Realfusion (based on stable-dreamfusion)
RealFusion: 360° Reconstruction of Any Object from a Single Image
Melas-Kyriazi et al. | CVPR 2023

Paper Summary
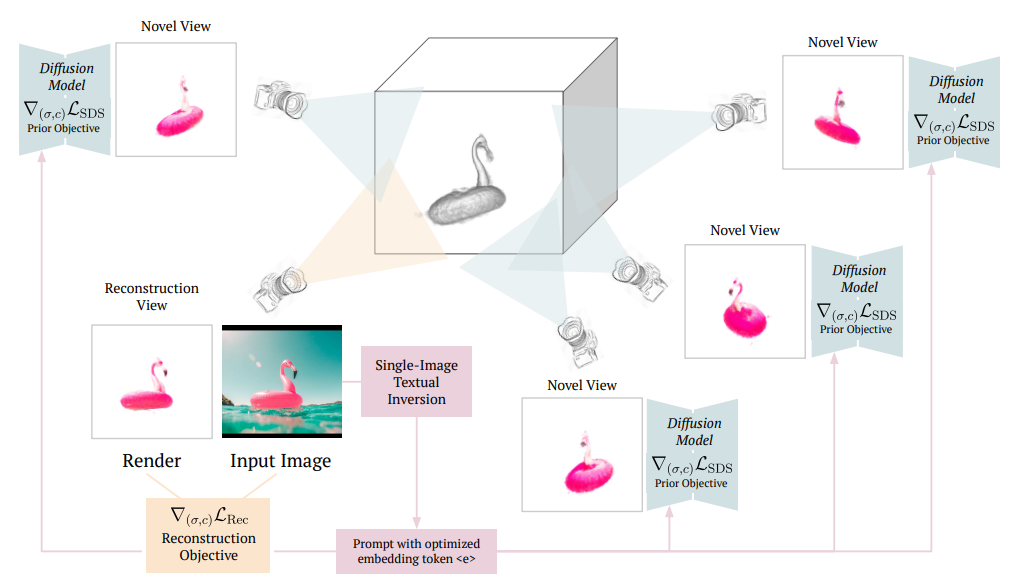
: 단일 이미지에 대해 DreamFusion(NeRF+Imagen)으로 생성된 novel view image로 full-360 reconstruction 진행.
Dependencies
Repo 상 dependencies 실행 후,
1) textual_inversion.py 파일 line 578의 'logging_dir' 'project_dir' 수정
2) 'accelerate' 라이브러리 버전 업데이트
pip install git+https://github.com/huggingface/accelerate3) trimesh, mcubes, lovely_tensors, rembg 라이브러리 설치
pip install trimesh PyMCubes lovely_tensors rembg4) diffusers 라이브러리 버전 업데이트
pip install diffusers==0.15.0.Data
python scripts/extract-mask.py --image_path ./examples/lipstick/lipstick.png --output_dir ./examples/lipstickTextual Inversion
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="../examples/crocs"
export OUTPUT_DIR="../examples/crocs"
python textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="_shoes_" \
--initializer_token="shoes" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 --scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir=$OUTPUT_DIR \
--use_augmentationsReconstruction
export DATA_DIR=examples/crocs
python main.py --O \
--image_path $DATA_DIR/rgba.png \
--learned_embeds_path $DATA_DIR/learned_embeds.bin \
--text "A high-resolution DSLR image of a _shoes_"7/6 Thu.
*Server: V-100 32GB
- Reconstruction 이전에 textual inversion 작업 필요
(3,000-it | 대략 2hr 40min ~ 3hr 소요) - 이후 reconstruction 5,000-it 학습 (대략 30min ~ 40min 소요)
- 각 단계의 epoch 수에 대한 최적화 필요
- ./examples/natural-images/banana_1 & bird_sparrow에 대해 학습
- 인터넷 상 lipstick, crocs 이미지에 대해서도 학습
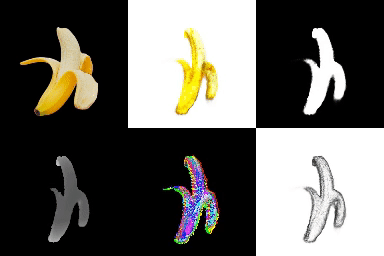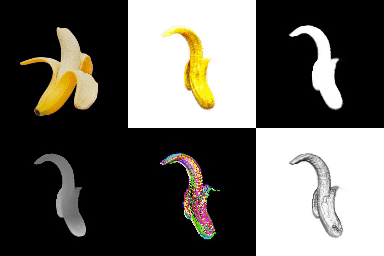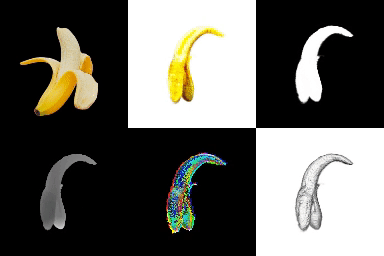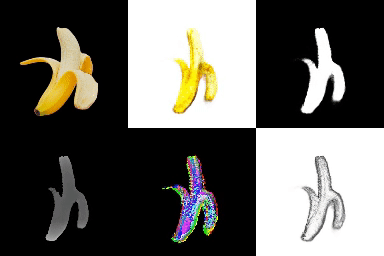
[Reference : Single-View 3D Reconstruction (Texture)]

