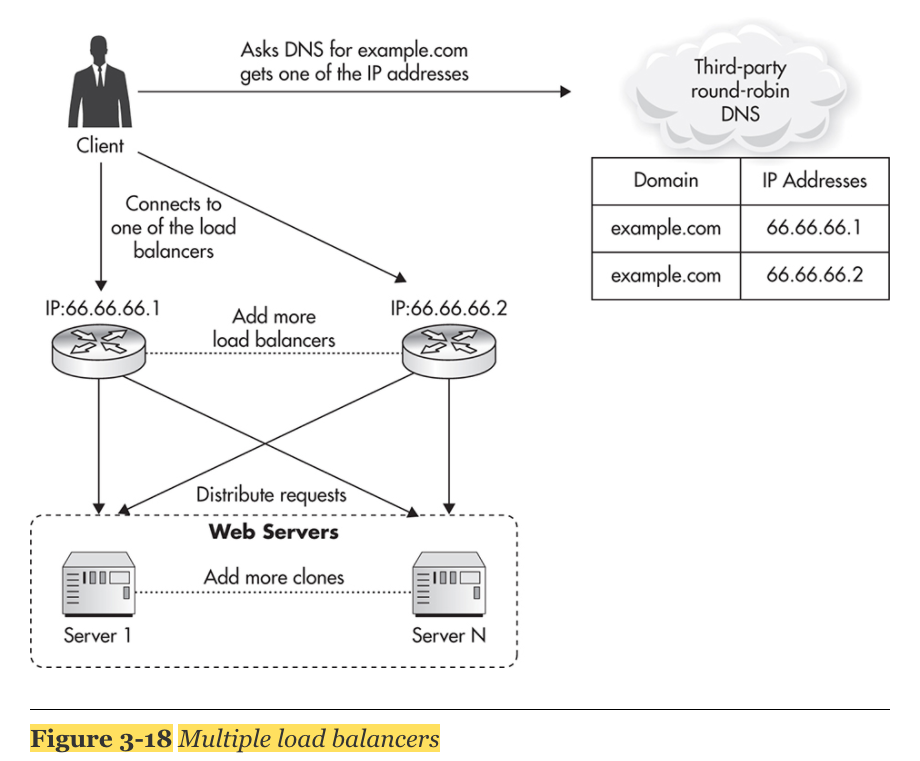
2. Load Balancers
- by deploying multiple load balancers under distinct public IP addresses and distributing traffic among them via a round-robin DNS.
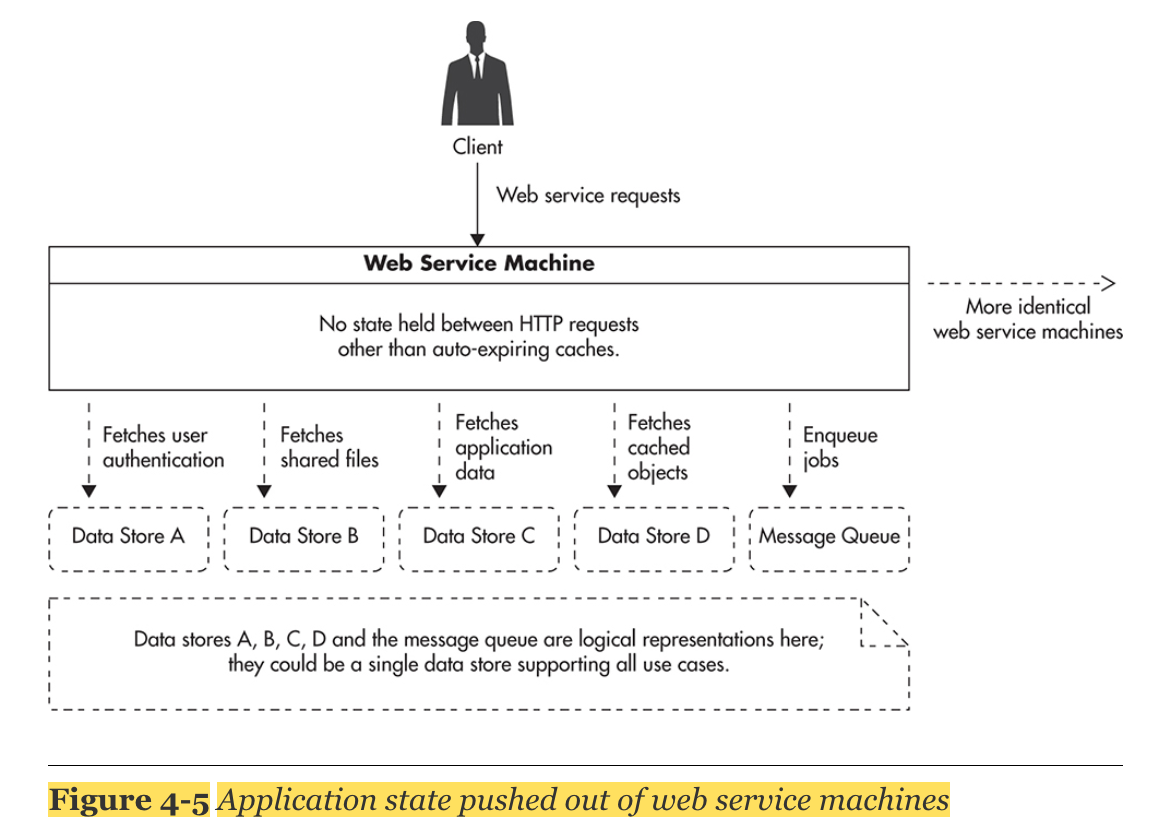
3. Web Servers
- should not have much business logic
- stateless 하다면 scaling 하기 쉽다.
- Zookeeper 와 같은 distributed lock systems 사용함으로써 resource lock을 피할 수 있다. 하지만 distributed lock은 어려운 문제이므로, 마지막 업데이트후 상태를 체크하는 방식으로 concurrency를 하거나, message queues를 사용하는 방식이 나을 것이다.
