'Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior' Paper Summary
'23 Internship Study
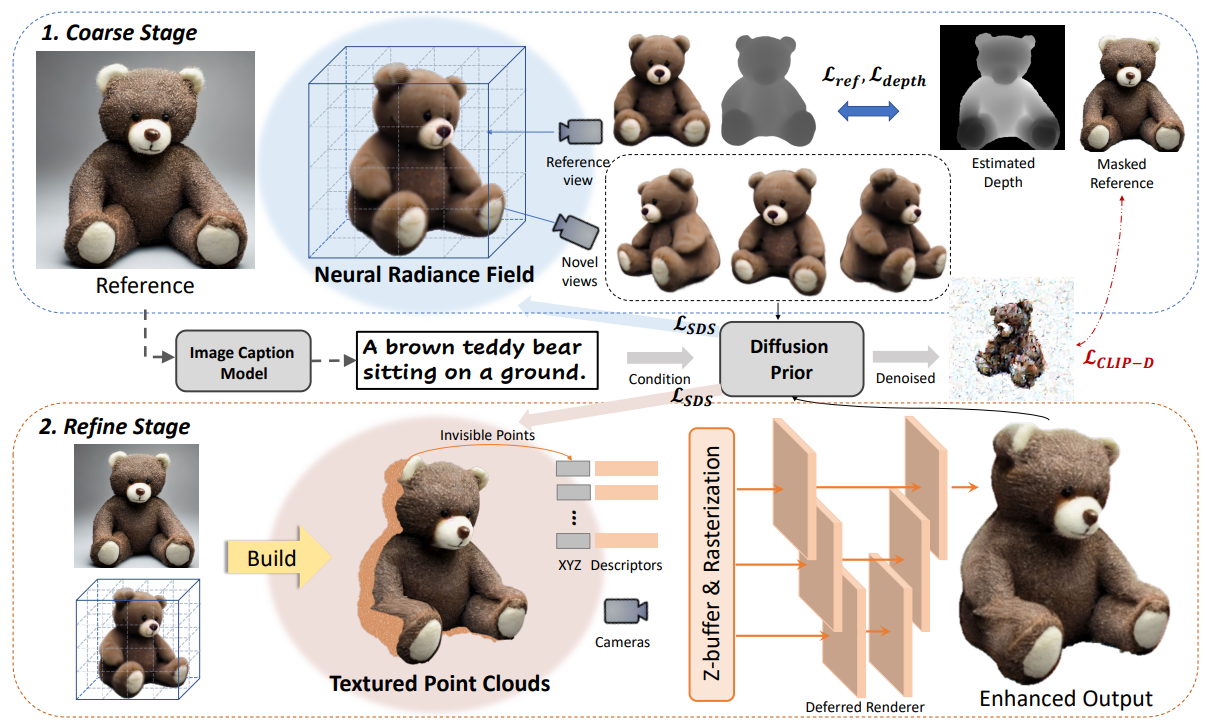
Abstract
2D diffusion model의 prior를 활용하여 two-stage optimization pipeline으로 구성된 Make-It-3D 모델 제시: 1) Reference image와 diffusion prior를 통해 NeRF optimization을 진행하는 첫 번째 stage와 2) Coarse model을 textured point clouds로 변환하여 reference image의 high-quality texture를 입히는 두 번째 stage로 구성.
1. Introduction
[First Coarse Stage]
: SDS와 reference-view supervision으로 NeRF optimize. Text prompt만으로 reference view와의 alignment가 떨어지는 문제는 reference와 novel view rendering 간 image-level similarity를 높이고 reference의 depth image를 geometry prior로 활용하며 완화.
[Second Refine Stage]
: First stage만 거치면 over-smooth textures와 saturated colors 문제 발생. Coarse NeRF model을 textured point clouds로 추출하여 reference texture를 입힌 뒤 나머지 부분은 diffusion prior로 해결.
2. Related Work
(생략)
3. Method
- Reference view의 texture와 depth로 constraint를 부여해 NeRF를 optimize한 뒤, textured point clouds로 변환하여 text-to-image generative model과 text-image contrastive model의 prior로 texture refine.
3.1. Preliminaries
- DreamFusion의 SDS loss
3.2. Coarse Stage: Single-View 3D Reconstruction
-
Reference view에 대해선 pixel-wise loss 부여.
-
Text-to-3D 모델의 prior로 SDS loss 부여. Image captioning model로 prompt 작성.
-
Text prompt에 conditioning 되어 reference image와 align되지 않는 문제를 해결하기 위해 novel view rendering에 대한 denoised image가 reference view와 비슷해지도록 diffusion CLIP loss 적용.
-
는 학습 초반에, 는 학습 후반에 적용.
-
Shape ambiguity를 완화하고자 single-view depth estimator를 사용하여 estimated depth와 reference depth 간 negative Pearson correlation으로 regularize.
-
Reference view 기준으로 narrow range에 대해 학습을 시작하여 점차 range를 넓혀가는 progressive training strategy 사용.
3.3. Refine Stage: Neural Texture Enhancement
-
Reference view로 시작하여 camera pose를 바꿔가며 이전 시점에 보이지 않아 생성되지 않은 point들을 추가해나가는 방식으로 NeRF model을 explicit point clouds로 추출.
-
Reference view의 high-quality texture를 projection. Occluded points의 smooth texture는 diffusion prior를 해결하여 완화.
-
Point cloud의 각 3D point에 19-dimensional descripter 적용. Novel view 에 대해, point cloud 를 번 rasterize (differentiable point rasterizer , descripter )하여 feature map 를 얻어낸 뒤, U-Net renderer 로 image 생성.
4. Experiments / 5. Applications / 6. Conclusions
(생략)
Paper Summary
Single-shot 3D reconstruction을 coarse/refine stage로 나누어 진행. Reference view에 대한 recon. loss와 diffusion prior로부터의 SDS loss에 diffusion CLIP loss와 depth regularization의 trick 추가하여 성능 개선.
