1. Introduction
-
Frame 단위로 별개의 SR을 적용하는 것은 temporal incoherence가 망가지는 경향이 있음. VSR은 inter-frame information을 어떻게 leverage하여 motion consistency를 유지하는가가 핵심.
-
VSR 모델은 크게 고전적 방법과 딥러닝 기반 방법으로 나뉨.
-
고전적 방법: Affine model로 motion estimation 수행. Non-local mean 및 3D steering kernel regression을 적용하거나 Bayesian approach로 접근하여 blur kernel을 추정하지만 한계가 명확함.
-
딥러닝 기반 방법: CNN, GAN, RNN 기반으로 LR & HR video sequences를 활용해 inter-frame alignment 및 feature extraction 등을 학습함. 대부분 아래와 같이 alignment module - feature extraction and fusion module - reconstruction module로 구성됨.
-
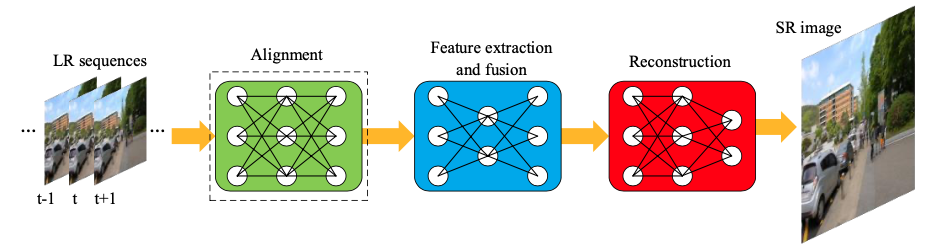
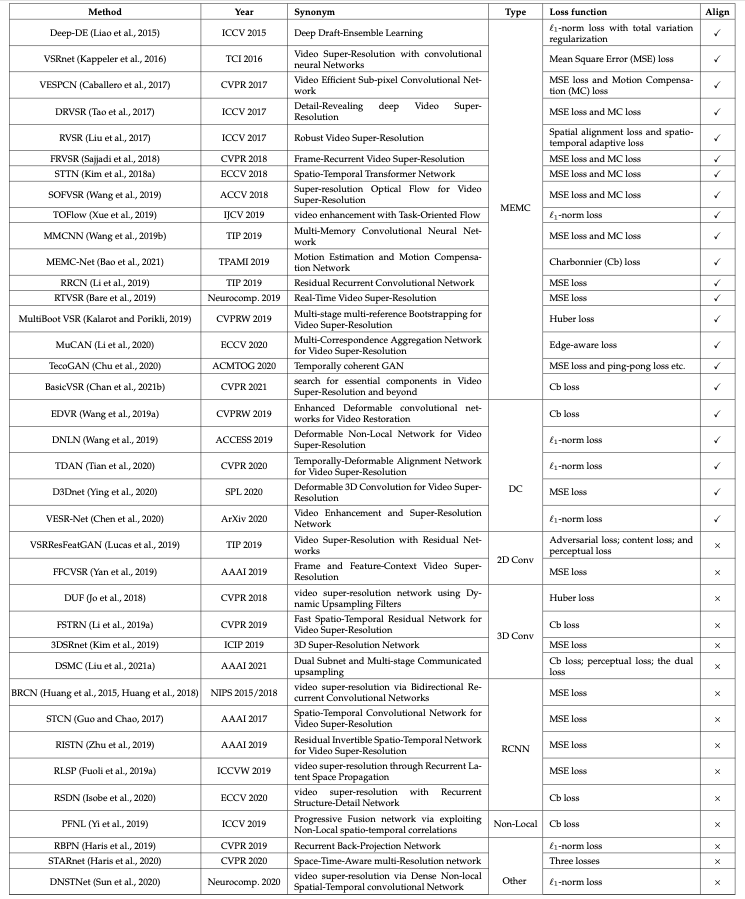
2. Video Super-Resolution Methods
cf. SISR 모델: SRCNN(2014, 이를 기반으로 2016년 VSRnet 발표), FSRCNN(2016), VDSR(2016), ESPCN(2016), RDN(2018), RCAN(2018), ZSSR(2018), SRGAN(2017)
-
Inter-frame information의 utilization 방식에 있어, 영상의 각 프레임이 explicit하게 align되는가를 기준으로 1) with alignment 모델과 2) without alignment 모델로 분류 가능.