4. Caching
- CDN 사용
- Nginx와 같은 reverse proxies 사용
- Redis, Memcached 와 같은 shared object cache 사용 ex) authentication token
- HTTP caching
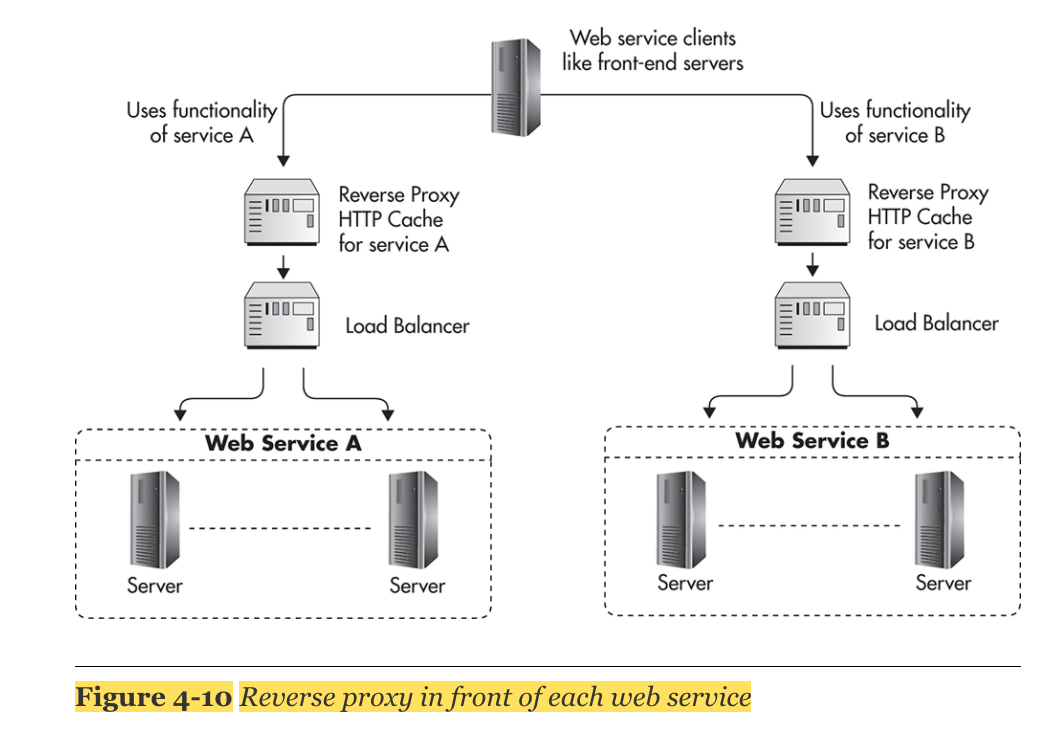
5. Auto-Scaling
- Amazon Ec2 사용
- Amazon S3 사용
- Amazon ELB 사용
- Amazon Cloud Watch사용
Deployment Examples
AWS Scenario
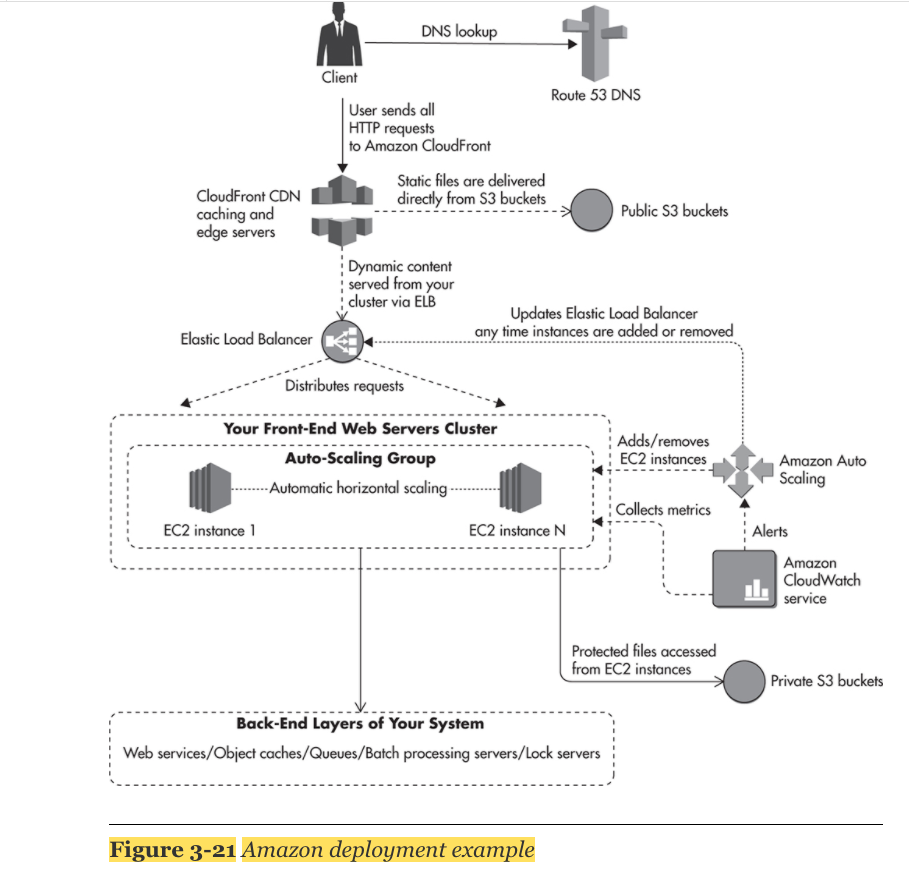
Data Layer
Scaling with MySQL
1. Replication
- master - slave 구조: master는 updates, inserts, deletes, create에 관여하고, slave는 read하는 역할을 한다.
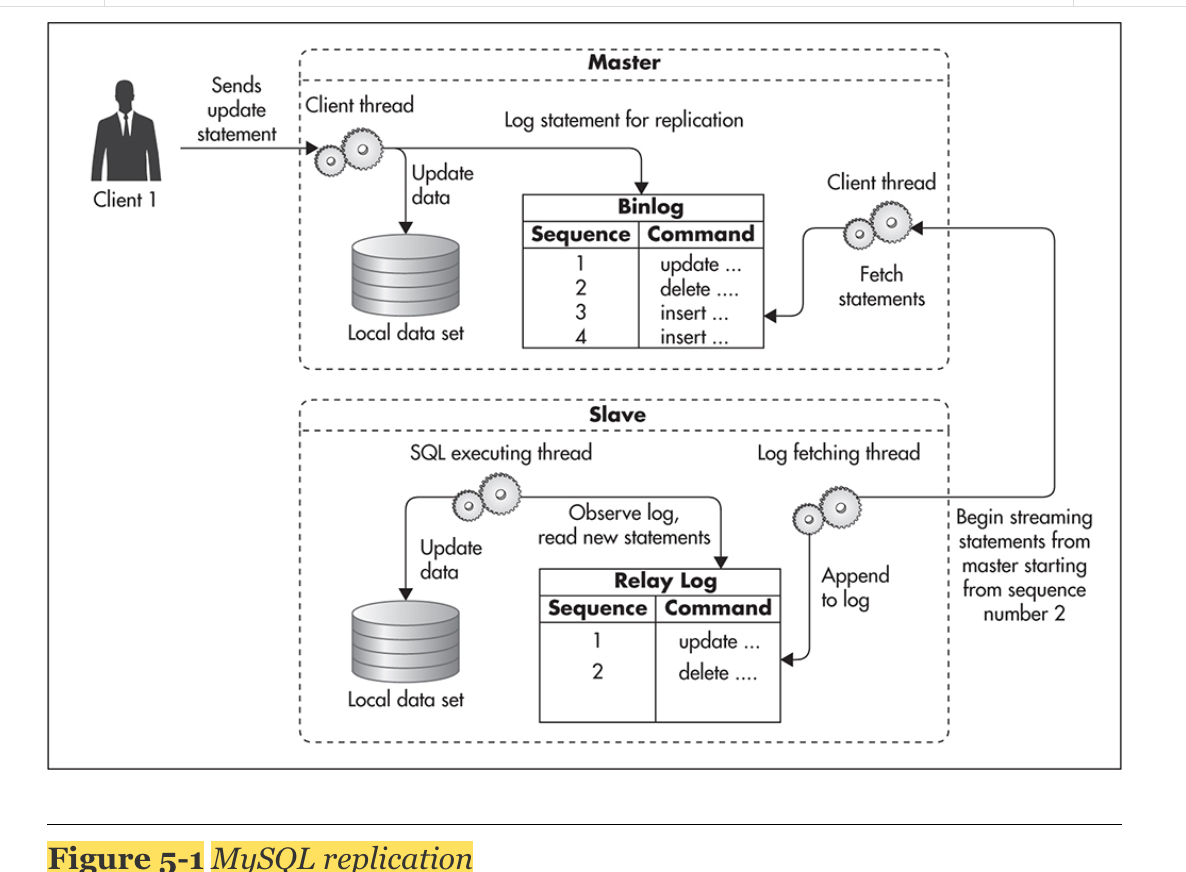
- MySQL replication
- 비동기적임: master는 slave가 statement를 replicated 하기를 기다리지 않음
- multiple slave를 가질 수 있음
- 동작원리:
1) client가 master에 연결되서 data modification statement 를 실행시키고, binlog file에 기록함
2) slave server는 비동기적으로 master의 binlog file을 보고 relay log에 기록함 - 장점:
1) You can distribute read-only statements among more servers, thus sharing the load among more machines.
