
DALL-E2와 Imagen 등 코드를 공개하지 않는 최근 diffusion models에 반해, 손쉬운 모델 개발 및 API 사용 등을 위해 Huggingface에서 구현된 오픈소스 diffusion model 라이브러리. 빠른 inference를 위해 UNet과 Scheduler로 구성된 pipeline 함수를 제공하며, huggingface에 호스팅되어 있는 모든 pretrained model을 사용할 수 있음.
Installation
pip install --upgrade diffusers[torch]Simple Inference
- Pipeline (text_encoder + tokenizer + scheduler + unet + vae)
: Model과 그에 맞는 scheduler가 결합되어 간편한 inference를 가능케 해줌.
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipeline.to("cuda")
prompt = "An image of a squirrel in Picasso style"
image = pipeline(prompt).images[0]
# Pipeline options (deterministic outputs, inference steps, guidance scales, ...)
generator = torch.Generator("cuda").manual_seed(1024)
image = guided_pipeline(
prompt,
num_inference_steps=50,
guidance_scale=7.5,
clip_guidance_scale=100,
num_cutouts=4,
use_cutouts=False,
generator=generator,
).images[0]- UNet Models & Schedulers manually
: UNet2DModel과 같은 Models는 noisy image를 입력받아 less noisy image or residual을 계산하도록 학습된 parameterized neural network(PyTorch modules)에 해당.
https://github.com/huggingface/diffusers/tree/main/src/diffusers/models
: 반면, DDPMScheduler와 같은 Schedulers는 image에 noise를 추가하거나 less noisy sample을 계산하는 알고리즘에 해당하며, trainable weights가 없는 parameter-free Python class에 해당.
https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers
Model이 less noisy sample과의 residual을 예측(model.sample), scheduler가 less noisy sample 생성(scheduler.step)하며 inference 진행.
from diffusers import DDPMScheduler, UNet2DModel
from PIL import Image
import torch
import numpy as np
scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
model = UNet2DModel.from_pretrained("google/ddpm-cat-256").to("cuda")
scheduler.set_timesteps(50)
sample_size = model.config.sample_size
noise = torch.randn((1, 3, sample_size, sample_size)).to("cuda")
input = noise
for t in scheduler.timesteps:
with torch.no_grad():
noisy_residual = model(input, t).sample
prev_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
input = prev_noisy_sample
image = (input / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
image = Image.fromarray((image * 255).round().astype("uint8"))- 'from_pretrained' options
: HuggingFace Diffusers docs (from_pretrained)
Core API Codes
-
from diffusers import [PIPELINE or MODEL or SCHEDULER module name]
-
repo_id = "[HUGGINGFACE MODEL repo name]"
-
model = [module name].from_pretrained([repo_name])
-
model.config Necessary parameters to define the model architecture
-
model.to("cuda")
-
image = model("[OPTIONAL conditioning]").images
-
model.save_pretrained("my_model") 'config.json', 'diffusion_pytorch_model.bin'
Prompt Conditioning
- Text prompt를 tokenize(wordtoken mapping) & encode(tokenembedding-vector mapping)하는 module.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")- Text embeddings 생성
prompt = ["a photograph of an astronaut riding a horse"]
text_input = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt"
)
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]- Classifier-free guidance를 위한 unconditional text embeddings 추가
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
with torch.no_grad():
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])- 이후 noise residual을 계산할 때 encoder_hidden_states에 text embeddings 전달
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sampleTextual-Inversion
Koo's log: Fine-Tuning Techniques for Diffusion Models
HuggingFace: Stable Diffusion concepts library
-
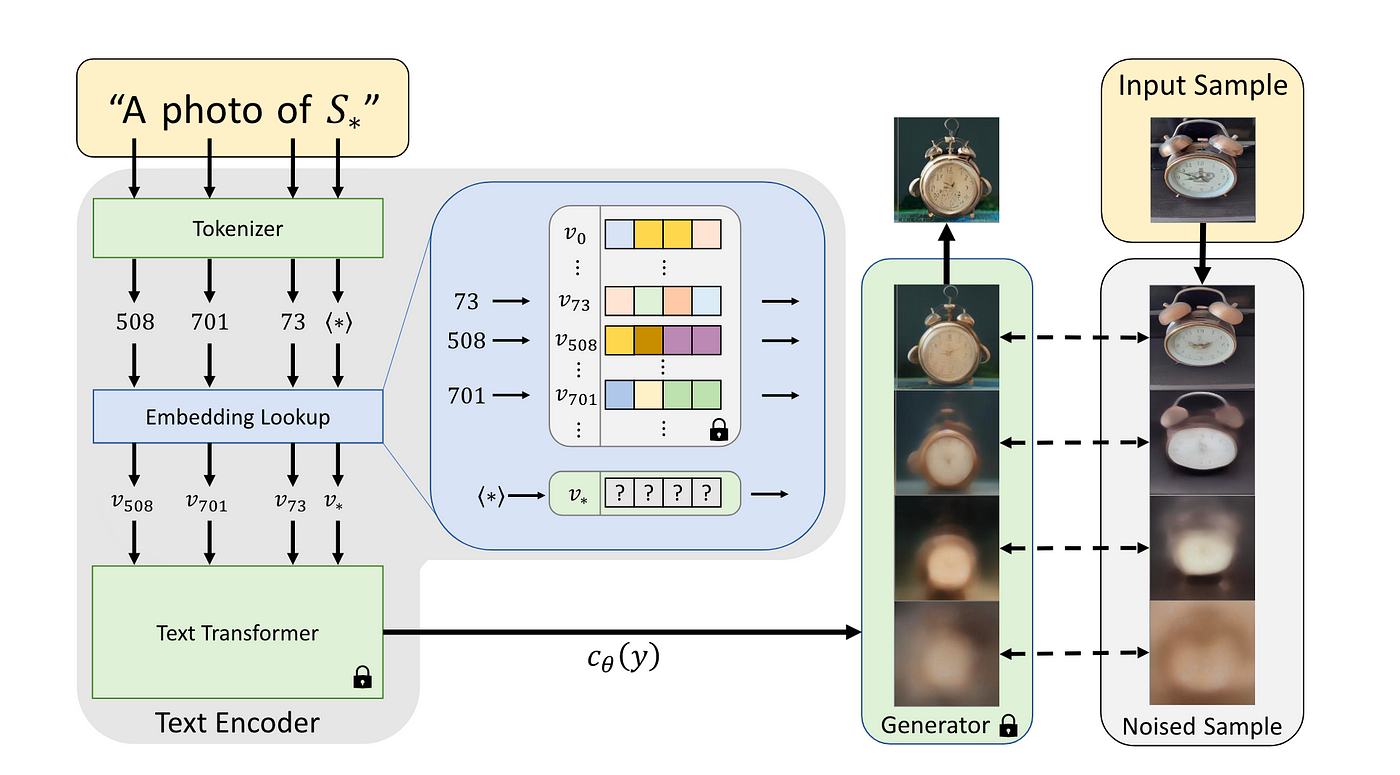
Text prompt를 word token embedding vector의 순서로 변환하는 text encoder에 대해, 특정 visual concept에 대한 새로운 pseudo-word를 생성하여 diffusion model이 해당 concept에 대한 semantic understanding을 갖추도록 하는 방법.
-
학습시키려는 concept에 대해선 일반적으로 angle brackets를 붙여 <cat-toy>와 같은 placeholder_token을 설정함. 또한 해당 concept과 관련된 initializer token으로 해당 concept에 대한 학습의 시작점 설정 가능.
References
