다음 네 Ref-based VSR 논문의 methods에 대한 요약
-
CrossNet: 'CrossNet: An End-to-end Reference-based Super Resolution Network using Cross-scale Warping' (ECCV 2018, Zheng et al.)
# FlowNet 활용하여 warping
*CrossNet++ (IEEE 2021, Zheng et al.) 모델은 dual-camera SR 목적 -
SSEN: 'Robust Reference-based Super-Resolution with Similarity-Aware Deformable Convolution' (CVPR 2021, Shim et al.)
# Deformable conv. 활용 -
-Matching: 'Robust Reference-based Super-Resolution via -Matching’ (CVPR 2021, Jiang et al.)
# -matching 제안 -
EFENet: 'Reference-based Video Super-Resolution with Enhanced Flow Estimation’ (CVPR 2022, Zhao et al.)
# RNN-based 모델
1. CrossNet
'CrossNet: An End-to-end Reference-based Super Resolution Network using Cross-scale Warping’ (ECCV 2018, Zheng et al.)
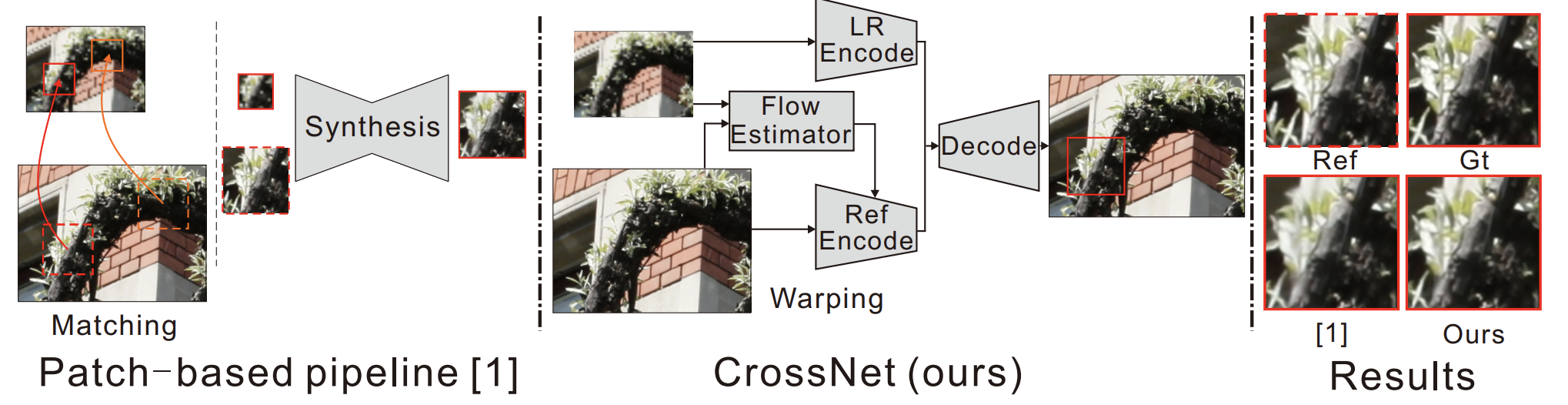
- LR input과 HR ref에 대해 patch 단위의 mapping을 진행하여 patch별로 SR하는 기존의 patch-based pipeline Inter-patch misalignment 발생(blocky artifact, blurring effect) + 많은 연산량(장당 30분 소요).
