Abstract
여러 scale에 걸쳐 weights를 공유하는 feature extractor와 "scale-agnostic"한 motion estimator로 frame interpolation algorithm 구성. sGram matrix loss로 학습시켰으며, optical-flow 및 depth network가 별도로 필요하지 않은 unified single-network approach를 제시함.
1. Introduction
-
Large scene motion에도 적용 가능한 frame interpolation model 제시. Multi-scale feature extractor를 적용하여 "scale-agnostic" bidirectional motion estimation module 제시.
-
High-level VGG features 간 auto-correlation에 해당하는 Gram matrix loss로 optimize하여 large disoccluded region에 대한 blurriness 해결.
-
Optical flow, depth와 같은 prior network를 별도로 학습시킨 기존의 방법에 비해, 일반적인 frame triplet으로 학습 가능한 unified architecture 제안.
2. Related Work
(생략)
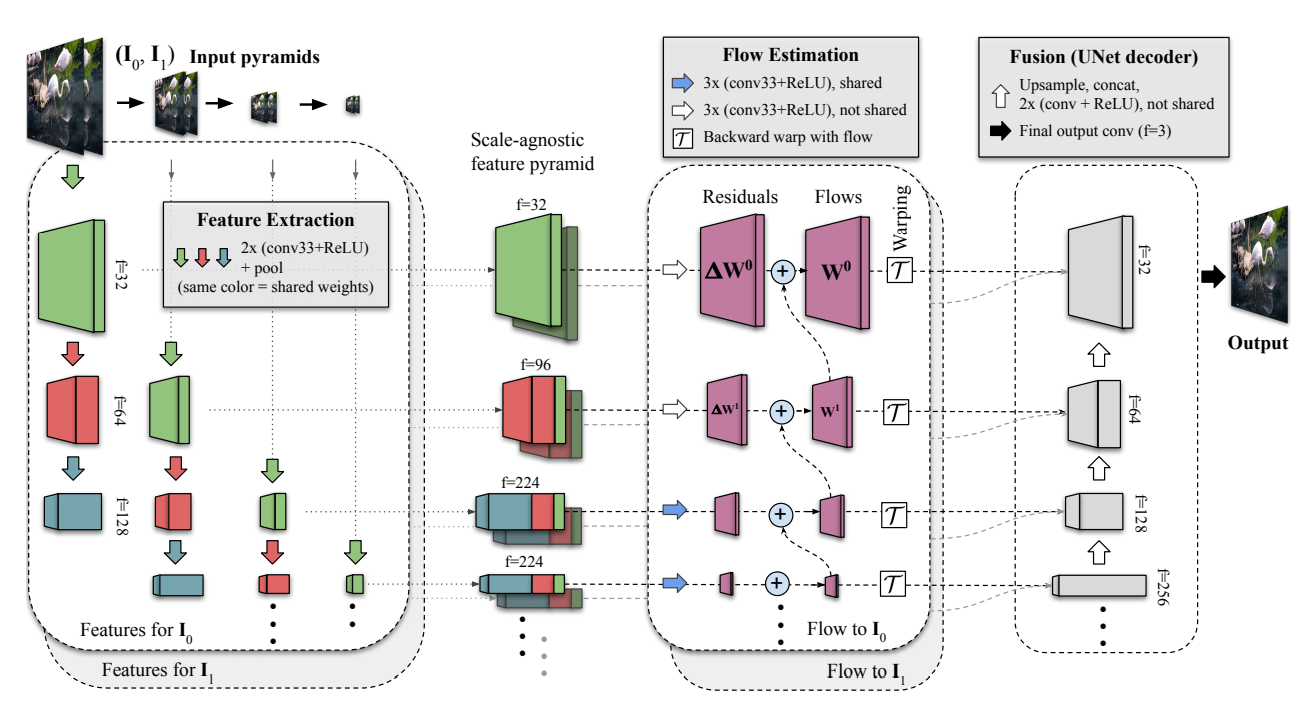
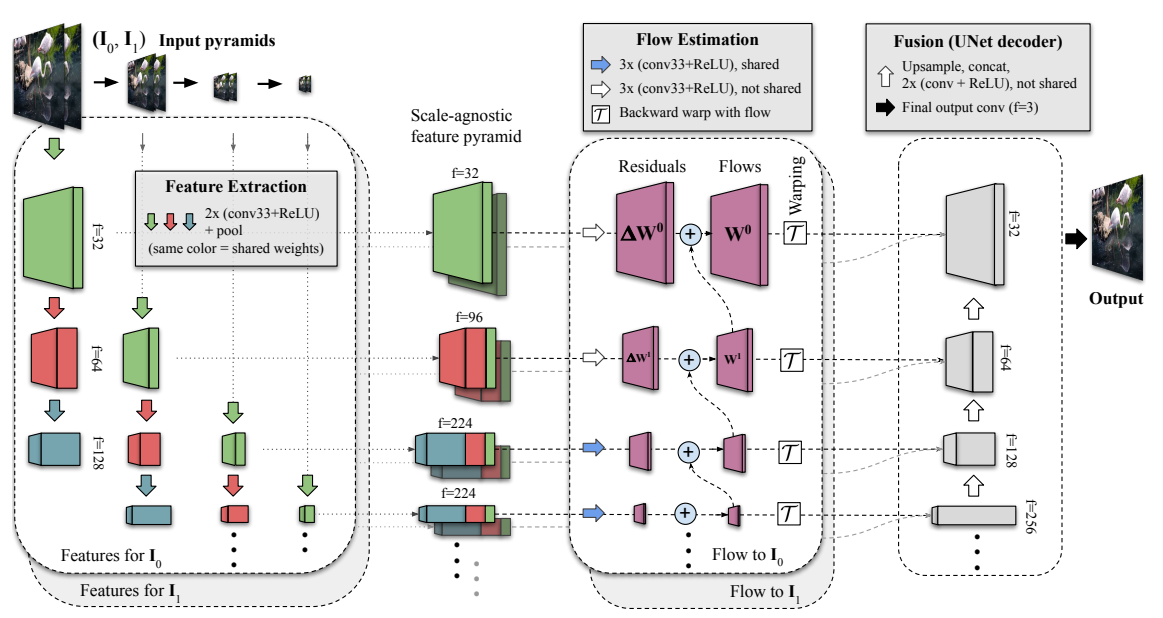
3. Method
-
In-between motion이 큰 두 이미지 쌍 에 대해, mid-image 생성.
: 학습 단계에선 에 대해 supervise한 뒤 recursive하게 in-between image에 대한 prediction 진행.
-
Finer scale에서의 large motion이 coarser scale에서의 small motion과 동일해야 하기에 scale에 걸쳐 weights를 공유하는 convolution layer를 사용하면 large motion supervision에 많은 pixel 사용 가능.
Feature Extraction