-
2015-2017년에는 frame alignment가 대부분 활용되었으나, 2018년부터는 FFCVSR, DUF, RISTN, PLNL 등을 비롯해 alignment를 포함하지 않는 모델이 다수 발표되었음. 또한 과거엔 특정 범위 내의 프레임에 한해 sliding-window를 활용하여 VSR에 적용했다면, 최근엔 receptive field를 늘려 모든 프레임 정보를 활용함.
3. Methods with Alignment
- 일반적으로 1) MEMC(Motion Estimation and Motion Compensation) 혹은 2) deformable convolution을 활용하여 frame을 align.
3.1 Motion Estimation and Motion Compensation Methods
: 프레임 간의 motion 정보를 추출하는 motion estimation과, 이를 바탕으로 한 프레임을 다른 프레임과 align하도록 warping(transformation)하는 motion compensation으로 구성. 대부분 optical flow method 사용.
: 이웃한 프레임 사이에서 시간축 상의 correlation과 variation을 기반으로 motion 계산.

- Deep-DE (2015): TV- flow와 motion detail preserving (MDP)를 고려하여 SR 초안을 생성한 뒤 bicubic interpolated LR frame과 concatenate하여 CNN을 통과시킴.
- VSRnet (2016): SISR 모델 SRCNN을 기반으로 하여, Druleas algorithm으로 motion information을 계산, filter symmetry enforcement (FSE) mechanism과 adaptive motion compensation mechanism 제시.
- RRCN (2019): Bidirectional RNN으로 residual image를 학습하여 연속된 프레임으로부터 중간 프레임을 SR. Combined local-global with total variable (GLG-TV) method 사용.
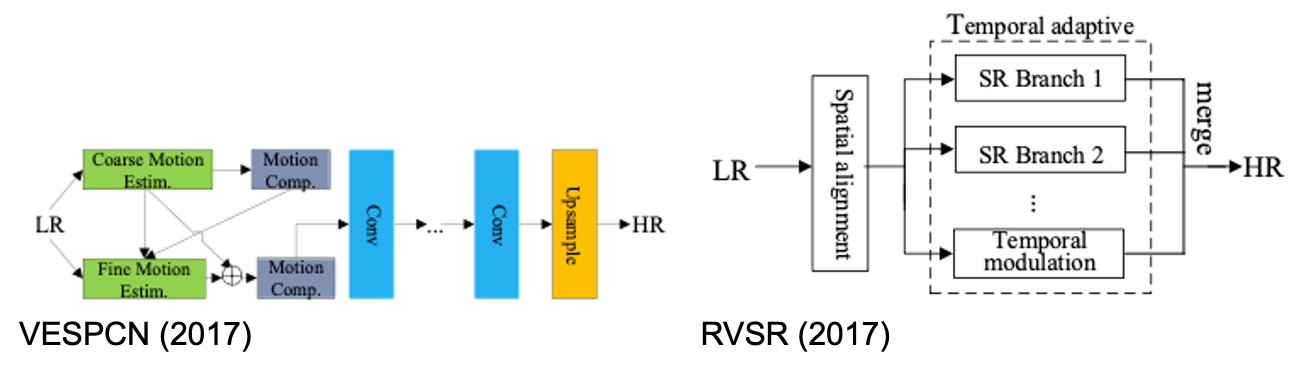
- VESPCN (2017): Spatial motion compensation transformer (MCT) module 제시. Coarse-to-fine approach로 optical flow 계산. LR 이미지에 대한 up-sampling을 네트워크의 마지막에서 수행하여 연산량 감소, 배로 up-scaling할 때 배만큼 채널 수를 늘려 feature mape을 구성한 뒤 이로부터 한 픽셀씩 떼어와서 HR 이미지로 reconstruct Sub-pixel convolution.
- RVSR (2017): Spatial alignment module로 alignment 성능을 올리고 temporal adaptive module로 temporal dependency의 최적 scale을 결정.