2) You can use different slaves for different types of queries. For example, you could use one slave for regular application queries and another slave for slow, long-running reports.
3) You can use the asynchronous nature of MySQL replication to perform zero-downtime backups.
4) If one of your slaves dies, you can simply stop sending requests to that server (taking it out of rotation) until it is rebuilt. - 단점:
1) master failure를 recover시키는 것이 복잡하다.
2) write를 scale시킬 순 없다.
3) data set size를 scale시킬 순 없다.(데이터 전체를 복제하니까 scale 관점에서 악영향)
4) 단점을 극복하는 방안으로 MySQL solution인 Amazon RDS를 사용하는 방안이 있다.
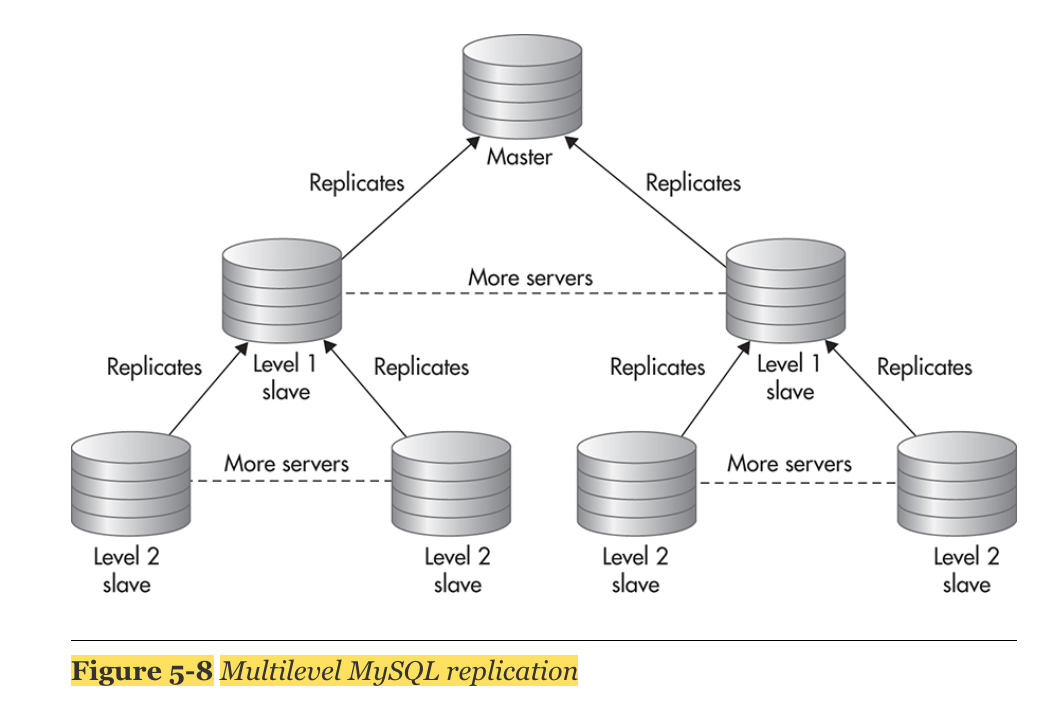
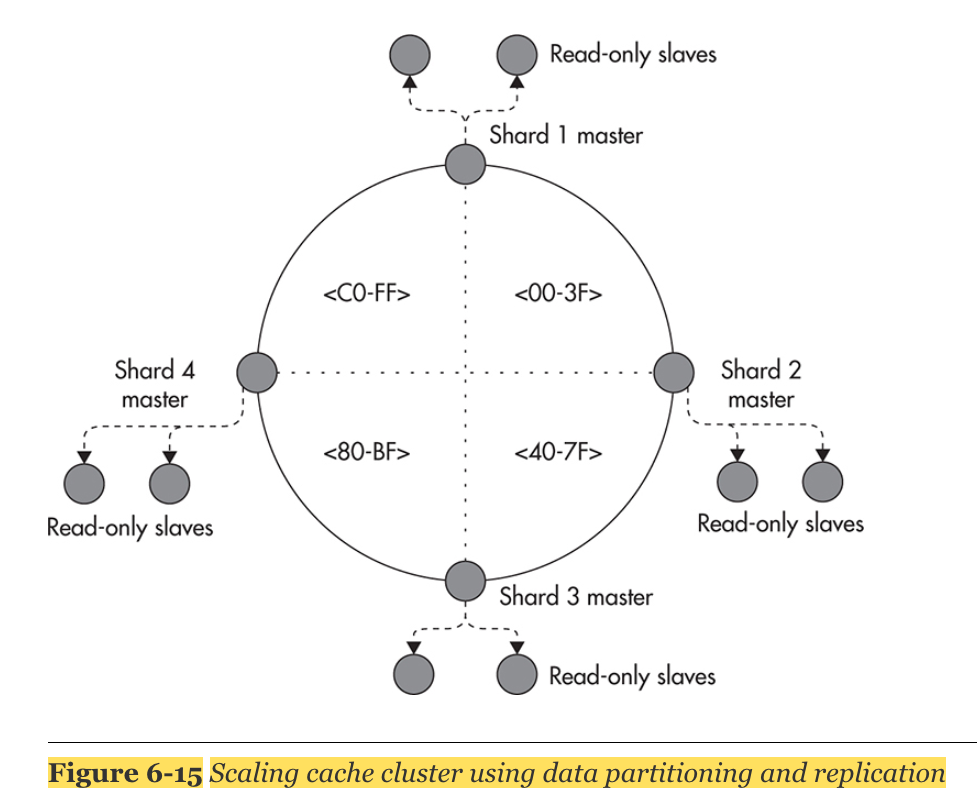
2. Data Partitioning(Sharding)
- dataset을 smaller bucket에 나누어 담는 것을 sharding이라고 한다.
- sharding key를 정하는 것이 핵심이다. sharding key는 어떤 server가 그 데이터를 담당하고 있는지 결정하는 정보가 된다.
- You can apply sharding to object caches, message queues, nonstructured data stores, or even file systems.
- Challenges: you cannot execute queries spanning multiple shards
sharding 하는 방법
1. range-based sharding
- ex) account ID를 sharding key로
- sharding할경우 dataset이 비슷한 분포로 나뉘는 sharding key를 설정하는 것이 중요
2. modulus-based sharding
- ex) modulo operator를 사용하여 server number를 sharding key로 사용
- 단점: 전체 server 갯수가 바뀌면 mapping에 영향을 준다. 따라서 추가적인 server를 더하기 힘들어진다.
- 다음과 같이 lookup table을 만드는 방식으로 극복 할 수 있다.
