cs231n 강의 중 'Lecture 3 | Loss Functions and Optimization'을 정리한 내용이다.
가중치 W 찾기
-
Loss function

- Image classification에 적절한 loss function: Multiclass SVM loss


- x축인 syi가 맞은 class에 대한 점수이고 y축이 loss인데, 맞은 카테고리의 점수가 증가할수록 loss가 0이 되어가며 감소한다.
- Image classification에 적절한 loss function: Multiclass SVM loss
Regularization
- 모델이 복잡한 W가 아닌 간단한 W를 선택하게 해주어 오버피팅을 방지한다.
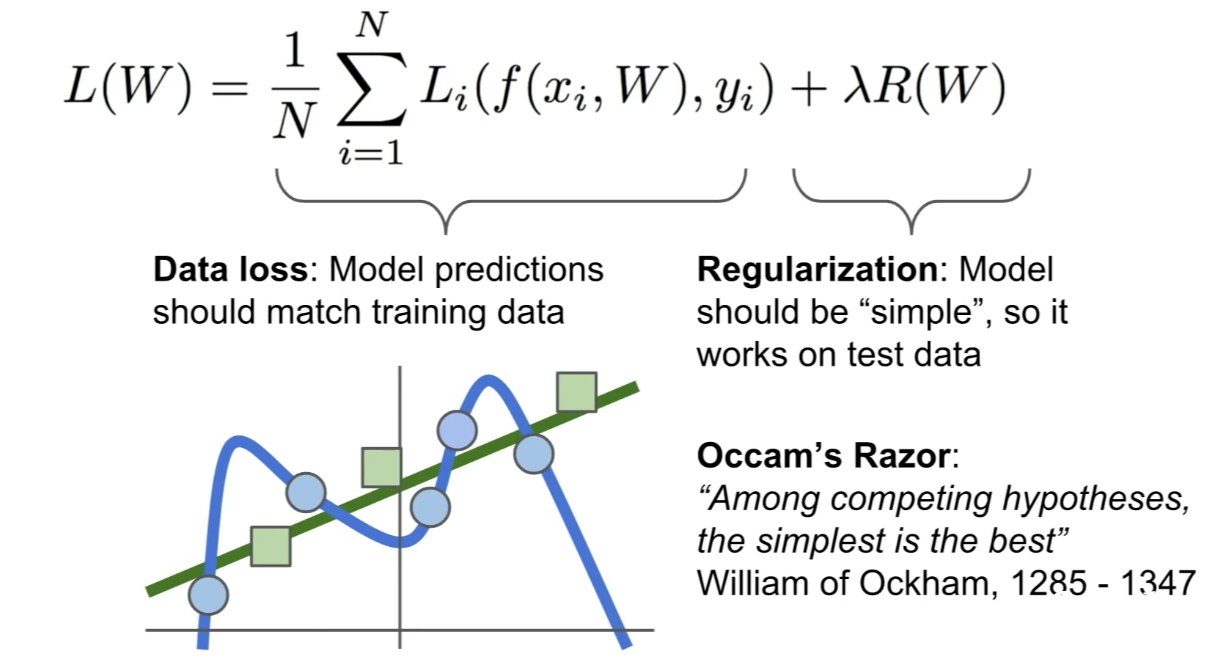
- 다양한 Regularization

