일반적으로 Diffusion model의 본체가 되는 checkpoint는 2~7GB 정도로 파일의 크기가 매우 큼. 한편 LoRA, hypernetwork 등의 fine-tuning 파일들은 약 100~200MB 정도로 가벼운 크기를 지님.
Textual Inversion
'An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion' | Gal et al. | AUG22
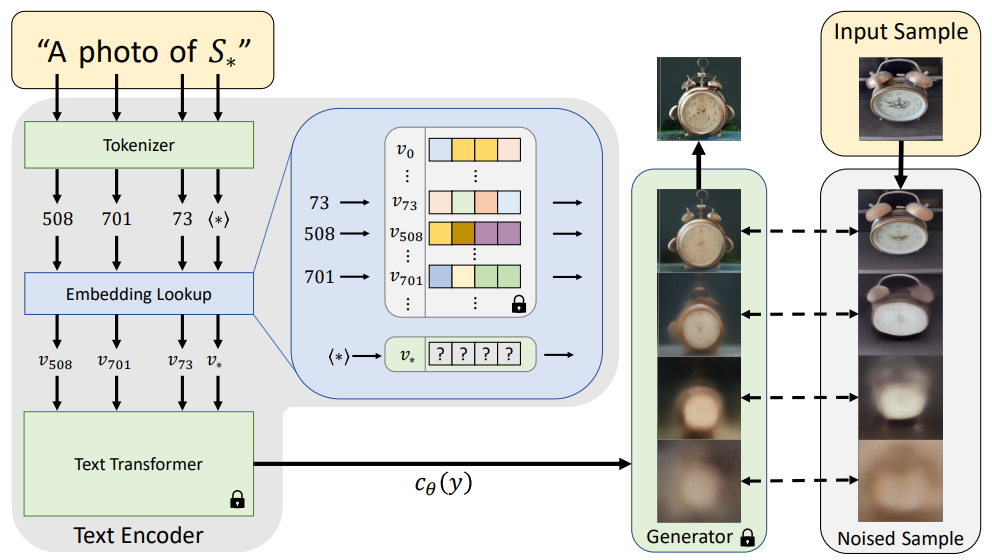
- 특정 object에 대한 3~5장의 이미지만으로 textual embedding vector를 찾아 customized model 생성. 해당 subject의 pseudo-word 에 대해, 'A photo of '의 문장이 예시 이미지를 다시 reconstruct할 수 있도록 의 embedding을 LDM loss로 optimize(text encoder와 diffusion model은 frozen), 이를 textual inversion이라 칭함.
- Embedding space가 특정 object의 image semantics를 잡아내기에 충분히 expressive하다는 사실에 기인하여, 해당 공간에서 주어진 object를 가장 정확히 근사하는 vector를 찾아내는 방법론. 모델 자체에 대한 추가 학습이 불필요하며 DreamBooth가 생성하는 파일 크기가 2-7GB에 달하는 것에 반해, textual inversion은 100KB 내외의 embedding vector만을 생성하며 용량 면에서 큰 이점을 지님. 단, 그만큼 성능은 떨어지는 듯.
DreamBooth (CVPR 2023, Google)
'DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation' | Ruiz et al. | MAR23
- Google의 이미지 생성 AI 'Imagen' 용으로 개발된 이미지 최적화 기술.
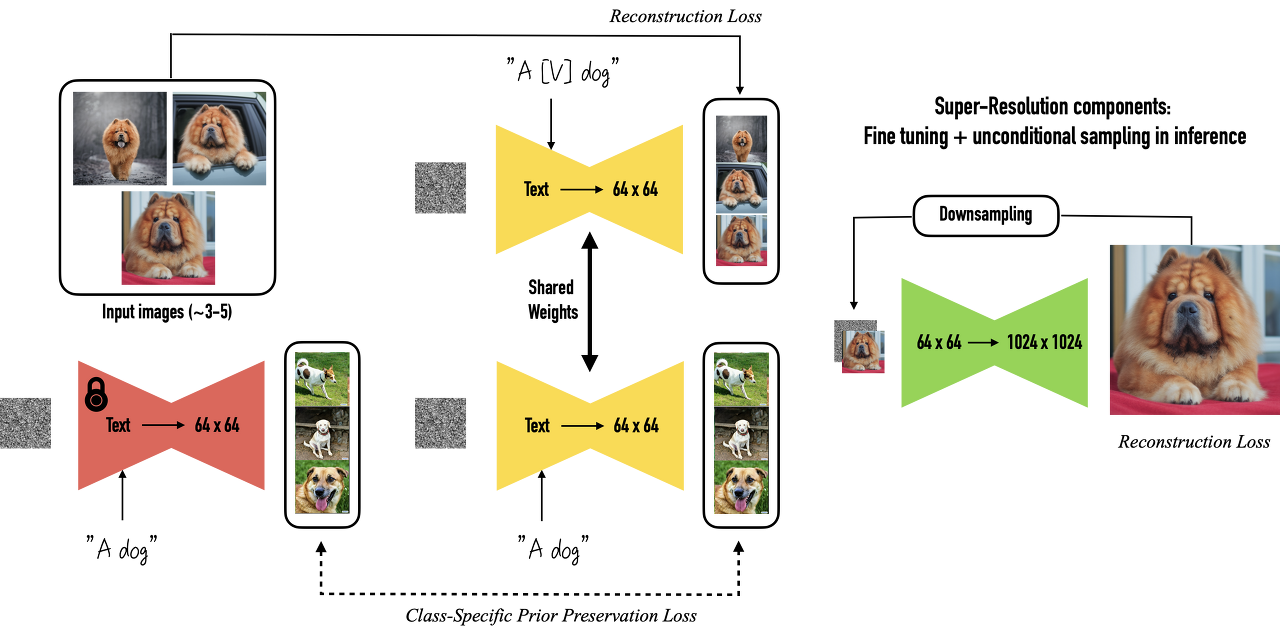
- Pre-trained Imagen을 특정 class명 및 그와 연관된 3~5장의 이미지로 fine-tuning하여 customized text-to-image model 생성.
