cs231n 강의 중 'Lecture 5 | Convolutional Neural Networks'을 정리한 내용이다.
History of Convolutional Neural Networks
-
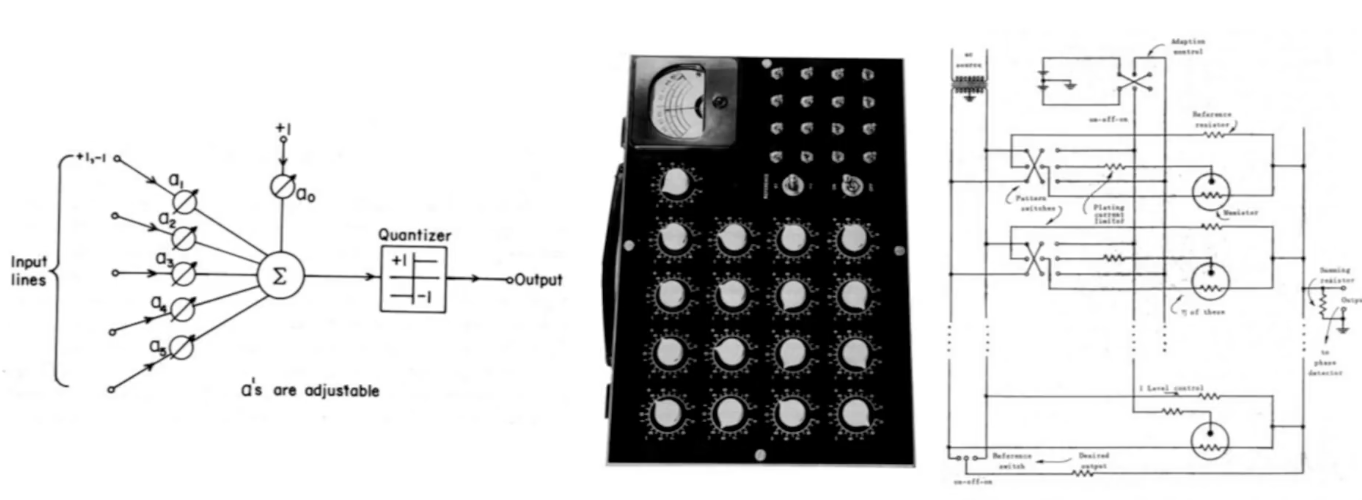
1957, Frank Rosenblatt: perceptron 알고리즘을 연구하는 첫번째 시도, Mark 1 Perceptron machine

-
1960, Widrow and Hoff: linear layer들을 multilayer perceptron network로 구성하기 시작했다.
-
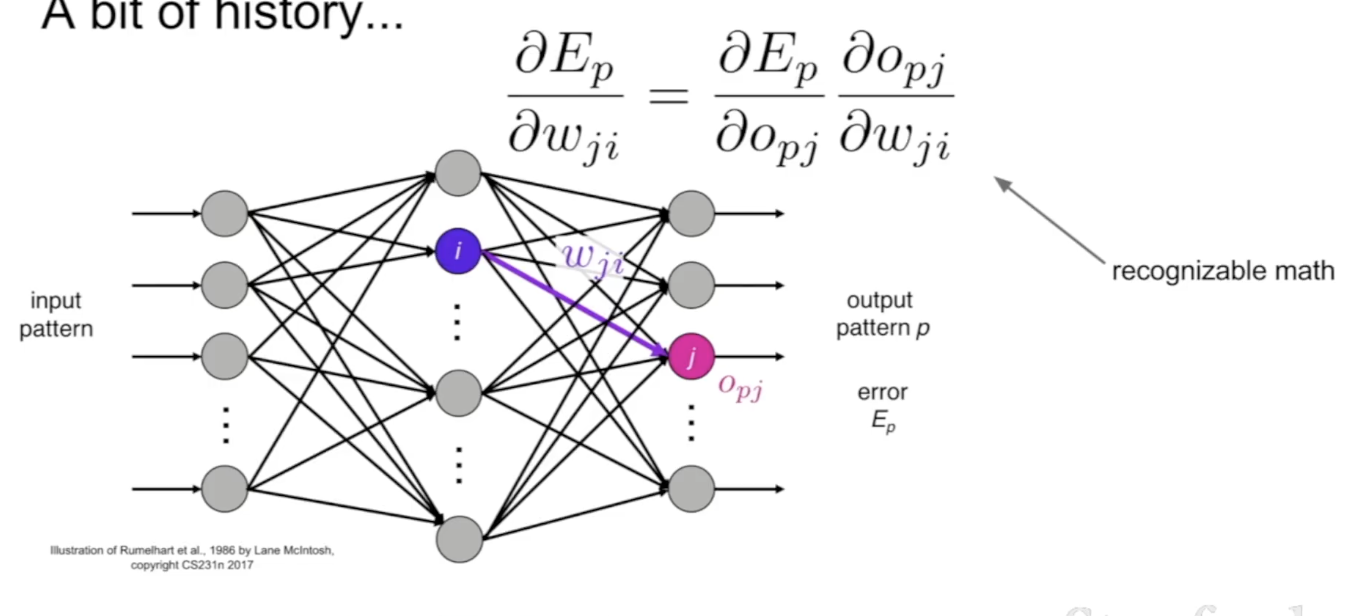
1986, Rumelhart: back propagation 개념을 도입하여 model을 train하는 network architectures가 등장하였다.