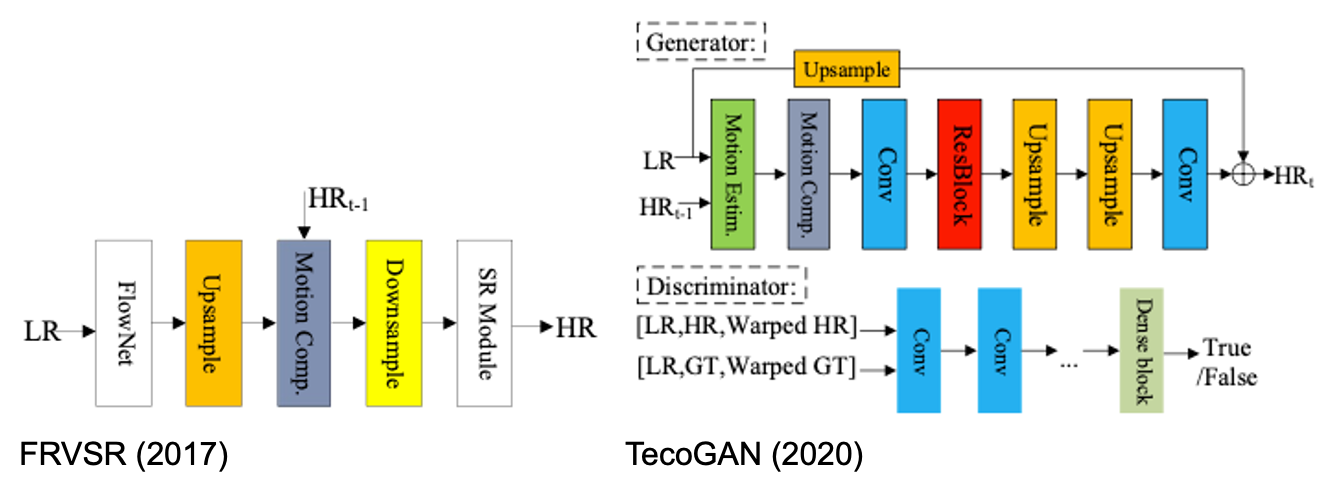
- FRVSR (2017): Super-resolution을 거친 이전 프레임에 FlowNet으로 얻어낸 optical flow를 더하여 SR.
- TecoGAN (2017): Spatio-temporal discriminator 제시. Generator는 현 LR frame과 이전 SR frame을 입력받아 SR 진행, discriminator는 생성된 결과와 GT에 대한 (LR, HR, Warped) 이미지를 입력받아 평가 수행.
MEMC technique은 인접한 프레임들을 align하는데 사용되며, 가장 일반적. 단, 조명 조건이 급격히 바뀌거나 큰 움직임을 포함하면 정확도가 떨어지게 됨.
3.2 Deformable Convolution Methods
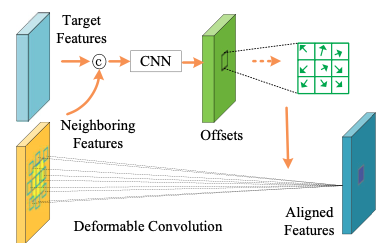
: 기하학적 변형에 대해 학습하기 어려운 기존 CNN의 한계점 보안. Target feature와 neighboring feature를 통해 구한 offset을 기존의 convolution kernel에 적용하여 크기와 모양이 변화하는 deformable convolution kernel을 얻어냄.