-
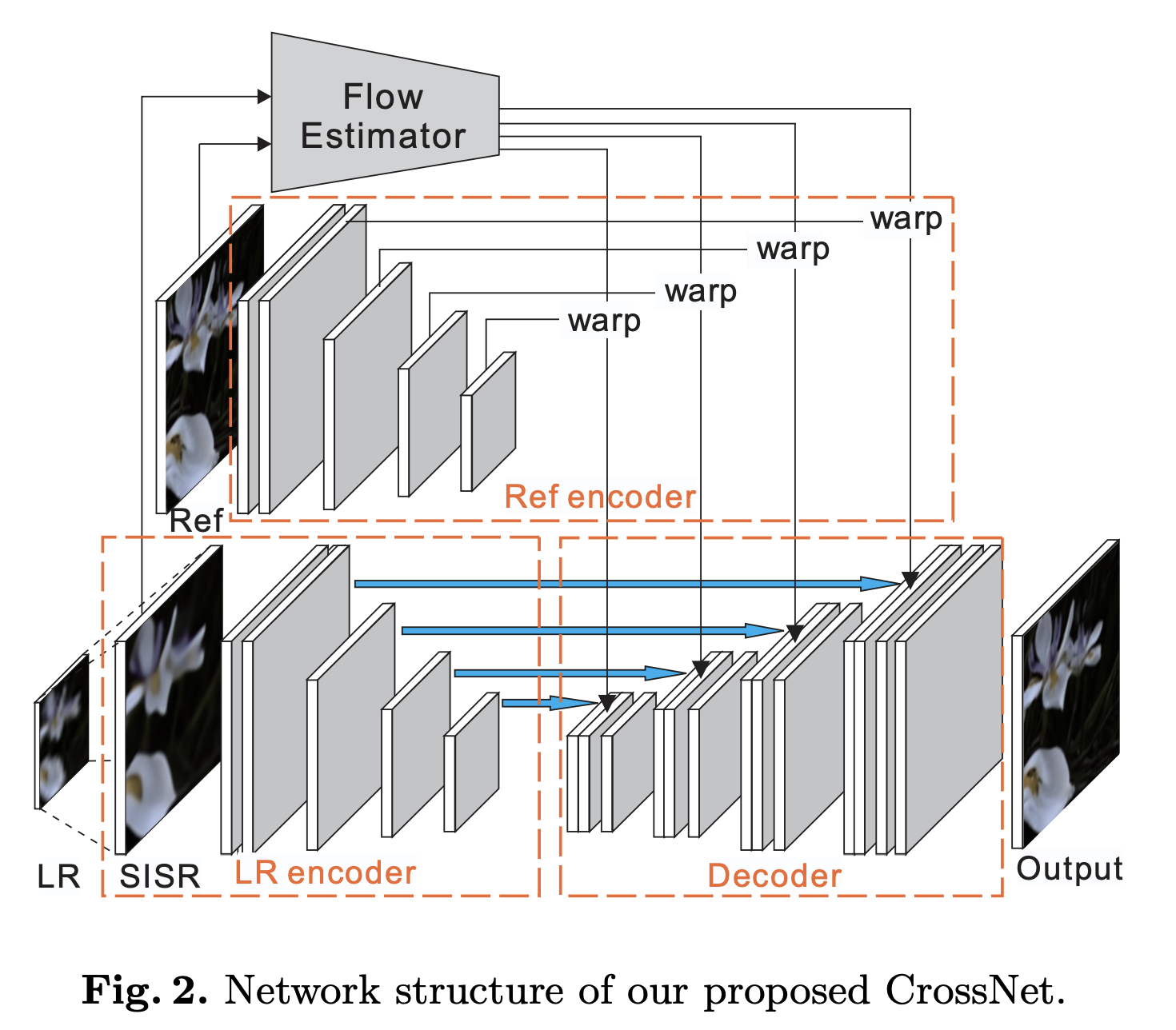
Spatial transformer network (STN)의 warping module이 갖는 이점을 활용하여, 이미지 전체에 대해 FlowNet의 각 layer가 출력하는 correspondency 정보를 U-net decoder의 각 layer에 concatenate하며 multi-scale warping 수행. Fully convolutional end-to-end network structure.