- 두 입력 이미지 에 대해, image pyramid 생성.
- 각 image pyramid level에 대해, shared UNet encoder로 feature pyramid , 생성.
- Scale-agnostic feature pyramids , 생성. 각 level의 서로 다른 depth지만 spatial dimension이 같은 layer를 concatenate.
Flow Estimation
-
두 scale-agnostic feature pyramids의 각 level에 대해, bi-directional motion 산출: Level 의 predicted residual과 coarser level 의 upsampled flow를 더하여 level 의 task oriented flow 계산.
-
해당 flow로 bilinear warping하여 intermediate time 에 대한 feature map , 생성.
Fusion
- 각 layer의 feature map을 upscale, concatenate을 반복하여 최종 mid-frame 생성.
3.1 Loss Functions
- Intermediate stage에 대한 loss 없이 image synthesis loss만을 부여함.
- Interpolated frame과 ground-truth frame 간 L1 loss(reconstruction loss):
- VGG-19 features에 대한 L1 loss(perceptual loss):
- VGG-19 features에 대한 Gram matrix loss(style loss):
- Interpolated frame과 ground-truth frame 간 L1 loss(reconstruction loss):
3.2 Large Motion Datasets
4. Implementation Details / 5. Results
(생략)
Paper Summary
두 이미지 사이의 frame-interpolation을 fine/coarse 이미지의 multi-level feature map을 복합적으로 겹쳐 사용하며 별도의 optical flow나 depth에 대한 prior 없이도 학습함.