-
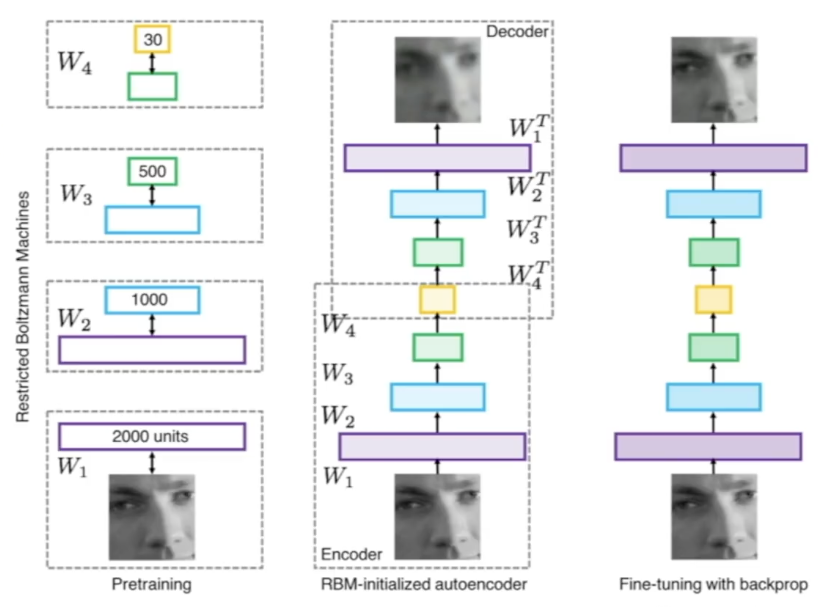
2006, Hinton and Salakhutdinov: pretraining을 진행하고 weight를 구한 뒤 hidden layer를 활용해 full neural network를 훈련하는 구조
-
2010, 2012년에 각각 음성 인식, 이미지 인식에 있어 CNN이 큰 성과를 거두었다.
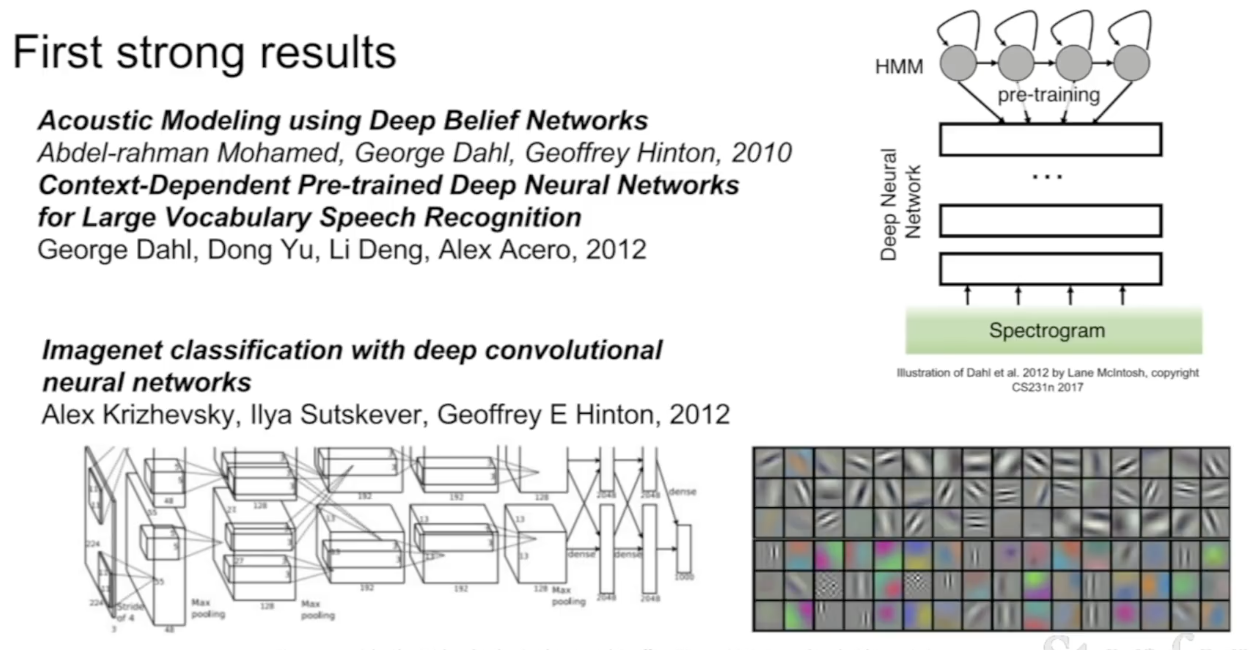
-
2012, Alexnet: CNN 모델형태로, 인터넷 상의 많은 이미지와 GPU의 병렬 computing power를 활용하게 되었다.
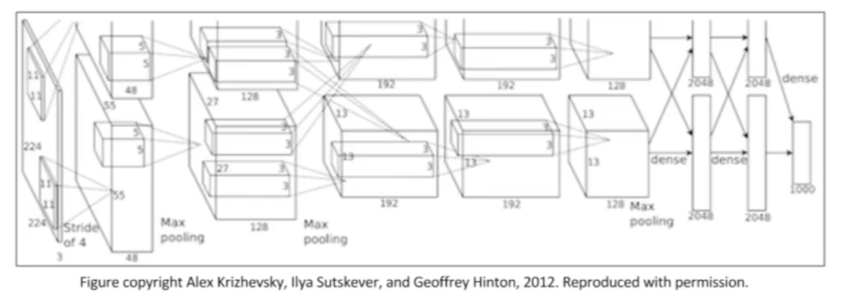
ConvNets의 활용
-
Classification, Retrieval, Detection, Segmentation, self-driving-cars, face recognition, pose recognition, Image captioning 등 여러 분야에서 유용하게 활용된다.

