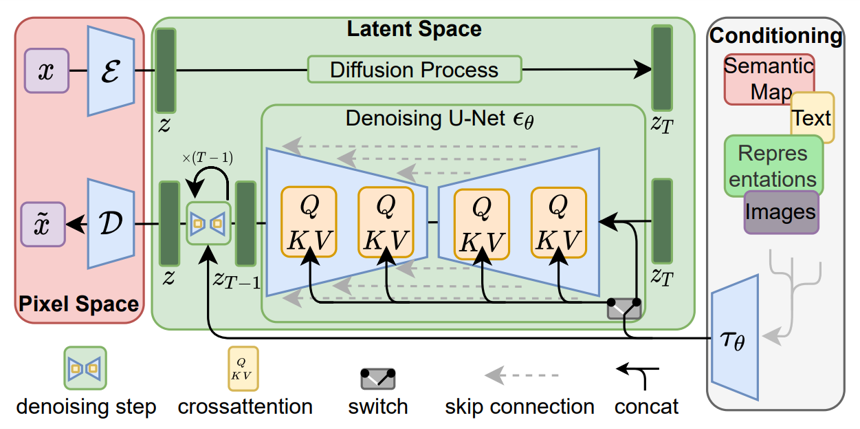
이제 대망의 Stable Diffusion을 알아보도록 하자.
'High-Resolution Image Synthesis with Latent Diffusion Models' (Rombach et al. CVPR 2022)
: Powerful pretrained autoencoder의 latent space에 DM training을 적용하여 computational requirements를 획기적으로 줄였다.
1. Introduction
- Likelihood-based diffusion model은 data의 imperceptible detail을 modeling하는 데 많은 capacity를 소비한다. 이는 training과 inference 과정에서 모두 큰 computational resources를 요한다.
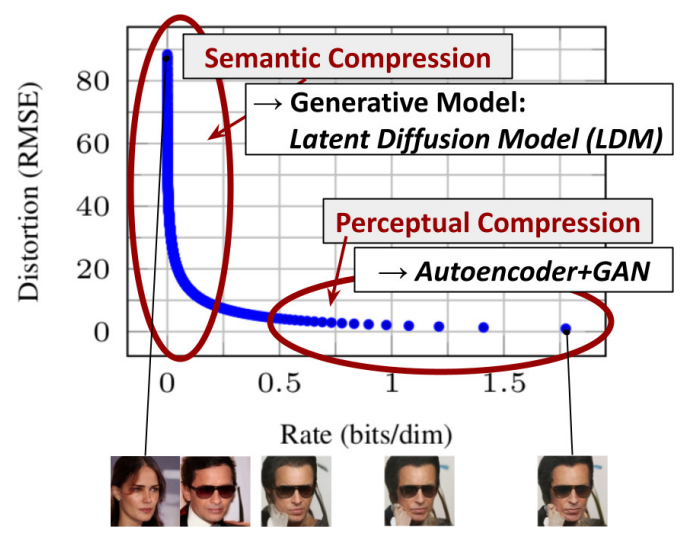
- Imperceptible detail을 학습하는 perceptual compression 과정과 semantic and conceptual composition을 학습하는 semantic compression으로 분리하였다.
- Perceptual compression 단계는 autoencoder를 활용하여 lower-dimensional representational space를 얻어내고, 이후의 semantic compression 단계를 Latent Diffusion Models(LDMs)를 통해 수행한다.
- 이를 통해, 1) compression level에서 학습함으로써 more detailed reconstruction 구현, 2) universal autoencoding stage를 통해 다양한 task 수행 가능, 3) 학습 과정에서 delicate weighting 불필요, 4) convolutional fashion으로도 적용 가능, 5) cross-attention을 통한 conditioning으로 text-to-image와 layout-to-image 모델 구현 등이 모두 가능하다.
2. Related Work (생략)
3. Method
-
Reconstruction loss term을 undersampling하여 perceptually irrelevant details를 무시할 수 있도록 하여도 high-resolution image synthesis를 위해서는 high computational demand가 발생한다.
-
"Explicit separation of the compressive form the generative learning phase"
-
1) Low-dimensional image space에서 sampling을 진행하기에 computationally efficient, 2) U-Net architecture를 통해 data의 spatial structure 효율적으로 학습, 3) multiple generative model에 적용 가능한 general-purpose compression model 획득의 장점을 가진다.