-
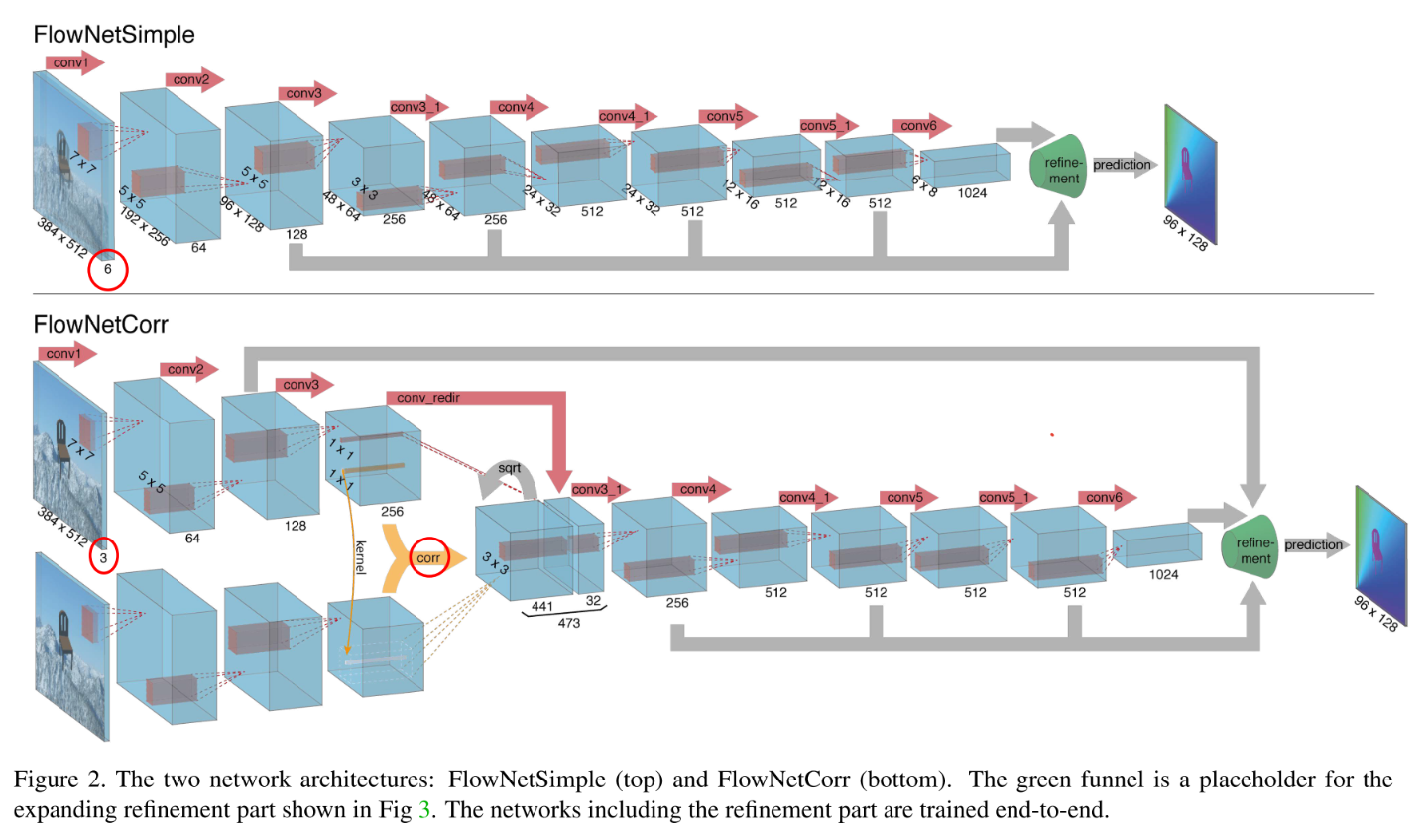
Flow estimator로는 FlowNetS의 마지막 layer에 x4 upsampling layer를 두 개의 x2 upsampling module로 대체하여 사용.
2. SSEN
'Robust Reference-based Super-Resolution with Similarity-Aware Deformable Convolution' (CVPR 2020, Shim et al.)
- Multi-scale manner로 pixel-/patch-wise similarity를 찾는 non-local block 적용하여 다양한 범위의 similarity에 robust하도록 학습(관련 없는 reference가 입력되어도 원본이 망가지지 않도록).