*영상은 1) 원본 이미지, 2) RGB, 3) Opacity, 4) Depth, 5) Normal, 6) Texture 순서.



7/10 Mon.
Official Live Demo
- Original input image에 대한 reconstruction loss와 novel view에 대한 SDS loss + normal vector regularization을 기반으로 학습되는 기존 pipeline을, reconstruction loss에 대해서만 학습시켜 limited angle view에 대해 얼마나 reference를 잘 수행하는지 확인.
: Inference time이 얼마나 줄어들고, reference view에 대한 resolution이 얼마나 향상되며, 어느 각도까지 돌릴 수 있겠는가?
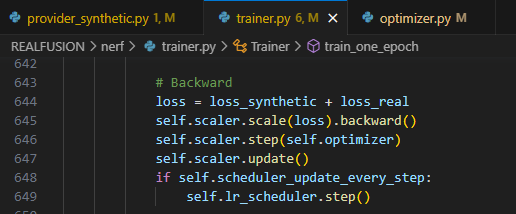
- 644 line을 아래와 같이 수정하면 SDS loss에 대한 backprop을 멈출 수 있음.
loss = loss_real- 이후 lipstick에 대해 생성된 3D reconstruction 결과.

7/11 Tue.
-
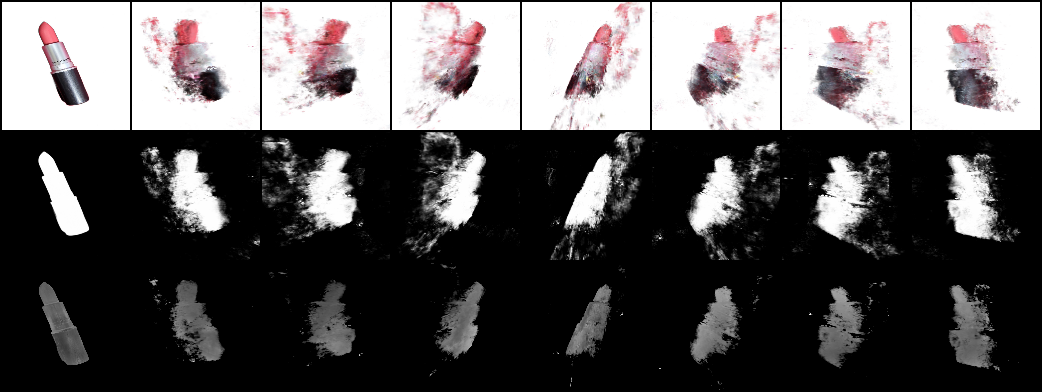
Recon. loss만 적용한 경우, reference view에 대해서는 500 epoch만 지나도 충분히 fitting되며, novel view는 각도를 살짝만 틀어도 크게 망가짐.

-
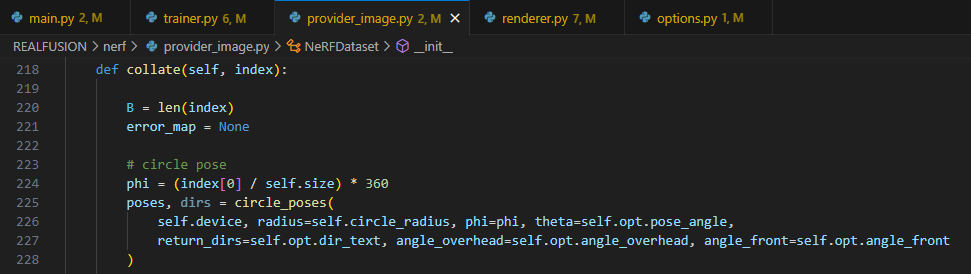
provider_image.collate() 함수가 pose의 phi 값을 360°/size로 등분하고, validation은 8개의 각도, training은 100개의 각도에 대해 inference 진행.