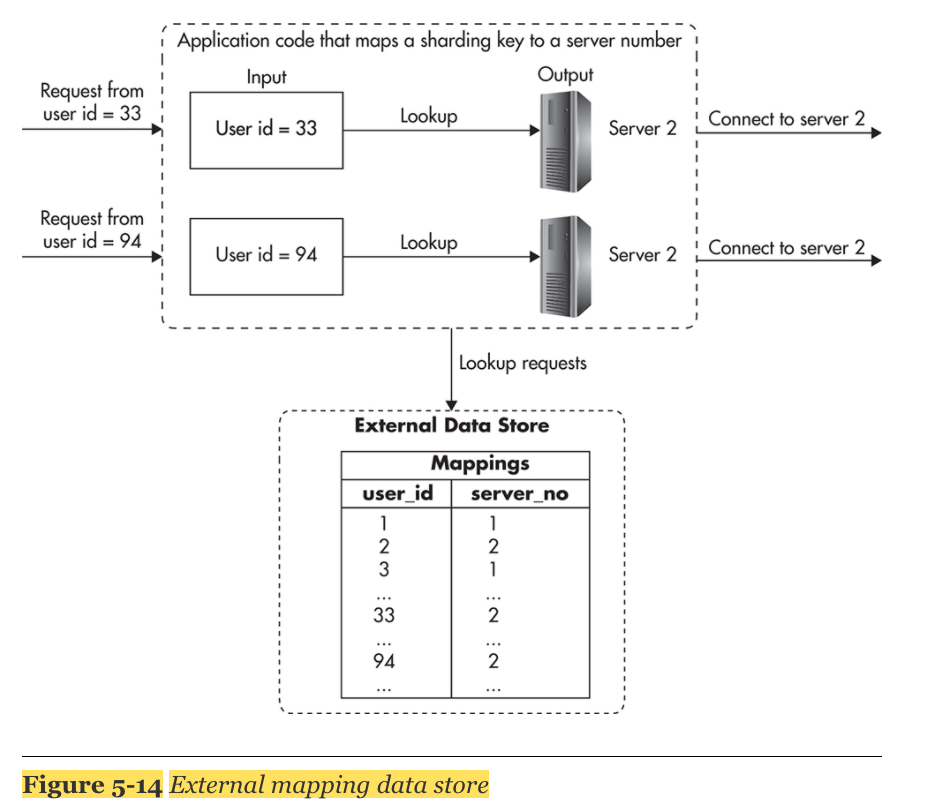
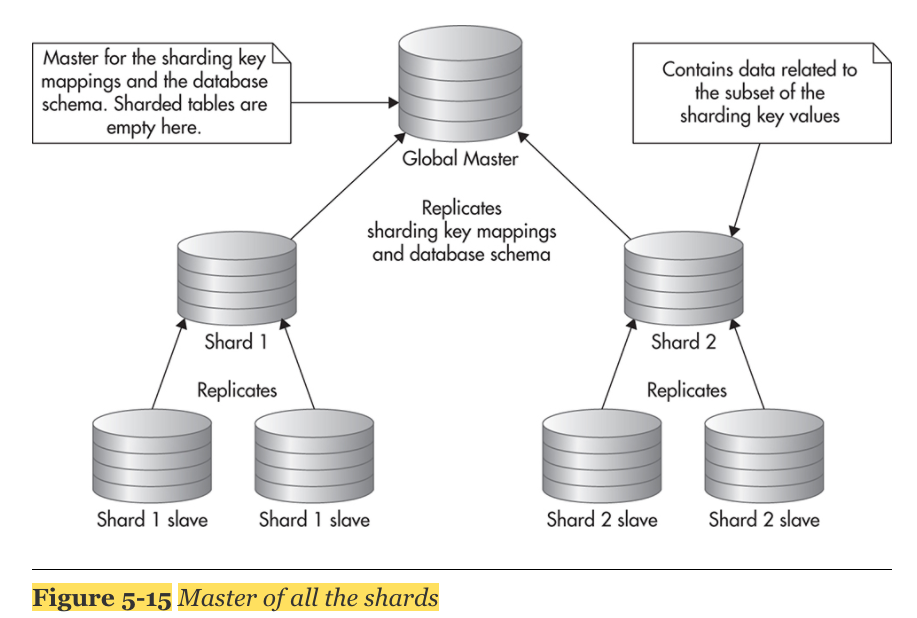
- 위의 방식을 약간 변형시켜 master가 sharding key mapping table 을 가지고, slave를 두는 방식이 있다.
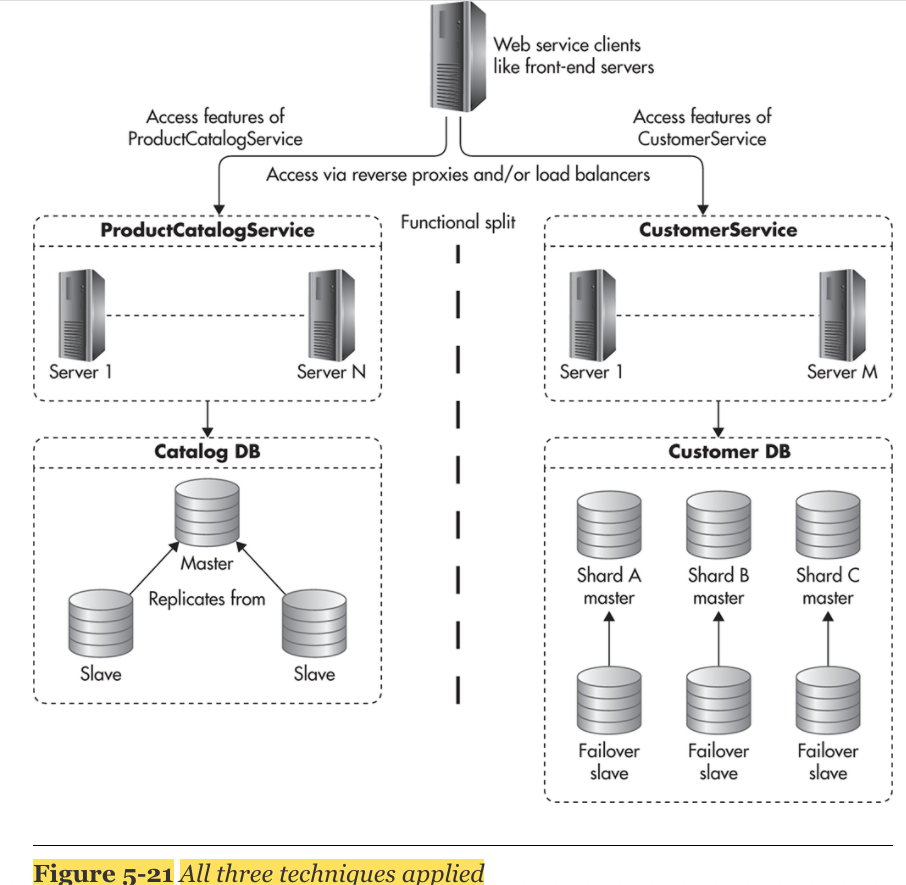
- 최종적으로 replication 방식과 sharding 방식을 합치면 다음과 같다.
Scaling with NoSQL
1. The Rise of Eventual Consistency
- Quorum 과 Configurable Threshold를 통해 결과적 인관성(Eventual Consistency)을 구현한다.
- 결과적 인관성(Eventual Consistency)는 특정 서버가 변경된 데이터를 조회하고, 일부는 변경되지 않은 상태에서 조회될 수 있는데, 이때 데이터의 일관성을 위하여 모든 서버에 결과값을 질의하고 N개 이상이 같은 값을 반환할때 사용자에게 해당 값을 보여주는 형태의 일관성이다.
2. Faster Recovery
- Many of the modern NoSQL data stores support automatic failover or failure recovery in one form or another
3. Cassandra Topology
- BigTable 과 Dynamo를 합친 형태
- Client는 어떤 노드에도 연결 가능. 모든 노드는 같은 기능을 수행함. Client는 노드가 어떤 데이터를 가지고 있는지 알 필요없음.