-
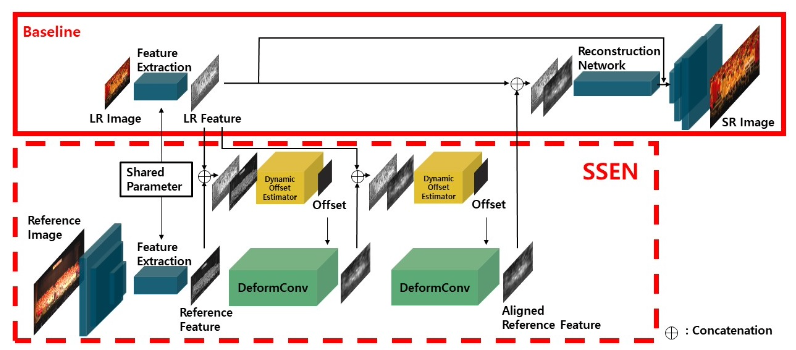
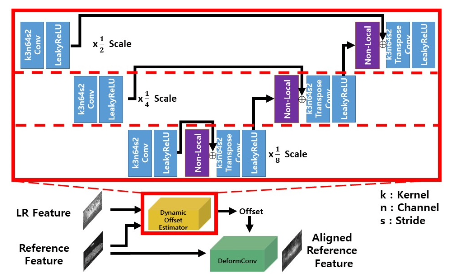
LR input과 HR reference 각각으로부터 추출한 feature로 deformable convolution kernel의 offset을 추정한 뒤 reference feature를 DeformConv layer(별도의 optical flow prior 없이 feature alignment 가능)에 태워 warping.
-
두 차례 alignment를 거친 뒤 원래의 LR feature와 concatenate하여 decoder에 태워 SR 수행.
-
Dynamic Offset Estimator는 U-net 구조로 구성되고, intra-/inter-features(pixel-space의 patch에 해당)의 global correlation에 해당하는 non-local blocks는 각 scale에 곱해져 어느 scale의 feature에 가중치를 부여할 것인지를 결정.
-
Reference로 input과 동일한 LR image를 입력할 경우 self-similarity SR 가능.
3. -Matching
'Robust Reference-based Super-Resolution via -Matching’ (CVPR 2021, Jiang et al.)
- LR input과 HR reference 간 correspondency를 찾기 위해선 transformation(scale & rotation) gap과 resolution gap을 해결해야 함. 이전의 방법들은 content & appearance similarity를 기반으로 correspondency를 계산했는데, 이는 reference 간에 scale이나 rotation 등의 차이가 있는 경우 matching을 제대로 해결하지 못함.
-
그러한 변환에 robust한 -matching 제안.