+ Training epoch가 늘어날 수록 오히려 novel-view synthesis에 대한 smoothness는 떨어지는 것 같은데 다른 object에 대해서도 확인해봐야 할 듯.
*Pose angle을 10°로 바꿔주면?
: Azimuthal angle을 360° 돌려주기 때문에 위와 같은 result 발생. Pose angle은 80°~90°로 고정시켜 두어도 괜찮을 듯.

-
Lipstick보다 복잡한 형태의 object에 대해서도 limited angle에서 consistency가 얼마나 유지되는지 확인해보자 'colorful_teapot.png'
-
Full 3D-reconstruction (Training duration: 32m 28s / 35s per 100-it)

-
Only recon. loss guided (Training duration: 6m 17s / 4s per 100-it)


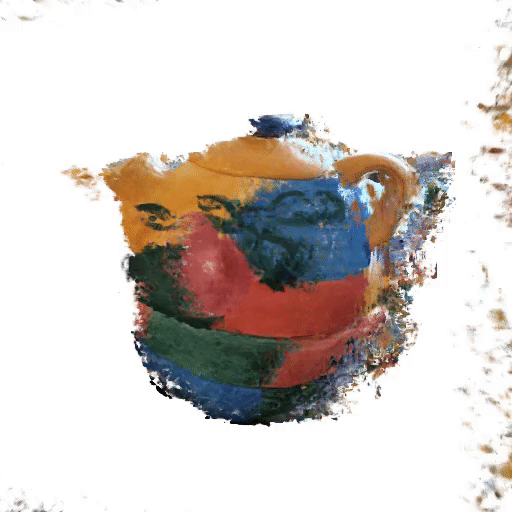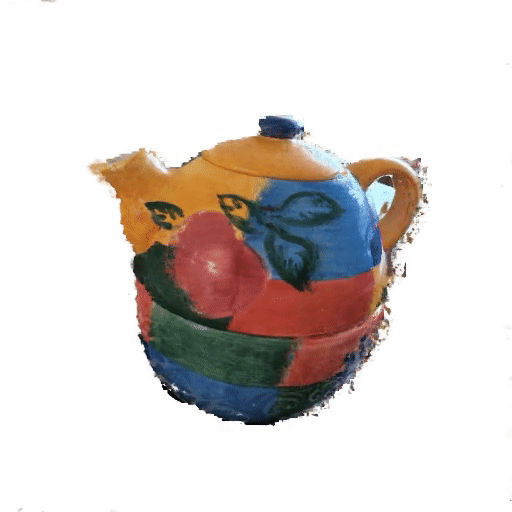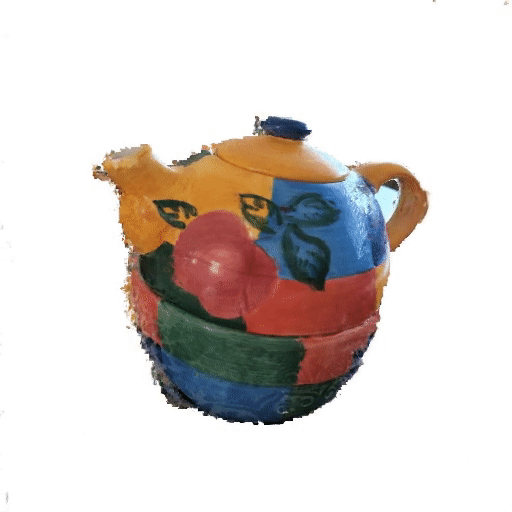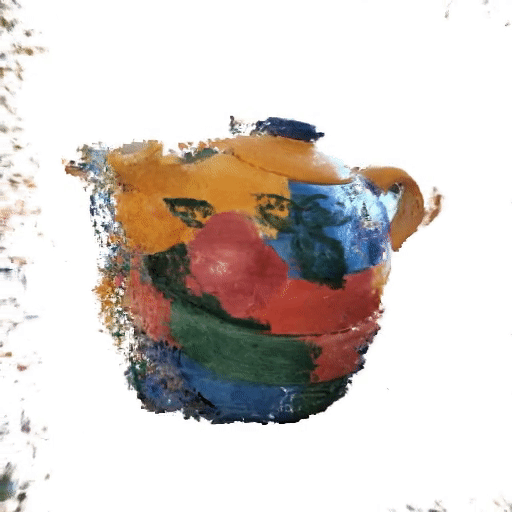
-