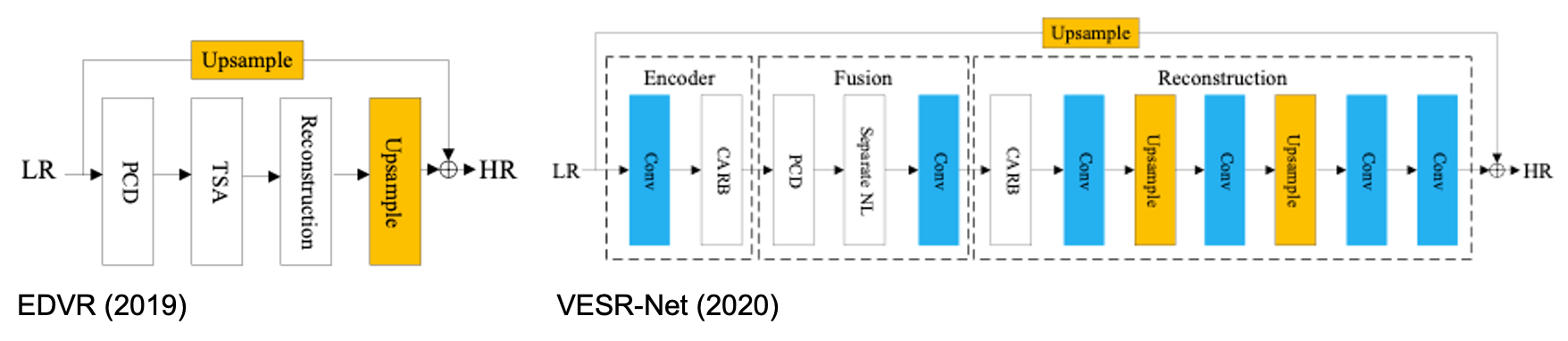
- EDVR (2019): 큰 동작을 해결하기 위한 pyramid, cascading and deformable (PCD) alignment module과 여러 프레임을 효과적으로 합치는 temporal-spatial attention (TSA) fusion module 제시. 인접한 여러 프레임이 PCD alignment module을 통과한 뒤 TSA fusion module에 의해 합쳐지고, reconstruction module을 통해 feature가 refine되어 upsample됨.
- VESR-Net (2020): 다음의 세 module로 구성 - Conv layer와 channel-attention residual blocks (CARBs)로 구성된 1) feature encoder. Inter-frame feature alignment를 수행하는 PCD convolution과 그 결과물을 spatial, channel, temporal dimension으로 분류하는 Seperate NL로 구성된 2) fusion module. CARBs와 sub-pixel convolutional layer로 구성되어 feature decoder의 역할을 수행하는 3) reconstruction module.
초기의 SR 알고리즘이 전통적인 MEMC 방법론을 사용했다면, 후반부의 모델은 MEMC의 sub-module을 활용하는 형태로 발전함. 하지만 이는 조명 변화와 큰 움직임이 포함될 경우 성능이 하락하여 biRNN을 backbone으로 적용하며 문제를 완화하려 노력함. 이후, 이들에 둔감한 deformable convolution (DConv)이 제시되어 많이 활용되었으나 이 역시 연산량이 많고, 학습이 잘 수렴되지 않는다는 단점이 존재함.
4. Methods without Alignment
4.1 2D Convolution Methods
-
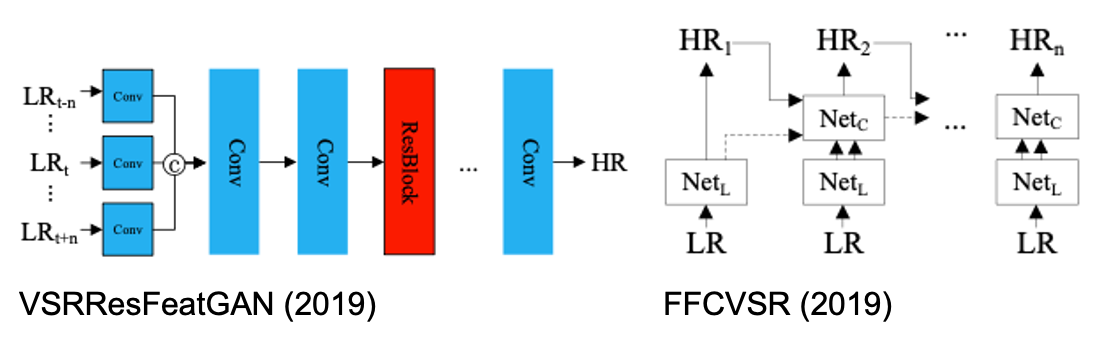
VSRResFeatGAN (2019): 인접한 프레임을 conv layer로 직접 통과시켜 SR 진행.
-
FFCVSR (2019): Local network와 context network로 구성되어 RNN의 형태로 SR 진행.
2D-convolution method는 motion estimation을 적용하여 warping을 하지 않고, 인접 프레임 자체로부터 spatial correlation을 직접 얻어냄.