-
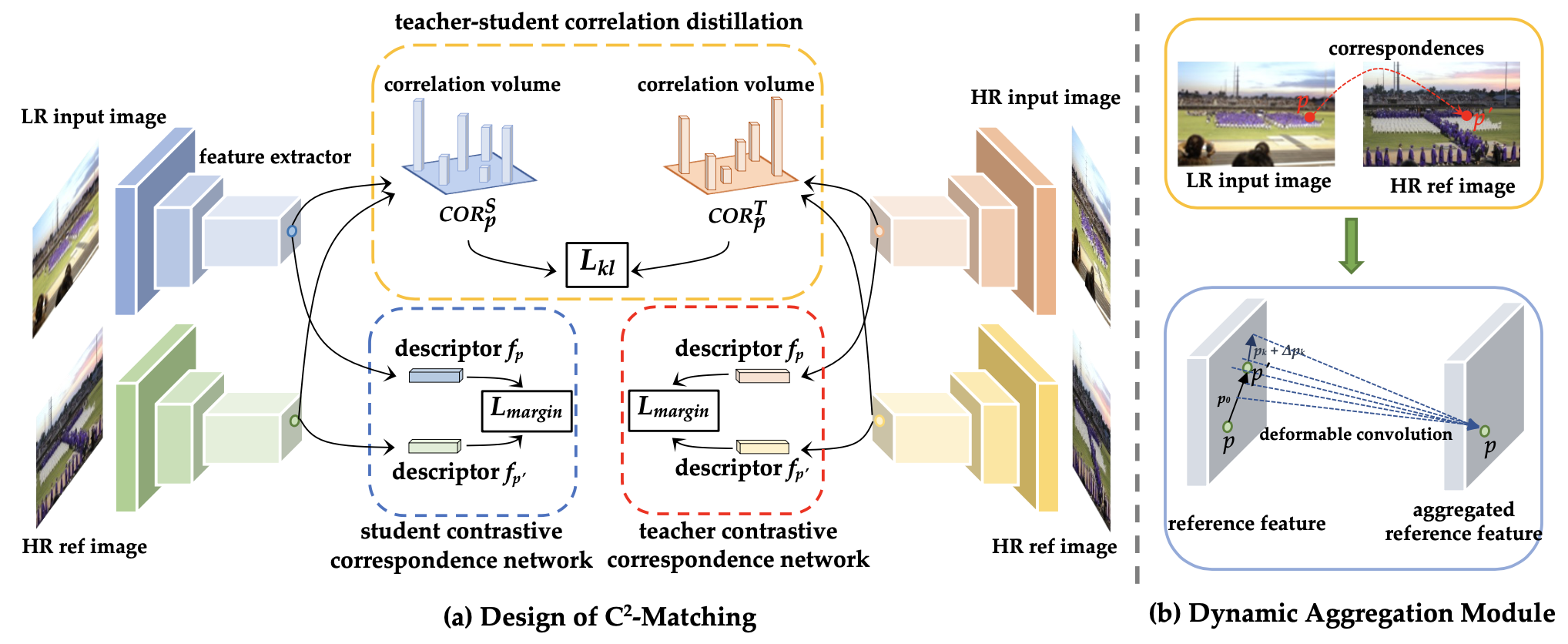
Contrastive Correspondence Network (cross transformation matching)
: 두 이미지(HR input을 downsampling한 LR input 와 homography transformations를 적용한 HR reference )의 동일한 지점 , (3x3 patch)에 대해, feature extractor를 거쳐 출력되는 descriptor , 가 서로 동일하도록 학습. 이후, 가장 비슷한 feature 값을 가지는 위치끼리 mapping 수행. -
Teacher-Student Correlation Distillation (cross resolution matching)
: 이때, LR input의 정보 손실로 LR-HR matching의 학습이 tricky하기에, 동일한 네트워크 구조에 입력 데이터만 달리하여 HR-HR matching 모델을 학습시킨 뒤, input과 reference 간의 descriptor들의 분포 차이에 해당하는 correlation volume을 구하여 그에 대한 두 모델의 KL-divergence 값이 줄어들도록 학습.
