'NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis' Paper Summary
'23 Internship Study
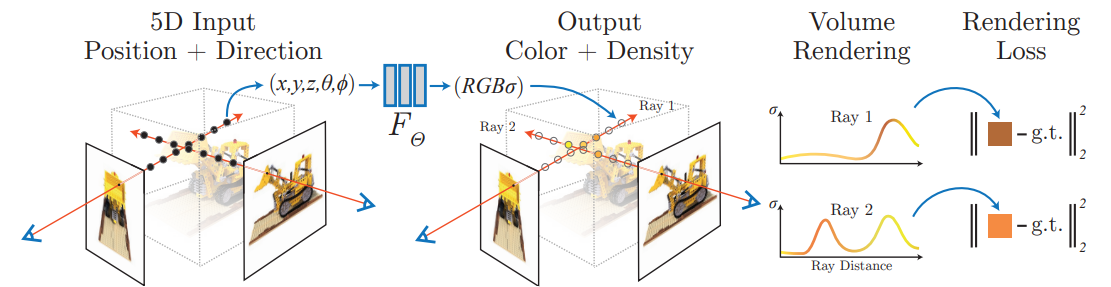
Abstract
Sparse set of input views로부터, MLP로 구성된 underlying continuous volumetric scene function을 optimize하여 complex scene에 대한 novel view를 합성함. 모델은 spatial location 와 viewing direction 를 입력받아 volume density와 view-dependent emitted radiance를 출력하며, 고전적인 volume rendering technique를 사용해 novel-view를 synthesize.
1. Introduction
-
3D point coordinate 와 ray direction 를 입력받아 radiance와 density(해당 지점을 지나며 축적되는 radiance의 크기를 의미하는 opacity)를 출력하는 5D function.
-
학습 이후, rendering 과정은 다음과 같음.
1) 2D screen의 각 pixel에서 scene으로 향하는 camera ray 상의 3D point set sampling.
2) 각 point에 대한 정보를 모델에 입력하여 color/density 값 출력.
3) 고전적 volume rendering technique 활용하여 2D image 상의 최종 rgb 값 계산. -
High-resolution을 얻어내기 위해, 1) positional encoding과 2) hierarchical sampling procedure 도입
2. Related Work
(생략)
3. Neural Radiance Field Scene Representation
-
+ <5D vector-valued function > +
-
Viewing direction과 관계없는 volume density 는 location 로부터만 계산되도록 설계. 3D coordinate 가 8 FC layers에 입력되어 값과 256-dim. feature vector를 출력하고, viewing direction 이 concatenate되어 1 FC layer에 입력, 최종 view-dependent RGB color가 출력됨.
4. Volume Rendering with Radiance Fields
- Volume density 를 해당 지점에서 ray가 멈출 differential probability로 여기는 관점. Camera ray 에 해당하는 expected color 은 아래와 같이 계산.
-
는 으로부터 까지 진행한 ray에 축적된 transmittance를 의미.
-
위 계산을 deterministic quadrature로 근사하되, 아래와 같이 를 개의 등간격으로 나눈 뒤 각 구간에서 uniform하게 query point를 추출하는 stratified sampling approach를 사용. 연속적인 지점 모두에 대한 학습이 이뤄지므로 continuous scene을 represent할 수 있음.
- 는 인접한 3D point sample 간 거리를 의미.
5. Optimizing a Neural Radiance Field
5.1 Positional Encoding
- Deep network는 lower frequency function으로 학습되려는 경향이 있음. 이를 방지하기 위해, 입력값을 higher dimensional space로 mapping한 뒤 network에 입력하는 방식.
- Transformers에서 사용되는 positional encoding은 sequence를 구성하는 token의 discrete position에 대한 정보를 부여하려는 목적이었다면, NeRF에서는 input coordinates를 higher dimensional space로 보내려는 목적.
5.2. Hierarchical Volume Sampling
-
Ray 상의 query points를 sampling하면 빈 공간이나 가려진 공간 등까지 반복적으로 선택돼 비효율적임. Rendering에 대한 기여도에 따라 sampling하기 위해 'coarse' network와 'fine' network를 동시다발적으로 학습.
-
Stratified sampling으로 locations를 추출하여 우선 'coarse' network evaluate. 그렇게 학습된 'coarse' network의 출력값으로 계산된 normalized weights 를 기반으로 inverse transform sampling하여 locations 추출. 최종적으로 samples에 대해 rendering 진행.
5.3. Implementation Details
- 두 network에 대해, image에서 임의로 추출된 pixel의 rendered color와 true pixel color간 total squared error로 학습 진행.
Paper Summary
Spatial location과 viewing direction으로부터 color와 density를 출력하는 MLP에 고전적 volume rendering 방법을 결합하여 novel-view synthesis 수행. Positional encoding을 통해 resolution을 높이고 hierarchical volume sampling으로 학습의 효율을 높임.