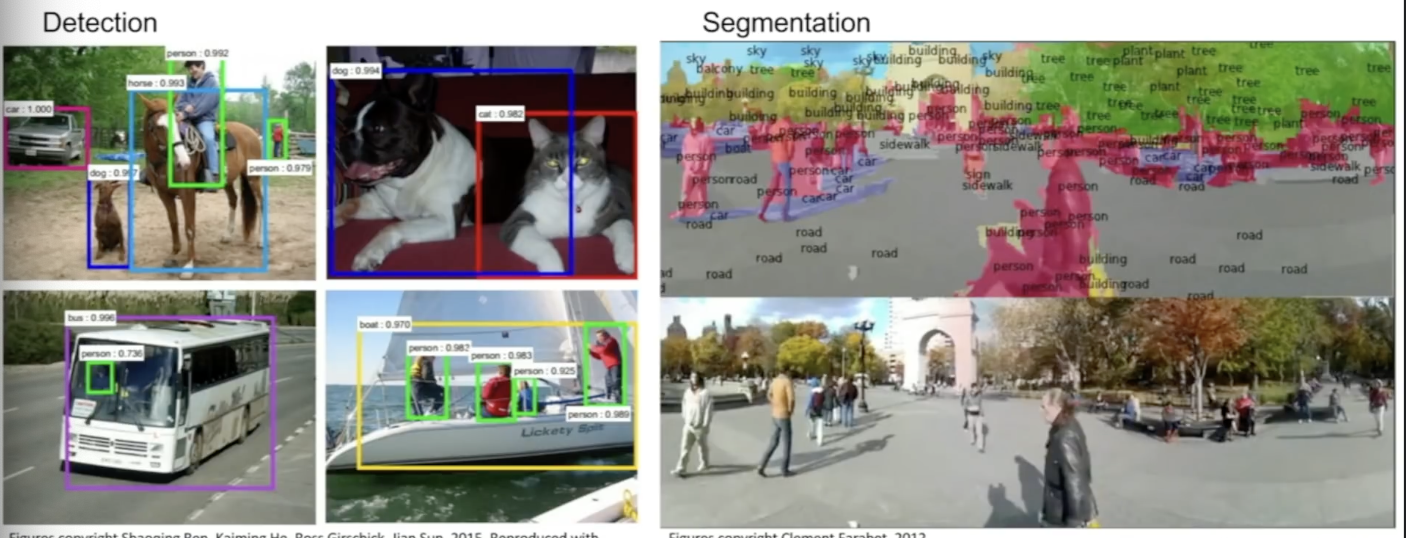

Convolutional Neural Networks
-
기존의 Fully Connected Layer은 Input image를 하나의 긴 벡터로 변환한 후 가중치를 적용해 10개의 뉴런 output을 받았다.
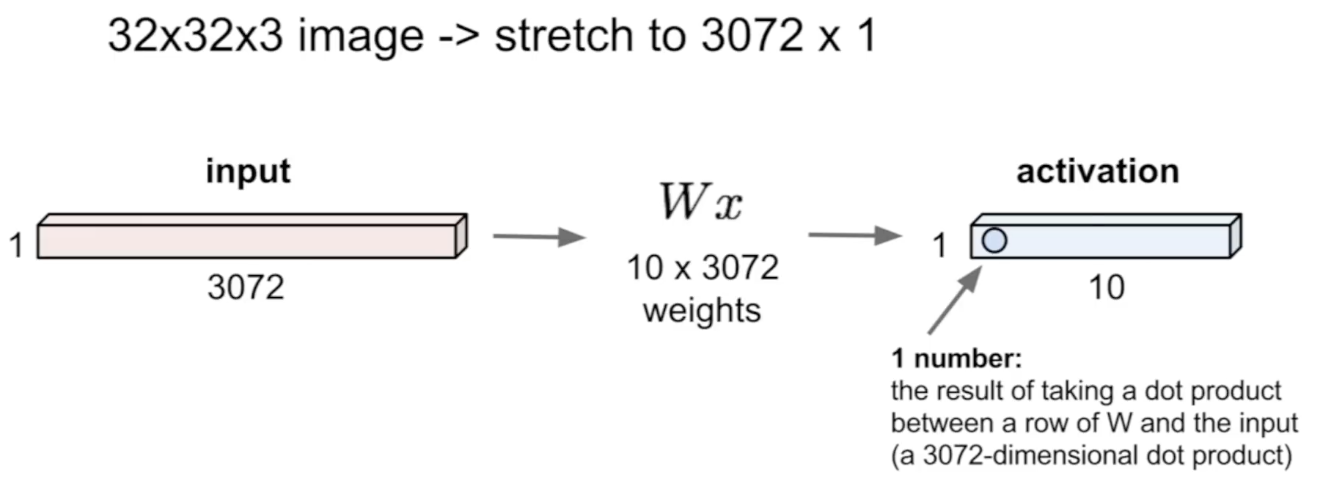
-
Conovlution Layer에서는 이미지를 하나의 긴 벡터로 변환하지 않고 3차원의 구조 그대로 사용한다. 작은 필터를 이용해 각각의 영역별로 dot product를 진행한다.