-
-
앞선 contrastive correspondence network로 feature map 상에서의 mapping이 이뤄지면, dynamic aggregation module로 reference의 texture를 합침. 이는 아래와 같이 convolution kernel weight , learnable offset , learnable modulation scalar 로 구성됨. (가 HR ref으로 mapping된 position과의 차이)
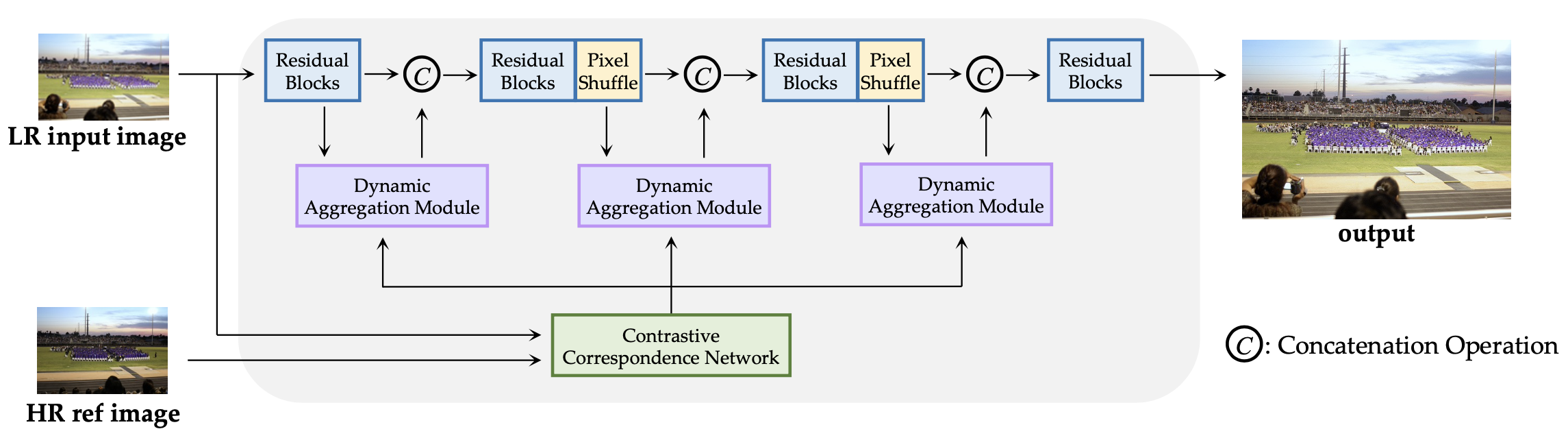
: 실제로는 LR input을 ResNet과 dynamic aggregation module을 여러 번 통과시키며 서로 다른 scale의 feature map에 대해 ref feature를 전이해 나가며 SR 수행. (PixelShuffle이 2x upscale 역할 수행) 이때 correspondence network와 restoration network를 별도로 학습.
-
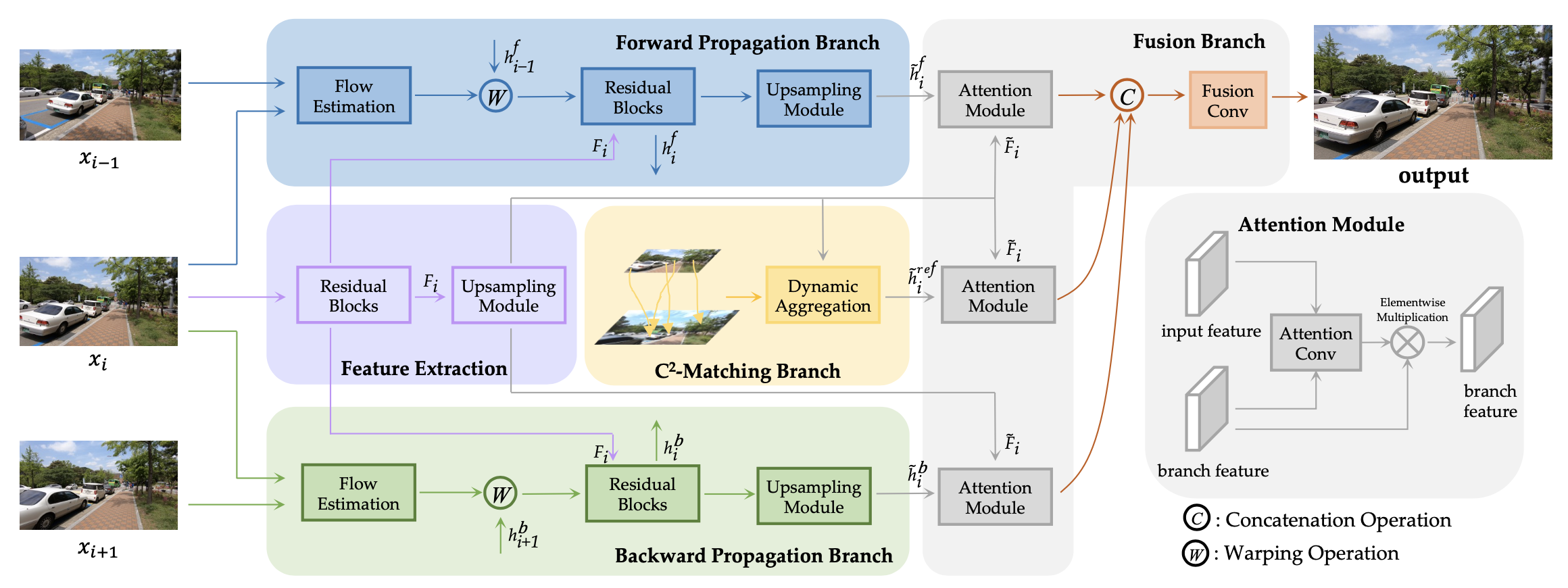
Reference-based video SR의 경우 bi-directional RNN framework를 활용해 VSR 수행.