-
Perceptual Image Compression
- Perceptual loss(출력된 feature map 간의 L2 loss)와 patch-based adversarial objective(image 전체가 아닌 patch 조각에 대해 진위여부를 판별하여 local realism을 enforce) 기반의 autoencoder로 image manifold로의 reconstruction을 수행한다.
- Downsampling factor .
- 두 가지의 regularization에 대해 각각 실험하였다. :
- KL-reg : Learned latent와 standard normal 간의 KL-penalty 부여 Latent space가 Gaussian distribution을 따르도록. (cf. VAE)
- VQ-reg : Decoder에 vector quantization layer 사용 Latent space가 discrete하도록. (cf. VQ-VAE)
VQ-VAE : Encoder에서 출력된 latent vector에 대해, codebook(embedding space)의 vector 중 가장 거리가 가까운 vector를 찾아 decoder에 넣어 학습.
-
Latent Diffusion Models
- 에서 autoencoder를 통과한 에 대한 loss 식을 사용한다 ( 에 대한 neural backbone은 time-conditional UNet )
- U-Net backbone에 cross-attention mechanism을 도입해 DM에도 conditioning을 적용하였다. Domain specific encoder 도입
- : Intermediate representation of (control signal)
- ,
,
: a flattened intermediate representation of the UNet - Text 정보의 경우 attention layer(, 는 text features, 는 해당 layer의 noisy image에 해당)에, spatially aligned input (e.g. semantic maps, inpainting)의 경우 에 concatenate한다.
- 에서 autoencoder를 통과한 에 대한 loss 식을 사용한다 ( 에 대한 neural backbone은 time-conditional UNet )

정리하자면, parameterization을 통한 DDPM의 denoising process loss term을 동일하게 사용하나, denoising process을 cross-attention mechanism을 적용한 U-Net으로 구성하여 conditioning 기능을 추가하였다.
4. Experiments
-
On Perceptual Compression Tradeoffs
- Downsampling factor가 작으면 training progress에 대한 efficiency가 감소, 크면 information loss로 인한 fidelity stagnation이 발생한다. LDM-4, LDM-8이 가장 좋은 성능을 보였다고 한다.
-
Image Generation with Latent Diffusion
- Unconditional model은 GANs나 LSGM, ADM과 비슷하거나 상회하는 성능을 보였다고 한다.
-
Conditional Latent Diffusion
- Text-to-image image modeling : 1.45B parameter KL-regularized LDM conditioned on language prompts on LAION-400M + BERT-tokenizer + classifier-free diffusion guidance
- Semantic synthesis, super-resolution, inpainting에도 적용 가능하다.
Paper Tree
-
'Deep Unsupervised Learning using Nonequilibrium Thermodynamics', ICML 2015
: Nonequilibrium thermodynamics 분야의 개념을 도입해 비지도학습을 위한 방법론으로 diffusion probabilistic process를 처음 제시. -
'Denoising Diffusion Probabilistic Models', NeurlPS 2020
-
'Denoising Diffusion Implicit Models', ICLR 2021
: 간소화된 loss term과 U-Net structure를 도입해 high quality sampling에 대한 capability 증명.
https://jang-inspiration.com/ddim -
'Diffusion Models Beat GANs on Image Synthesis', NeurlPS 2021
-
'High-Resolution Image Synthesis with Latent Diffusion Models', CVPR 2022
-
'Classifier-Free Diffusion Guidance', NeurlPS 2021
-
'GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models', CVPR 2021
: Classifier-free and CLIP guidance를 통해 학습 -
'Hierarchical Text-Conditional Image Generation with CLIP Latents', CVPR 2022
: DALL-E2 / Text-encoder를 거친 latent space에 diffusion 적용. -
'Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding', CVPR 2022
: Imagen
- 'Attention Is All You Need', NIPS 2017
: Cross-attention 개념 도입.
Quantitative Evaluation
Inception Score / FID
Precision and Recall
https://velog.io/@tobigs-gm1/evaluationandbias
Samplers
https://stable-diffusion-art.com/samplers/
References
