Abstract
Large-scale diffusion model의 geometric prior를 활용, synthetic dataset에 대해 학습되어 한 장의 RGB 이미지가 주어졌을 때 카메라 viewpoint를 바꾸는 framework 제시.
1. Introduction
-
3D annotation이나 stereo views, camera poses에 대한 training dataset의 부족. 이에 의존하는것은 poor generalization capability 유발.
-
Zero-shot novel view synthesis 혹은 3D shape reconstruction을 수행하기 위해, camera viewpoint를 large-scale diffusion model을 통해 제어할 수 있음을 보임.
-
단일 RGB 이미지는 under-constrained 조건이지만, 여러 viewpoint에 대한 object의 이미지로 학습된 diffusion model을 fine-tuning하여, camera correspondences 없이도 다른 camera viewpoint에 대한 decoding 가능.
2. Related Work
-
3D generative models: Pre-trained large-scale 2D diffusion model을 ground truth 3D data 없이 3D domain으로 transfer하려는 시도들이 이뤄지고 있음.
e.g. NeRFs, DreamFields, Dreamfusion, Magic3D -
Viewpoint-conditioned image-to-image translation
e.g. 3DiM (zero-shot generalization에 대해선 다루지 않음), NeRDi, RealFusion, NeuralLift-360 (language-guided prior와 textual inversion 활용) -
Single-view object reconstruction
: Meshes, voxels, point clouds 등의 3D primitives에 의존하는 방법론은 generalization capbaility가 떨어짐.
: Local image feature로 scene reconstruction을 진행하는 locally conditioned model들은 close-by view로 제한됨.
: MCC 모델은 RGB-D view로부터 3D reconstruction 진행.
Pre-trained stable diffusion model로부터 추가적인 depth information 없이 geometric information을 추출하였음.
3. Method
-
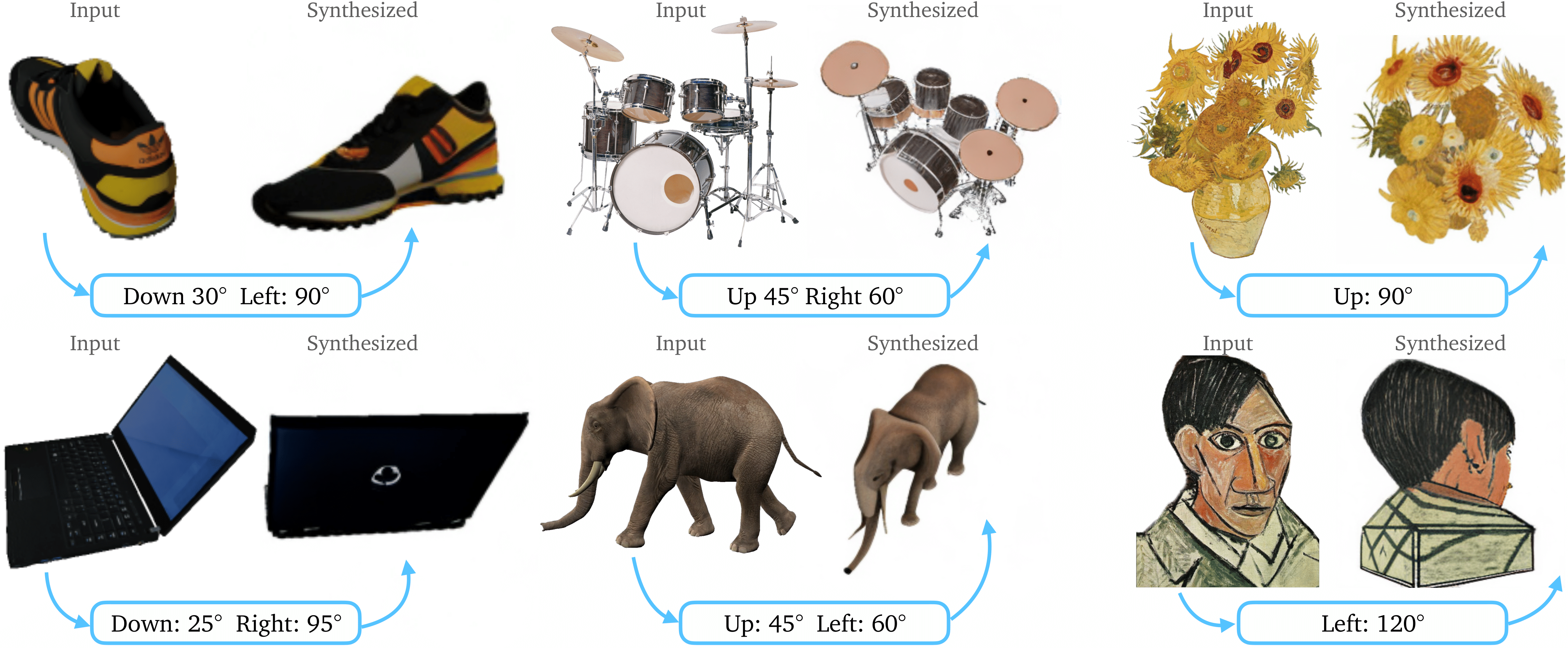
단일 RGB 이미지 와 desired viewpoint로의 relative camera rotation , translation 를 입력받아 synthesized image 를 생성.
-
다양한 viewpoint에 대해 학습된 large-diffusion model이더라도, viewpoint 간 correspondency가 explicit하게 학습되어 있지 않으며, 인터넷 상 이미지의 정면을 바라보는 bias가 반영되어 있음.
3.1. Learning to Control Camera Viewpoint
-
Camera extrinsics를 제어하는 메커니즘을 pre-trained diffusion model이 학습할 수 있도록 함.
-
이미지 쌍과 relative camera extrinsic 을 기반으로 pre-trained diffusion model에 대한 fine-tuning 진행. Camera viewpoint의 회전에 대한 generic mechanism 학습.
- (: Embedding of input view and relative camera extrinsics
3.2. View-Conditioned Diffusion
- Hybrid conditioning mechanism 제시.
1) Input image의 CLIP embedding에 camera condition 를 concatenate하여 "posed CLIP" embedding 를 구성한 뒤, U-Net에 cross-attention으로 conditioning Input image에 대한 high-level of semantics 부여.
2) Input image 자체를 denoising process에 channel-concatenate Identity 및 detail 유지.
3.3. 3D Reconstruction
- Score Jacobian Chaining (SJC) framework를 적용, 임의의 viewpoint를 추출한 뒤 volumetric rendering 진행.
- NeRF representation에 대한 regularization을 위해, depth smoothness loss와 near-view consistency loss 추가.
3.4. Dataset
- High-quality 3D model로 구성된 Objaverse dataset 이용, 12 camera extrinsic matrices에 대해 12 views를 샘플링하여 image pair 생성.
4. Experiments
-
일반적으로 3D reconstruction을 진행 후, 3D object를 projection하여 novel view synthesis를 진행하는 반면, 본 모델은 그 순서가 반대이기에 novel view synthesis의 속도가 빠름.
-
이하 생략.
Appendix
C. Finetuning Stable Diffusion
- Inference Details: 2 sec to generate a novel view (RTX A6000 GPU)
D. 3D Reconstruction
- 30 minutes to run a full 3D reconstruction (RTX A6000 GPU)
Paper Summary
Pre-trained diffusion model을 (image pair, camera extrinsics)의 dataset으로 fine-tuning하여 novel-view synthesis 학습. 이후 SJC framework로 3D-reconstruction 학습.
