Stable diffusion 논문을 살펴보기 전, generative models 이외의 prerequisite 개념에 대해 살펴보도록 하자.
'Attention Is All You Need' (NIPS 2017)
Introduction
-
기존 Seq2Seq(NIPS 2014) 모델은 고정된 크기의 context vector 에 input의 내용을 압축하는 과정에서 병목현상이 발생하여 성능적인 한계가 발생한다.
입력 sequence 전체에서 정보를 추출하는 attention 기법을 접목하였다. -
Encoder에서의 모든 output을 decoder가 참고할 수 있도록 해주는 방안이다.
: 각 단어에 대한 hidden state를 별도의 배열에 기록해둔 뒤 각 출력 단계에서 input state에 매기는 가중치인 energy 값을 정의한다. 이후 decoder에서 hidden state를 갱신할 때, 1) decoder의 이전 hidden state 값과 2) encoder의 hidden state를 energy와 곱한 weighted sum을 반영한다. -
를 현재의 decoder가 처리 중인 index, 를 encoder의 출력 index라고 두면,
-
Energy : 어떤 값과 가장 많은 연관성을 갖는가?
-
Weight : 확률값으로 바꾸어 에 곱해준다.
* : Decoder가 이전의 번째 단어를 생성할 때 사용한 hidden state, : Encoder에서 번째 단어의 hidden state -
과 를 통해 출력한다.
-
-
Attention 가중치를 사용해 각 출력이 어떤 input의 정보를 참고했는지 시각화도 가능.
Structure
-
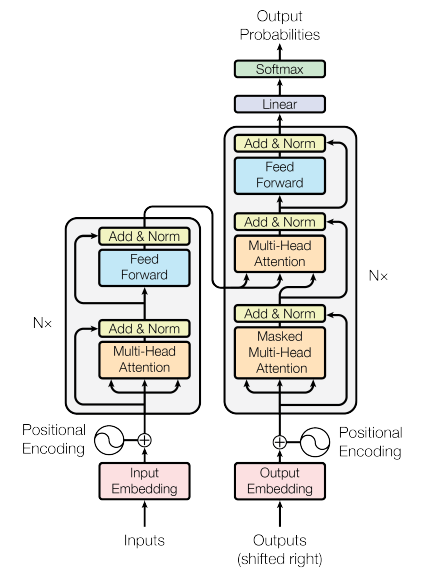
Transformer는 RNN이나 CNN을 전혀 사용하지 않으며, 문장 내 단어의 순서에 대한 정보는 positional encoding을 통해 제공한다. Multi-head attention에 입력되는 정보는 input embedding matrix + positional encoding.
*Encoder Self-Attention : 각각의 단어가 서로에게 어떠한 연관성을 갖는지를 구하기 위해 사용한다. -
또한 ResNet에서와 같이 residual learning을 사용한다. Encoder는 < Multi-head attention Residual add./norm. Feedforward layer Residual add./norm. >로 구성된 layer가 중첩된 구조이다.
-
반면 decoder의 경우 1) output embedding matrix에 대한 Masked Decoder Self-Attention layer와 2) 현재 출력되고 있는 단어와 input 단어들에 대한 상관성이 담긴 encoder의 output을 활용한 Encoder-Decoder Attention layer로 구성되어 있다.
-
RNN과는 달리, input 문장을 embedding matrix의 형태로 한 번에, 병렬적으로 입력해주므로 계산 복잡도가 낮아진다. Decoder의 경우, 가 나올 때까지 반복하여 network를 사용한다.
Multi-Head Attention Layer
-
Attention을 위한 세 가지 입력 요소 : Query, Key, Value
ex. "I am a teacher."의 문장에서 'I'가 다른 단어들과 가지는 연관성을 고려하는 경우, query는 'I', key는 각 단어들이 된다. -
개의 쌍을 concatenate한 뒤 linear layer를 거쳐 출력한다. 출력되는 vector의 크기는 입력되는 와 동일한 dimension을 가진다.
-
*Key dimension 으로 scaling하는 것은 gradient vanishing 문제를 피하기 위함이다. -
-
Self-attention
- 총 N개의 단어가 있다고 가정한다.
- 임의의 n번째 단어의 Q 값을 m번째 단어의 K 값과 내적, softmax 함수에 넣어 attention energy 값을 계산한다.
- m번째 단어의 V 값에 해당 energy 값을 곱한 후, 이를 N개의 단어에 대해 모두 수행하여 더한 weighted sum을 구하면 n번째 단어에 대한 self-attention 값이 완성된다.
- 이를 N개의 단어에 대해 수행하므로 NxD의 attention matrix가 생성되고, 이는 query, key, value matrix와 size가 동일하다.
Cross-attention
- 총 M개의 단어가 있는 언어(A-sequence)를 N개의 단어가 있는 언어(B-sequence)로 번역한다고 가정해보자.
- 임의의 n번째 단어의 Q 값을 m번째 단어의 K 값과 내적, softmax 함수에 넣어 attention energy 값을 계산한다.
- m번째 단어의 V 값에 해당 energy 값을 곱한 후, 이를 M개의 단어에 대해 모두 수행하여 더한 weighted sum을 구하면 n번째 단어에 대한 self-attention 값이 완성된다.
- 이를 N개의 단어에 대해 수행하므로 NxD의 cross-attention matrix가 생성되고, 이는 A-sequence의 matrix size와 동일하다.
Classifier Guidance
: 학습된 classifier의 gradient를 guidance로 삼는 아이디어이다.
-
Conditional reverse-time SDE
-
Bayesian rule을 적용하여 두 term으로 나누면,
두 번째 term은 time-dependent classifier로 학습 가능하다. -
기존 reference 단계의 score model 값에 trained classifier의 gradient 값을 더한 뒤 sampling. 해당 class의 image를 생성할 수 있다. (conditioning)
-
에 masked image를 입력하면 inpainting 가능, text를 입력하면 text-to-image 모델이 생성된다.
Classifier-free Guidance
:
Conditional diffusion model을 기반으로 unconditional diffusion model을 condition을 점차 안 주는 방향으로 학습시켜 conditional model의 성능을 구현한다.
References
