ARCUS 데이터 분산 저장 정책
서비스 운영중에 부하가 집중되어 성능에 문제가 발생할 때 이를 해결하기 위한 방법으로 스케일 업(scale up)과 스케일 아웃(scale out)이 있습니다. 스케일 업은 단순히 서버의 하드웨어를 더 좋은 것으로 교체하는 것으로, 가장 간단한 해결방법이지만 서비스를 재구동 해야하며 성능 증가에 한계가 있습니다. 반면 스케일 아웃의 경우 컴퓨팅 파워를 병렬로 증설하는 것으로 스케일 업과 비교하여 지속적 확장이 가능하다는 장점이 있지만 추가적으로 분산 아키텍쳐 및 정책을 수립해야하기 때문에 복잡성이 증가합니다. ARCUS는 클러스터 기능을 통해 스케일 아웃을 지원하며 이를 통해 서비스의 요청을 분산 저장하고 부하를 분산합니다. 이 글에서는 데이터를 분산 저장할 때 선택할 수 있는 아키텍쳐와 정책들을 소개하고 ARCUS는 어떻게 데이터를 분산하여 저장하는지 소개합니다.
데이터 분산 아키텍쳐
일반적으로 데이터를 분산 저장할 때 고려할 수 있는 분산 구조는 노드 간에 데이터를 공유하는지 여부에 따라 shared everything과 shared nothing 구조로 나뉩니다.
Shared everything
- 클러스터를 구성하는 노드들이 모든 데이터를 공유하는 구조입니다.
- 클러스터의 어느 노드가 고장나더라도 다른 노드들이 동일한 데이터에 접근할 수 있으므로 노드 장애에도 데이터를 손실하지 않습니다.
- Lock 경합에 따른 성능저하가 있으며 구현 복잡성이 큽니다.
Shared nothing
- 클러스터의 노드들이 데이터를 나누어서 저장하는 구조입니다.
- 각 노드들은 정해진 분산 정책에 따라 데이터의 일부를 책임지고 저장합니다. 데이터들을 공유하지 않기 때문에 lock이 필요하지 않고 이로 인한 성능저하도 없습니다.
- 노드에 장애가 발생할 경우 해당 노드가 담당하고 있는 데이터들이 손실될 수 있습니다.
- 각 노드들에 어떻게 데이터를 분배하여 저장할 지 추가적인 분산 정책을 수립할 필요가 있습니다.
ARCUS는 소개한 분산 아키텍쳐 중 shared nothing 분산 구조를 사용합니다. 성능이 중요한 캐시 솔루션의 특성과 잘 맞으며 구현이 간단하기 때문입니다. Shared nothing 구조의 특성 상 캐시 노드 장애가 발생할 경우 일부 데이터를 손실할 수 있지만, 클러스터를 이루는 다른 캐시 노드들로 서비스는 지속될 것이며 잃어버린 데이터들로 인해 잠시동안 캐시 미스(cache miss)가 일어나더라도 캐시 서비스의 특성상 일반적으로 원본 데이터가 데이터베이스에 저장되어있기 때문에 바로 복구가 가능합니다.
Shared nothing 구조에서의 데이터 분산 정책
Shared nothing 구조를 채택하였을 때 고민해야할 것은 데이터들을 어떠한 방식으로 분산하여 저장할 것인가에 대한 부분입니다. 이러한 데이터 분산 정책을 정할 때 고려해야할 사항들은 아래와 같습니다.
- 노드 추가 혹은 제거로 클러스터 노드 목록이 변하였을 때 얼마나 많은 데이터들을 재배치 해야하는가
- 데이터들이 노드들에 균일하게 분산되는가
여기서는 키-밸류 스토어에서 주로 사용하는 세 가지 데이터 분산 정책들에 대해 소개합니다.
