'Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation' Paper Summary
'23 Image-to-3D Study

Abstract
Image model을 video model로 전환시키는 zero-shot text-guided video-to-video translation framework를 제시함. 1) Key frame translation part는 hierarchical cross-frame constraint가 적용된 채 key frame을 생성하는 adapted diffusion model로 구성되며, 2) Full video translation part는 temporal-aware patch matching과 frame blending을 통해 key frame을 다른 frame으로 전파함.
이를 통해 LoRA, ControlNet 등의 pre-trained model에 별도의 re-training 및 optimization 없이 global style과 local texture에 대한 temporal consistency를 얻어냄.
1. Introduction
-
Text-to-video diffusion model은 일반적으로 1) large-scale video data에 대해 학습시키거나(막대한 computing resources 요구, 기존의 image model 활용 불가), 2) image model을 단일 video에 대해 fine-tuning하거나(긴 영상에 대해선 비효율적이며 overfitting의 문제 발생), 3) 별도의 training 없이 cross-frame constraint를 부여하는 zero-shot method를 사용(global style만을 익히고 local structure와 texture는 보존시키지 못함)
Low-level temporal consistency를 유지하는 zero-shot strategy를 새롭게 고안! -
Previous rendered frame을 low-level reference로, first rendered frame을 rendering process에 대한 regulator로 삼는 optical flow를 diffusion sampling의 multiple stages에 dense cross-frame constraint으로 부여.
-
Key frame translation과 Full video translation part로 나뉨.
-
Diffusion-based generation과 patch-based propagation을 혼합한 방법론 제시.
2. Related Work
-
Text Driven Image Generation
- Autoregressive models: DALL-E, CogView, Make-A-Scene
- Diffusion models: DALLE-2, Imagen, GLIDE, LDM
- Customized models: Textual Inversion, DreamBooth, LoRA, ControlNet
-
Video Editing with Diffusion Models
- Video Diffusion Model, Imagen Video, Make-A-Video
Large-scale video data 필요. - Tune-A-Video, Edit-A-Video, Video-P2P, vid2vid-zero
Cross-frame attention, Null-Text Inversion 등을 Image diffusion model에 적용하여 video model 구현.
Fine-tuning, optimization 필요(비효율적). - FateZero, Text2Video-Zero, Pix2Video
Cross-frame attention + Early-step latent fusion
Texture와 detail에 대한 cross-frame consistency 면에서 떨어짐.
- Video Diffusion Model, Imagen Video, Make-A-Video
3. Preliminary: Diffusion Models
-
Stable Diffusion (생략)
-
ControlNet
: Text prompt의 spatial controllability를 향상시키기 위해 extra condition(e.g. edges, depth, human pose) 부여
: Temporal consistency가 개선된 zero-shot V2V framework를 구성하기 위해, structure guidance를 부여할 수 있는 ControlNet을 사용함.
4. Zero-Shot Text-Guided Video Translation
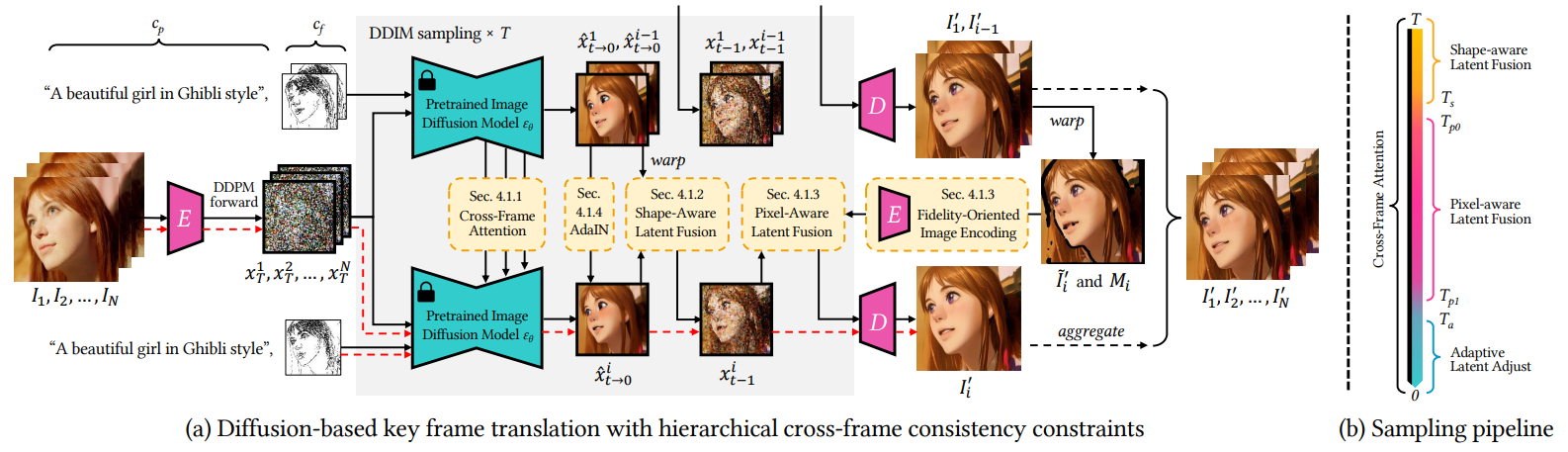
