cs231n 강의 중 'Lecture 2 | Image Classification' 을 정리한 내용이다.
Image Classification에서의 problem
-
Semantic gap
- 인간과 달리, 컴퓨터는 고양이와 같이 단순한 물체를 인식함에 있어서도 매우 큰 픽셀의 데이터를 활용해야 하며, 복잡하다.
-
Viewpoint variation
- 다른 각도에서 찍힌 사진을 같은 물체로 인식하기도 어렵다.
-
Illumination
- 밝기에 따라 물체를 인식하기 힘들어지기도 한다.
-
Deformation
- 다른 자세로 있을 경우 인식하기 힘들기도 한다.
-
Occulsion
- 물채의 일부만 있을 경우 인식하기 힘들다.
-
Background Clutter
- 배경과 유사하면 인식하기 힘들다.
-
Intraclass variation
- 물체의 종, 모양에 따라 다르게 인식할 수 있다.
- 이 문제를 해결하기 위해 유사한 이미지를 가져와 머신러닝 classifier를 훈련시키고, 새로운 이미지에 대해 어떤 classifier인지 판단하는 방법을 이용하기 시작했는데, 이 data-driven approach idea를 통해 간단한 classifier를 다루는 방법이 정립되었다.
Nearest Neighbor Classifier

-
training 과정에서 시간은 오래 걸려도 test 과정에서 시간은 짧은 것이 좋다. training은 미리 진행해놓고 나중에 실전에서 test를 여러번 적용할 수 있기 때문이다.
-
K-Nearest Neighbors
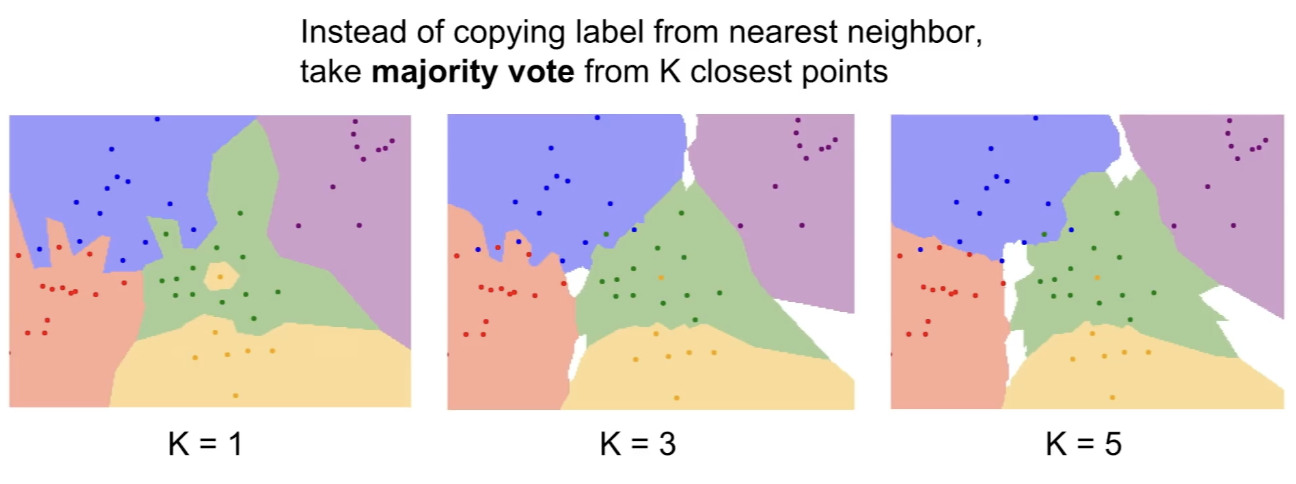
- decision boundary를 원만하게 만들어준다.