- Dataset: LR과 HR의 화질은 각각 40x40, 160x160. 보통의 Ref-SR 모델은 CUFED5 dataset에서 학습되지만, 웹 상에서 input과 similarity가 비교적 떨어지는 reference를 구하는 경우도 고려되도록 WR-SR dataset 구축하여 evaluation에 활용.

[Summary]
이미지에 대한 feature extractor를 distillation도 활용하여 학습시킨 뒤 feature descriptor의 correspondence로 결정되는 mapping과 dynamic aggregation으로 Ref-based SR 수행.
4. EFENet
'Reference-based Video Super-Resolution with Enhanced Flow Estimation’ (CVPR 2022, Zhao et al.)
-
HR reference를 기준으로, 모든 LR frame들과의 cross-scale flow를 추정한 뒤 SR하려는 마지막 frame에 대해 flow refinement를 수행하며, CrossNet++의 temporal gap에 대한 error를 보완. HR reference의 visual cues와 LR sequence의 temporal information을 모두 활용하여 alignment error 최소화.
-
이전의 Ref-VSR 모델들은 인접한 frame 간의 correspondence를 추정(LR image 간 optical flow estimation의 error 발생)하고 최종 frame에 해당 정보를 누적하는 반면, EFENet은 이를 global하게 다루어 error가 누적되는 것을 방지.

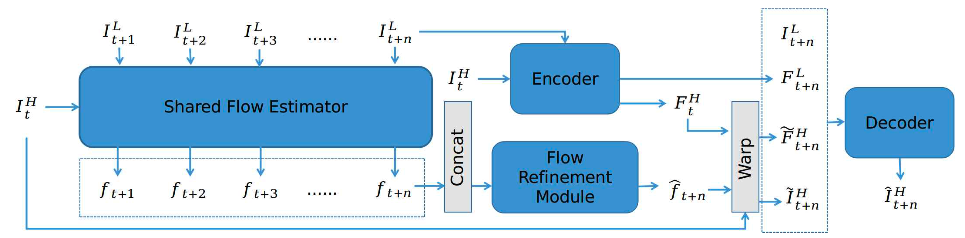
- HR ref 와 LR frames 각각으로부터 optical flow maps 계산(CrossNet++의 cross-scale flow estimator 활용).
- 이들을 concatenate한 뒤 flow refinement module(U-net)에 입력하여 계산.
- HR ref 와 이를 encoder에 통과시켜 얻은 feature 를 로 warping하여 계산.
- LR furthest frame 과 이를 encoder에 통과시켜 얻은 feature 까지 함께(concatenate) decoder를 통과시켜 계산
- 학습데이터는 Vimeo90K(7-frame의 영상으로 구성, 448×256 화질)와 MPII 사용.
Considerations
Input과 reference 간 similarity가 많이 떨어지는 WR-SR 데이터셋에 대해 학습이 이뤄짐. 회전하는 물체에 fine-tuning한다면 더 효과적으로 texture를 옮겨올 수 있지 않을까.