4.1. Key Frame Translation
-
Style-Aware Cross-Frame Attention 모든 sampling step에 적용
: U-Net 상의 self-attention layer를 first(anchor) frame과 previous frame에 대한 cross-frame attention layer로 교체. -
Shape-Aware Cross-Frame Latent Fusion Sampling step 초반에 적용
: Optical flow와 occlusion mask , 로 frame의 latent feature를 warping하여 frame의 latent feature에 반영. 실험적으로 anchor frame이 previous frame보다 좋은 guidance를 제공하였음.*Optical flow: 두 프레임 사이에서 각 픽셀의 motion을 나타내는 vector map.
*Occlusion mask: 현재 프레임 상에서 일시적으로 가려진 이전 프레임 상 픽셀들의 집합. 두 프레임 간의 픽셀 강도 변화나 이동 크기 등을 기준으로 임계치보다 클 경우 occlusion이 발생한 것으로 판단. -
Pixel-Aware Cross-Frame Latent Fusion Sampling step 중반에 적용
- Fidelity-Oriented Image Encoding
: Low-level texture feature를 유지시키기 위해선 latent feature를 그대로 warping하기보단, pixel space상에 생성된 (low-level texture feature를 담고 있는) 이전 frame을 warping한 뒤 latent space로 다시 encoding하여 반영해야 함. 하지만, frame index가 증가할수록 lossy autoencoder를 많이 거치기에, distortion과 color bias가 누적됨.
: 단일 auto-encoding process마다 정보 손실량이 균일하다는 사실에 착안하여, 1차 auto-encoding 후 이미지와 2차 auto-encoding 후 이미지 간 차이만큼을 1차 auto-encoding 후 이미지에 더해주는 compensation 진행. (실험적으로 일 때 효과적이었음.): 한편, compensation으로 발생하는 artifact를 방지하고자 와 사이 error가 임계값을 넘어가는 지점을 제외시키는 mask 추가. - Structure-Guided Inpainting
: Pixel-space 상에서 생성된 rough rendered frame 에 대해, 미리 생성된 anchor frame 과 previous frame 을 warping한 뒤 합산하여 pixel reference 생성.: 이후 latent space 상에서, DDIM sampling을 진행할 때마다 mask area 에는 ControlNet의 guidance를, 그 외에는 의 guidance 부여.
- Fidelity-Oriented Image Encoding
-
Color-Aware Adaptive Latent Adjustment Sampling step 종반에 적용
: AdaIN(style transfer network)을 적용하여 의 channel-wise 평균 및 분산 값을 과 일치시킴. 이를 통해 모든 key frame에 대한 color style이 일관되도록 유도.
4.2. Full Video Translation
Key frames에 대해서만 앞선 adapted diffusion model 적용 후, patch-based frame interpolation algorithm으로 나머지 frames 렌더링.
-
Patch-Based Propagation
: Guided path-matching algorithm에 color, positional, edge, temporal guidance를 부여하여 인접 frame 간 correspondences map 생성. -
Temporal-Aware Blending
: Rendered key frame 와 를 각각 와 로 propagate. 이후 rendered image 과 propagated image 사이의 patch matching error 를 기반으로 pixel selection mask 구성.: 의 원소는 모두 1로 초기화. 이후 매 frame index 에 대해, 이전 frame의 mask 를 optical flow 로 warping한 뒤 을 갖는 pixel에 대해서만 update 진행. (에서 점차 로 진행되도록)
5. Experimental Results
- Pre-trained diffusion model에 추가적으로 입력되는 edge에 대한 structure guidance는 ControlNet을 활용.
- Optical flow estimation은 GMFlow 활용.