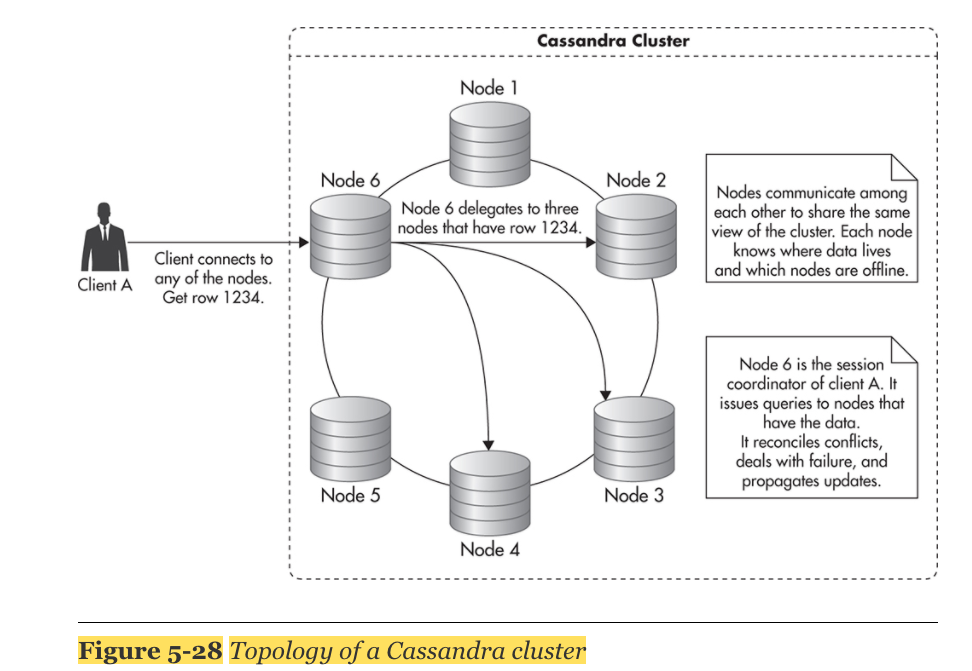
- cassandra는 data partitioning(샤딩)을 자동으로 수행함
- node들끼리 서로 communicate를 하고, 서로 어떤 데이터를 가지고 있는지 알고 있음
- wide cloumn 모델에 기초해 있는데, unlimit row를 가질 수 있음
- Different rows may have different columns (fields), and they may live on different servers in the cluster.
- To access data in any of the columns, you need to know which row are you looking for, and to locate the row, you need to know its row key
- Cassandra server is responsible for that particular partition range and delegates the query to the correct server.
- no master–slave relationship between servers
- although the client connects to a single server and issues a single write request, that request translates to multiple write requests, one for each of the replica holders.
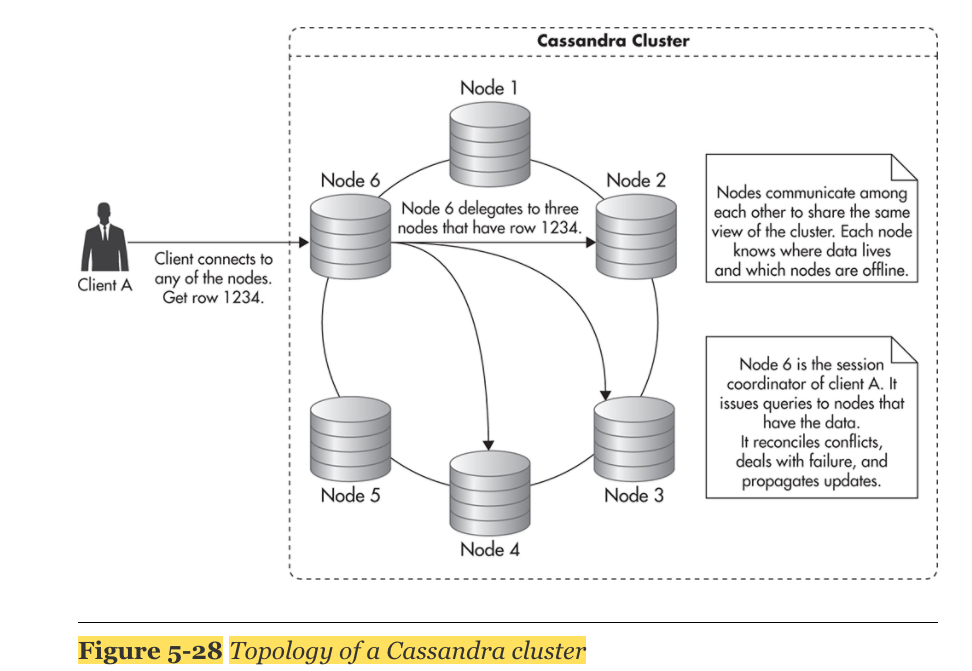
- The more servers you add, the more read and write capacity you get, and you can easily scale in and out depending on your needs.
- adding new servers is as easy as starting up a new node and telling it to join the cluster. Again, Cassandra takes care of rebalancing the cluster and making sure that the new server gets a fair share of the data.
- deletes are the most expensive type of operation you can perform in Cassandra.
- Cassandra uses append-only data structures, which allows it to write inserts with astonishing efficiency.
Caching
Cache Hit Ratio
Cache Hit Ratio: 얼마나 같은 cached response를 자주 사용하는지
- Cache Hit Ratio에 영향을 주는 3가지 요소:
1. space: 자주 사용될 수 있는 Cache key를 잘 설정함으로써 최대한 적은 갯수의 cache keys를 갖는 것이 중요하다.
2. dataset size: 최대한 많은 item들을 cache화 할 수 있을 수록 좋다.
3. longevity: cache를 최대한 오랫동안 유지 시킬 수 있을 수록, 다시 재사용할 확률이 높아진다.
Caching Based on HTTP
read-through cache: client와 server사이에 지나가는 중간 통로에 있는 cache로써, client가 원하는 정보가 read-through cache에 있는 지 확인한 후, 없으면, 서버에 직접가서 원하는 정보를 요청하게 된다.
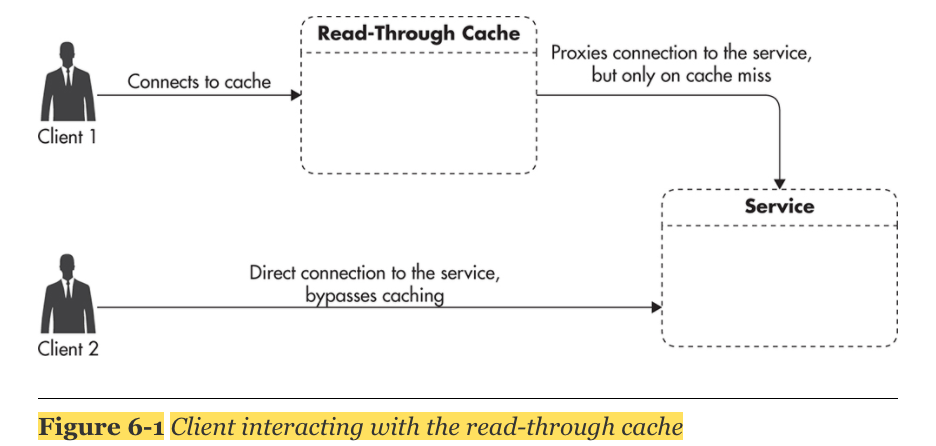
HTTP Caching Headers
- HTTP header를 통해 cache설정을 할 수 있다.
HTTP header의 Cache-Control 옵션에서 다음과 같은 설정을 통해 cache 관련 설정이 가능하다.
1. private: 특정 유저에 대한 response를 원할 때 사용,현업에서는 브라우저만 이 response를 cache할 수 있도록 하고 싶을때 사용.
2. public: 모든 유저가 share가능한 cache를 사용할 때
3. no-store: response가 memory안에 cache가능하고, disk에는 저장 못 시키게 할 때 사용.
4. max-age: TTL(cache age) 설정 - 최대 1년까지만 설정하도록 권장한다.