Softmax vs SVM
- SVM은 맞은 class와 틀린 class의 점수를 다루는 반면 Softmax는 확률적 분포와 -log를 확인한다.
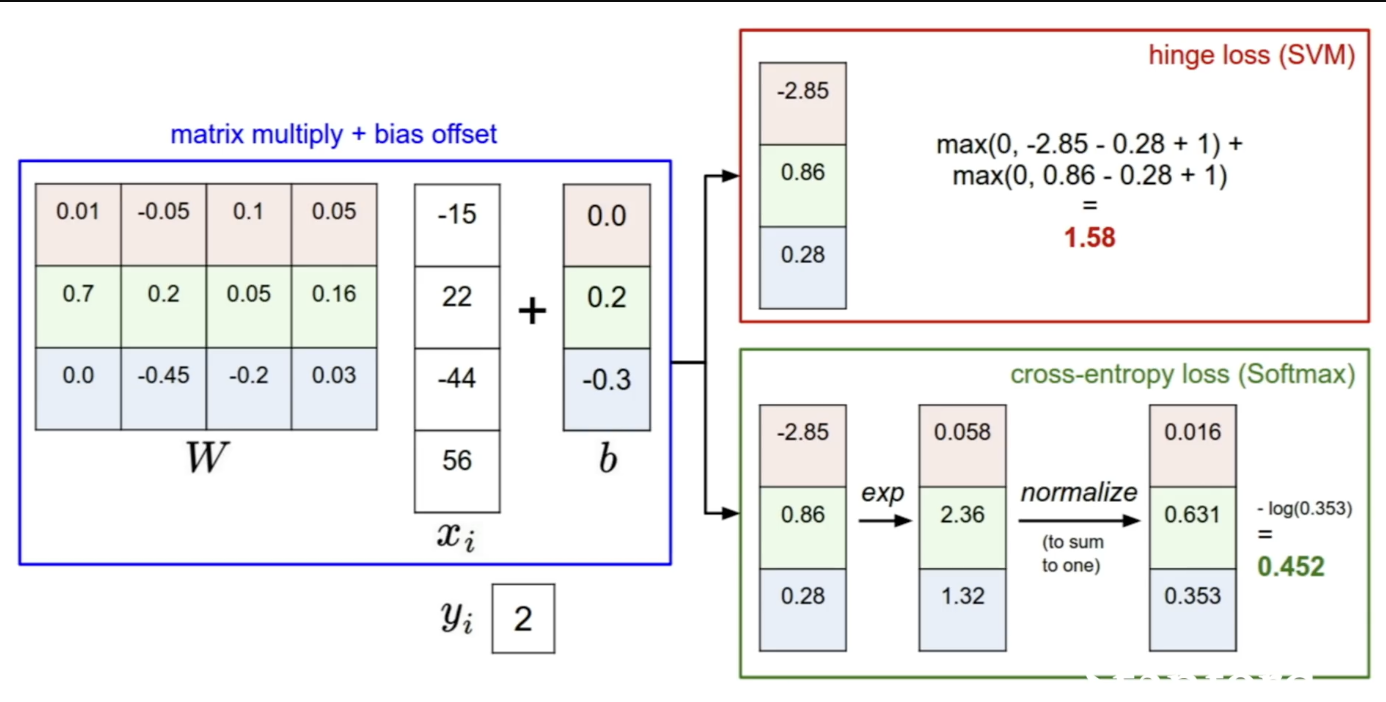
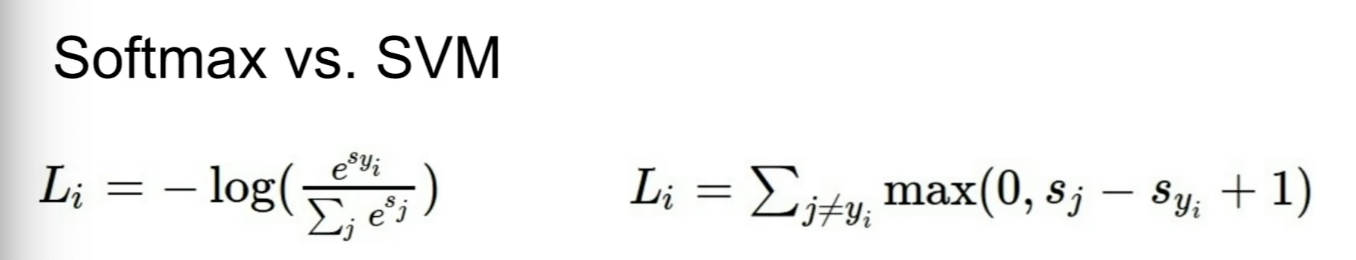
- SVM은 맞는 class의 점수가 높은것에 집중하고, Softmax는 확률의 합을 1로 가깝게 하며 정답 점수를 최대한 높게하고 틀린 점수를 최대한 낮게 한다.
Optimization
-
Random Search는 정확도가 떨어져 좋지 않음 방법
-
slope를 따라 내려가는 것처럼 step을 조절하며 찾는 방법도 있다.
-
모든 방향에서의 slope는 gradient와 방향을 표시하는 unit vector의 dot product로 표현할 수 있다.
-
gradient는 이처럼 현위치에 대해 linear한 function을 가능하게 해주므로 gradient를 이용해 parameter vector를 계속 update할 수 있어 딥러닝에 있어 매우 중요하다.
-
Numerial gradient는 매우 느리므로 Analytic grdient를 사용하는 것이 빠르고 좋다. Analytic gradient를 사용한 후 numerical gradient로 계산을 다시 확인해보는 것을 gradient check이라고 한다.
Gradient Descent
-
W를 랜덤하게 초기화하고, loss와 gradient를 계산한 후 gradient 방향의 반대로 weight를 업데이트 해준다. step size는 하이퍼파라미터로, learning rate라 부르며 training에 있어 매우 중요한 하이퍼파라미터이다.
-
gradient를 이용해 모든 step에서 어디로 step할지 결정하는 간단한 알고리즘이다. 다양한 update rule이 있다.
-
Stochastic Gradient Descent (SGD)

- 모든 training set에 loss와 gradient를 계산하기 보단 minibatch라 부르는 sample을 나누어 gradient를 추정하는 방법이다.