Additional Study :: Fine-Tuning Techniques
Textual Inversion, DreamBooth, LoRA, Hypernetwork
Fine-Tuning Techniques for Diffusion Models
ControlNet
'Adding Conditional Control to Text-to-Image Diffusion Models' | Zhang et al. | FEB23
-
Edge map, segmentation map, key points 등의 추가적인 input condition으로 pre-trained diffusion model을 control.
-
Large diffusion model의 weights를 'trainable copy'와 'locked copy'로 복제하여, 'trainable copy'는 task-specific 데이터셋을 통해 conditional control를 학습시키고, 'locked copy'는 기존 모델의 prior가 유지되도록 함. (단, 데이터셋의 크기가 1M 이상인 경우 locked copy에 대해서도 학습 진행)
-
두 neural net block은 'zero convolution'과 연결되며, 이는 weights와 bias가 0으로 초기화된 1x1 크기의 conv. layer에 해당. 따라서 학습 초반에는 locked copy에 영향을 미치지 않으며, condition vector의 semantic content에 대해 optimize.
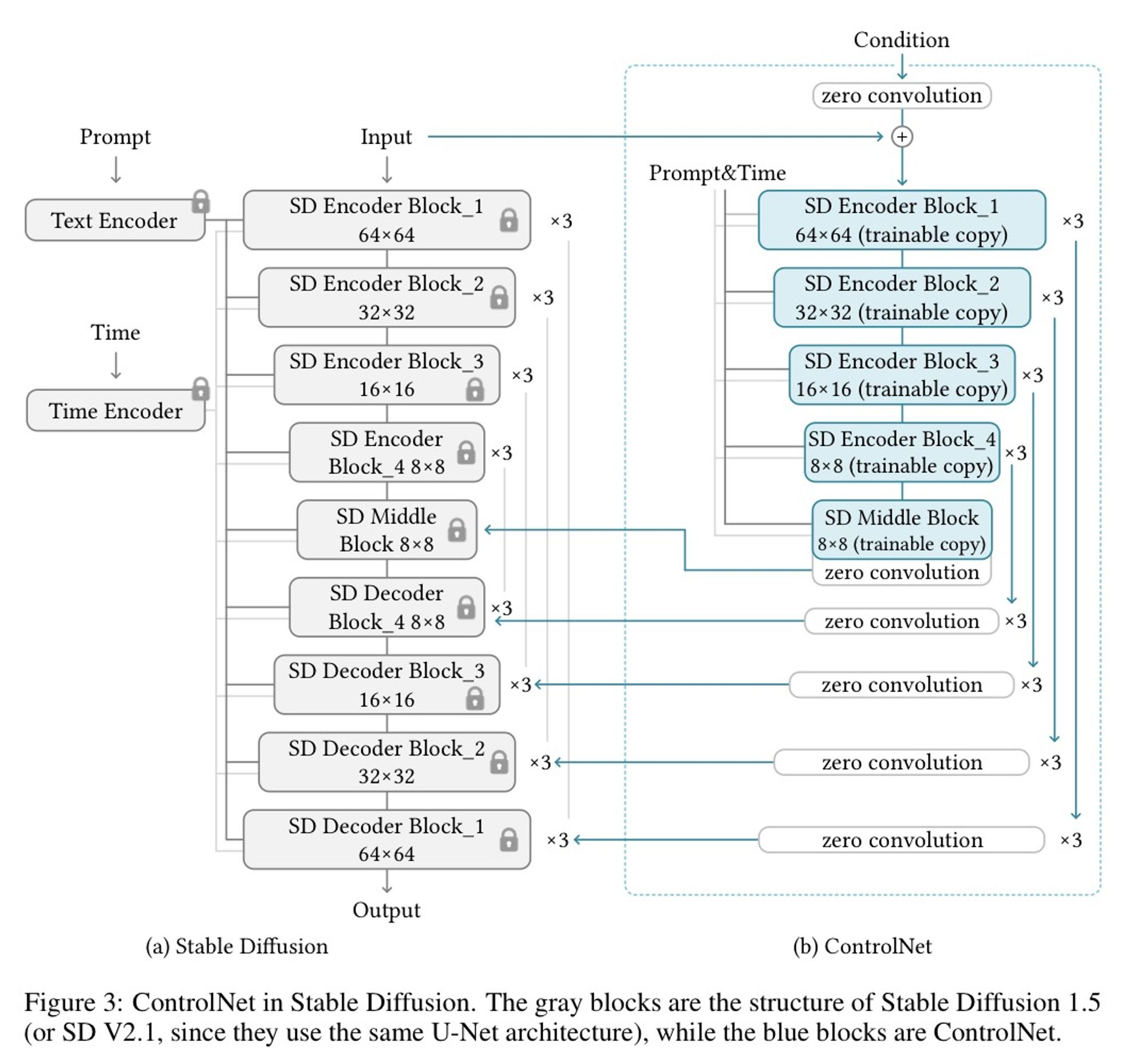
- Canny, Depth, OpenPose, HED(Holistically-Nested Edge Detection), M-LSD 등 수많은 ControlNet 존재.