4.2 3D Convolution Methods

- DUF (2016): 인접 프레임들의 feature map을 3D conv layer에 입력하여 spatio-temporal information을 한 번에 학습.
- FSTRN (2019): Factorized 3D convolution으로 연산량 개선. LR video에 대한 shallow feature extraction을 수행하는 LFENet, fast spatio-temporal residual blocks (FRBs), LR feature fusion & up-sampling SR net (LSRNet), global residual learning (GRL) module로 구성.
3D convolution method는 별도의 MEMS 없이 spatio-temporal correlation을 계산할 수 있으나, 대부분 높은 연산량을 요하며 real-time을 불가능케 함.
4.3 Recurrent Convolutional Neural Network (RCNN)
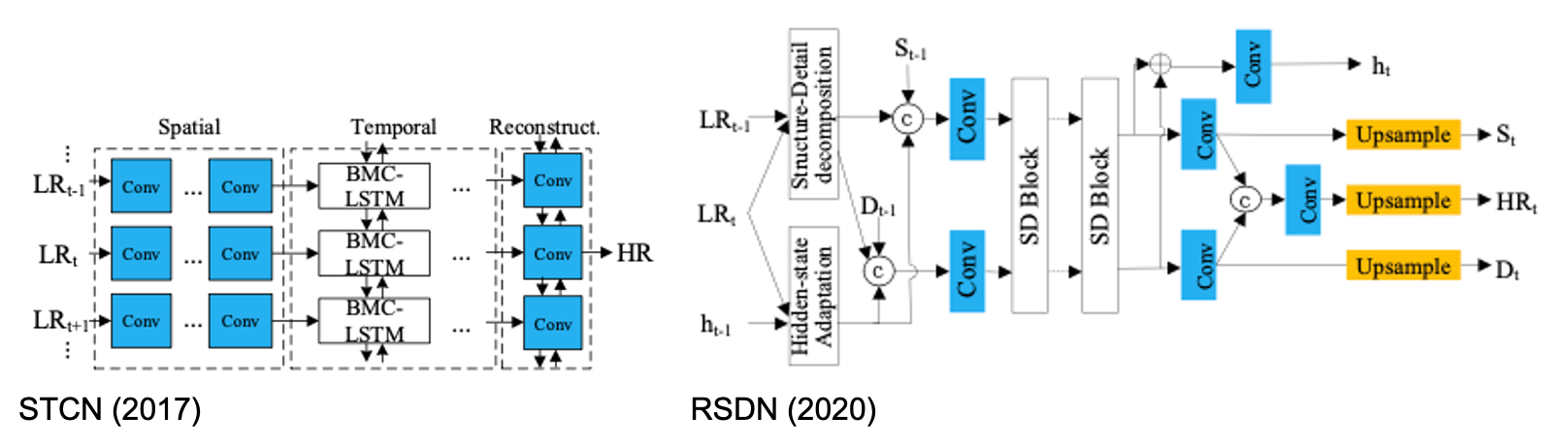
- STCN (2017): MEMC 없이 LSTM을 통해 spatial & temporal correlation을 추출.
- RSDN (2020): Structure와 detail component로 나누는 decomposition modeule과 SR에 도움이 되는 요소를 선별하는 hidden-state adaptation module로 구성.
RCNN-based 방법론은 long-term dependency를 보다 가벼운 구조로 학습할 수 있다는 장점이 있으나, 학습이 어렵고 gradient vanishing problem을 겪는다는 단점 존재.
4.4 Non-Local Methods
: 아래 관계식과 같이 feature map 상의 모든 지점에 대한 attention mechanism 사용.
Non-local method는 receptive field를 영상 전체로 확장하여 spatio-temporal 정보에 대한 dependency를 효율적으로 형성하나, 연산량이 많음.
Summary
최근 Deep-learning based VSR은 다음과 같은 방법을 사용.
- MEMC 또는 deformable convolution으로 인접한 frame들을 서로 align한 뒤 SR 진행.
- 별도의 explicit alignment 없이, 2D/3D conv layer 또는 RCNN, attention mechanism** 등으로 frame들로부터 spatio-temporal correlation을 얻어낸 후 SR에 leverage.
References