-
L1 Distance와 L2 Distance
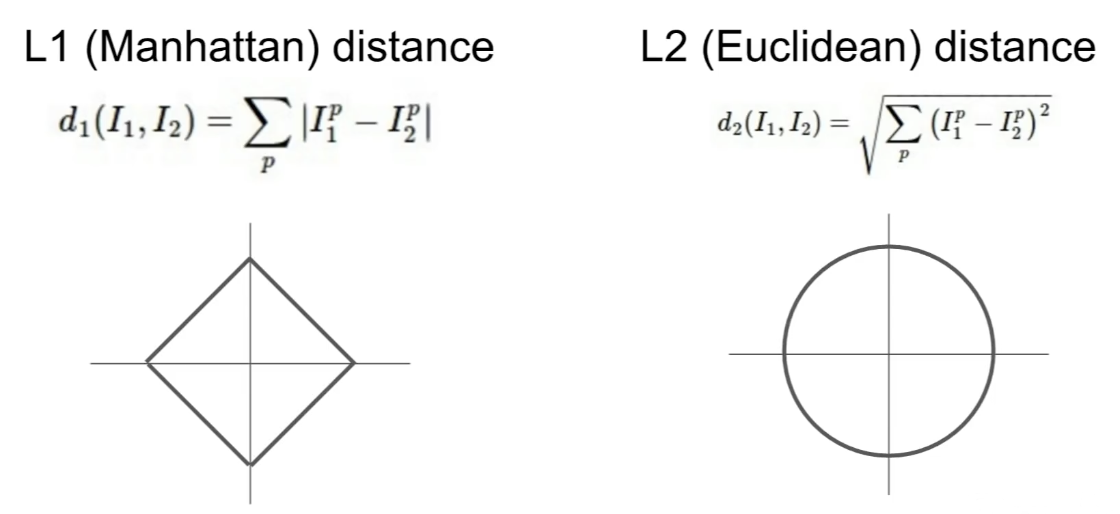
- 만약 input feature가 task에 유의미한 영향을 주면 L1 distance가 적절할 수 있고, 의미를 모른다면 L2 distance가 적절할 수 있다.
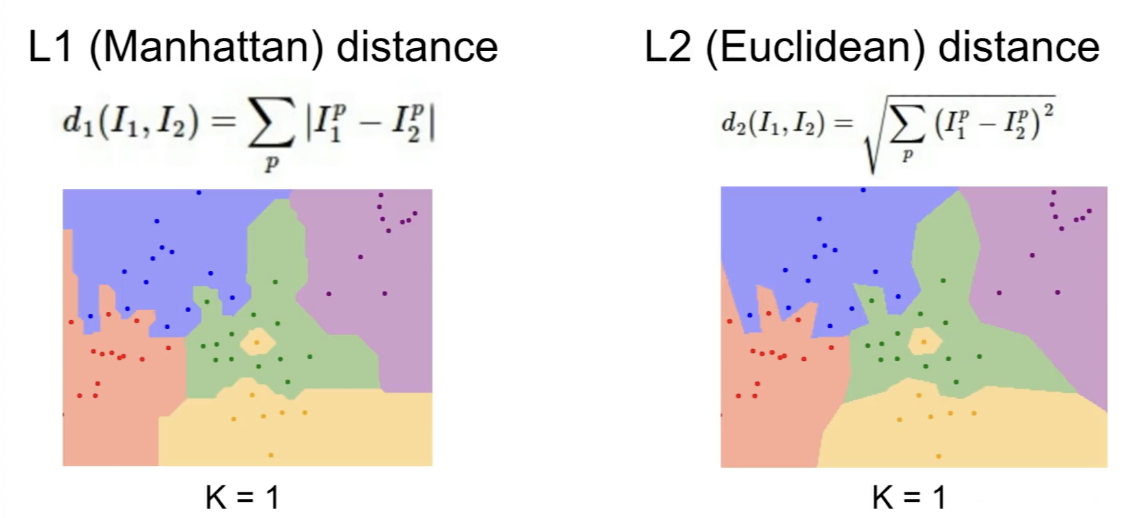
- 만약 input feature가 task에 유의미한 영향을 주면 L1 distance가 적절할 수 있고, 의미를 모른다면 L2 distance가 적절할 수 있다.
Hyperparameters
-
k-Nearest Neighbors에서의 k를 몇으로 설정할지, distance는 어떤 것을 선택할지 등 hyperparameter를 잘 설정해야 한다.
-
문제에 따라 다르므로 여러 번 시도해보는 것이 좋다.