AdaIN
'Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization' | Huang et al. | JUL17
- Feature space 상의 평균과 분산이 style에 영향을 준다는 실험적 지식을 활용하여, content 이미지의 feature가 가지는 평균과 분산 값을, style 이미지의 값으로 바꿔주어 style transfer 수행.
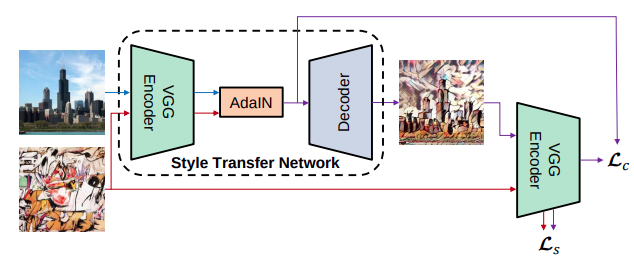
- Pre-trained VGG-19의 앞부분을 encoder로 활용하며, AdaIN layer 역시 learnable parameter가 없기에 decoder만 학습됨.
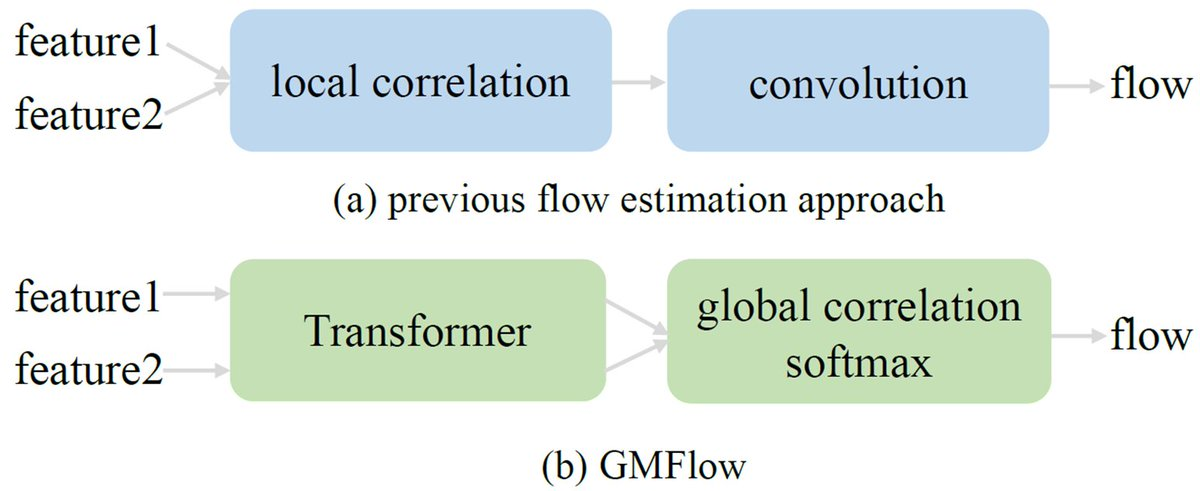
GMFlow
'GMFlow: Learning Optical Flow via Global Matching' | Xu et al. | JUL22
: Optical flow estimation을 global matching problem으로 두어 해결.
Paper Summary
Key Frame translation을 수행하는 DDIM sampling pipeline에 아래와 같이 개선.
1.(전부) self-attention layer를 anchor/previous frame에 대한 cross-frame attention layer로 바꾸어 style consistency 부여.
2.(초반) anchor frame의 denoised feature 를 warping 후 target frame의 denoised feature 에 반영하여 shape consistency 부여.
3.(중반) anchor/previous frame의 image pixel 을 warping 후 rough rendered target frame 에 합하여 생성한 pixel reference를 fidelity-oriented encoder에 입력 후 target frame의 noised feature 에 반영하여 structure consistency 부여.
4.(종반) AdaIN으로 denoised feature 의 channel-wise 평균 및 분산 값을 고정하여 color style consistency 부여.
양단의 rendered key frame으로 color, positional, edge, temporal guidance 기반의 correspondences map 생성 후, 그 사이 frame에 대해 각각 patch-based propagation 진행. Patch matching error 기반의 pixel selection mask로 blending하여 전체 영상 완성.