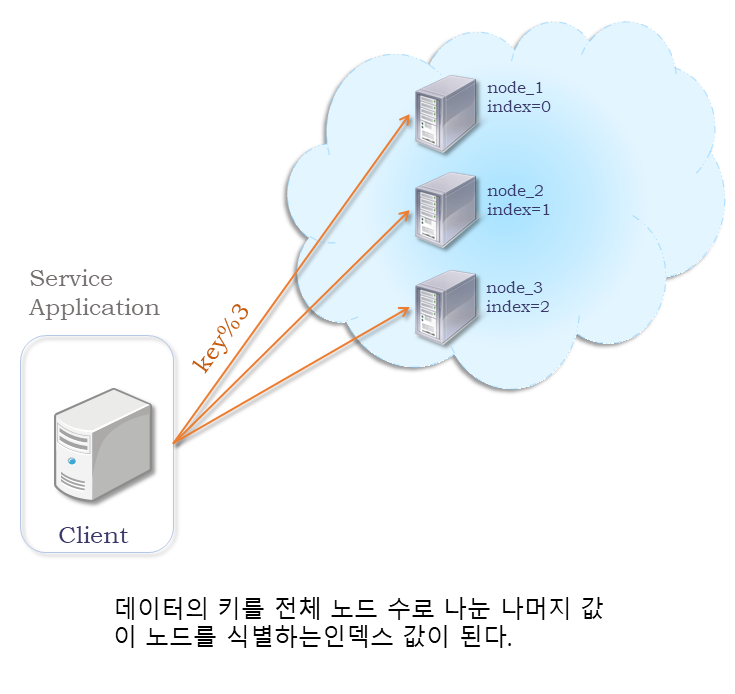
Modulo를 사용한 분산 정책
데이터를 분산 저장할 때 가장 쉽게 생각할 수 있는 데이터 분산 정책으로, 나머지 연산(modulo)을 사용하여 데이터를 분산하는 분산 정책입니다. 이 정책에서는 데이터의 키를 전체 노드 수를 나누어 나오는 나머지 값을 인덱스로 사용해 저장할 노드를 선택합니다. 가장 단순하며 이해하기 쉬운 형태이지만, 클러스터를 구성하는 노드가 추가되거나 제거되어 전체 노드 수가 바뀌면 저장되어있는 모든 데이터를 재배치해야하는 문제가 있습니다.
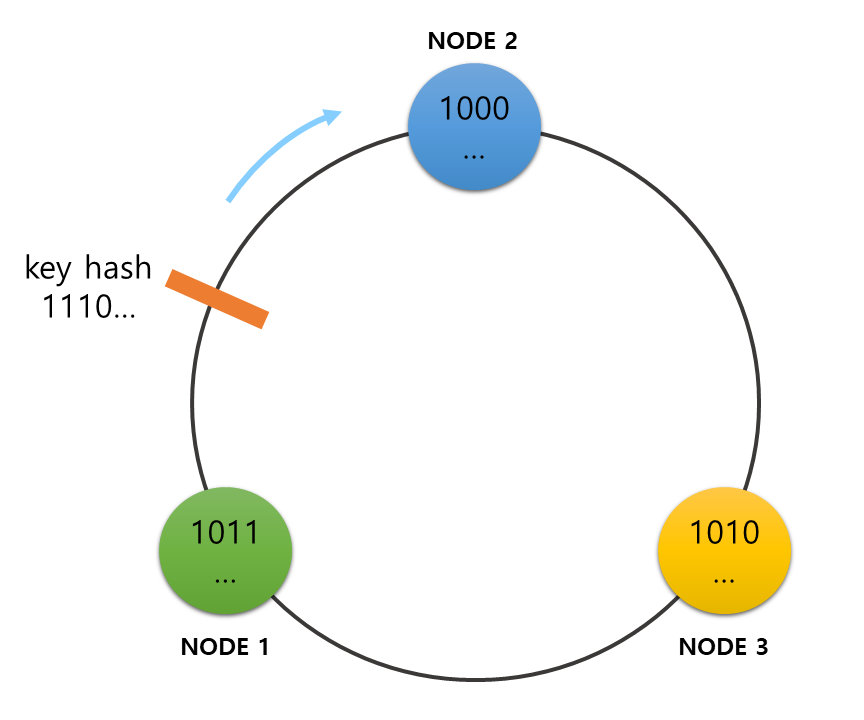
Consistent hashing
Modulo 방식이 나머지 연산을 통해 키에서 노드 인덱스를 알아냈다면 consistent hashing 방식에서는 해시 함수를 사용하여 데이터의 키에서 해시 값을 구하고 이를 통해 데이터를 저장할 노드를 선택합니다. 해시 값을 위치시키는 가상의 원이 있다고 가정합니다. 일반적으로 이 원을 해시 링(hash ring)이라고 부릅니다. 우선 해시 링에 노드들의 노드 이름을 해싱하여 얻어낸 해시 값들을 위치시킵니다. 해시 링에 모든 노드들이 위치를 확정하면 저장하려는 데이터의 키를 해싱하여 마찬가지로 해시 링에서 해당 해시 값의 위치를 찾아냅니다. 이 때 데이터의 해시 값 위치에서 시계 방향으로 가장 가까운 곳에 위치한 노드가 바로 이 데이터를 저장할 노드가 됩니다.