-
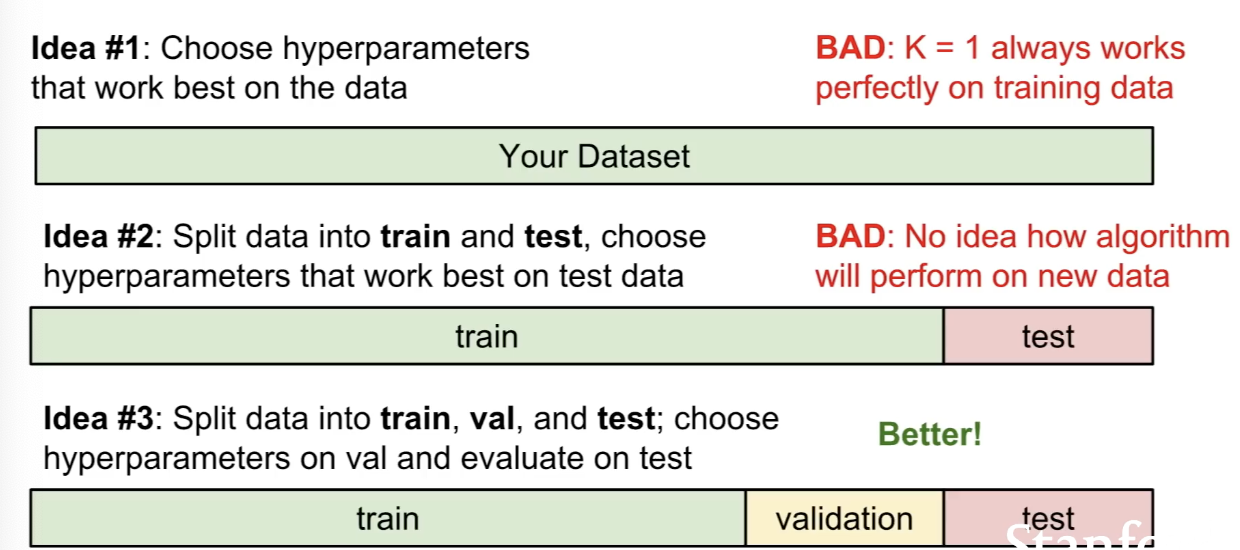
Hyperparmeter를 설정하는 여러 방법이 있을텐데, training data에만 잘 적용되는 아이디어는 좋지 않다. train, validation, test set으로 나누는 것이 이후 unseen data를 다룸에 있어 효과가 좋다.
- cross validation 방법은 작은 데이터셋에 대해 유용하다.
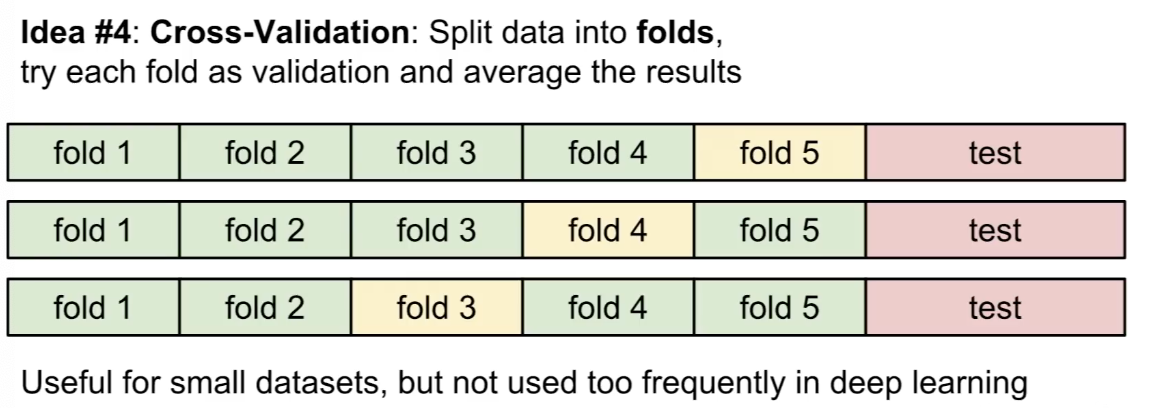
- cross validation 방법은 작은 데이터셋에 대해 유용하다.
k-Nearest Neighbor on images
- k-Nearest Neighbor는 이미지 데이터에 대해 사용되지 않는다.