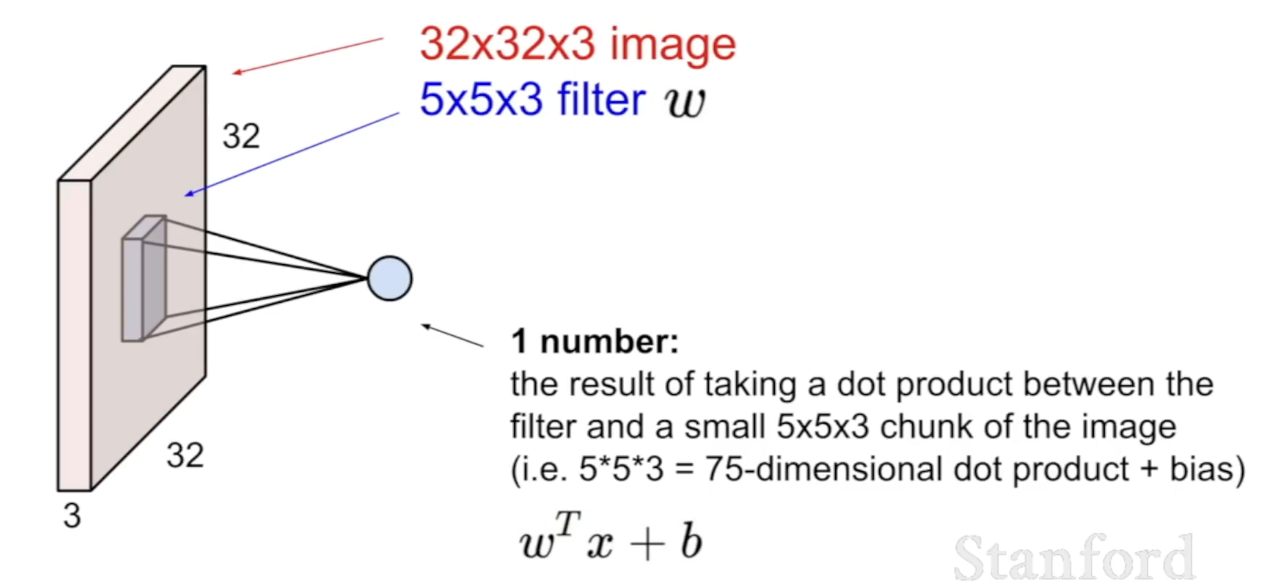
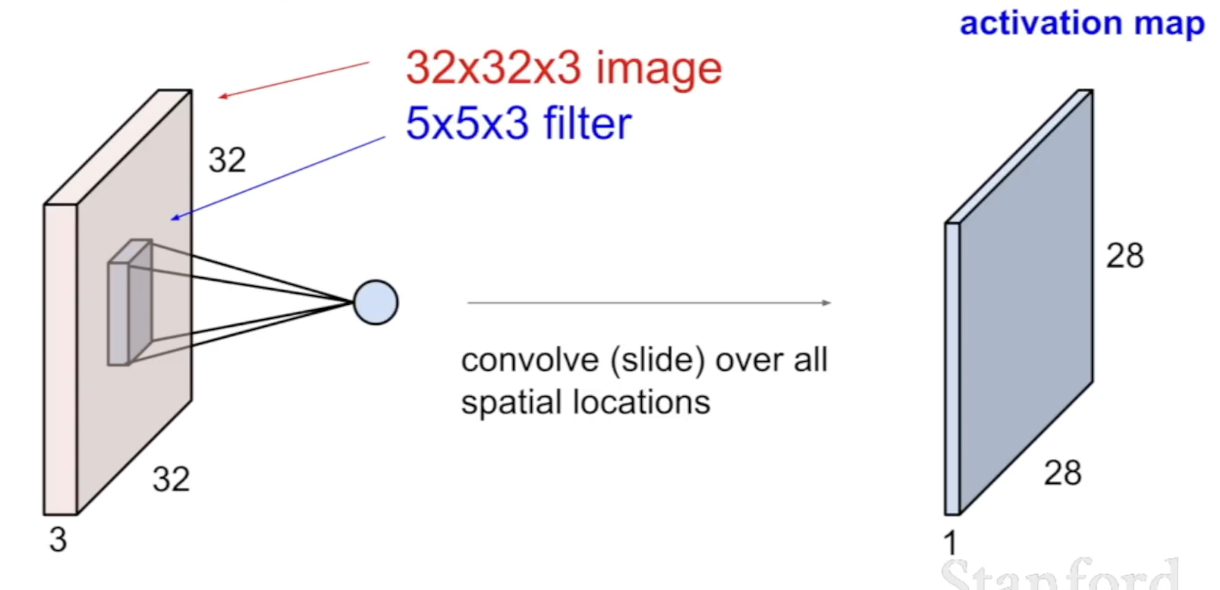
-
여러 개의 필터를 사용할 수 있고, 각각의 필터를 Input 이미지에 이용한뒤 activation maps에 합칠 수 있다.
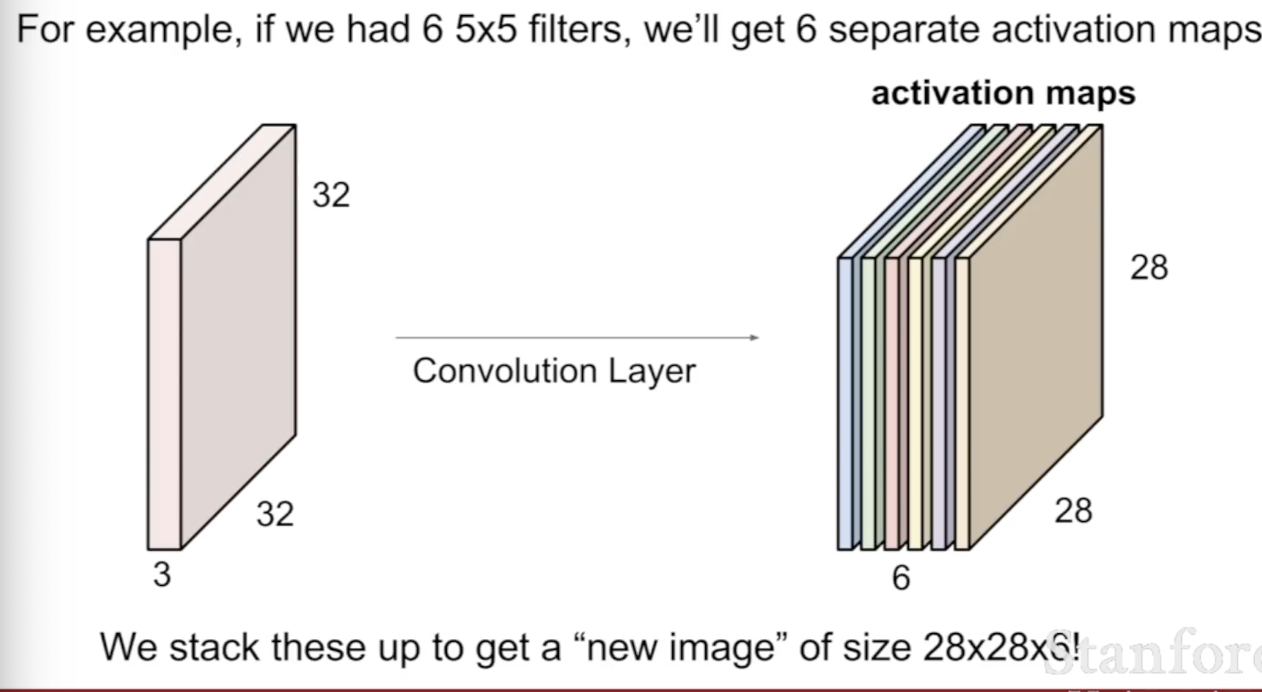
-
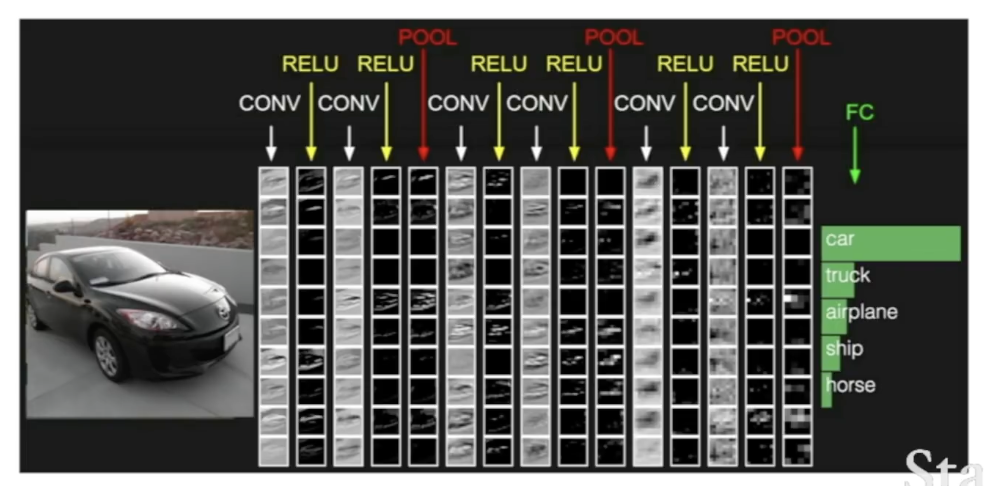
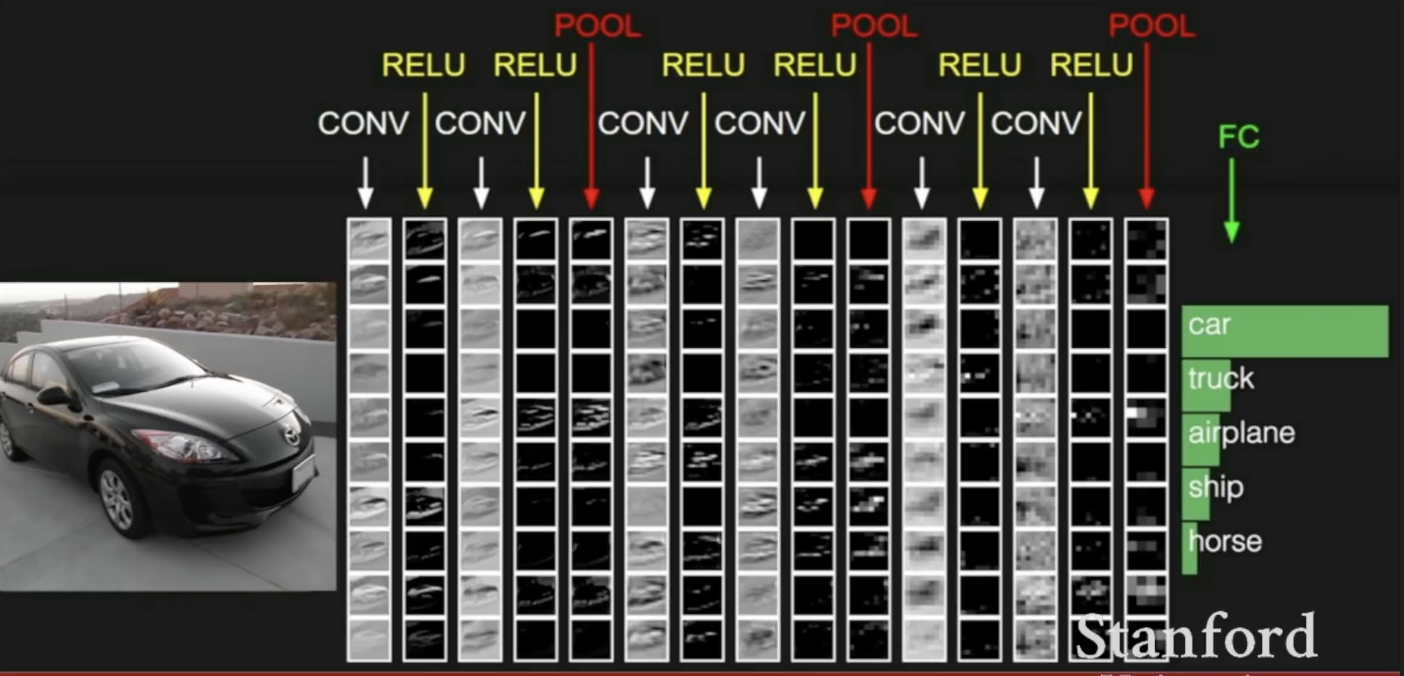