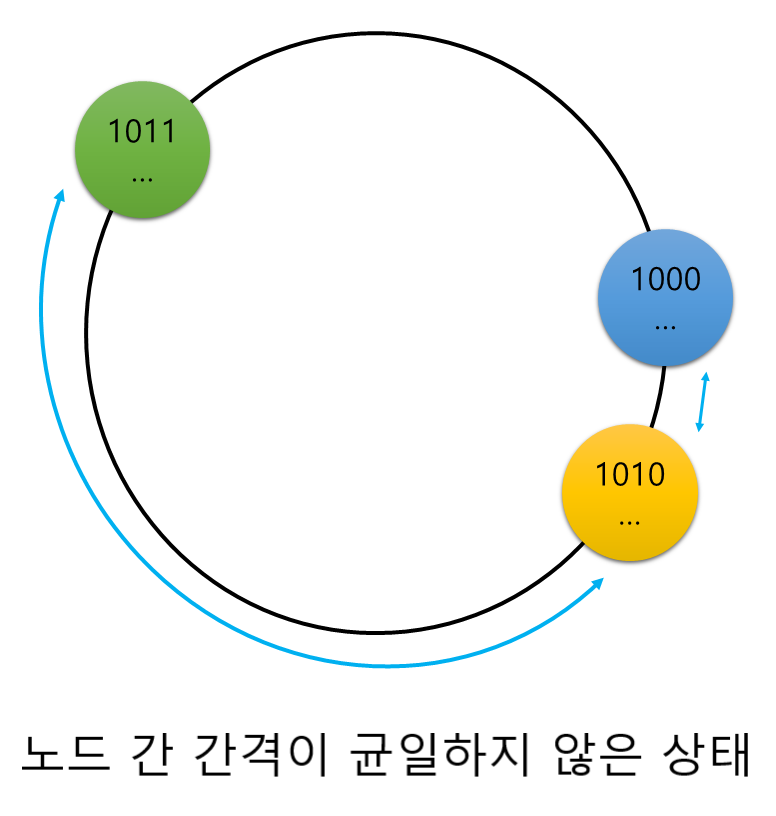
이와 같이 해싱 방법으로 데이터를 분산할 시 클러스터에 노드가 추가되거나 삭제되어 전체 노드 수가 변경되더라도 ‘1 / 전체 노드 수’ 만큼의 데이터만 재배치되므로 modulo에 비해 재배치가 매우 적게 발생하게 됩니다. 하지만 클러스터의 노드들이 해시 링에서 담당하는 영역의 크기가 서로 다를 수 있기 때문에 노드들에 데이터가 고르게 분산되지 않을 수 있습니다.
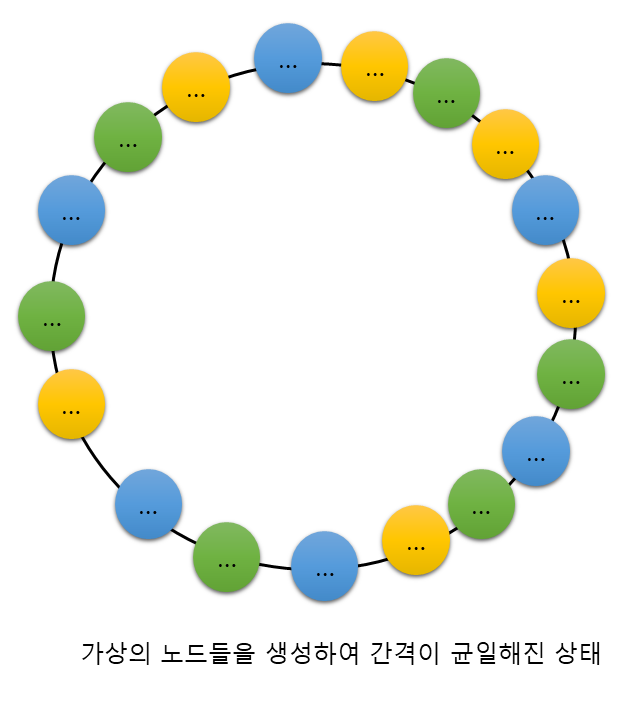
Ketama consistent hashing
Consistent hashing의 단점을 보완하기 위해 나온 분산 정책입니다. Consistent hashing과 마찬가지로 해시 값을 통해 해시 링을 구성하여 데이터를 분배하지만, consistent hashing이 노드 하나 당 하나의 해시 값을 가지는 것과 달리 노드 하나가 N개의 해시 값을 가진다는 특징을 지닙니다. 노드들이 각각 큰 수의 N 만큼 가상 노드를 생성하여 해시 값을 가지게 될 경우 해시 링은 노드들의 해시 값으로 가득 차게 됩니다. 이렇게 될 경우 해시 링에서 노드들이 차지하는 영역들이 어느 정도 균일해지기 때문에 전체 노드 수가 변경되더라도 재배치가가 적게 일어나고 데이터를 고르게 분산할 수 있는 분산 알고리즘을 완성할 수 있게 됩니다.
