'RealFusion: 360° Reconstruction of Any Object from a Single Image' Paper Summary
'23 Internship Study
Abstract
DreamFusion method로 input view와 conditional prior, regularizers를 합하여 full 360° reconstruction을 진행.
1. Introduction
-
Existing 2D model에서 3D information을 추출하는 문제는 아직 성능이 제한됨. 대표적으로, coverage(=mode collapse, 다양한 이미지를 생성하긴 하지만 대부분의 특정 이미지에 대해선 출력해내지 못함) 문제 발생.
-
입력 이미지에 대해 NeRF를 optimize 해주고, other views를 샘플링하여 DreamFusion에서의 diffusion prior로 regularize 진행.
-
이후 프롬프트를 적절히 수정하고, 몇 가지 regularizer를 추가함.
2. Related Work
- Image-based reconstruction of appearance and geometry
- Few-view reconstruction
- Single-view reconstruction
- Extracting 3D models from 2D generators
- Diffusion Models
3. Method
3.1. Radience Fields and DreamFusion
-
Radiance Field (RF)
: 일반적으로 NeRF의 image reconstruction에 대한 optimization이 이뤄지려면 단일 물체에 대한 수백 장의 이미지가 필요. 한 장의 이미지가 주어지는 single-view reconstruction의 경우 overfitting이 발생. -
Diffusion Model (DM)
: Prompt 에 conditioning 된 distribution 로부터 denoising 학습. Classifier-free guidance로 conditinoing의 strength 조절. -
DreamFusion and Score Distillation Sampling (SDS)
: Camera parameter 를 임의로 sampling하여 corresponding view 를 rendering한 뒤 pre-trained diffusion network를 frozen critic으로 두어 score distillation sampling 진행.
: 좋은 3D shape를 얻어내기 위해 classifier-free guidance weight을 100으로 크게 설정하는데, 생성물의 diversity를 낮춤.