Input 이미지를 Convlutional layer, reLu와 같은 non-linear layer, activation map의 크기를 줄여주는 pool layer에 적용하고, 마지막엔 마지막 convolutional layer outuput을 fully connected layer에 넣어 최종 결과를 얻는다.
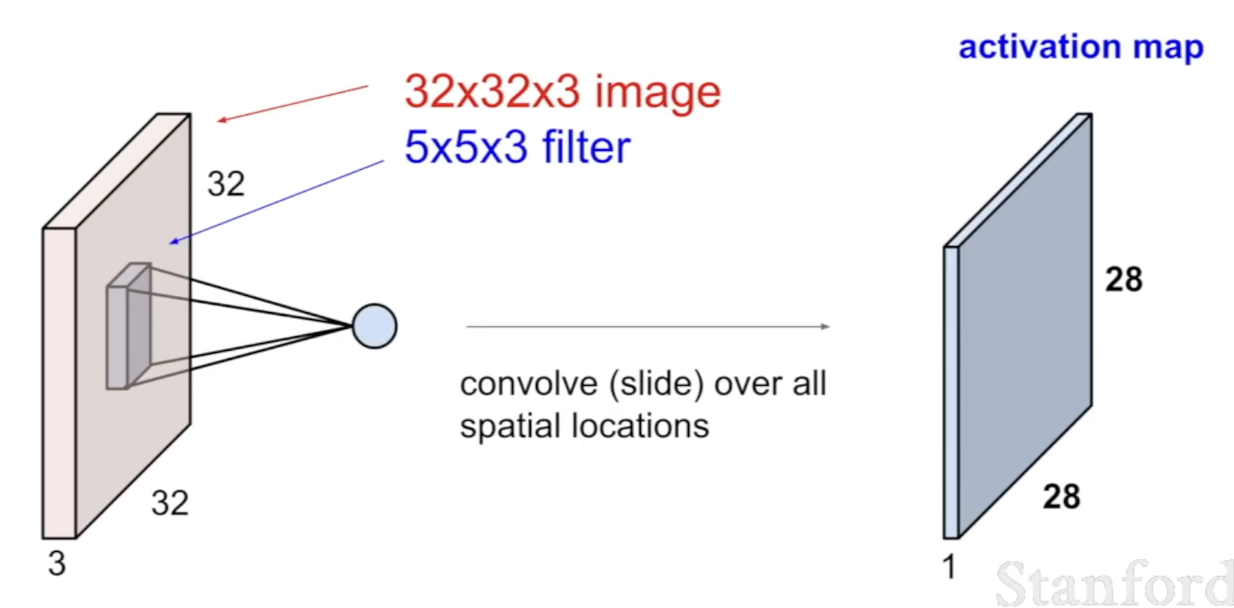
Spatial Dimensions 동작원리
-
32 x 32 x 3 사이즈의 Input 이미지와 5 x 5 x 3 필터가 있을 때 28 x 28 x 1의 activation map이 나오는 과정을 알아본다.