5. no-transform: CDN같은 경우 size를 reduce하거나, 저화질로 변형시키거나 하는데, 원본 response를 그대로 받고 싶을 때 사용
6. must-revalidate: cache보고 stale response를 주지 말라고하기 위해 사용.
Types of HTTP Cache Technologies
1. Browser Cache: 일반적으로 memory와 local files의 조합을 통해 사용된다. 만약 요청한 item이 browser cache에 존재한다면, HTTP request없이 그 item을 반환해준다. 그 결과, page load 속도, rendering 속도, static files 전송해주는 속도를 빠르게 해준다.
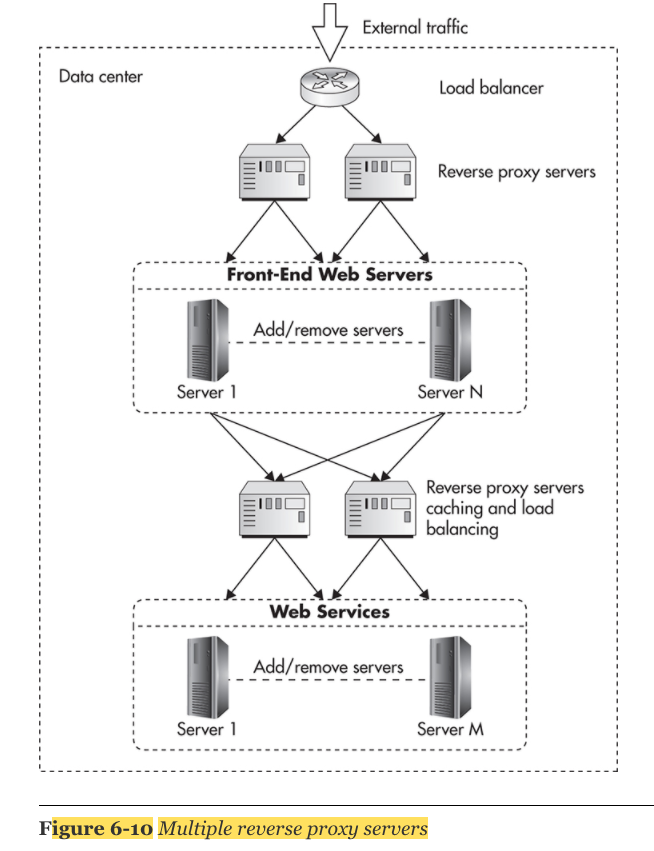
2. Reverse Proxy: Front-End layer 와 server 사이에 위치시킴으로써, server의 부하를 줄여준다. reverser proxy는 scale하기 좋다.
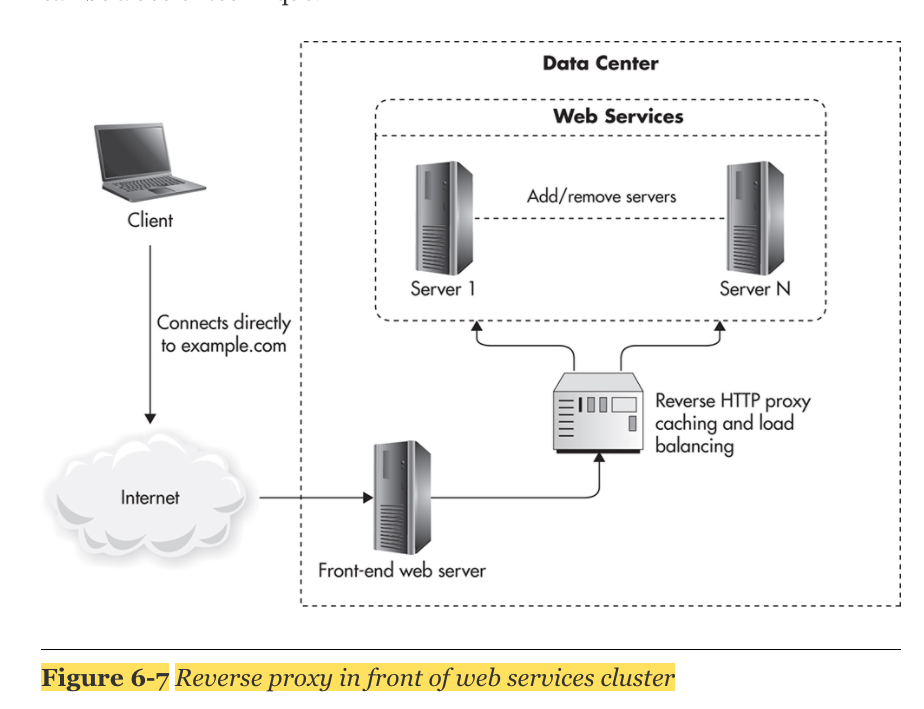
3. CDN: CDN provider는 static content와 dynamic content 둘다 지원한다. DDOS공격에 대한 방어책이 된다.
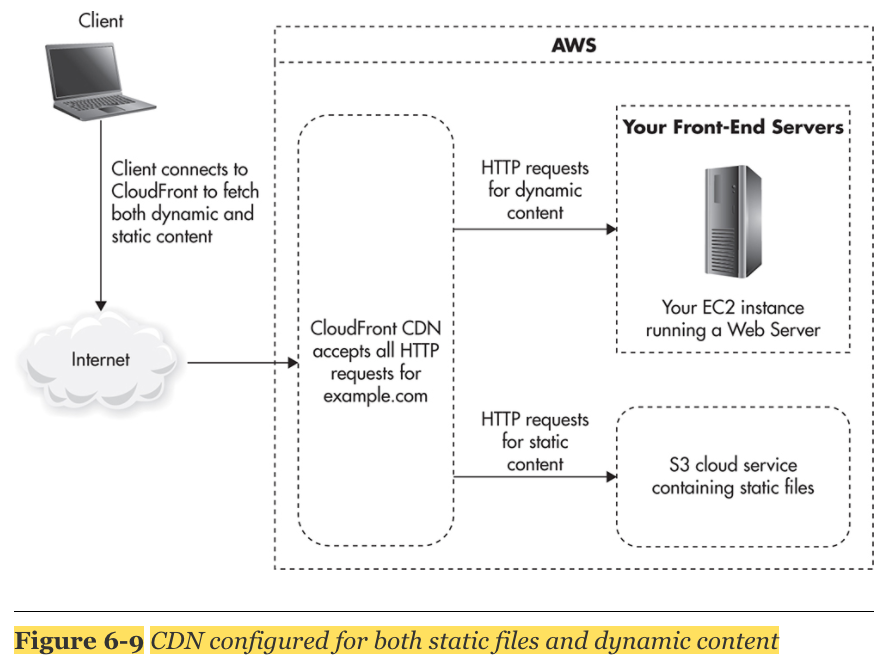
Scaling HTTP Caches
browser cache와 3rd party proxy servers는 사실 우리 관리의 영역은 아니다. 알아서 잘 scale하게 작동한다(?)
우리가 신경써야할 cache는 Nginx와 같은 reverse proxy servers이다. By deploying multiple reverse proxies in parallel and distributing traffic among them, concurrency limit 또는 throughput limit을 향상 시킬 수 있다.
다음 특성을 주의해서 관리한다.
1) Cache Key space
2) Average Response TTL - LRU알고리즘을 통해 "hot" item을 관리할 수 있음. TTL을 통해 cache invalidation을 관리함.
3) Average size of cached object
- HTTP caching을 올바르게 사용하고 있다면, reverse proxies를 추가해서 parallel하게 돌리는 것은 문제가 안된다. 왜냐하면 HTTP protocol은 HTTP caches 끼리 synchronization을 필요로 하지 않기 때문이다.