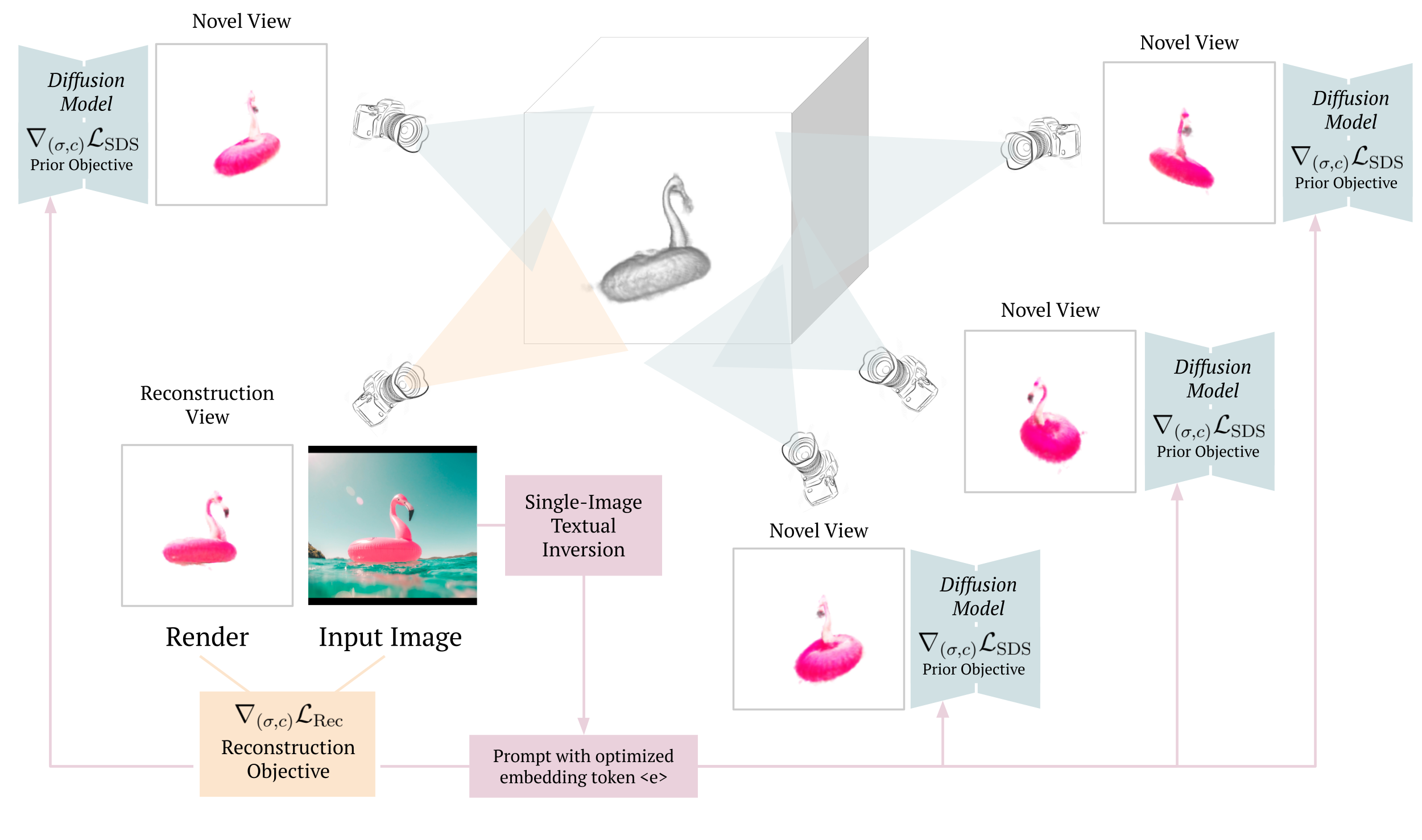
3.2. RealFusion
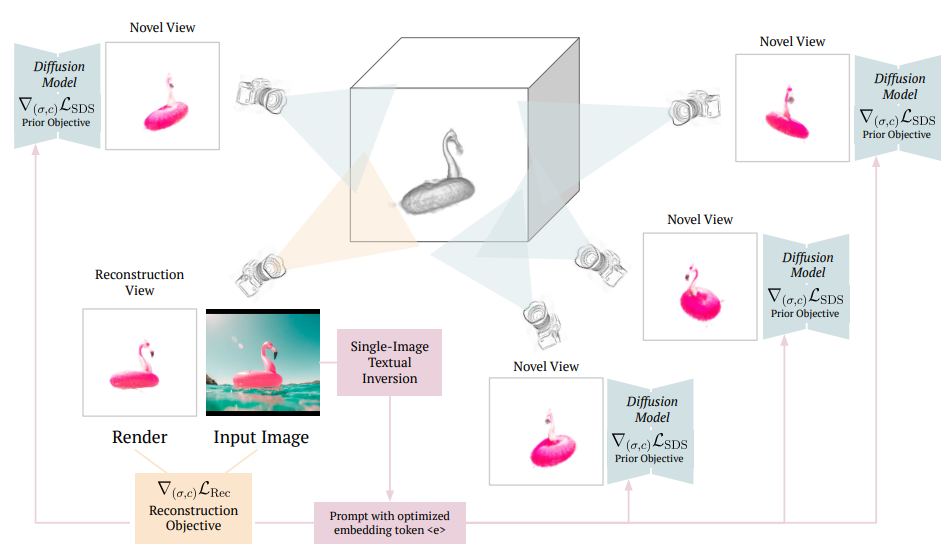
-
Single-image textual inversion as a substitute for alternative views
: Single-image 로부터 textual inversion으로 text prompt 생성. Pseudo-alternative-views의 역할을 수행하는 random augmentations 로 mini-dataset 구성 후 diffusion loss로 "an image of a " 형태의 prompt optimize. -
Coarse-to-fine training
: Multiple resolutions의 feature grids 로 feature를 저장하는 InstantNGP를 conventional MLP-based NeRF 대신 사용. 이 때 물체의 표면에 발생하는 작은 irregularities는 coarse-to-fine manner(학습 초반엔 lower-resolution feature grids만 학습 후 후반에 전체 grids를 학습)로 학습시키며 완화. -
Normal vector regularization
: 모델이 종종 low-level artifacts가 포함된 noisy-looking surfaces를 생성하는 것을 보완하기 위해, smooth normal vector를 갖도록 regularize. -
Mask loss
: Rendered opacity에 대한 L2 loss term을 추가하여 image matting 구현.- Image matting
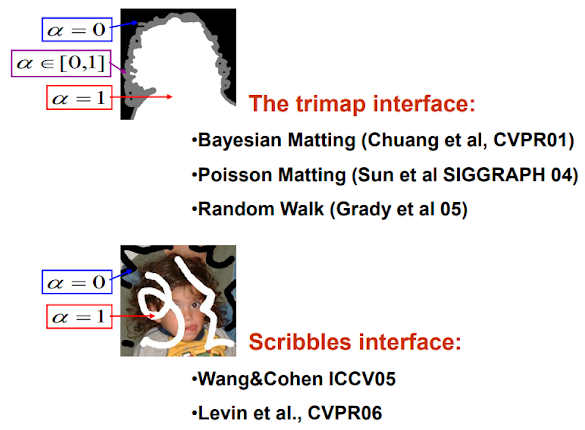
- Image matting
4. Experiments
- Per-scene hyper-parameter optimization 없이 진행.
F. Analysis of Failure Cases
- Transparent neural field를 종종 생성함.
- Reference view 상의 물체 앞에, input image의 reconstruction을 위해 'floater'가 생기는 문제 발생.
- Janus Problem 발생.
Paper Summary
Single-view 3D reconstruction을 위해, input image에 대한 textual inversion으로 model prompt를 생성한 후 pre-trained Stable Diffusion으로부터 score distillation sampling으로 InstantNGP 학습. Coarse-to-fine training과 normal vector regularization 통해 성능 개선.