- test 과정에서 매우 느리고, distance metrics가 잘 적용되지 않기 때문이다.

- 이 경우 이미지를 바꾸어도 L2 distance는 모두 같은데, 이는 잘 인식하지 못한 것이다.
- Curse of dimensionality
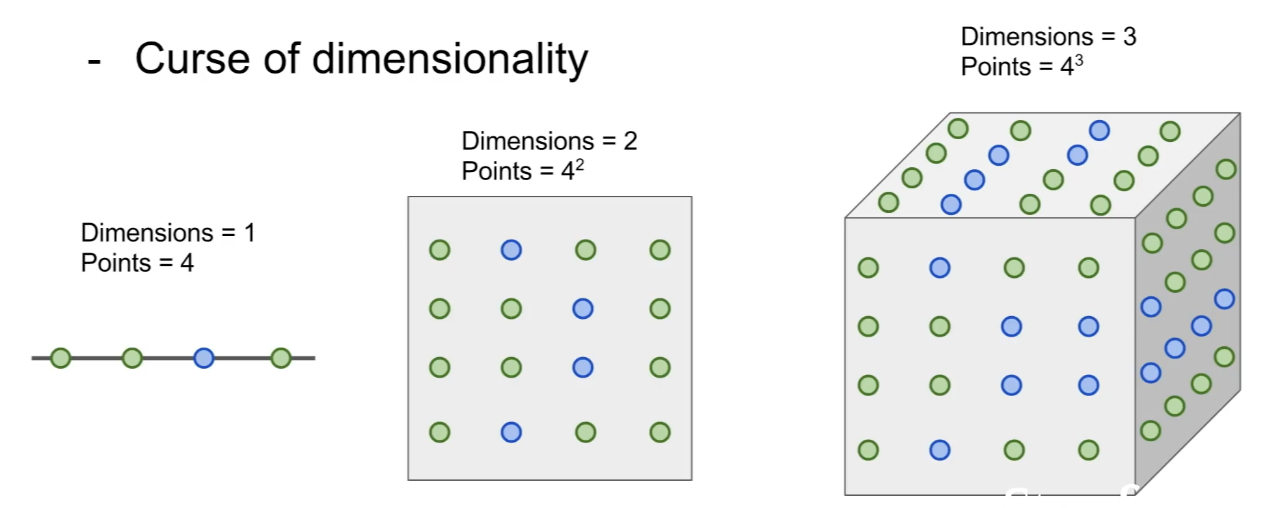