Caching Application Objects
Object caches: 'read-through'가 아닌'cache-aside'의 역할을 한다. 따라서 application이 object cache의 존재를 알고 있어야하고, 적극적으로 이를 사용한다. 일반적으로 key-value방식의 data store 이다.
Common Types of Object Caches
1. client-side cache: client쪽에서 동작하는 object cache
1) web storage: key-value store형식이고, 경량을 데이터를 cache화하는데 사용됨
2) local device storage: single-page applications(SPA)을 개발할때 유용하게 사용됨.
2. caches co-located with code: appliciation's memory에서 chache화 되어 있는 형태이다. overhead가 없이 바로 접근 가능하다. 하지만, 이는 server을 cloning방식으로 scale시킬 때, 중복된 duplicate가 많이 발생함으로, 좋은 scale전략은 아니다.
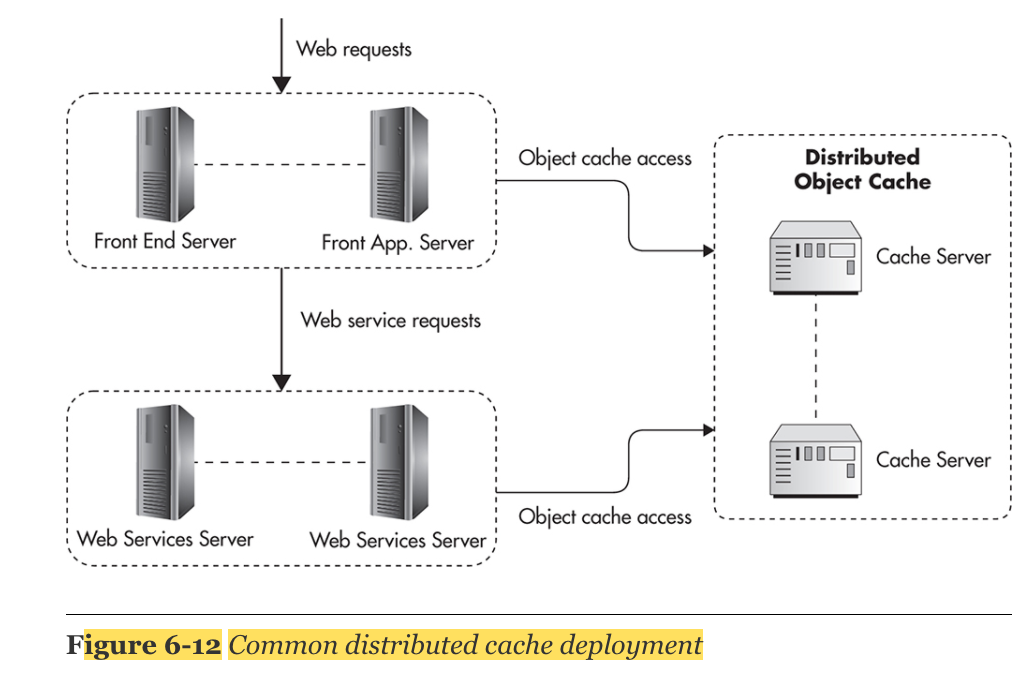
3. distribute object caches: 따로 외부에 Memcached, Redis와 같은 cache server를 따로 둠으로써, external shared memory방식의 형식을 취한다. server 1개로도 초당 수만개의 request를 감당할 수 있으므로 처음에는 memory를 추가하는 방식으로 scale을 한 후, 이후에 data-partitioning, replication을 통한 server 추가 개설을 scale 전략으로 취할 수 있다. 'cache invalidation'이 쉽다. cache key를 hash화 시킴으로써 분산 cluster의 일관성을 유지한다.
Asynchronous Processing
Asynchronous Processing: the caller never waits idle for responses from services it depends upon
ex) I/O 처리, TCP/IP connection 등에 활용할 수 있음.
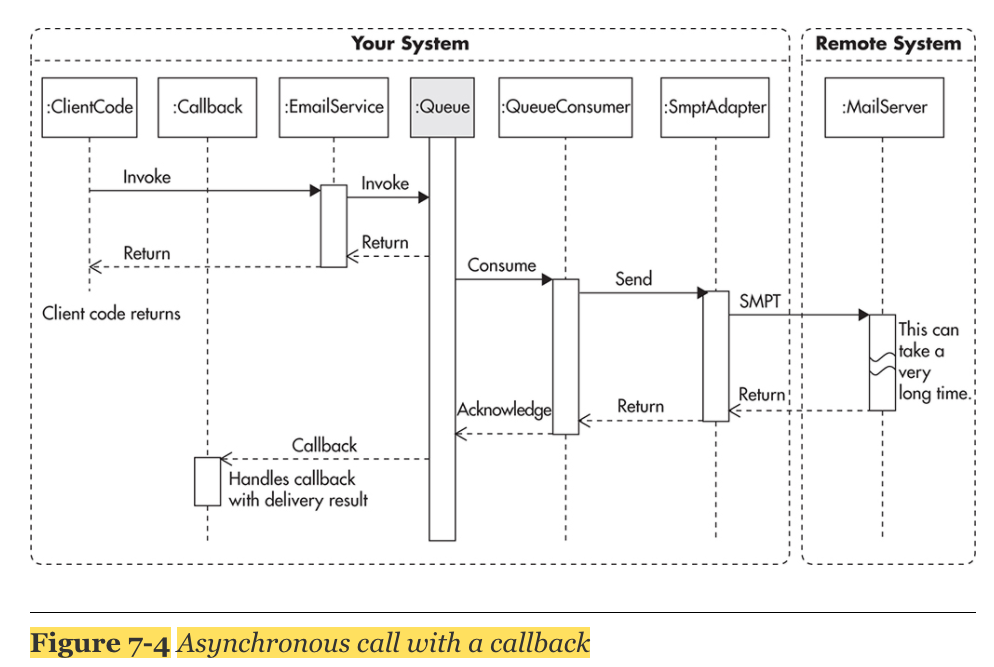
Direct Worker Queue Method
message queue(message broker): a component that buffers and distributes asynchronous requests
- message queue의 장점:
1) 비동기 처리를 가능하게 해준다.
2) producer와 consumer을 decouple시킴으로써 scale하기 쉽게 해준다
3) traffic이 솟구치는 것을 평탄하게 해준다.
4) failure에 더 견고하게 해준다. - message queue의 단점:
1) no message ordering (순서가 뒤죽박죽 들어옴)
2) race condition이 더 잘 발생하는 경향이 있다. - 구축시 안티패턴(하지말아야할 패턴)
1) Treating the Message Queue as a TCP Socket: consumer가 message를 다시 producer에게 send back하는 채널처럼 역할을 하게되면, 비동기처리가 되려 동기처리로 되버린다.
2) Treating Message Queue as a Database: It is best to think of a message queue as an append-only stream (FIFO).
3) Coupling Message Producers with Consumers: It is best to think of the message broker as being the endpoint and the message body as being the contract.
4) Lack of Poison Message Handling: A common anti-pattern is to assume that messages are always valid. 하지만 failure하는 경우도 있기 때문에, failure을 항상 대비해야한다.
producer 와 consumer는 각각의 서버에서 호스팅되고, 독자적으로 일할 수 있다.
- The separation of producers and consumers using a queue gives us the benefit of nonblocking communication between producer and consumer
- Another benefit of this separation is that now producers and consumers can be scaled separately. 서로 message queue를 사이에 두고, decoupling되어 있음
- message conumers을 'queue workers'라고도 부른다.