- 추가하려는 subject를 'a [identifier] [class noun]'의 형식으로 labeling하였으며, identifier의 경우 'unique'와 같이 자주 쓰이는 단어로 지정하면 기존의 의미를 새로운 의미로 disentangle-entangle해야 하기에 학습시간이 늘어나고 성능이 떨어짐. 반면 자주 쓰이는 단어나 'xxy5syt00'과 같은 랜덤 문자열의 경우 문자열 자체가 그림으로 묘사되거나 성능이 떨어지는 문제 발생. Vocabulary에서 상대적으로 rare한 token(language/diffusion model에서 weak prior를 가짐)을 text space로 invert하여 identifier 지정 (Rare-token identifier)
- 적은 장수의 예시 이미지와 기존의 conditioned diffusion loss로 fine-tuning을 진행할 경우, overfitting(예시 이미지의 pose, texture 등의 feature를 그대로 묘사)과 language-drift(identifier를 부여하지 않아도 부여된 object만을 생성하며 기존의 class noun에 대한 prior가 손실되는 현상) 문제 발생.
- Frozen pre-trained model로 생성한 이미지로 supervise함과 동시에 customize하려는 예시 이미지에 대해 학습하며 문제 해결.
LoRA
'LoRA: Low-Rank Adaptation of Large Language Models' | Hu et al. | OCT21
https://da2so.tistory.com/79
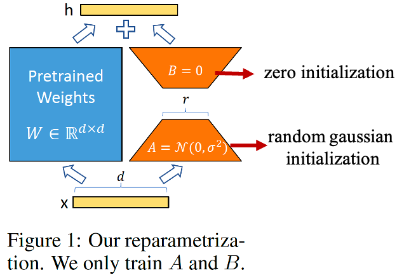
- Pre-trained LLM을 summarization, question and answering 등과 같은 특정 task로 full fine-tuning하는 것은 몇 달이 소요될 정도로 costly함. 이를 해결하기 위해 제안한 Low-Rank Adaptation(LoRA)에선 over-parameterized model은 low intrinsic dimension으로 존재하고 있다는 사실을 기반으로, pre-trained weights는 frozen해두고 특정 dense(FC) layers만 추가 학습하며, 이 때 해당 파라미터를 low rank로 decomposition한 matrices만을 optimize.(는 random Gaussian initialization, B는 0으로 initialize. Pre-trained weights 는 frozen 해두고 , 만 추가적으로 학습하여 이에 더함.)
- 특정 task에 대한 weight , 만 별도로 저장할 수 있어 storage, task switching 면에서 매우 효율적임. (Textual Inversion과 DreamBooth의 중간 용량에 해당: 2~200MB)
- 특히 text-to-image 모델에서는 DreamBooth를 기반으로 하여 cross-attention layer의 weight에 low-rank matrix decomposition 적용. 즉, DreamBooth의 학습 기법을 따르되, 기존 stable diffusion checkpoint model을 유지한 채 특정 task에 특화된 LoRA 파일을 추가할 수 있는 것.
- Character LoRA, Style LoRA, Concept LoRA, Pose LoRA 등 수많은 모델 존재.
Hypernetwork
: Stable diffusion에서 쓰이는 hypernetwork는 '하나의 network가 다른 network의 weight을 생성'한다는, 일반적으로 쓰이는 개념과는 다름.
*Static Hypernetwork: Target network의 weight을 결정
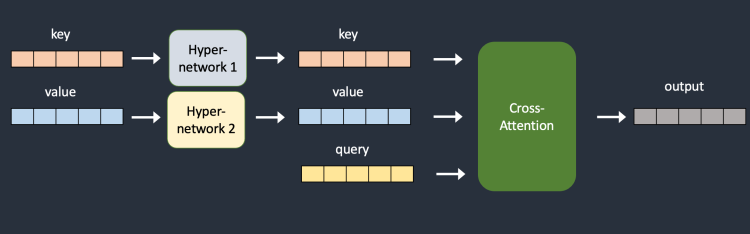
: Conditioning을 위한 cross-attention layer에 hypernetwork를 추가하여 key/value 값을 미세조정하는 technique.

K'AI'ST 학부생까지의 기록