-
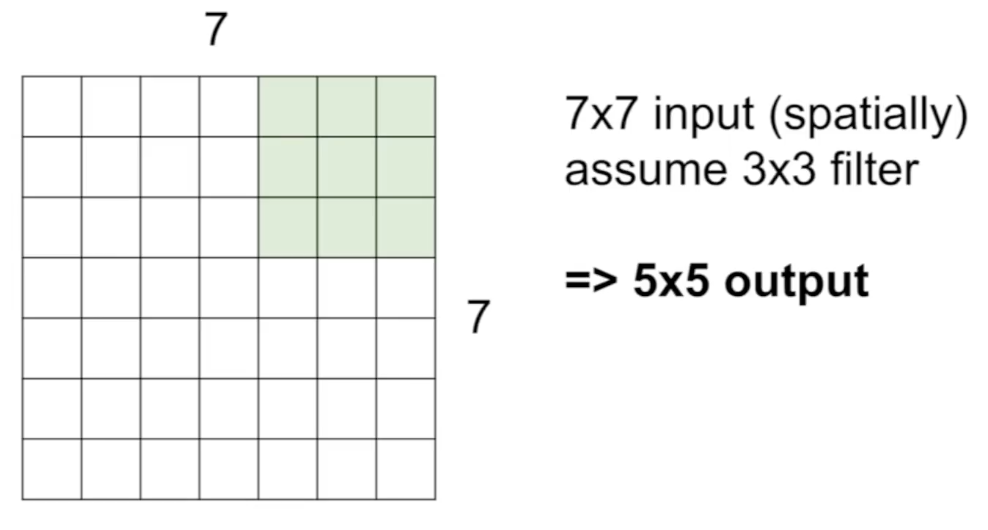
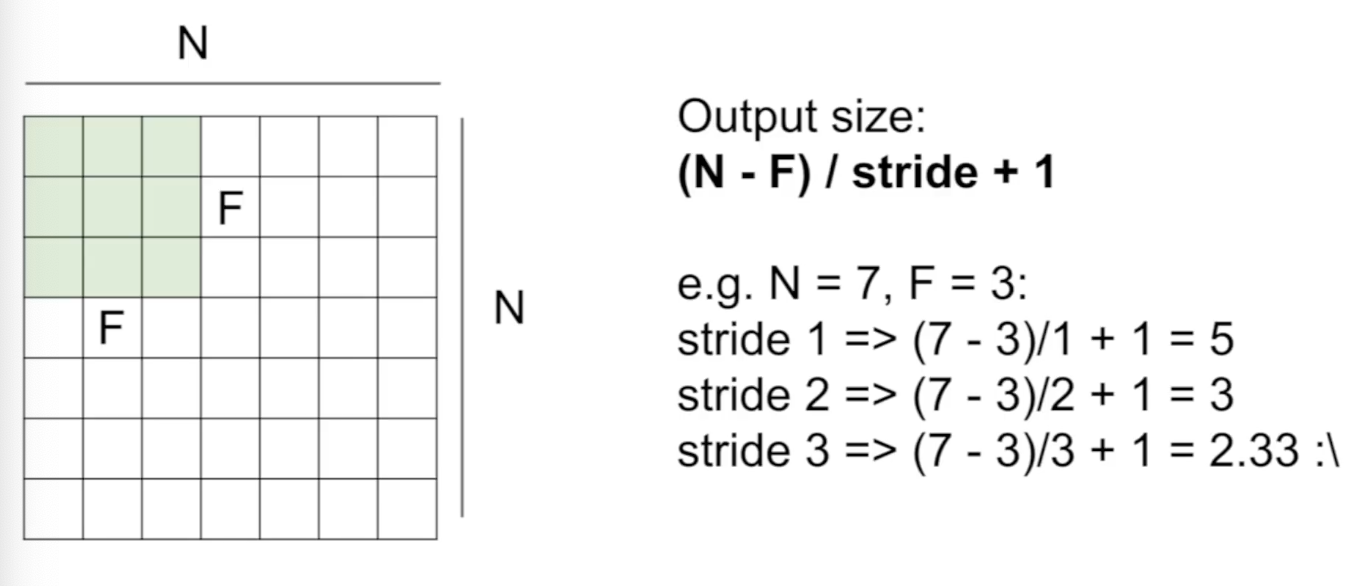
예를 들어 7 x 7 input과 3 x 3 필터가 있을 때 필터의 위치를 slide하며 output을 계속 받아 5 x 5 output이 만들어진다.