- 차원이 높아질수록 데이터간 거리가 멀어지기에 공간을 채우려면 필요한 데이터가 지수적으로 많이 증가하게 된다.
- test 과정에서 매우 느리고, distance metrics가 잘 적용되지 않기 때문이다.
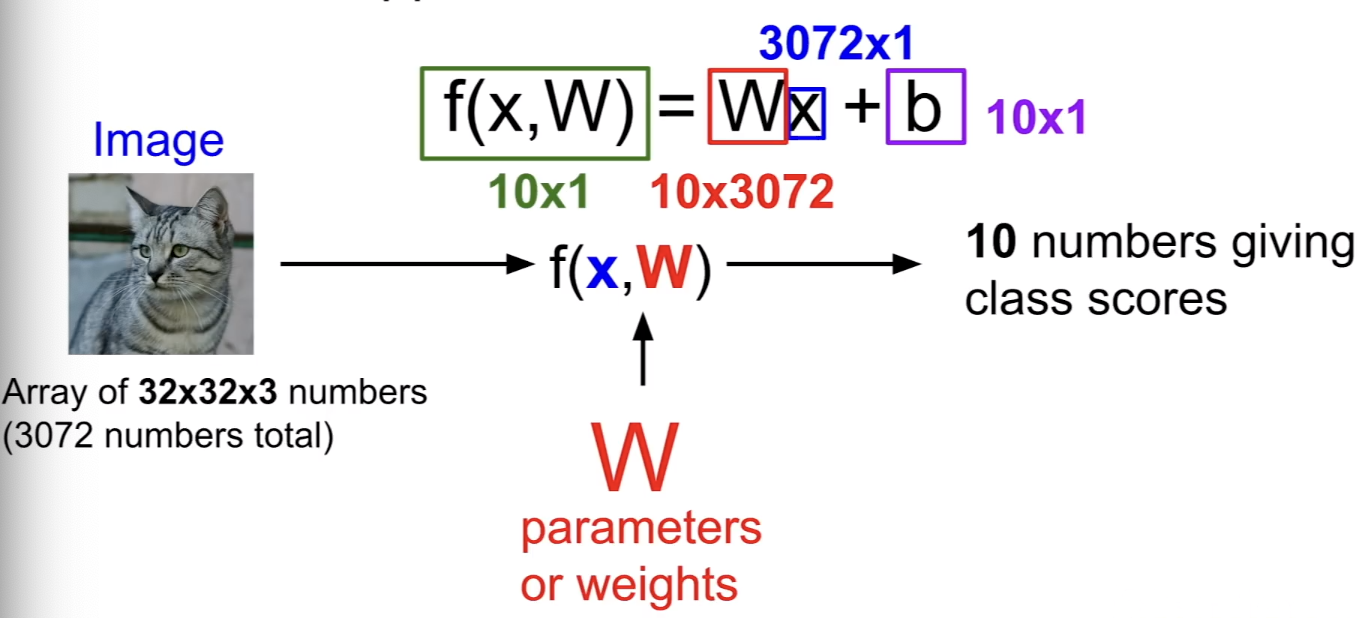
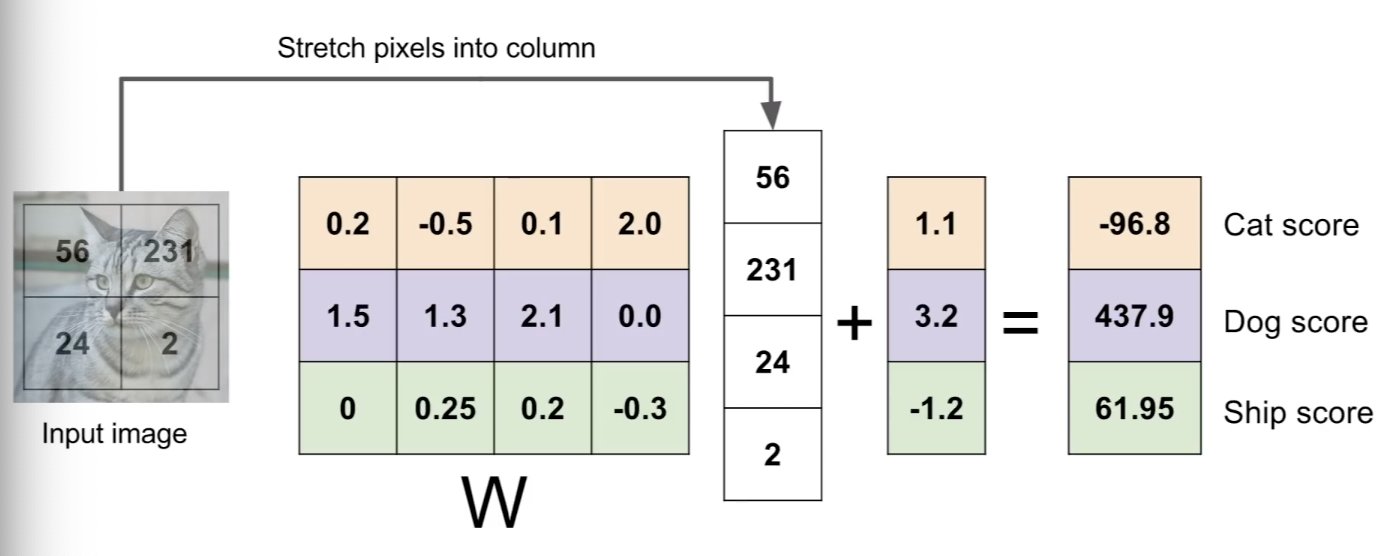
Linear Classifier
-
Parametric Approach