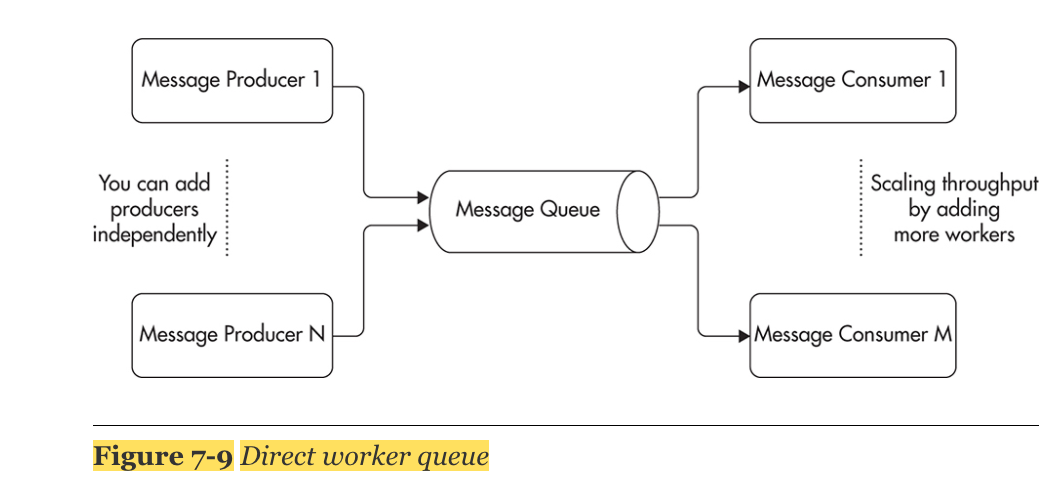
Publish/Subscribe Method
Producers는 message를 topic에 publish 하고, consumer는 topic을 subscribe함
- Consumers using the publish/subscribe model have to connect to the message broker and declare which topics they are interested in.
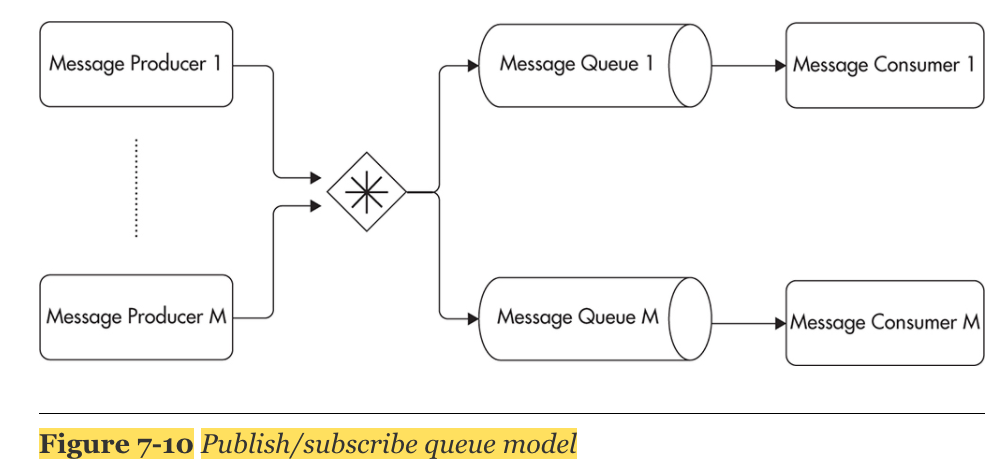
A good example of this routing model is to publish a message for every purchase. Your e-commerce application could publish a message to a topic each time a purchase is confirmed. Then you could create multiple consumers performing different actions whenever a purchase message is published. You could have a consumer that notifies shipping providers and a different consumer that processes loyalty program rules and allocates reward points.
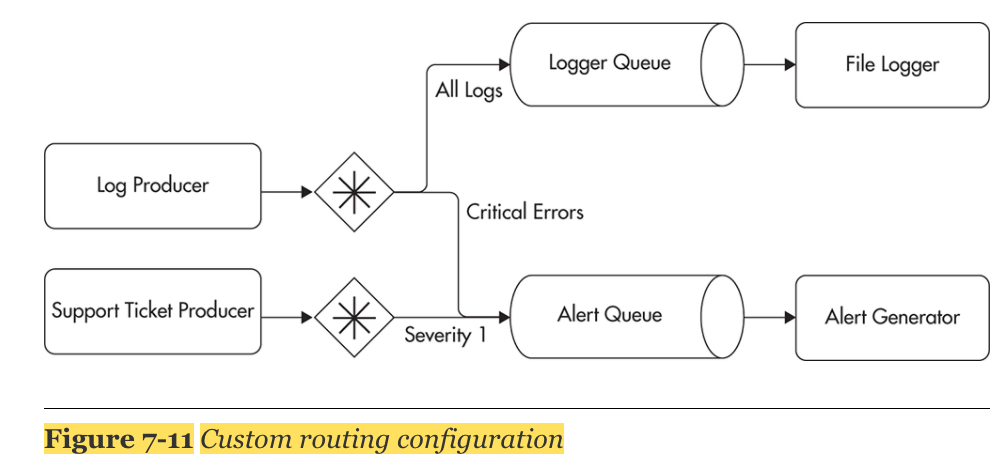
Custom Routing Rules
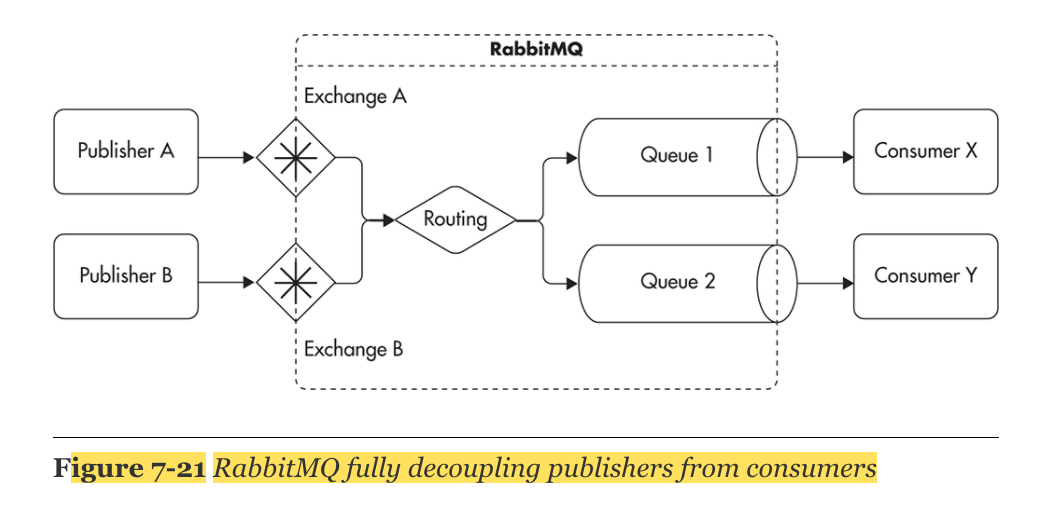
RabbitMQ
RabbitMQ
An exchange is just an abstract named endpoint to which publishers address their messages. Publishers do not have to know topic names or queue names as they publish messages to exchanges. Consumers, on the other hand, consume messages from queues.
Publishers have to know the location of the message broker and the name of the exchange, but they do not have to know anything else. Once a message is published to an exchange, RabbitMQ applies routing rules and sends copies of the message to all applicable queues.
Event-Driven Architecture
events can be published without having to know their destination. Event publishers do not care who reacts or how they react to events. By its nature, all event-driven interactions are asynchronous, and it is assumed that the publisher continues without needing to know anything about consumers. The main advantage of this approach is that you can achieve a very high level of decoupling. all the interactions are based on events
🏝이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)
참고 자료

언제나 좋은 포스팅 감사합니다 ~