-
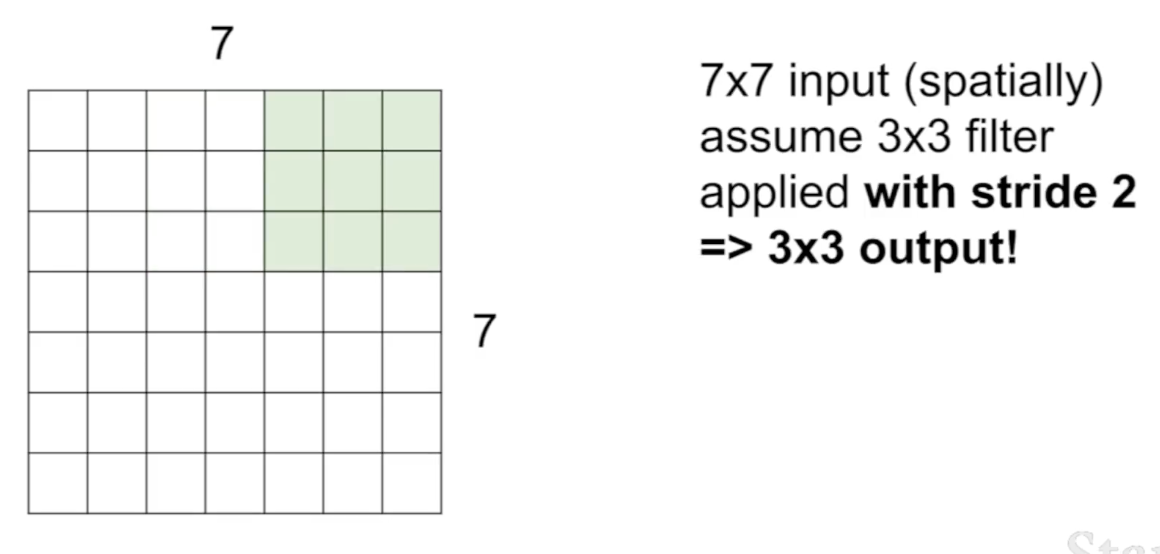
stride가 2라면 두 칸씩 건너뛰어 3 x 3 output이 만들어진다.
-
stride가 3라면 7 x 7 이미지에 맞지 않으므로 적용되지 않는다.
-
Output size를 구하는 공식: (N - F) / strid + 1
-
Padding을 통해 모서리의 데이터를 필터 가운데에 넣어줄 수 있다. zero padding을 자주 사용한다. Input size와 같은 Output size를 유지할 수 있다.

-
Padding이 있을 때 Ouput size를 구하는 방법

- Parameter의 개수 구하는 방법 - 5 x 5 x 의 weights에 bias 1을 더한 filter가 10개이므로 760으로 계산한다.

- Parameter의 개수 구하는 방법 - 5 x 5 x 의 weights에 bias 1을 더한 filter가 10개이므로 760으로 계산한다.
-
Summary

-
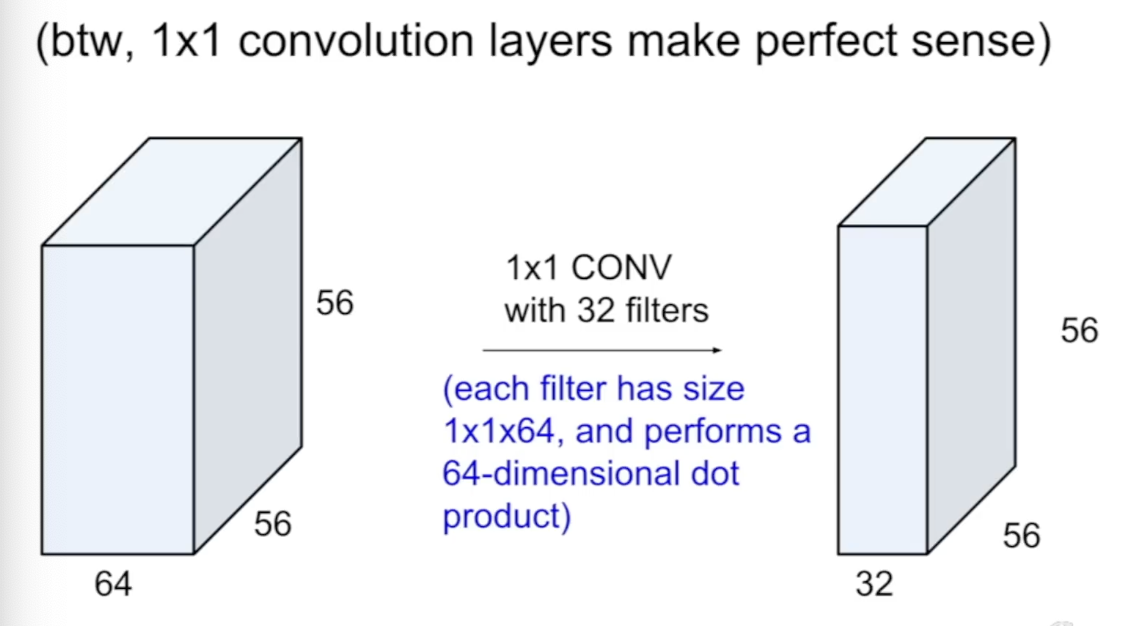
1 x 1 Convolution도 가능하고, 56 x 56 x 64의 Input image에 대해 32개의 1 x 1 x 64 사이즈의 필터를 적용해 dot product를 진행하면 56 x 56 x 32의 output이 나온다.