ARCUS 데이터 분산 정책
ARCUS는 위에서 소개한 분산 정책 중 ketama consistent hashing 정책을 사용합니다. ARCUS가 해시 링을 구성하는 알고리즘을 자세히 살펴보겠습니다. ARCUS 서버와 클라이언트 라이브러리는 ZooKeeper로부터 클러스터의 노드 구성을 인지하게 되면 해시 링을 생성하게 됩니다. 캐시 노드들의 경우 캐시 노드의 이름(IP:Port 문자열을 노드 이름으로 사용) 뒤에 숫자를 붙여 40개(기본설정)의 가상 노드를 생성하고, 이를 해싱하여 나온 128bit 값에서 4개의 해시 값을 얻습니다. 해시 알고리즘은 성능면에서 좋은 결과를 보이는 md5를 사용합니다. 이렇게 해시 값을 생성할 경우 ‘가상 노드 수 40 X 노드 당 4개의 해시 값 = 총 160개 해시 값’을 생성하며 해당 값들로 해시 링에 참여합니다.
ip:port + repetition = 10.0.0.1:11211-1
HashAlgorithm.md5(10.0.0.1:11211-1)
위 작업을 한 결과값 128bit를 네 등분합니다. (각 32비트)
11110000101000000101000000000000
10101010101010101010101010100101
10101010101010101010101010100101
10101010101010101010101010100101
네 등 분 된 것을 다시 네 부분으로 나눠서 reverse한 다음 사용합니다.
<11110000> 101000000 <10100000> 0000000
00000000 <01010000> 10100000 <11110000>
이런 방법으로 노드 이름 별로 4개의 해시 값(32bit)을 얻습니다.
repetition 값이 40개 있다고 가정하면 하나의 노드에 대해 총 160개의 해시 값을 얻을 수 있습니다.실제 ARCUS 자바 클라이언트에서 사용하는 코드를 확인하면 다음과 같습니다.
for (int i = 0; i < config.getNodeRepetitions() / 4; i++) {
byte[] digest = HashAlgorithm.computeMd5(getSocketAddressForNode(node) + "-" + i);
for (int h = 0; h < 4; h++) {
Long k = ((long) (digest[3 + h * 4] & 0xFF) << 24)
| ((long) (digest[2 + h * 4] & 0xFF) << 16)
| ((long) (digest[1 + h * 4] & 0xFF) << 8)
| (digest[h * 4] & 0xFF);
ketamaNodes.put(k, node);
}
}해시 링에 노드들의 해시 값들을 위치 시킨 이후에는 이미 ketama consistent hashing을 설명할 때 언급했던 대로 어떤 데이터를 저장해야할 때 해당 데이터의 키를 해싱한 결과로 해시 링에서 이 키를 담당하는 노드를 찾아 해당 데이터를 저장하게 됩니다. 한 가지 주의해야할 부분은 클러스터의 노드 수가 많아질 경우 수없이 많은 해시 값이 생성될 수 있고 이로 인해 해시 충돌이 발생할 수 있는데, ARCUS는 이러한 문제가 발생할 경우 문자열을 사전순으로 정렬하여 더 앞선 캐시 노드가 해당 해시 포인트를 차지하도록 합니다. 또한 이미 언급했던 대로 ketama consistent hashing를 사용할 경우 서버 목록 변경이 발생하면, ‘변경 노드 수 / 전체 노드 수’ 만큼의 캐시 데이터는 재배치가 발생하고 이로 인해 stale 데이터가 발생할 수 있습니다. ARCUS에는 이러한 stale 데이터를 삭제하는 scrub stale 기능이 존재하며 이에 대한 자세한 내용은 잼투인 블로그의 ‘캐시 시스템에 필요한 fault tolerance 의미와 이를 제공하는 방안’ 포스트를 참조해주시길 바랍니다.
마치며
지금까지 분산 저장 방법으로 사용하는 아키텍쳐 및 정책에 대해 알아보고 ARCUS에서는 어떻게 데이터를 분산 저장하고 있는지 설명드렸습니다. 현재 ARCUS는 자체적으로 캐시 데이터를 이동시키지 않으므로, 노드 목록에 변화가 발생할 경우 데이터 재배치로 인한 캐시 미스가 발생할 수 있습니다. 이러한 캐시 미스를 막기 위해서는 노드 장애에 대비한 캐시 데이터 복제 기능을 사용하거나 캐시 데이터를 이동하는 기능이 필요합니다. 이 중 복제 기능은 이미 엔터프라이즈 버전으로 개발되어 있는 상태이며 추후 캐시 데이터를 이동하는 마이그레이션(migration) 기능 또한 출시될 예정입니다