-
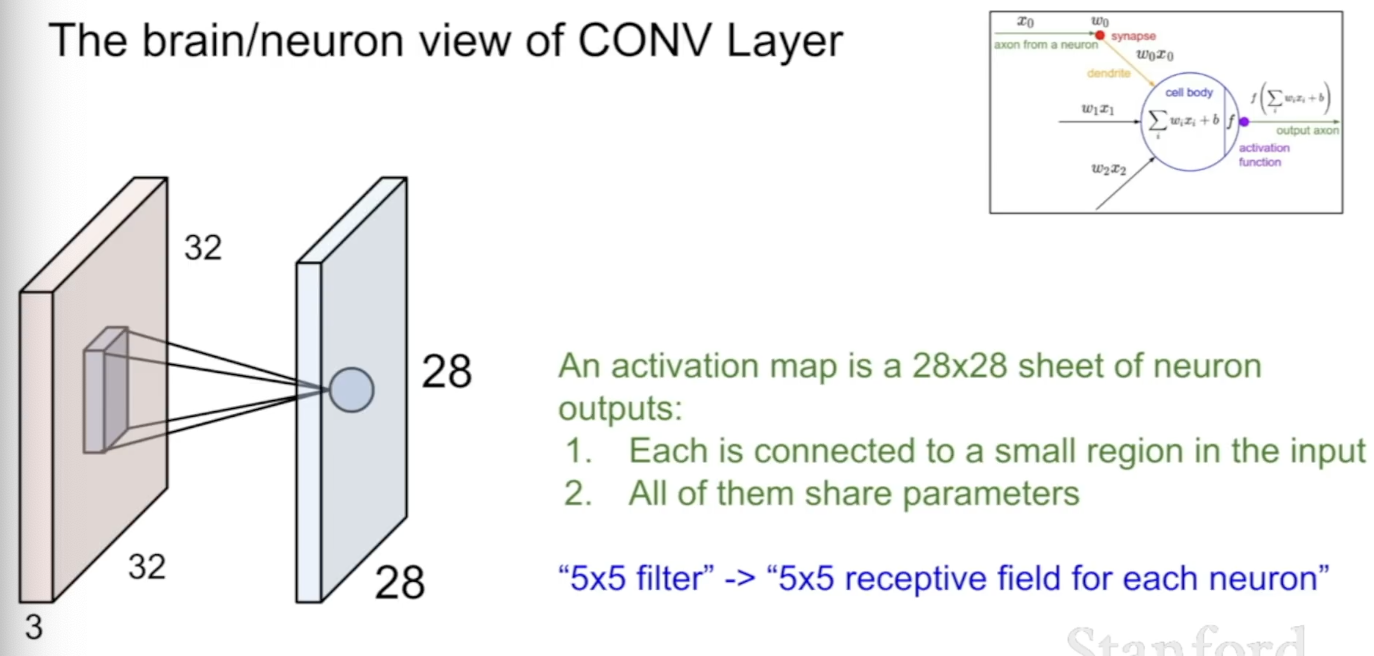
Activation map은 neuron output들의 집합으로, 각각은 Input image의 특정 구역과 연결되어 있고, 같은 필터를 사용하기 때문에 모두 같은 가중치, parameter를 공유한다. filter는 receptive field for each neuron이라 표현할 수 있다.
Pooling Layer, Fully Connected Layer
-
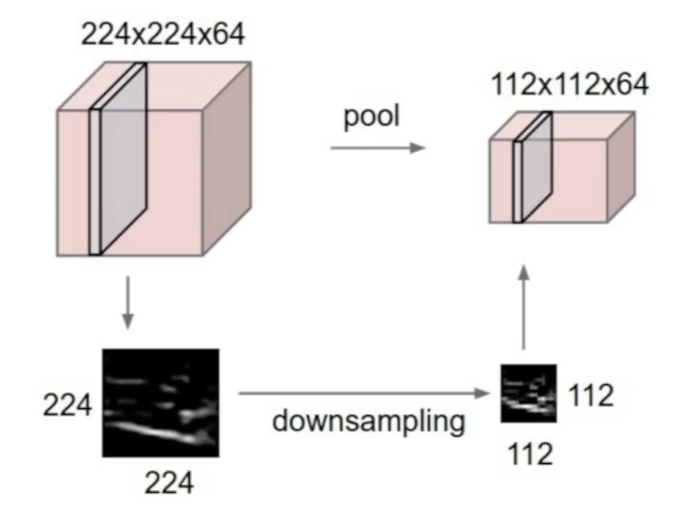
사이즈를 줄여 작고 관리하기 쉽게 해준다. Input volume을 줄여주는데, depth에는 영향을 주지 않는다. 각각의 activation map에 독립적으로 시행된다.
-
Max Pooling: 자주 사용되는 pooling 방법으로, 특정 구역에서 최댓값만을 선택한다. 이미지에서 강한 특색을 가진 부분을 이용하기에 직관적이다.
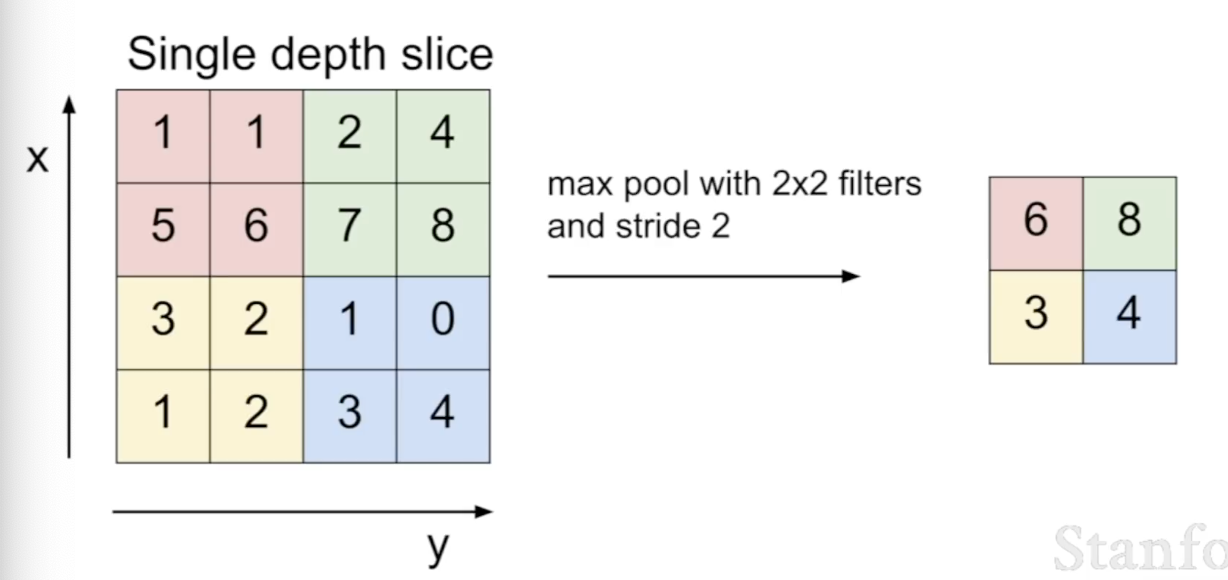
-
Fully Connected Layer (FC layer): width x height x depth로 구성된 Convolutional Network Output을 score output으로 바꾸어준다. 모든 정보를 합쳐 class의 score를 뽑아낸다.